经过一个多月来的研究实践,在亲友团的帮助下,我的第一个spark程序终于上线了,程序虽然简单,但也是我今天在新领域的探索,从业来,第一次去把一个java的小项目推上线。今天抽时间复盘总结下过程。
关于hive和spark的基础介绍,网上的说明比较多,我这里就不说明了,只根据自身感悟说明吧。
背景
所有的技术都是为特定的业务服务的,spark也不例外。我也是碰到一个特定的场景,需要涉及单日大量的数据生成,然后处理,前期计算量比较大。想方案,当时依赖其他业务资源,有几种方法可以研究。
- 线上接口使用,我们用业务方的线上的接口,需要我们和业务方同时申请大规模资源,去做处理。
- 其他部门兄弟推荐访问离线数据表进行计算。这个得重点说下,通过了解,公司恰巧有大数据相关的业务,有些部门专门做过这些内容,所以我们通过 问询,可以作为客户端应用层,接入业务,当然相关的业务逻辑得我们自己完成。
通过调研,和资源评估成本等原因,我们决定使用离线的方式解决,这样在满足需求的同时,共用系统资源,最低使用成本。
hive
说到离线计算不得不说到hive sql。hive sql是个MapReduce的任务过程。我问了其他部门做过相关业务的同事,开通了权限,然后用hive sql执行了下对离线表的查询。发现生成数据的时间还可以接受,但数据需要落地,然后传输到我们自己的业务机上,再处理。这个过程就比较慢了,难以达到要求。
ps: 或许是使用的姿势不对吧,总之这次一些各种指标不达标,继续需求新的方案。
环境搭建
其他部门兄弟推荐,使用spark计算,然后介绍多么多么速度快,完全实现我们的需求没有问题,最关键能给我们找个顾问。以前是搞web应用服务的,对于离线计算的只是概念上,只存在几个帖子里和一些理论的知识。所以,我综合评估了下,决定尝试下看看。问了下“顾问”,他给我讲了一遍,于是我们的spark之旅开始了。项目参照他们的项目,简化结构。
spark程序开发主要有几种方式:
- Scala 语言是一门类 Java 的多范式语言,其设计初衷就是为了继承函数式编程的面向对象编程的各种特性,网上了例子我百分之六七十都是使用scala作为开发语言的,我买的书籍也是使用scala进行开发的。
- Java 语言,这个是参考的兄弟部门的项目例子使用的语言,网上的例子虽然很少,但相对于scala来说,根据以前的经验,我还是使用java作为开发主语言,出了问题,至少在java上可以请教相关经验丰富的同事。
- python 虽然以前在开发游戏的时候做过,但spark相关的开发,还没有进行过,这里暂时不考虑。
经过裁判,我决定跟同事的项目保持一致,使用java,学习成本低,可以快速参考实现。
我本地用的intellij idea 作为本地开发工具,采用maven管理相关的包。
java版本:
java -version
> java version "1.8.0_20"新建项目:
填写相关信息:
修改项目的pom.xml引入相关的依赖,主要是hive sql相关的部分。
...
2.2.1
compile
org.apache.hive
hive-exec
1.2.1
provided
org.apache.spark
spark-hive_2.11
${spark.version}
provided
org.apache.spark
spark-core_2.11
${spark.version}
${spark.scope}
org.apache.spark
spark-sql_2.11
${spark.version}
${spark.scope}
...初始化SparkSession
import org.apache.spark.sql.SparkSession;
SparkSession sparkSession = SparkSession.builder()
.config("hive.exec.scratchdir", "/user_ext/{username}/hive-{username}")
.config("spark.sql.warehouse.dir", "/user_ext/{username}/warehouse")
.appName("{Your app name}")
.enableHiveSupport()
.getOrCreate();创建临时表
本来想再hive里面进行数据查询的,不过最终还是找帖子在spark里面实现。
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.*;
// 以下是创建一个简单结构
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField( "demo_id", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "demo_name", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType(structFields);
// 添加数据
List rows = new ArrayList<>();
rows.add(RowFactory.create("demo_id", "demo_name"));
... // 可以添加多行
// 创建临时表
Dataset df = sparkSession.createDataFrame(rows, structType);
df.registerTempTable("tmp_demo");
至此,临时表创建完成,tmp_demo可直接参与查询了。
查询
关于查询,需要注意理解分区的含义。
在写查找离线表之前,你要问清楚你的数据表是怎么存储的,是否有按照实践分区的概念。我一开始不理解,一执行语句就挂住。后来问了下,得知这个表是一直按照时间进行存储的,使用的使用得使用最新的分区。
show partitions tableName 可以查找到所有的分区,选择最新的一个即可。
select * from tableName where dt={最新分区}以下是一个完整的实例:
sql = "select * from tmp_demo";
Dataset rets = spark.sql(sql);
List list = rets.collectAsList();
for (Row row: list) {
do some action...
