0x00 概述
关于如何搭建ELK部分,请参考这篇文章,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html。
该篇用户为非root,使用用户为“elk”。
基于以前ELK架构的基础,结合Kafka队列,实现了ELK+Kafka集群,整体架构如下:
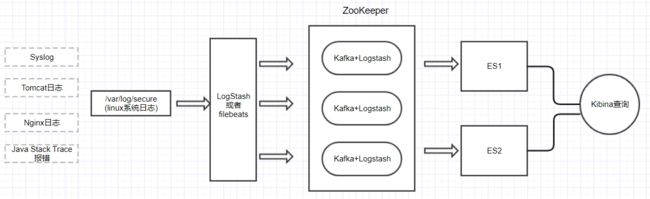
# 1. 两台es组成es集群;( 以下对elasticsearch简称es ) # 2. 中间三台服务器就是我的kafka(zookeeper)集群啦; 上面写的 消费者/生产者 这是kafka(zookeeper)中的概念; # 3. 最后面的就是一大堆的生产服务器啦,上面使用的是logstash,当然除了logstash也可以使用其他的工具来收集你的应用程序的日志,例如:Flume,Scribe,Rsyslog,Scripts……
# 双ES备份集群: CentOS1+CentOS2
# Kafka+LogStash集群:CentOS3+CentOS4+CentOS5
# ES-Header+Kibina+LogStash/Beats采集:CentOS6+CentOS7
# 注意!!由于测试环境限制,此篇博客中CentOS6+CentOS7的内容放到CentOS1+CentOS2中的

使用软件:
# Elasticsearch 6.2.4 # Kibana 6.2.4 # Logstash 6.2.4 # elasticsearch-head(从github直接clone) # filebeat 6.2.4 (本篇文章使用Logstash做搜集用,可以用filebeat替换Logstash) # phantomjs-2.1.1-linux-x84_64 (配合npm指令使用) # node-v4.9.1-linux-x64 (记住文件夹路径,需要增加到bash_profile中) # kafka_2.11-1.0.0 (该版本已经包含ZooKeeper服务)
部署步骤:
# ES集群安装配置; # Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志); # Kafka(zookeeper)集群配置;(Logstash写入数据到Kafka消息系统);
0x01 ES集群安装配置
ES安装请参考这里,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html;
1. 下面修改ES的配置文件:

# 确保下列参数被正确设置: cluster.name: logger # ES集群的名字 node.name: node-1 path.data: /usr/local/app/elasticsearch-6.2.4/data path.logs: /usr/local/app/elasticsearch-6.2.4/log bootstrap.memory_lock: false # 对于非专用ES,建议设置为false,默认为true bootstrap.system_call_filter: false network.host: 0.0.0.0 # 支持远程访问 http.port: 9200 # restful api访问接口 http.cors.enabled: true #允许ES head跨域访问 http.cors.allow-origin: "*" #允许ES head跨域访问
2. 获取es服务管理脚本
