大数据学习之路(一)MapReduce
本人某二本计科大三狗一只,自知高中不努力,大学图悲伤,前两年多发奋努力嵌入式,取得一些成果,最终发现还是喜欢大数据,选择了走向大数据的道路。
大数据学习任重而道远,需要学习的东西很多。
比如语言,Java,Scala,python,shell,甚至需要C,C++,头大中。
框架则更多,Hadoop,mapreduce,HDFS,yarn,spark,storm,zookeeper等等。
数据库,redis,MySQL,hive,bhase等。
还要会Linux基本命令。
后悔没有更早的开始大数据之路,二本计科狗,为了得到更好的机会,还需要数据结构(leetcode)
嗯,开始。
开始之前,需要一台搭建好分布式或者伪分布式的电脑(当然,配置越高越好),本狗自己电脑安装有centos7.0的虚拟机三台,分别为master节点和两个slave节点。本狗会从每一个框架的原理开始分析,今天开始Hadoop、mapreduce的过程。
每一部分会分两个阶段,分别会用代码复杂但是速度快的Java(框架的实现语言是Java)和代码结构简单速度还阔以的python(有一个叫做hadoopstreaming的东西了解一下)
当然,对于mapreduce来说,用什么语言影响不大。下面会具体分析。
从Hadoop开始,在Hadoop1.x中。任务只要分为两个阶段,jobtracker(任务调度,资源分配)和tasktracker。
其中jobtracker配置在master节点上,启动集群后通过jps命令可以查看到namenode进程,在slave从节点jps可以查看到datanode进程,关于1.x就不多扯了,因为基本上都会用2.x了,因为一个好东西(yarn,后面会写到)
程序会运行在一个worker进程中(环境的配置网上很多,文末会配上本狗的安装包版本号)
而在Hadoop2.x中将jobtracker进行了拆分,原因是,1.x中如果jobtracker挂了,很容易产生单点故障,而且jobtracker本身负责的东西有点多,因此,在2.x中,将jobtracker拆分为resourcemanager(资源调度)和applicationmanager(任务分配),从节点上的tasktracker也成为了nodemanager,程序运行在一个容器中(container)
MapReduce是做什么的呢?它是一个用于处理海量数据的分布式计算框架。
它解决了数据分布式存储;作业调度;容错;机器间通信等问题。
那么它从哪里读取和存储数据呢,HDFS,同时为了防止某一台节点挂掉导致数据丢失的问题,会将数据存储到不同的block中,具体会在HDFS中说明。
本篇先以我喜欢的python开发,需要用到的就是Hadoop streaming。
上面写到,语言对于开发mapreduce影响不大,因为mapreduce处理的PB以上的数据,不需要时效性,速度的些许提升无所谓(个人看法)
mapreduce采用的分而治之的思想,将整个过程分为
-分解
-求解
-合并
整个过程如下:
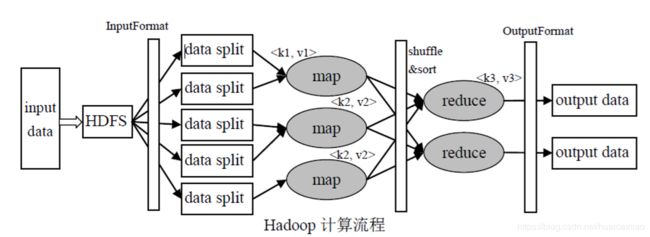
其中灰色部分是我们开发中需要用到的,首先将数据输入到HDFS中,然后经过数据格式化,切片处理,这些都是框架自动完成的,然后进入map阶段,运行我们的程序,以
输入的文件存储在HDFS中,每个文件切分为一定的大小(默认128M,可以通过配置文件进行更改)的block(默认3个备份)上
inputformat则是进行数据分割(spilt)和记录读取(Record Reader,每读取一条记录,调用一个map函数)
spilt,每一个spilt都含有后一个block的开头部分(解决了记录跨block问题)
shuffle阶段就是partion,sort,spill等过程,也是优化大有可为的地方
将map后的数据分配个哪一个reduce则是需要经过partititioner,来决定数据由哪一个reduce处理(哈希方法)
每一个map和partition处理的key value保存在memoryBuffer中(缓冲区大小默认100M,一般到达80M就会到达溢写阈值)
当内存缓冲区到达溢写阈值后。spill线程锁住这80M的缓冲区,开始将数据写出到本地磁盘上,然后释放内存
Hadoop streaming则是多了一步
整个Hadoopstreaming流程如下图
 相当于mapreduce的map阶段和reduce阶段多了一个罩子,这个罩子就是Hadoopstreaming ,可以将python语言通过标准输入转化为mapreduce。
相当于mapreduce的map阶段和reduce阶段多了一个罩子,这个罩子就是Hadoopstreaming ,可以将python语言通过标准输入转化为mapreduce。
那么streaming具有什么优点呢?
--开发效率高
方便一直Hadoop平台,只需要按照一定的格式从标准输入读数据、向标准输出写数据就可以
原有的单机程序稍加修改就可以在Hadoop平台进行分布式处理
容易单机调试
cat input | mapper | sort | reducer > output
--程序运行效率高
--便于平台进行资源控制
具体的原理就到这里,写的很乱,望指正。
Hadoop2.6.5