Spring Cloud Sleuth--服务链路追踪(二)
在链路中添加自定义数据
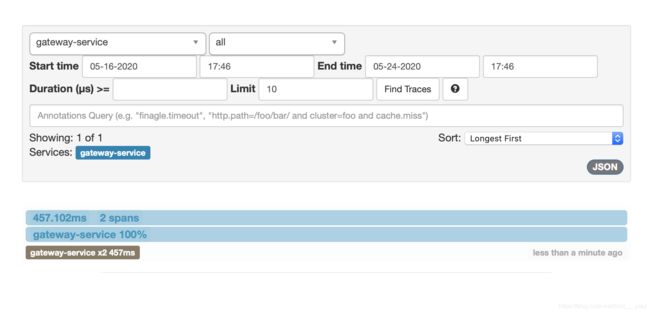
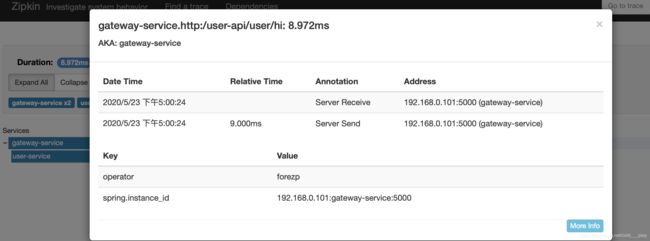
现在需要实现这样一个功能:在链路数据中加上请求的操作人。被案例在geteway-service服务中实现。在gateway-service工程中新建一个ZuulFilter过滤器,它的类型为post类型,order为900,开启拦截。在过滤器的拦截逻辑方法里,通过Tracer 的addTag 方法加上自定义的数据,在本案例中加上了链路的操作人。另外也可以在这个过滤器中获取当前链路的traceld信息,traceld 作为链路数据的唯一标识, 可以存储在log日志中,方便后续查找,本案例只是将traceld信息简单地打印在控制台上。代码如下:
@Component
public class LoggerFilter extends ZuulFilter {
@Autowired
Tracer tracer;
@Override
public String filterType() {
return FilterConstants.POST_TYPE;
}
@Override
public int filterOrder() {
return 900;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
tracer.addTag("operator", "forezp");
System.out.println(tracer.getCurrentSpan().traceIdString());
return null;
}
}
使用RabbitMQ传输链路数据
在上述案例中,最终gateway-service收集的数据是通过Http上传给zipkin-server的。在SpringCloudSleuth中支持消息组件来传递链路数据。
首先改造sipkin-server工程,在其pom文件中将zipkin-server的依赖去掉,加上spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit的依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eurekaartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-sleuth-zipkin-streamartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-stream-rabbitartifactId>
dependency>
dependencies>
配置中加上rabbitmq的配置:
server:
port: 9411
spring:
application:
name: zipkin-server
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
启动类上加上@EnableZipkinStreamServer注解:
@SpringBootApplication
@EnableEurekaClient
// @EnableZipkinServer
@EnableZipkinStreamServer
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
现在来改造Zipkin Client (包括gateway-service工程和user-service工程),在它们的pom文件中将spring coud-tartrzipki依赖改为spring cloud-sleth-zipkin-strearmn和spring-cloud-tarterstream-rabbit,代码如下:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-sleuth-zipkin-streamartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-stream-rabbitartifactId>
dependency>
同时在配置文件applicayion.yml加上RabbitMQ的配置,同zipkin-server工程。这样,就将链路的上传数据从Http改为用消息代组件RabbitMQ。

在MySQL数据库中存储链路数据
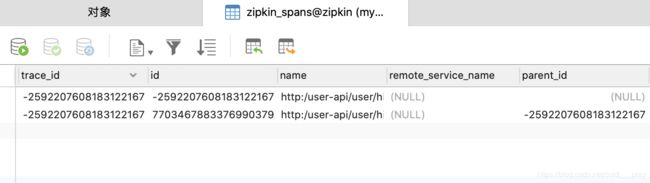
在上面的例子中,Zipkin Server将数据存储在内存中,一旦程序重启, 之前的链路数据全部丢失,那么怎么将链路数据存储起来呢? Zipkin 支持将链路数据存储在MySQL、Elasticsearch和Cassandra数据库中。
使用Http传输链路数据,并存储在MySQL数据库中
只需要改造zipkin-server 工程。在zipkin-server工程的pom文件加上Zipkin Server 的依赖zipkin-server、Zipkin 的MySQL存储依赖zipkin-storage-mysql (这两个依赖的版本都为1.19.0)、 Zipkin Server 的UI界面依赖zipkin-autoconfigure-ui、MySQL的连接器依赖mysql-connector-java 和JDBC的起步依赖spring-boot- starter-jdbc。代码如下:
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eurekaartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-storage-mysqlartifactId>
<version>1.19.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
dependencies>
在zipkin-server工程的配置文件application.yml中加上数据源的配置,包括数据库的Url、用户名、密码和连接驱动,并且需要配置zipkin.storage.type为mysql,代码如下:
server:
port: 9411
spring:
application:
name: zipkin-server
# rabbitmq:
# host: localhost
# port: 5672
# username: guest
# password: guest
datasource:
url: jdbc:mysql://localhost:3306/zipkin?userUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
zipkin:
storage:
type: mysql
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
另外需要在MySQL数据库中初始化数据库脚本,数据库脚本地址为https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
--
-- Copyright 2015-2019 The OpenZipkin Authors
--
-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except
-- in compliance with the License. You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software distributed under the License
-- is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express
-- or implied. See the License for the specific language governing permissions and limitations under
-- the License.
--
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
最后需要在程序的启动类ZipkinServerApplication中注入MySQLStorage的Bean,代码如下:
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
// @EnableZipkinStreamServer
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
@Bean
public MySQLStorage mySQLStorage(DataSource dataSource) {
return MySQLStorage.builder()
.datasource(dataSource)
.executor(Runnable::run)
.build();
}
}