[ root @ elk ~ ] # git clone https://github.com/elastic/elasticsearch-servicewrapper.git [ root @ elk ~ ] # mv elasticsearch-servicewrapper/service /usr/local/elasticsearch/bin/ [ root @ elk ~ ] # /usr/local/elasticsearch/bin/service/elasticsearch install Detected RHEL or Fedora : Installing the Elasticsearch daemon . . [ root @ elk ~ ] # #这时就会在/etc/init.d/目录下安装上es的管理脚本啦 #修改其配置: [ root @ elk ~ ] # set . default . ES_HOME = /usr/local/app/elasticsearch-6.2.4 #安装路径 set . default . ES_HEAP_SIZE = 1024 #jvm内存大小,根据实际环境调整即可
3. 启动es ,并检查其服务是否正常
[ root @ elk ~ ] # netstat -nlpt | grep -E "9200|"9300 tcp 0 0 0.0.0.0 : 9200 0.0.0.0 : * LISTEN 1684/ java tcp 0 0 0.0.0.0 : 9300 0.0.0.0 : * LISTEN 1684/ java
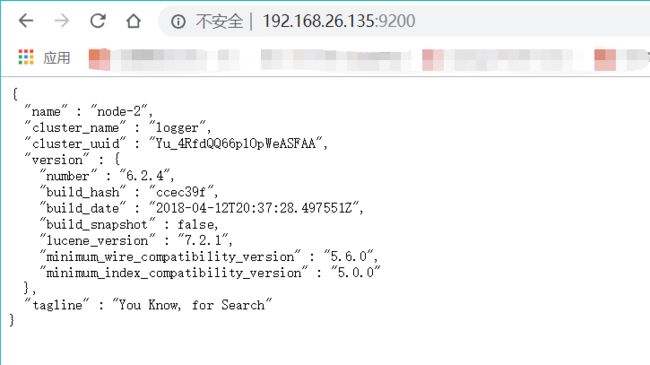
访问http://192.168.26.135:9200/ 如果出现以下提示信息说明安装配置完成
4. es1节点已经设置好,我们直接把目录复制到es2
[ root @ elk ] # scp -r elasticsearch-6.2.4 192.168.26.136:/usr/local/app [ root @ elk ] # elasticsearch/bin/service/elasticsearch install #es2只需要修改node.name(此处使用的是node-2和node-1)即可,其他都与es1相同配置
5. 安装es的管理插件elasticsearch-head
es-head安装,请参考这里,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html。
安装好之后,访问方式为:http://192.168.26.135:9100/


到此,ES集群的部署完成。
0x02 Logstash客户端安装配置
LogStash安装请参考这里,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html;
# Logstach需要搭配指定的配置文件启动,创建一个logstash配置文件,比如logstash-es.conf,启动LogStash时候使用;根据不同的配置文件,LogStash会做不同工作。
1. 通过stdin标准实时输入的方式向Logstash向es集群写数据(测试,暂未通过Kafka队列传递)
1.1 使用如下命令创建LogStash启动配置文件
# cd /usr/local/app/logstash-6.2.4/config # touch logstash_for_stdin.conf
# [elk@localhost config]$ vim logstash_for_stdin.conf
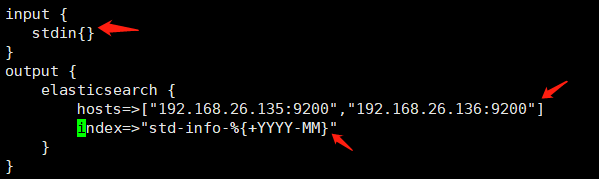
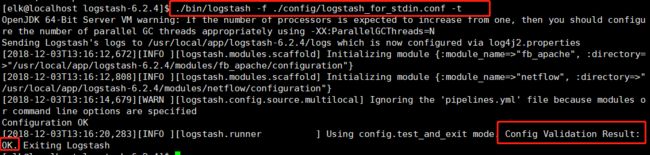