}
注意:少量的数据可以使用collectAsList进行转换,但是大量的数据就得考虑用 mapPartition,或者foreachPatition进行遍历了。
具体内容可参考map,mapPartition,foreachPatition的比较。
踩过的坑
打包
对java项目不熟悉,什么又没有熟悉的同学,所以有几天卡在这个打包上。一开始我参照之前的例子,在Project Structure -> Artifacts 里面进行配置,然后在build -> build Artifacts 里面打包,生成的jar文件进行上传。
! 注意:上面这是一种错误的打包方式。我将 output 的jar包上传后,一直报告找不到类的错误。

当然网上还有一种错误,就是main所在的类用的路径在 spark-submit 的参数中没有加上。
正确的打包方式,应该选用右侧的maven projects方式进行,
这样在 target 目录下生成的.jar 文件就没有问题了。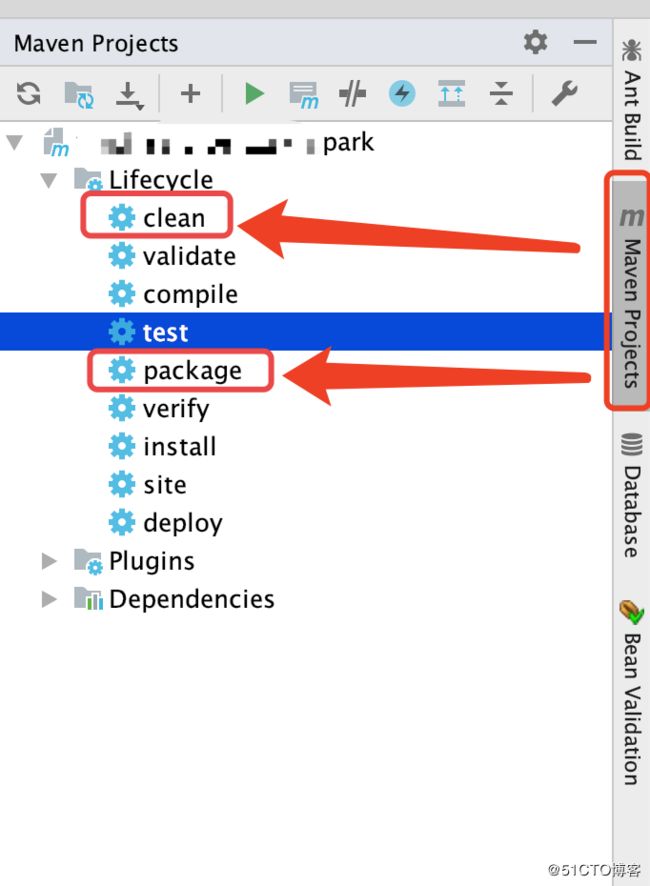
上传
因为是传到远端服务器上的jar包,所以决定上传的效率有两个。
- jar包的大小,我选择最小的引入,能省略的省略。
- 传输媒介的速率,这个最好选择内网有线,比无线强太多了。
foreachPatition的日志
使用foreachPatition,在参数的地方使用new ForeachPartitionFunction进行处理。
在Call函数里面的日志,一般是在类似子任务里面,在这里我调试了数次,找了半天我的日志在哪里打印。
执行命令
最后执行一定落实到下面的命令上,此时 --class的参数一定要包含你的main函数,对应的包名。
spark-submit --master yarn --deploy-mode cluster ... --class package1.package2.classname demo.jar开始执行,等待分配资源
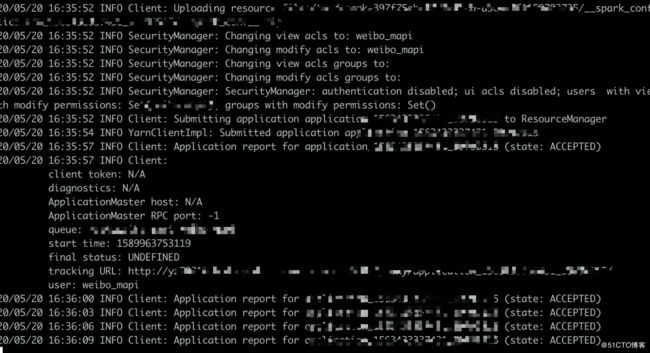
执行中
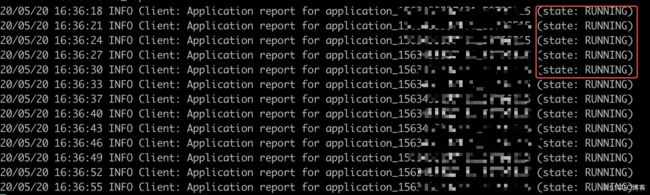
程序执行完结果

总结
为了这次的尝试,我基本上把网上的例子翻遍了,发现有很多是基于scala的,看来scala是大趋势。同时相关的靠谱的帖子少于其他话题的,
估计搞大数据的相关的人还是相对搞应用的不太多吧。推荐本书《Spark大数据分析 源码解析与实例详解》,对理解spark相关的知识很有帮助。
最后,欢迎有兴趣的朋友一起讨论啊。