混淆矩阵、ROC、AUC
主要内容
(1)混淆矩阵(主要指标)
(2)绘制ROC
(3)AUC
(4)多分类
-------------------------------------------------------------------------------------------------------------------------
一、混淆矩阵
| 样本 | 预测值 | ||
| 1 | 0 | ||
| 实际值 | 1 | TP(真正) | FN(假负) |
| 0 | FP(假正) | TN(真负) | |
TP(真正)True Positive:实际为正,预测为正
FP(假正)False Positive:实际为负,预测为正
FN(假负)False Negative:实际为正,预测为负
TN(真负)True Negative:实际为负,预测为负
主要指标计算(另外还有其余指标):
真正类率:Sensitive or True Positive Rate(TPR)= TP/(TP+FN)【击中率】
假真类率:Fall-out or False Positive Rate(FPR)= FP/(FP+TN)【错误报警率】
真负类率:TNR = TN/(FP+TN) = 1 - FPR
准确率:Accuracy(ACC) = (TP+TN)/(P+N) = (TP+TN)/(TP+FP+FN+TN)
精确率(就预测结果而言):Precision = TP/(TP+FP)
召回率(就原来样本而言):Recall = TP/(TP+FN)
调和平均值 F1 = 2*P*R/(P+R)
二、ROC曲线绘制
ROC曲线(receiver operating characteristic curve),又称为感受性曲线(sensitivity curve),如下图所示。
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,在此引入ROC,ROC曲线可以用于评价一个分类器。
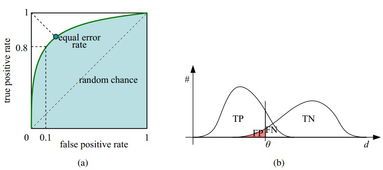
(a)ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。
比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)
(b)随着阈值theta增加,TP和FP都减小,TPR和FPR也减小,ROC点向左下移动;
那么,ROC曲线如何绘制呢?
参照网上一个例子来说

这张表共20个样本,实际数据有10个p(正例),10个n(反例),Score代表正例的概率(通过模型得到,例如RF等),对这个概率进行降序排列,即最可能为正样本的排在前面。但至于这个样本是否是正例,需要将score与分类阈值进行比较,若大于这个阈值,则为正例,反之为反例,接着对混淆矩阵进行计算。
下面共列举3个场景说明如何画出ROC曲线点。
(1)场景一:假设设定的阈值为0.9(即大于或等于0.9,预测为正;小于0.9,预测为负)
下面计算混淆矩阵:对于10个实际为正的,1个预测为正,9个预测为负;对于10个实际为负的,0个预测为正,10个预测为负。混淆矩阵如下:
| 样本 |
预测值 |
||
| p |
n |
||
| 实际值 |
p |
1 |
9 |
| n |
0 |
10 |
|
TPR = TP/(TP+FN) = 1/(1+9) = 0.1
FPR = FP/(FP+TN) = 0/(0+10) = 0
即该点在ROC曲线坐标下为(0,0.1)
(2)场景二:假设设定的阈值为0.8(即大于或等于0.8,预测为正;小于0.8,预测为负)
下面计算混淆矩阵:对于10个实际为正的,2个预测为正,8个预测为负;对于10个实际为负的,0个预测为正,10个预测为负。混淆矩阵如下:
| 样本 |
预测值 |
||
| p |
n |
||
| 实际值 |
p |
2 |
8 |
| n |
0 |
10 |
|
TPR = TP/(TP+FN) = 2/(2+8) = 0.2
FPR = FP/(FP+TN) = 0/(0+10) = 0
即该点在ROC曲线坐标下为(0,0.2)