1.2 检查配置文件是否有语法错(如下 -t 为测试命令)
# [elk@localhost logstash-6.2.4]$ ./bin/logstash -f ./config/logstash_for_stdin.conf -t
1.3 启动 Logstash,开始写入操作
# [elk@localhost logstash-6.2.4]$ ./bin/logstash -f ./config/logstash_for_stdin.conf
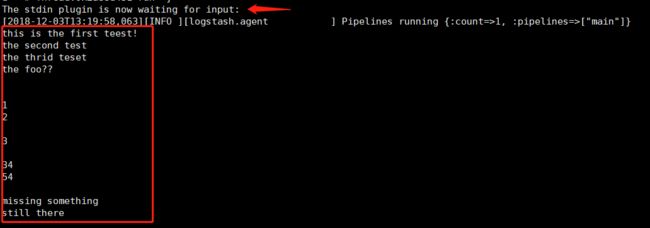
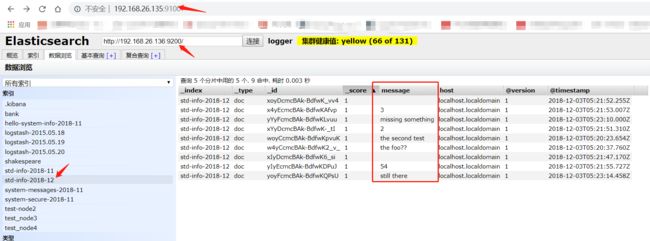
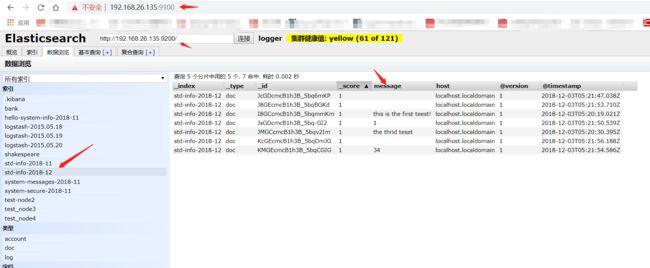
以上是输入数据,从ES-Header(192.168.26.135:9200)插件就可以看到,数据已经分散的写入到两个集群内
ES Server:192.168.26.136
ES Server:192.168.26.135
2. 通过采集制定文件的输入的方式向Logstash向es集群写数据(测试,暂未通过Kafka队列传递)
2.1首先创建一个用于采集系统日志的LogStash启动的conf文件,使用如下命令
# cd /usr/local/app/logstash-6.2.4/config # touch logstash_for_system_messages.conf
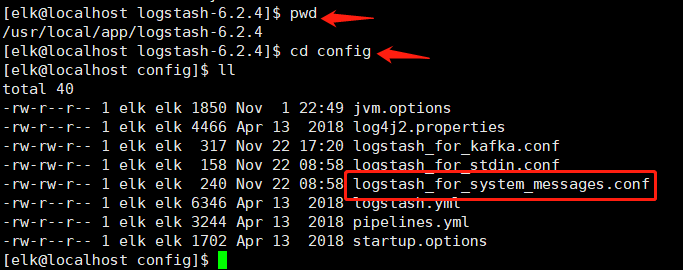
2.2 编辑logstash_for_system_messages.conf文件
# [elk@localhost config]$ vim logstash_for_system_messages.conf
input { file{ path => "/var/log/messages" #这是日志文件的绝对路径 start_position=>"beginning" #这个表示从 messages 的第一行读取,即文件开始处 } } output { #输出到 es elasticsearch { #这里将按照这个索引格式来创建索引 hosts=>["192.168.26.135:9200","192.168.26.136:9200"] index=>"system-messages-%{+YYYY-MM}" } }
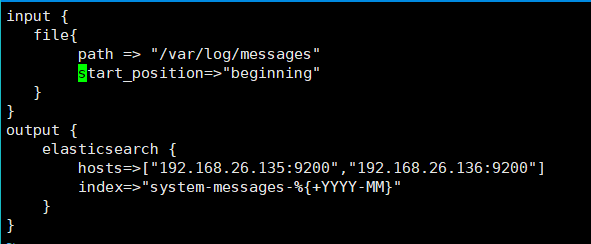
2.3 测试ogstash_for_system_messages.conf文件
# [elk@localhost logstash-6.2.4]$ ./bin/logstash -f ./config/logstash_for_system_messages.conf -t
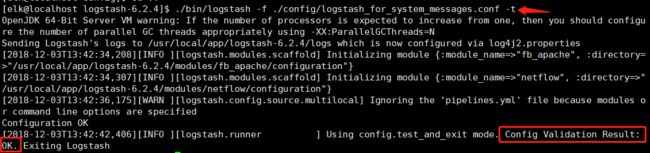
2.4 启动LogStash,开始采集系统日志
# 注意,系统日志需要权限,命令行前面使用 sudo
# [elk@localhost logstash-6.2.4]$ sudo ./bin/logstash -f ./config/logstash_for_system_messages.conf


ES Server: 192.168.26.136
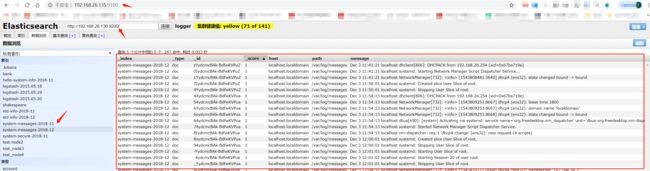
ES Server: 192.168.26.135
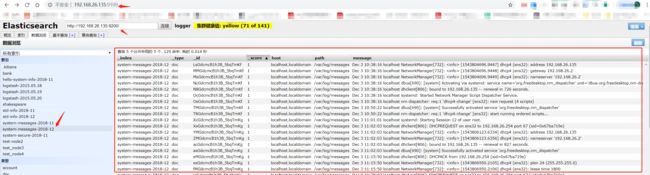
系统日志我们已经成功的收集,并且已经写入到es集群中.
