机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
http://blog.csdn.net/zouxy09
机器学习算法与Python实践这个系列主要是参考《机器学习实战》这本书。因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学习算法。恰好遇见这本同样定位的书籍,所以就参考这本书的过程来学习了。
这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法。啥叫正统呢?我概念里面机器学习算法一般是这样一个步骤:
1)对于一个问题,我们用数学语言来描述它,然后建立一个模型,例如回归模型或者分类模型等来描述这个问题;
2)通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
3)然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
a)如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数了。
b)如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。或者求导后式子得不到解释解,例如未知参数的个数大于已知方程组的个数等。这时候我们就需要借助迭代算法来一步一步找到最有解了。迭代是个很神奇的东西,它将远大的目标(也就是找到最优的解,例如爬上山顶)记在心上,然后给自己定个短期目标(也就是每走一步,就离远大的目标更近一点),脚踏实地,心无旁贷,像个蜗牛一样,一步一步往上爬,支撑它的唯一信念是:只要我每一步都爬高一点,那么积跬步,肯定能达到自己人生的巅峰,尽享山登绝顶我为峰的豪迈与忘我。
另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解,方圆五百里就只有一个山峰,那命中注定了,它就是你要找的唯一了。但如果是非凸的,那么就会有很多局部最优的解,有一望无际的山峰,人的视野是伟大的也是渺小的,你不知道哪个山峰才是最高的,可能你会被命运作弄,很无辜的陷入一个局部最优里面,坐井观天,以为自己找到的就是最好的。没想到山外有山,人外有人,光芒总在未知的远处默默绽放。但也许命运眷恋善良的你,带给你的总是最好的归宿。也有很多不信命的人,觉得人定胜天的人,誓要找到最好的,否则不会罢休,永不向命运妥协,除非自己有一天累了,倒下了,也要靠剩下的一口气,迈出一口气能支撑的路程。好悲凉啊……哈哈。
呃,不知道扯那去了,也不知道自己说的有没有错,有错的话请大家不吝指正。那下面就进入正题吧。正如上面所述,逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏,冥冥人海,滚滚红尘,我们是否找到了最适合的那个她。
一、逻辑回归(LogisticRegression)
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。之前在经典之作《数学之美》中也看到了它用于广告预测,也就是根据某广告被用户点击的可能性,把最可能被用户点击的广告摆在用户能看到的地方,然后叫他“你点我啊!”用户点了,你就有钱收了。这就是为什么我们的电脑现在广告泛滥的原因了。
还有类似的某用户购买某商品的可能性,某病人患有某种疾病的可能性啊等等。这个世界是随机的(当然了,人为的确定性系统除外,但也有可能有噪声或产生错误的结果,只是这个错误发生的可能性太小了,小到千万年不遇,小到忽略不计而已),所以万物的发生都可以用可能性或者几率(Odds)来表达。“几率”指的是某事物发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。还记得上几节讲的支持向量机SVM吗?它就是个二分类的例如,它可以将两个不同类别的样本给分开,思想是找到最能区分它们的那个分类超平面。但当你给一个新的样本给它,它能够给你的只有一个答案,你这个样本是正类还是负类。例如你问SVM,某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这对我们来说,显得太粗鲁了,要不希望,要不绝望,这都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,你想都不用想了等等,告诉你她有49%的几率喜欢你,总比直接说她不喜欢你,来得温柔。而且还提供了额外的信息,她来到你的身边你有多少希望,你得再努力多少倍,知己知彼百战百胜,哈哈。Logistic regression就是这么温柔的,它给我们提供的就是你的这个样本属于正类的可能性是多少。
还得来点数学。(更多的理解,请参阅参考文献)假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
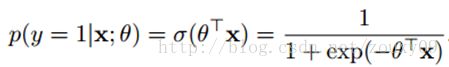
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
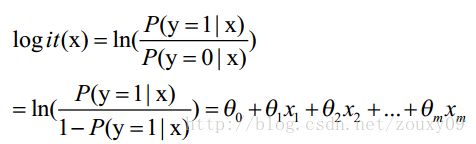
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。请选择你的心仪男生,非诚勿扰!哈哈。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离,这个活实际上就让logistic regression给干了。
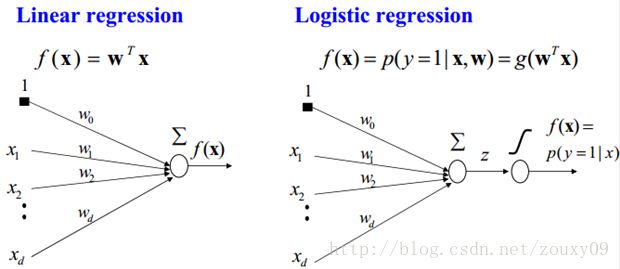
所以说,LogisticRegression 就是一个被logistic方程归一化后的线性回归,仅此而已。
好了,关于LR的八卦就聊到这。归入到正统的机器学习框架下,模型选好了,只是模型的参数θ还是未知的,我们需要用我们收集到的数据来训练求解得到它。那我们下一步要做的事情就是建立代价函数了。
LogisticRegression最基本的学习算法是最大似然。啥叫最大似然,可以看看我的另一篇博文“从最大似然到EM算法浅解”。
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:

