大话大话数据结构——图
目录
存储
遍历
最短路径
Dijkstra
Bellman-Ford
BF算法大致过程
代码
Floyd 全员恶人最短路问题
最小生成树
prim
kruskal
关键路径
求解关键路径
首先说明,以下内容只是个人的鄙见。BTW,所有算法的正确性《算法笔记》都没说,需要去《算法导论》看。
存储
图的表示方法和树或者链表一样,可以用邻接矩阵或者表,一个是连续存储,一个是离散存储,链式存储。
当然如果使用STL的vector就十分方便,如下图,不存放边权,使用vector
当然形式可以多样一点,入边也可以冗余的表示,看个人喜好改变代码。
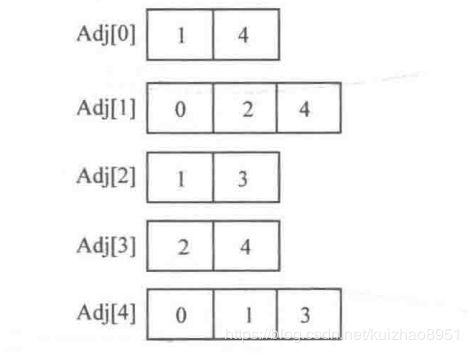
遍历
可以分为DFS和BFS
最短路径
Dijkstra
用G(V,E)表示图 G是图 V是顶点 E是边
迪杰斯特拉一开始要将到所有顶点(除了起点)的距离设为无穷打,先从起点开始从可以到达的路径中选择最短的访问,设这个最短的路径到达的是u顶点。
然后查看通过s->u之后u再到其他的u可以到达的顶点 使用的路径和会不会比之前没有到u时候观察的最小路径还要小。如果还要小就优化这个最小路径。执行n次之后 就可以知道每一个顶点的最小路径长度了。
迪杰斯特拉适用于单源无负权边的图。
以下代码中,注释掉的是有些时候可能遇到的顶点权值、花费什么的,其实迪杰斯特拉还有使用堆优化的,但是这里也不详细写了。(毕竟不会,貌似迪杰斯特拉是贪心,并且有贪心到达全局最优的证明……以及优化什么的 那就是比较深入了,这里不求甚解)
#include
#include
#include
#include
#include
#include
/* run this program using the console pauser or add your own getch, system("pause") or input loop */
using namespace std;
const int MAXV = 1000;//最大顶点数
const int INF =100000000; //表示距离无穷远
int n,m,st,ed,G[MAXV][MAXV];//n是顶点数 m是边数 st是起点 使用邻接矩阵来存储图
int cost[MAXV][MAXV];//cost为花费矩阵
//int weight[MAXV];//每个顶点的点权
int d[MAXV];//起点到某个顶点的最短路径长度
//int c[MAXV];//记录最小花费
//int w[MAXV];//w[u]代表从起点s到顶点u可以得到的最大点权之和
//int num[MAXV];//num[u]表示从起点s到顶点u的最短路径的条数 初始化时候num[s]=1 其他num[u]=0
vector pre[MAXV];//保存从起点到顶点v的路径上,v前面一个顶点是什么 以此得到路径
bool vis[MAXV]={false};//标记是否已经访问过的数组
void Dijkstra(int s){//s为起点,Dijkstra解决的是单源(只有一个起点)无负权最短路径问题
fill(d,d+MAXV,INF);//fill函数将整个d数组赋值为INF(慎用memset)
//fill(c,c+MAXV,INF);
//memset(num,0,sizeof(num));
//memset(w,0,sizeof(w));
//for(int i=0;iv的路程
if(d[u]+G[u][v]w[v]){//如果说以u为中介 可以使得点权之和更大
// w[v]=w[u]+weight[v];
//}
//if(c[u]+cost[u][v] path,tempPath;//最优路径、临时路径
void DFS(int v){//v为要访问的顶点 从终点开始递归
if(v==st){//递归边界 如果到达了起点 那么输出起点并且返回
tempPath.push_back(v);//将st加入临时路径tempPath的最后面
int tempCost=0;//int value;//存放tempPath上的第二指标的值
//此处计算tempPath上的value值; 下面只是例子
//例子begin
for(int i=tempPath.size()-1;i>0;i--){
int id=tempPath[i],idNext = tempPath[i-1];
tempCost+=cost[id][idNext];
}
//例子end
if(tempCost=0;i--){
printf("%d",path[i]);
}
printf("%d %d\n",d[ed],minCost);//printf("%d %d\n",num[ed],w[ed]);
return 0;
} Bellman-Ford
dijkstra不能解决有负边权的地图,而BF算法可以,BF算法可以。
算法笔记中提出,在一个环(头尾相接,并且如果是有向的那么必定要是单方向)如果所有边权和不为负数,那么就不会y影响最短路径的求解,如果是负数就会
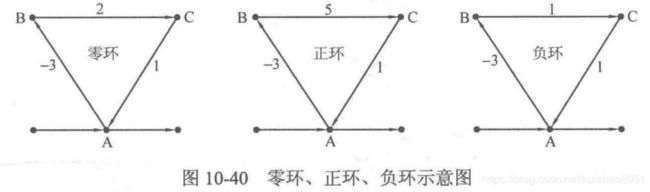
我也不敢说懂,就隐约觉得可以能是这样因为,如果看前两个,原点A到A、B、C本来最小的路径应该就是不动 0 -3 2以及正环的 0 -3 2 但是你看负环,到A如果 ABCA 就是-1了 多绕几圈还可能是……-2 以及更少,到BC的最小路径长度同理也会更少,所以BF算法有判断是否存在负环。(当然从原点如果到不到这个负环,也就不算了,因为到不到 所以不会有无穷小的长度)
BF算法大致过程
BF算法在循环的时候和DIJKSTRA不一样的地方是不用判断是否访问过(听我的,都访问,我是店长我说了算)
然后判断是否使得最短距离更短。
在”n-1次循环看每一个顶点u的边是否让u连接的v的d[v]最短距离更短,有就更新“之后。