上面的演示是logstash直接将日志写入到es集群中的,这种场合我觉得如果量不是很大的话直接像上面已将将输出output定义到es集群即可.
如果量大的话需要加上消息队列Kafka来缓解es集群的压力,下面就在三台server上面安装kafka集群。
0x03 Kafka集群安装配置1
本篇博客使用的Kafka版本为
# kafka_2.11-1.0.0 (该版本已经包含ZooKeeper服务)
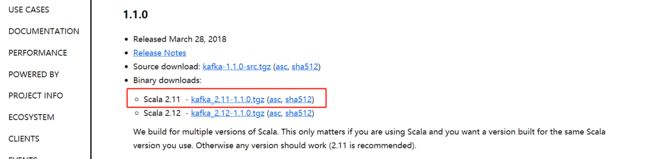
1. 从官网获取装包,https://kafka.apache.org/downloads
2. 配置Zookeeper集群,修改配置文件
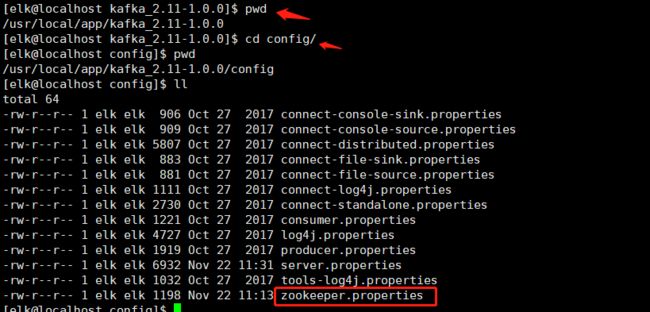
# [elk@localhost config]$ vim zookeeper.properties
修改内容如下:
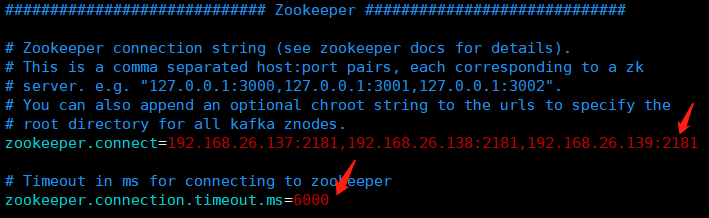
dataDir=/usr/local/app/kafka_2.11-1.0.0/zookeeperDir # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=1024 tickTime=2000 initLimit=20 syncLimit=10 server.2=192.168.26.137:2888:3888 server.3=192.168.26.138:2888:3888 server.4=192.168.26.139:2888:3888
# 说明: tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口; 3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。
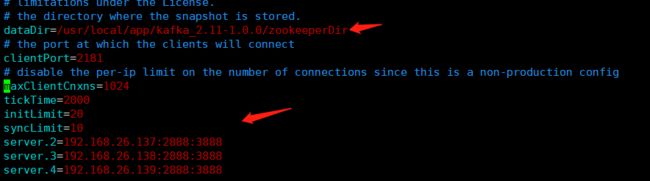
3. 创建Zookeeper所需的目录
进入Kafka目录内
![]()
创建目录zookeeperDir
# [elk@localhost kafka_2.11-1.0.0]$ mkdir zookeeperDir
# [elk@localhost kafka_2.11-1.0.0]$ cd zookeeperDir
在zookeeperDir目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的
# [elk@localhost zookeeperDir]$ touch myid
命名myid
# [elk@localhost zookeeperDir]$ echo 2 > myid
以上就是zookeeper集群的配置,下面等我配置好kafka之后直接复制到其他两个节点即可
4. Kafka配置
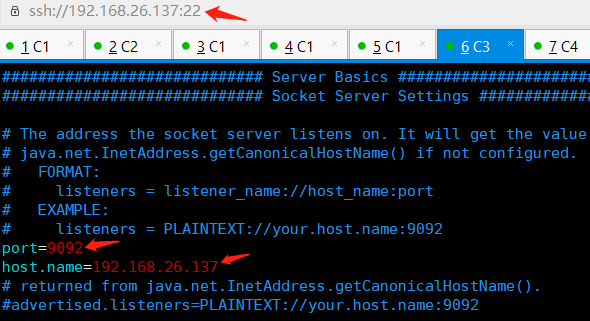
修改内容如下
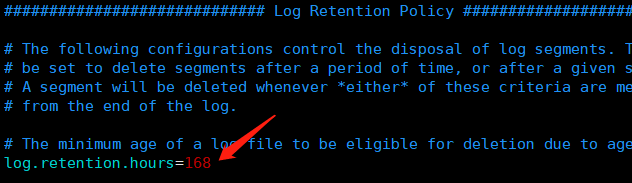
broker . id = 2 # 唯一,填数字,本文中分别为 2 / 3 / 4 prot = 9092 # 这个 broker 监听的端口 host . name = 192.168.2.22 # 唯一,填服务器 IP log . dir = / data / kafka - logs # 该目录可以不用提前创建,在启动时自己会创建 zookeeper . connect = 192.168.2.22 : 2181 , 192.168.2.23 : 2181 , 192.168.2.24 :2181 # 这个就是 zookeeper 的 ip 及端口 num . partitions = 16 # 需要配置较大 分片影响读写速度 log . dirs = / data / kafka - logs # 数据目录也要单独配置磁盘较大的地方 log . retention . hours = 168 # 时间按需求保留过期时间 避免磁盘满
