T-Statistic、T-test、p-value、Standard Error、Standard Deviation及三大抽样分布:卡方分布,t分布和F分布
https://blog.csdn.net/anshuai_aw1/article/details/82735201#1%C2%A0%E5%8D%A1%E6%96%B9%E5%88%86%E5%B8%83%EF%BC%88%E5%88%86%E5%B8%83%EF%BC%89
Standard Error标准误,Standard Deviation标准差,这两者的概念是不同的。
T统计量与标准误(Standard Error)之间存在反比关系,见以下公式:
T-Statistic=某平均值 / 标准误
标准误=标准差 / 样本量的开平方
当然,T统计量与标准差(Standard Deviation)之间也同样存在反比关系。
实际上T-Statistic中的平均值指的是平均差值之类的概念,有单样本t检验和双样本t检验之分,具体如下。
单样本t检验:T-Statistic=(样本平均值 - 靶值)/ 标准误
靶值就是你想要与你的样本均值相比较的数值,例如自己预测出的值或者需要检验的值。
双样本t检验:T-Statistic=(样本1的平均值 - 样本2的平均值)/ 标准误
T-statistic用于检验差异是否有显著性,其数值大小不存在好坏之分,具体意义如下。
在单样本t检验中,T-statistic的绝对值越大,则样本平均值偏离靶值越远,也就是样本平均值与靶值有显著差异的概率越大。
在双样本t检验中,T-statistic的绝对值越大,则两组样本平均值的差距越大,也就是两组样本平均值有显著差异的概率越大。T-test:
T-test是指用T-statistic来做假设检验(hypothesis testing),而T-statistic是根据model计算的,用来做检验的统计量.
正常T-statistic应该在0假设(null hypothesis)为真时,服从T分布(T-distribution).
T-test时根据T-statistic值的大小计算p-value,决定是接受还是拒绝假设.
T统计量:
用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。
意义:
t统计量分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。
在概率论和统计学中,学生t-分布(Student's t-distribution)经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t测定的基础。t检定改进了Z检定(en:Z-test),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但Z检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t检定。
由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t 值的分布称为t分布。
图像:
1.以0为中心,左右对称的单峰分布;
2.t分布是一簇曲线,其形态变化与n(确切地说与自由度df)大小有关。自由度df越小,t分布曲线越低平;自由度df越大,t分布曲线越接近标准正态分布(u分布)曲线
计算:
假设X服从标准正态分布N(0,1),Y服从![]() 分布,那么
分布,那么![]() 的分布称为自由度为n的t分布,记为
的分布称为自由度为n的t分布,记为![]() 。
。
分布密度函数
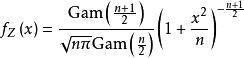 ,
,
其中,Gam(x)为伽马函数。
ps.
正态分布(normal distribution)是数理统计中的一种重要的理论分布,是许多统计方法的理论基础。正态分布有两个参数,μ和σ,决定了正态分布的位置和形态。为了应用方便,常将一般的正态变量X通过u变换[(X-μ)/σ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为μ=0,σ=1的标准正态分布(standard normal distribution),亦称u分布。
P-value:
https://blog.csdn.net/u011331731/article/details/72858416
F-statisitc(见《handbook of fMRI附录一》,待理解):
https://wenku.baidu.com/view/726bfc9d0408763231126edb6f1aff00bfd5707e.html
多元线性回归模型的F检验:
https://www.cnblogs.com/wmn7q/p/7265548.html
https://blog.csdn.net/xuxiatian/article/details/55047998
http://www.dataguru.cn/thread-615908-1-1.html
F检验主要是检验因变量同多个自变量的整体线性关系是否显著,在k个自变量中,只要有一个自变量同因变量的线性关系显著,t检验则是对每个回归系数分别进行单独的检验,以判断每个自变量对因变量的影响是否显著。
F检验 对于多元线性回归模型,在对每个回归系数进行显著性检验之前,应该对回归模型的整体做显著性检验。这就是F检验。当检验被解释变量yt与一组解释变量x1, x2 , ... , xk -1是否存在回归关系时,给出的零假设与备择假设分别是
H0:b1 = b2 = ... = bk-1 = 0 ,
H1:bi, i = 1, ..., k -1不全为零。
首先要构造F统计量。总平方和(SST)可分解为回归平方和(SSR)与残差平方和(SSE)两部分。与这种分解相对应,相应自由度也可以被分解为两部分。