Python电影爬虫之身体每况愈下
1.一时兴起
我们平常在线看视频时,有的时候会想下载到本地继续观看,但是苦于页面上找不到下载按钮,那么我们如何自己实现这个功能呢?
2.跃跃欲试
不要着急,我们打开浏览器f12开发者模式,点击如下:
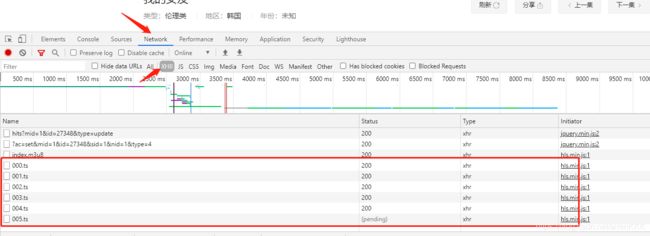
可以看到下面这个带编号的ts文件,我们点开000号文件看看

可以看到,000号文件请求了一个网址,我们新开一个窗口,看看里面有什么
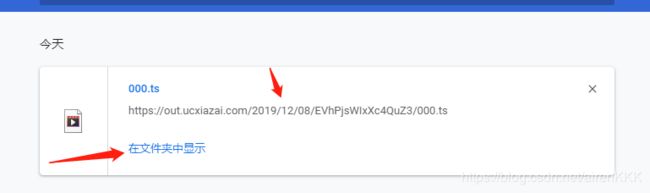
可以看到,在网址栏输入这个地址,它给我们下载下来了000.ts文件,我们打开该文件观察一下

打开一看,是一个5s的短视频,场景怎么如此熟悉,这不正是我们开头所见的那一幕吗。
有了有了,原来我们在线观看的视频是浏览器一次一次请求的ts文件拼接而来的,第一个文件真是正是000.ts,那么,我们可不可以找到这个编号的规律,自己一次性去请求这些地址从而拿到视频呢,答案是肯定的,因为这个规律实在是太过简单
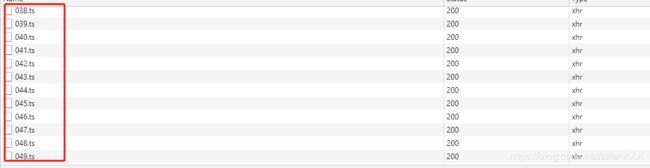
这不正是10以内的加减法吗,我们直接快进到视频结束,可以看到
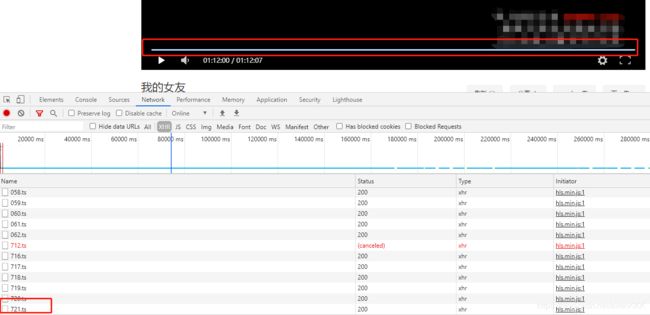
最后一个ts文件的编号正是721,ok。那么开始编码吧
import requests
import os
import time
from multiprocessing import Pool
def run(i):
url = 'https://v-cntv-cn.com/20181001/8645_8bbbbc35/800k/hls/96c5332c236%03d.ts'%i
print("开始下载:"+url)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"}
r = requests.get(url, headers = headers)
with open('./download/{}'.format(url[-10:]),'wb') as f:
f.write(r.content)
def merge(t,cmd):
time.sleep(t)
res=os.popen(cmd)
print(res.read())
if __name__ == '__main__':
# 创建进程池,执行10个任务
pool = Pool(10)
for i in range(722):
pool.apply_async(run, (i,)) #执行任务
pool.close()
pool.join()
#调用合并
merge(0,"copy /b download\\*.ts download\\movie.mp4")
print('ok!处理完成')
for循环生成顺序数传入run函数,启动10个线程同时下载。
下载完成之后我们再调用merge函数将这700多个ts文件拼接成一个mp4文件。
运行主函数:

3.大功告成

可以看到,download目录下生成了一些奇奇怪怪的ts文件,文件夹打开,也可以看到出现了一些奇奇怪怪的片段

等待程序运行完成,我们的download目录下会生成一个合并后的文件,点开播放之,时长吻合

4.索然无味
索然无味