上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):

那最大似然法就是求模型中使得似然函数最大的系数取值θ*。这个最大似然就是我们的代价函数(cost function)了。
OK,那代价函数有了,我们下一步要做的就是优化求解了。我们先尝试对上面的代价函数求导,看导数为0的时候可不可以解出来,也就是有没有解析解,有这个解的时候,就皆大欢喜了,一步到位。如果没有就需要通过迭代了,耗时耗力。
我们先变换下L(θ):取自然对数,然后化简(不要看到一堆公式就害怕哦,很简单的哦,只需要耐心一点点,自己动手推推就知道了。注:有xi的时候,表示它是第i个样本,下面没有做区分了,相信你的眼睛是雪亮的),得到:

这时候,用L(θ)对θ求导,得到:

然后我们令该导数为0,你会很失望的发现,它无法解析求解。不信你就去尝试一下。所以没办法了,只能借助高大上的迭代来搞定了。这里选用了经典的梯度下降算法。
二、优化求解
2.1、梯度下降(gradient descent)
Gradient descent 又叫 steepest descent,是利用一阶的梯度信息找到函数局部最优解的一种方法,也是机器学习里面最简单最常用的一种优化方法。它的思想很简单,和我开篇说的那样,要找最小值,我只需要每一步都往下走(也就是每一步都可以让代价函数小一点),然后不断的走,那肯定能走到最小值的地方,例如下图所示:
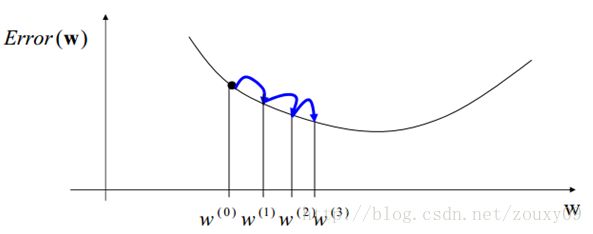
但,我同时也需要更快的到达最小值啊,怎么办呢?我们需要每一步都找下坡最快的地方,也就是每一步我走某个方向,都比走其他方法,要离最小值更近。而这个下坡最快的方向,就是梯度的负方向了。
对logistic Regression来说,梯度下降算法新鲜出炉,如下:

其中,参数α叫学习率,就是每一步走多远,这个参数蛮关键的。如果设置的太多,那么很容易就在最优值附加徘徊,因为你步伐太大了。例如要从广州到上海,但是你的一步的距离就是广州到北京那么远,没有半步的说法,自己能迈那么大步,是幸运呢?还是不幸呢?事物总有两面性嘛,它带来的好处是能很快的从远离最优值的地方回到最优值附近,只是在最优值附近的时候,它有心无力了。但如果设置的太小,那收敛速度就太慢了,向蜗牛一样,虽然会落在最优的点,但是这速度如果是猴年马月,我们也没这耐心啊。所以有的改进就是在这个学习率这个地方下刀子的。我开始迭代是,学习率大,慢慢的接近最优值的时候,我的学习率变小就可以了。所谓采两者之精华啊!这个优化具体见2.3 。
梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
计算整个数据集的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
################################################
注:因为本文中是求解的Logit回归的代价函数是似然函数,需要最大化似然函数。所以我们要用的是梯度上升算法。但因为其和梯度下降的原理是一样的,只是一个是找最大值,一个是找最小值。找最大值的方向就是梯度的方向,最小值的方向就是梯度的负方向。不影响我们的说明,所以当时自己就忘了改过来了,谢谢评论下面@wxltt的指出。另外,最大似然可以通过取负对数,转化为求最小值。代码里面的注释也是有误的,写的代码是梯度上升,注销成了梯度下降,对大家造成的不便,希望大家海涵。
2.2、随机梯度下降SGD (stochastic gradient descent)
梯度下降算法在每次更新回归系数的时候都需要遍历整个数据集(计算整个数据集的回归误差),该方法对小数据集尚可。但当遇到有数十亿样本和成千上万的特征时,就有点力不从心了,它的计算复杂度太高。改进的方法是一次仅用一个样本点(的回归误差)来更新回归系数。这个方法叫随机梯度下降算法。由于可以在新的样本到来的时候对分类器进行增量的更新(假设我们已经在数据库A上训练好一个分类器h了,那新来一个样本x。对非增量学习算法来说,我们需要把x和数据库A混在一起,组成新的数据库B,再重新训练新的分类器。但对增量学习算法,我们只需要用新样本x来更新已有分类器h的参数即可),所以它属于在线学习算法。与在线学习相对应,一次处理整个数据集的叫“批处理”。
随机梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
对数据集中每个样本
计算该样本的梯度
使用alpha xgradient来更新回归系数
}
返回回归系数值
################################################
2.3、改进的随机梯度下降
评价一个优化算法的优劣主要是看它是否收敛,也就是说参数是否达到稳定值,是否还会不断的变化?收敛速度是否快?