(3)场景三:假设设定的阈值为0.7(即大于或等于0.7,预测为正;小于0.7,预测为负)
下面计算混淆矩阵:对于10个实际为正的,2个预测为正,8个预测为负;对于10个实际为负的,1个预测为正,9个预测为负。混淆矩阵如下:
| 样本 |
预测值 |
||
| p |
n |
||
| 实际值 |
p |
2 |
8 |
| n |
1 |
9 |
|
TPR = TP/(TP+FN) = 2/(2+8) = 0.2
FPR = FP/(FP+TN) = 1/(1+9) = 0.1
即该点在ROC曲线坐标下为(0.1,0.2)
以下计算按照上面步骤进行,直至完成,结果如下图所示
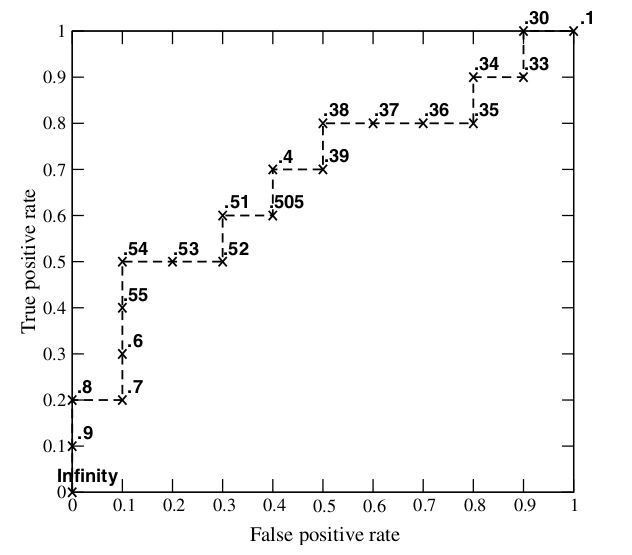
其中,X轴为FPR,Y轴为TPR,当图中的点(threshold)的个数越多,曲线越平滑。
三、AUC值
AUC值就是ROC曲线下方的面积(计算方法即每个点的对应的梯形面积)
四、多分类
以上所述的为二分类的P值,R值,F1值的计算以及ROC曲线的画法,对于多分类问题,我们该如何解决呢?
下面举例说明:
场景:假设一共五个样本,共三类,如下所示
| 实际值 | 预测值 |
| 0 | 0 |
| 1 | 0 |
| 2 | 2 |
| 2 | 2 |
| 2 | 1 |
其结果如下
| precision | recall | f1-score | support | |
| 0 | 0.50 | 1.00 | 0.67 | 1 |
| 1 | 0.00 | 0.00 | 0.00 | 1 |
| 2 | 1.00 | 0.67 | 0.80 | 3 |
| avg/total | 0.70 | 0.600 | 0.61 | 5 |
拿实际值为2的来看,其余以此类推
实际值为2的样本共有3个,则认为2为正例,0和1为负例。其中2个被预测正确,一个预测错误,无负例被预测为正例,建立混淆矩阵如下:
| 样本 |
预测值 |
||
| p(2) |
n(0,1) |
||
| 实际值 |
p(2) |
2 |
1 |
| n(0,1) |
0 |
2 |
|
在此基础上,计算得到:
P = 2/(2+0) = 1.00
R = 2/(2+1) = 0.67
F1 = 2*1.00*0.67/(1+0.67) = 0.80
对于avg是通过加权平均得到的,结果如下:
avg(P) = (0.50*1+1.00*3)/5 = 0.70
avg(R) = (1.00*1+0.67*3)/5 = 0.60
avg(F1) = (0.67*1+0.80*3)/5 = 0.61
那么ROC曲线该如何画呢?
对于测试样本m,共有n个类别。(通过模型训练完后,会得到每个样本在各个类别下的概率,也就是score),接着按类别进行排序,并转换为哑变量(二进制),如下所示(假设n=3)
[ 0 => 100 ; 1 => 010 ; 2 => 001 ]
方法一:对哑变量的每一列进行计算FPR和TPR,那么可以得到3条不同的ROC曲线,再对其去平均值,画出最终的ROC曲线(略)。
方法二:
正样本M个,负样本N个,做交叉,总共会产生M*N个样本对,统计一下在这些样本对中有多少正样本的score大于负样本的score,例如有K对,那么AUC的值就是K/(M*N)
举例说明一下:
样本:y=1,y = 1, y=1, y = -1, y = -1, y = -1
模型1的预测:0.8,0.7,0.3,0.5,0.6,0.9
模型2的预测:0.1, 0.8, 0.9, 0.5, 0.85, 0.2
模型1:正样本score大于负样的对包括(y1,y4)(y1,y5)(y2,y4)(y2,y5)。所以AUC值为4/9
模型2:正样本score大于负样本的对包括(y2,y4)(y2,y6)(y3,y4)(y3,y5)(y3,y6)。所以AUC的值为5/9
五、关键问题
(1)样本数量与threshold不是一个概念。样本量对应的score未出现重复时,样本量与threshold数量保持一致。
(2)当ROC曲线出现斜线时,即相对于上一个阈值,FPR和TPR同时增大。
(3)即使数据很大,ROC曲线也会出现不平滑。