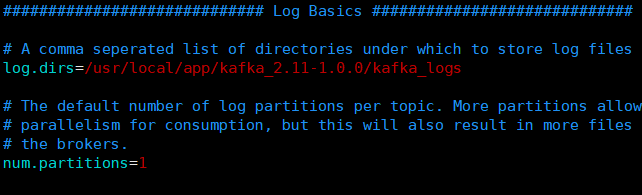
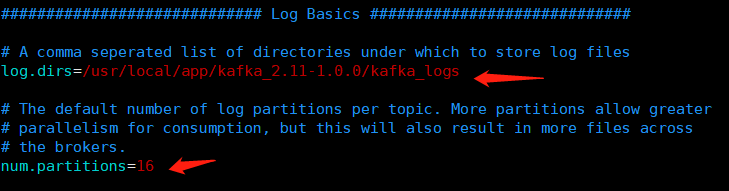
5. 将kafka(zookeeper)的程序目录全部拷贝至其他两个节点
# [elk@localhost app]$ scp kafka_2.11-1.0.0 192.168.26.138:/usr/local/app/ # [elk@localhost app]$ scp kafka_2.11-1.0.0 192.168.26.139:/usr/local/app/
6. 修改两个节点的配置,注意这里除了以下两点不同外,都是相同的配置
# zookeeper 的配置 mkdir zookeeperDir echo "x" > zookeeperDir/myid # “x”这里是3或者4,前面已经使用过2了 # kafka 的配置 broker.id = x # “x”这里是3或者4,前面已经使用过2了 host.name = 192.168.26.137 # ip改为26.138或者26.139
7. 修改完毕配置之后我们就可以启动了,这里先要启动zookeeper集群,才能启动kafka
我们按照顺序来,kafka1 –> kafka2 –>kafka3
# [elk@localhost kafka_2.11-1.0.0]$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties & #zookeeper启动命令 # [elk@localhost kafka_2.11-1.0.0]$ ./bin/zookeeper-server-stop.sh #zookeeper停止的命令
注意,如果zookeeper有问题 nohup的日志文件会非常大,把磁盘占满,这个zookeeper服务可以通过自己些服务脚本来管理服务的启动与关闭。
后面两台执行相同操作,在启动过程当中会出现以下报错信息
[2018-12-03 15:06:02,089] WARN Cannot open channel to 4 at election address /192.168.26.139:3888 (org.apache.zookeeper.server.quorum.QuorumCnxManager) java.net.ConnectException: Connection refused (Connection refused) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:562) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:614) at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:843) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:913)
由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他节点也可能会出现类似的情况,属于正常。
8. Zookeeper服务检查
在Kafka三台Server上执行如下命令
# netstat -nlpt | grep -E "2181|2888|3888"
显示如下端口和信息,说明Zookeeper运行正常
