大数据学习之路----Scala语言学习(安装、常量、变量、类型)
一、scala语言Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言、并集成面向对象编程和函数式编程的各种特性,这种语言与java类似,有很多java的影子存在,而且还有一些自己的特点,我们可以使用这门语言去操作spark计算引擎,scala在计算和执行效率上要高于java所以我们在使用spark进行在线计算时,采用的是scala语言。
多范式:既包含java的面向对象,又包含javascript的面向过程,也就是说他可以去定义对象进行方法实现,也可以写一个函数进行函数操作。
二、Scala的安装
在这里我使用的是Idea的Scala
1.一定要安装jdk
2.idea中File>>>Settings>>>搜索Plugins
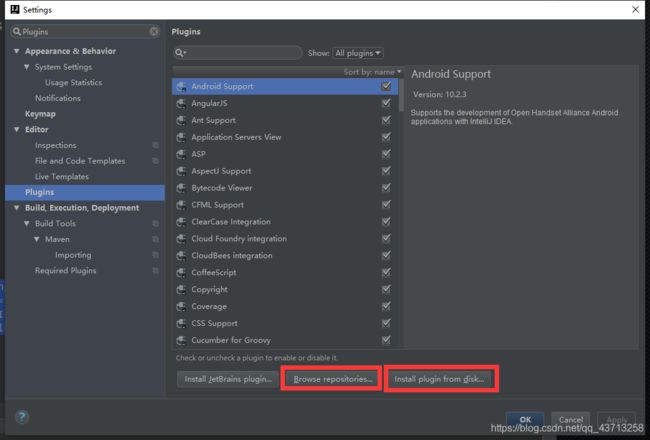
图片中两个框中第一个是可以联网去下载的,可以点击后在上方搜索Scala
第二个框中是我们可以去下载Scala安装文件放到本地中去选取的,这个点击后直接选择路径就能配置环境了
创建项目>>>File>>>New>>>Projects,在这里弹出一个框,我们可以搜索到Scala
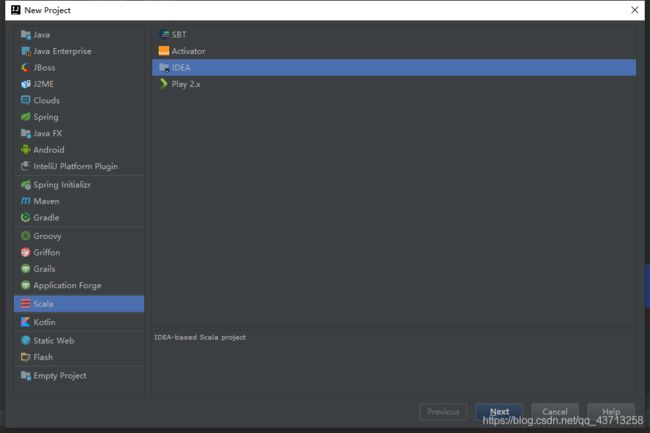
点击next建立项目,在上方写项目名字,Scala SDK是选择Scala安装包

这个里要注意一点,在我们新建类时,一定要选择Scala Class

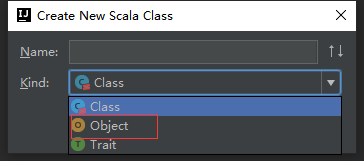
一定要选择Object,这个类是可以运行方法的,其他的运行不了
三、Scala的常量和变量
1)定义
常量:是在运行的过程中,其值不会发生变化的量 例如:数值3 字母A 修饰的关键字val
变量:是在运行的过程中,其值可以发生变化的量 例如:时间,年龄 修饰的关键字var
2)语法
val name:Type=变量值
var name:Type=变量值
注意1:
类型可以不写,scala 可以自动类型推断
注意2:变量名称必须符合命名规范,不能使用关键字(命名规范和java一样)
1.字母,下划线,数字组成,并且不能以数字开头
val 4_tablename=“t_user”;
2.变量名要做到见名知意,(如果英文不好我们通过通过有道翻译)
3.用驼峰命名法命名多个单词组成的变量名
val tablename=“t_user”;
4.变量名不能使用关键字
val def =12
四、Scala中的数据类型

这里Scala的数据类型与java是差不多的,所有类型的基类是Any,也称为顶级类,它有两个直接子类:AnyVal和AnyRef
AnyVal代表值类型,也就是一些int、short、long…等等;而AnyRef代表的是引用类型,所有非值类型都被定义为引用类型,在Scala中,每个用户自定义的类型都是AnyRef的子类型。
Null是所有引用类型的子类型(即AnyRef的任意子类型)。它有一个单例值由关键字null所定义。
Nothing是所有类型的子类型,也称为底部类型。没有一个值是Nothing类型的。

五、Scala中的方法
Scala中的方法有两种,一个是main方法和自定义方法
1、main方法
语法:def main(args: Array[String]): Unit = {
方法体
}
def 定义方法
main 方法名字
args 参数的名字
Array[String] 参数类型 ,字符串数组
Unit 没有返回值,相当于java中的void
2、自定义方法
语法:def 方法名( 参数名: 参数类型 ): 返回类型 = {
方法体
}
调用方法时直接写方法名(参数)
六、懒加载
1)scala 中使用lazy 关键字修饰变量,就是惰性变量,实现延迟加载
注意:惰性变量只能是常量,并且只有在调用惰性变量时,才会去实例化这个变量
2)案例演示
//正常的
var str = {
println(“helloworld”)
}
//懒加载的形式
lazy val str1 = {
println(“helloworld”)
}
//调用这个变量
str1
3)好处
使用在比较耗时的业务中,如网络IO 磁盘IO
这里懒加载就是为了我们在处理数据时内存容量最大限度地去利用,让内存不会突然就产生巨大数据,从而提高计算效率
七、插值器
scala中有三种插值器
1.在任何字符串前面加上s,就可直接在字符串中使用变量了
val name:String=“cat”
println(s"she is name is n a m e " ) 2. f 插 值 器 : v a l h e i g h t = 1.23568 p r i n t l n ( f " 身 高 是 {name}") 2.f插值器: val height=1.23568 println(f"身高是 name")2.f插值器:valheight=1.23568println(f"身高是{height}%.2f")
3.raw插值器:是输入字符串原样,不进行转义
例如:
//没有使用raw
println("a\nb\n\tc")
//使用的效果
println(raw"a\nb\n\tc")
其实f插值器就是s插值器的升级版
八、访问修饰符
Scala的访问修饰符有三种
private:一个类的内部可用
protected:自己类 子类也可以被访问(这个比java更加严格,java同一个包的其他类也可以访问)
public:如果没有指定修饰符 ,这样的成员在任何地方都可以被访问
注意:
如果不指定的情况下,就是public
九、运算符
Scala的运算符与java也相同分为:算术运算符、关系运算符、逻辑运算符、赋值运算符
算术运算符:加 减 乘 除 取余
关系运算符: == != > < >= <=
逻辑运算符:&& || !
赋值运算符: = += -= *= /= %=
十、类型转换
Scala的类型转换中没有Java的强制转换,如果要转换的话只能使用toInt、toFloat…等方法去转换
十一、总结
以上就是我今天学习Scala的基本内容,我在实际操作中也有很多点下面分享给大家:
1.输出:println()
2.在控制台输入:Console.readline()
3.获取首字符
“Hello”.take(1)/“Hello”(0)可以根据下标直接获取"H"
4.获取尾字符
“Hello”.reverse(0)
“Hello”.takeRight(1)
5.随机数
Random.nextInt(范围)