上图展示了随机梯度下降算法在200次迭代中(请先看第三和第四节再回来看这里。我们的数据库有100个二维样本,每个样本都对系数调整一次,所以共有200*100=20000次调整)三个回归系数的变化过程。其中系数X2经过50次迭代就达到了稳定值。但系数X1和X0到100次迭代后稳定。而且可恨的是系数X1和X2还在很调皮的周期波动,迭代次数很大了,心还停不下来。产生这个现象的原因是存在一些无法正确分类的样本点,也就是我们的数据集并非线性可分,但我们的logistic regression是线性分类模型,对非线性可分情况无能为力。然而我们的优化程序并没能意识到这些不正常的样本点,还一视同仁的对待,调整系数去减少对这些样本的分类误差,从而导致了在每次迭代时引发系数的剧烈改变。对我们来说,我们期待算法能避免来回波动,从而快速稳定和收敛到某个值。
对随机梯度下降算法,我们做两处改进来避免上述的波动问题:
1)在每次迭代时,调整更新步长alpha的值。随着迭代的进行,alpha越来越小,这会缓解系数的高频波动(也就是每次迭代系数改变得太大,跳的跨度太大)。当然了,为了避免alpha随着迭代不断减小到接近于0(这时候,系数几乎没有调整,那么迭代也没有意义了),我们约束alpha一定大于一个稍微大点的常数项,具体见代码。
2)每次迭代,改变样本的优化顺序。也就是随机选择样本来更新回归系数。这样做可以减少周期性的波动,因为样本顺序的改变,使得每次迭代不再形成周期性。
改进的随机梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
对随机遍历的数据集中的每个样本
随着迭代的逐渐进行,减小alpha的值
计算该样本的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
################################################