[elk@localhost ~]$ netstat -nlpt | grep -E "2181|2888|3888" (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 :::2181 :::* LISTEN 5465/java tcp6 0 0 192.168.26.139:3888 :::* LISTEN 5465/java
可以看出,如果哪台是Leader,那么它就拥有2888这个端口
[elk@localhost ~]$ netstat -nlpt | grep -E "2181|2888|3888" (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 :::2181 :::* LISTEN 5434/java tcp6 0 0 192.168.26.138:2888 :::* LISTEN 5434/java tcp6 0 0 192.168.26.138:3888 :::* LISTEN 5434/java
9. 启动Kafka服务
这时候zookeeper集群已经启动起来了,下面启动kafka,也是依次按照顺序启动,kafka1 –> kafka2 –>kafka3
# [elk@localhost kafka_2.11-1.0.0]$ pwd # /usr/local/app/kafka_2.11-1.0.0 # [elk@localhost kafka_2.11-1.0.0]$ ./bin/kafka-server-start.sh ./config/server.properties & #启动Kafka服务
# [elk@localhost kafka_2.11-1.0.0]$ ./bin/kafka-server-stop.sh # 停止Kafka服务
10. 此时三台上面的zookeeper及kafka都已经启动完毕,下面来测试一下
10.1 建立一个主题(在Kafka Server 192.168.26.137)

# 注意:factor大小不能超过broker的个数
# ./bin/kafka-topics.sh --create --zookeeper 192.168.26.137:2181 --replication-factor 3 --partitions 1 --topic test1test2test
10.2 查看已经创建的topics(Kafka Server :192.168.26.137)
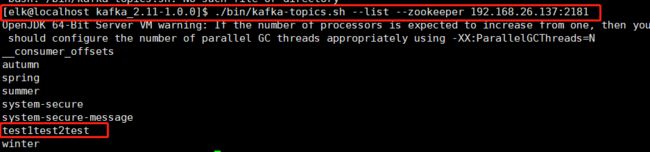
# ./bin/kafka-topics.sh --list --zookeeper 192.168.26.137:2181
10.3 查看test1test2test这个主题的详情(Kafka Server :192.168.26.137)

#主题名称:test1test2test #Partition:只有一个,从0开始 #leader :id为4的broker #Replicas 副本存在于broker id为2,3,4的上面 #Isr:活跃状态的broker
10.4 发送消息,这里使用的是生产者角色(Kafka Server :192.168.26.137)

# ./bin/kafka-console-producer.sh --broker-list 192.168.26.137:9092 --topic test1test2test
10.5 接收消息,这里使用的是消费者角色(更换到另外一台KafkaServer上运行,Kafka Server :192.168.26.138)
消息已经显示出来了。
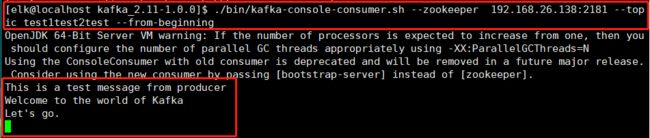
# ./bin/kafka-console-consumer.sh --zookeeper 192.168.26.138:2181 --topic test1test2test --from-beginning
以上是Kafka生产者和消费者的测试,基于Kafka的Zookeeper集群就成功了。
11. 下面我们将ES Server:192.168.26.135上面的logstash的输出改到kafka上面,将数据写入到kafka中
11.1 创建LogStash结合Kafka使用的.conf文件,注意文件目录
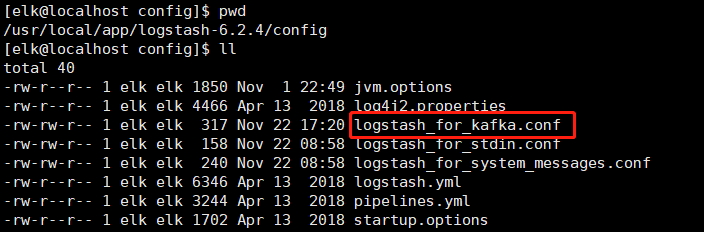
11.2 编辑输入到Kafka的.conf文件
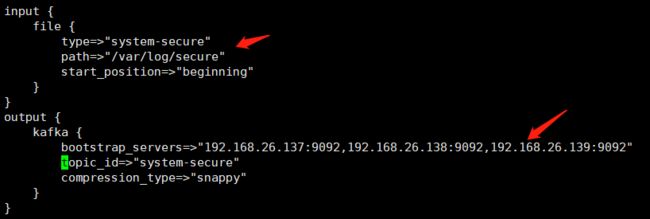
# vim logstash_for_kafka.conf
input { #这里的输入还是定义的是从日志文件输入
file {
type = > "system-message"
path = > "/var/log/messages"
start_position = > "beginning"
}
}
output { #stdout { codec => rubydebug } #这是标准输出到终端,可以用于调试看有没有输出,注意输出的方向可以有多个
kafka { #输出到kafka
bootstrap_servers = >
"192.168.26.137:9092,192.168.26.138:9092,192.168.26.139:9092" #他们就是生产者
topic_id = > "system-secure" #这个将作为主题的名称,将会自动创建
compression_type = > "snappy" #压缩类型
}
}
11.3 测试输入到Kafka的配置文件
![]()
![]()
# [elk@localhost logstash-6.2.4]$ ./bin/logstash -f ./config/logstash_for_kafka.conf -t
11.4 使用该配置文件启动LogStash
注意采集系统日志需要权限,命令行前面必须加sudo
![]()
# [elk@localhost logstash-6.2.4]$ sudo ./bin/logstash -f ./config/logstash_for_kafka.conf
11.5 验证数据是否写入到kafka,这里我们检查是否生成了一个叫system-secure的主题
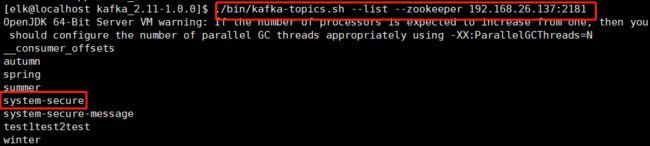
# [elk@localhost kafka_2.11-1.0.0]$ ./bin/kafka-topics.sh --list --zookeeper 192.168.26.137:2181
11.6 查看system-secure详情

# [elk@localhost kafka_2.11-1.0.0]$ ./bin/kafka-topics.sh --describe --zookeeper 192.168.26.137:2181 --topic system-secure
11.7 对于logstash输出的我们也可以提前先定义主题,然后启动logstash 直接往定义好的主题写数据就行啦,命令如下:
#[elk@localhost kafka_2.11-1.0.0]$ ./bin/kafka-topics.sh --create --zookeeper 192.168.26.137:2181 --replication-factor 3 --partitions 3 --topic TOPIC_NAME
好了,我们将logstash收集到的数据写入到了kafka中了,在实验过程中我使用while脚本测试了如果不断的往kafka写数据的同时停掉两个节点,数据写入没有任何问题。
0x04 Kafka集群安装配置2
那如何将数据从kafka中读取然后给ES集群呢?