比较原始的随机梯度下降和改进后的梯度下降,可以看到两点不同:
1)系数不再出现周期性波动。2)系数可以很快的稳定下来,也就是快速收敛。这里只迭代了20次就收敛了。而上面的随机梯度下降需要迭代200次才能稳定。
三、Python实现
我使用的Python是2.7.5版本的。附加的库有Numpy和Matplotlib。具体的安装和配置见前面的博文。在代码中已经有了比较详细的注释了。不知道有没有错误的地方,如果有,还望大家指正(每次的运行结果都有可能不同)。里面我写了个可视化结果的函数,但只能在二维的数据上面使用。直接贴代码:
logRegression.py
#################################################
# logRegression: Logistic Regression
# Author : zouxy
# Date : 2014-03-02
# HomePage : http://blog.csdn.net/zouxy09
# Email : [email protected]
#################################################
from numpy import *
import matplotlib.pyplot as plt
import time
# calculate the sigmoid function
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))
# train a logistic regression model using some optional optimize algorithm
# input: train_x is a mat datatype, each row stands for one sample
# train_y is mat datatype too, each row is the corresponding label
# opts is optimize option include step and maximum number of iterations
def trainLogRegres(train_x, train_y, opts):
# calculate training time
startTime = time.time()
numSamples, numFeatures = shape(train_x)
alpha = opts['alpha']; maxIter = opts['maxIter']
weights = ones((numFeatures, 1))
# optimize through gradient descent algorilthm
for k in range(maxIter):
if opts['optimizeType'] == 'gradDescent': # gradient descent algorilthm
output = sigmoid(train_x * weights)
error = train_y - output
weights = weights + alpha * train_x.transpose() * error
elif opts['optimizeType'] == 'stocGradDescent': # stochastic gradient descent
for i in range(numSamples):
output = sigmoid(train_x[i, :] * weights)
error = train_y[i, 0] - output
weights = weights + alpha * train_x[i, :].transpose() * error
elif opts['optimizeType'] == 'smoothStocGradDescent': # smooth stochastic gradient descent
# randomly select samples to optimize for reducing cycle fluctuations
dataIndex = range(numSamples)
for i in range(numSamples):
alpha = 4.0 / (1.0 + k + i) + 0.01
randIndex = int(random.uniform(0, len(dataIndex)))
output = sigmoid(train_x[randIndex, :] * weights)
error = train_y[randIndex, 0] - output
weights = weights + alpha * train_x[randIndex, :].transpose() * error
del(dataIndex[randIndex]) # during one interation, delete the optimized sample
else:
raise NameError('Not support optimize method type!')
print 'Congratulations, training complete! Took %fs!' % (time.time() - startTime)
return weights
# test your trained Logistic Regression model given test set
def testLogRegres(weights, test_x, test_y):
numSamples, numFeatures = shape(test_x)
matchCount = 0
for i in xrange(numSamples):
predict = sigmoid(test_x[i, :] * weights)[0, 0] > 0.5
if predict == bool(test_y[i, 0]):
matchCount += 1
accuracy = float(matchCount) / numSamples
return accuracy
# show your trained logistic regression model only available with 2-D data
def showLogRegres(weights, train_x, train_y):
# notice: train_x and train_y is mat datatype
numSamples, numFeatures = shape(train_x)
if numFeatures != 3:
print "Sorry! I can not draw because the dimension of your data is not 2!"
return 1
# draw all samples
for i in xrange(numSamples):
if int(train_y[i, 0]) == 0:
plt.plot(train_x[i, 1], train_x[i, 2], 'or')
elif int(train_y[i, 0]) == 1:
plt.plot(train_x[i, 1], train_x[i, 2], 'ob')
# draw the classify line
min_x = min(train_x[:, 1])[0, 0]
max_x = max(train_x[:, 1])[0, 0]
weights = weights.getA() # convert mat to array
y_min_x = float(-weights[0] - weights[1] * min_x) / weights[2]
y_max_x = float(-weights[0] - weights[1] * max_x) / weights[2]
plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g')
plt.xlabel('X1'); plt.ylabel('X2')
plt.show()四、测试结果
测试代码:
test_logRegression.py
#################################################
# logRegression: Logistic Regression
# Author : zouxy
# Date : 2014-03-02
# HomePage : http://blog.csdn.net/zouxy09
# Email : [email protected]
#################################################
from numpy import *
import matplotlib.pyplot as plt
import time
def loadData():
train_x = []
train_y = []
fileIn = open('E:/Python/Machine Learning in Action/testSet.txt')
for line in fileIn.readlines():
lineArr = line.strip().split()
train_x.append([1.0, float(lineArr[0]), float(lineArr[1])])
train_y.append(float(lineArr[2]))
return mat(train_x), mat(train_y).transpose()
## step 1: load data
print "step 1: load data..."
train_x, train_y = loadData()
test_x = train_x; test_y = train_y
## step 2: training...
print "step 2: training..."
opts = {'alpha': 0.01, 'maxIter': 20, 'optimizeType': 'smoothStocGradDescent'}
optimalWeights = trainLogRegres(train_x, train_y, opts)
## step 3: testing
print "step 3: testing..."
accuracy = testLogRegres(optimalWeights, test_x, test_y)
## step 4: show the result
print "step 4: show the result..."
print 'The classify accuracy is: %.3f%%' % (accuracy * 100)
showLogRegres(optimalWeights, train_x, train_y) 测试数据是二维的,共100个样本。有2个类。如下:
testSet.txt
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0训练结果:
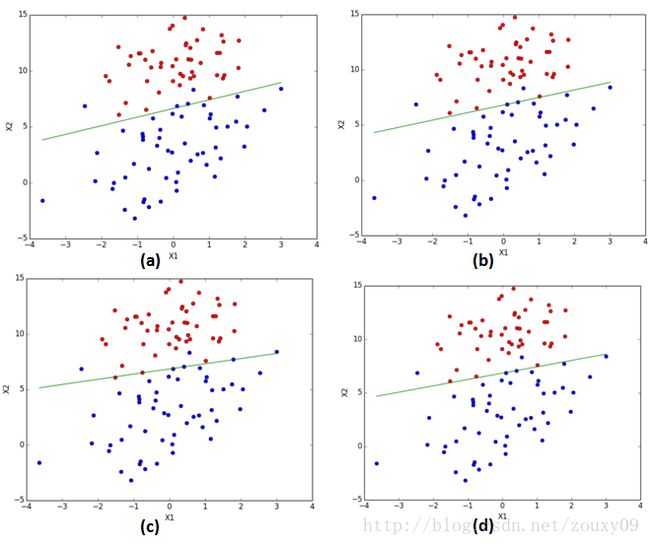
(a)梯度下降算法迭代500次。(b)随机梯度下降算法迭代200次。(c)改进的随机梯度下降算法迭代20次。(d)改进的随机梯度下降算法迭代200次。
五、参考文献
[1] Logisticregression (逻辑回归) 概述
[2] LogisticRegression 之基础知识准备
[3] LogisticRegression