那下面我们在kafka集群上安装Logstash,可以通过上面的方法,先配置一台的logstash,然后通过scp命令通过网络拷贝,安装路径是“/usr/local/app/logstash-6.2.4”;
三台上面的logstash的配置如下,作用是将kafka集群的数据读取然后转交给es集群,这里为了测试我让他新建一个索引文件,注意这里的输入日志是secure,主题名称是“system-secure”;
1. 如上所说,在三台Kafka集群的Server上分别安装LogStash,并在如下目录新建logstash_kafka2ES.conf

2. 配置logstash_kafka2ES.conf
# [elk@localhost config]$ vim logstash_kafka2ES.conf

3. 在三台Kafka Server上按顺序分别启动LogStash,启动命令三台是通用的

# [elk@localhost logstash-6.2.4]$ ./bin/logstash -f ./config/logstash_kafka2ES.conf
4. 测试通过Kafka队列传递消息到ES集群
在ES Server:192.168.26.135上写入测试内容,利用secure这个文件来测试

可以看到消息已经分散的写入ES及集群中
ES Server 192.168.26.135
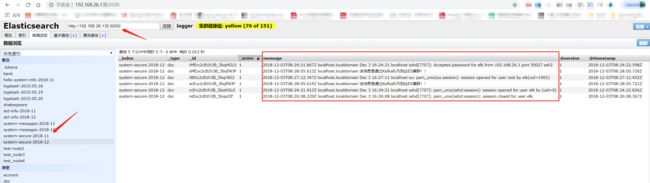
ES Server 192.168.26.136

0x05 在Kibana中展示
ELK中的Kibana中的使用和部署,请看这篇文章 https://www.cnblogs.com/JetpropelledSnake/p/9893566.html
1. 根据ES集群中存入的数据,在Kibana中建立Index
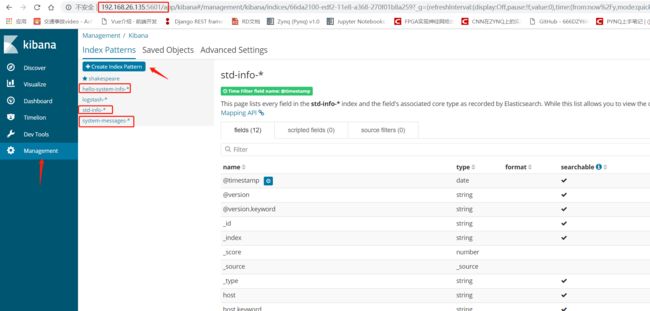
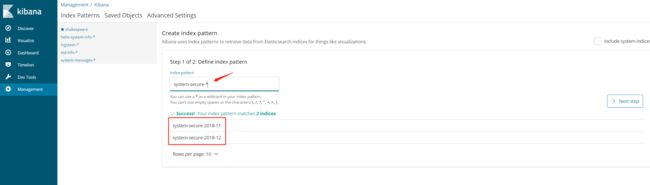
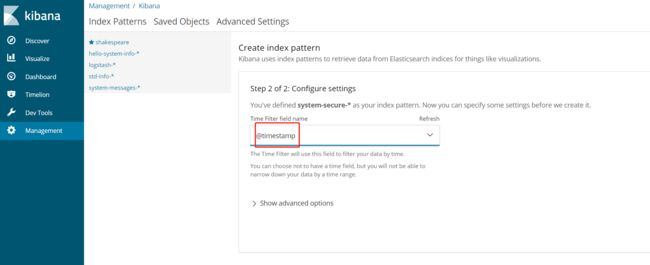
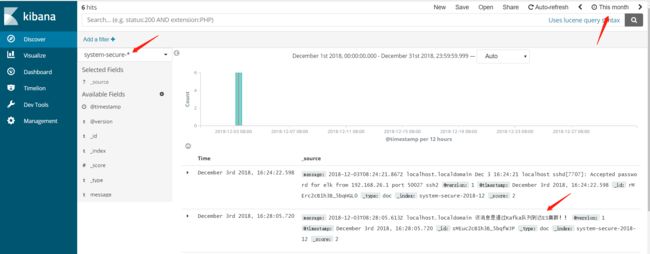
2. 建立好index后,就可以在Discover这里查询介入的数据了
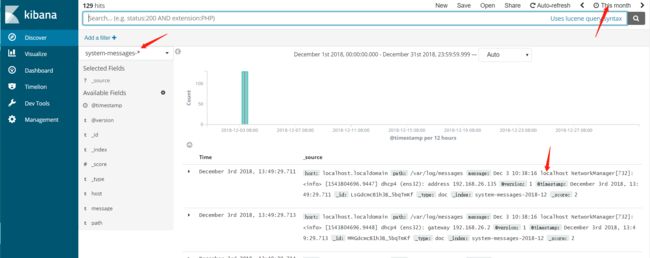
3. ES集群采用的查询语言是DSL语言,该语言采用json的格式组织查询语句。
4. Kibana可以多样化展示ES集群中介入的数据,github上有很多定制好的格式,针对常见生产环境可以直接配置,十分方便。