我们要看图中是否有原点可以到达的负环,因为负环的存在让最短距离可以进一步变小,通过这一点判断。
代码
PAT A1003
#include
#include
#include
#include
#include
#include
#include
/* run this program using the console pauser or add your own getch, system("pause") or input loop */
using namespace std;
const int MAXV = 510;//最大顶点数
const int INF =0x3fffffff; //表示距离无穷远
struct Node{
int v,dis;//邻接边的目标顶点,dis为边权
Node(int _v,int _dis):v(_v),dis(_dis){}
};
int n,m,st,ed;//n是顶点数 m是边数 st是起点
//int G[MAXV][MAXV];//使用邻接矩阵来存储图
//int cost[MAXV][MAXV];//cost为花费矩阵
int weight[MAXV];//每个顶点的点权
int d[MAXV];//起点到某个顶点的最短路径长度
//int c[MAXV];//记录最小花费
int w[MAXV];//w[u]代表从起点s到顶点u可以得到的最大点权之和
int num[MAXV];//num[u]表示从起点s到顶点u的最短路径的条数 初始化时候num[s]=1 其他num[u]=0
vector Adj[MAXV];//保存从起点到顶点v的路径上,v前面一个顶点是什么 以此得到路径
set pre[MAXV];
void Bellman(int s){//这里没有判断有没有负环 因为这样题目就做不了了
fill(d,d+MAXV,INF);
memset(num,0,sizeof(num));
memset(w,0,sizeof(w));
d[s]=0;
w[s]=weight[s];
num[s]=1;
//求解d数组
for(int i=0;iw[v]){
w[v]=w[u]+weight[v];
}
pre[v].insert(u);
num[v]=0;
set::iterator it;
for(it=pre[v].begin();it!=pre[v].end();it++){
num[v]+=num[*it];
}
}
}
}
}
}
int main(int argc, char** argv) {
scanf("%d%d%d%d",&n,&m,&st,&ed);//顶点数 边数 起点 终点坐标
for(int i=0;i=0;i--){
printf("%d",path[i]);
}
printf("%d %d\n",d[ed],minCost);//printf("%d %d\n",num[ed],w[ed]);
*/
printf("%d %d\n",num[ed],w[ed]);
return 0;
} 当然比起迪杰斯特拉BF会有很多多余的操作。我们注意到,只有某个顶点的d[u]改变的时候,其邻接点v的d[v]才可能改变,所以有人提出优化,创建一个队列,每次对队列首的结点判断是否可以松弛(使得其下一个结点v的最小距离更短),如果可以松弛,就看一下v在不在队列里面,不再的话就加入队列,直到队列空(队列空也表示没有负环)
这种优化后的算法就是SPFA了
Floyd 全员恶人最短路问题
复杂度比较高,On^3,思想就是里三层外三层的循环看每一个结点和可以到达的结点作为中间结点可否优化到其他结点的距离。
#include
#include
#include
#include
#include
#include
#include
/* run this program using the console pauser or add your own getch, system("pause") or input loop */
using namespace std;
const int MAXV = 200;//最大顶点数 不要太大 floyd不适合太大的。
const int INF =0x3fffffff; //表示距离无穷远
int n,m;//n是顶点数 m是边数
int dis[MAXV][MAXV];//dis[i][j]代表从顶点i到顶点j的最短距离
void Floyd(){
for(int k=0;k 很暴力。
最小生成树
最小生成树是说从一幅无向图G生成一棵树,这棵树的有以下三个特点
- 拥有图中所有顶点
- 所有边都是来自于图G中的边,树内没有环
- 树的边权和最小
由于图是无向图,所以可以使用图中任意顶点生成不同的最小生成树,我们一般会指定顶点。
prim
prim和dijkstra的想法几乎完全相同,一开始我都是瞎的,然后起点距离为0,其他都是无穷远,占领起点之后将起点加入到S(已经访问集合)中并且作为树的根结点,然后通过起点连接的道路,优化其他未访问的顶点距离S的最小距离,然后再从中选择一个最近的,放入S中,并且作为其子结点,两点之间的权值就是那条距离S的最小距离代表的边的权值,如此循环直至所有的顶点都访问,就生成一颗最小生成树了。
和Dijkstra的差别就在于,迪杰斯特拉每次是优化从原点s到其他未访问结点的最小距离,而prim是优化S到其他未访问结点的最小距离。
代码省略(wo bu hui)。
kruskal
kruskal的思想比较好理解,将所有顶点都设置为单独的连通块,然后将边从小到大每一个查看,如果这个边连接的两个顶点不在同一个连通块就将这条边加入到树中,直到边的个数为顶点个数-1,或者所有边都看完,如果所有边都测试结束了,边的个数小于顶点个数-1,那么说明图不连通。
这里的代码实现可以使用并查集,也就是说设置一个顶点数大小的并查集,每次需要查看某个顶点是不是同一集合就不断递归到集合根结点,如果相同就是同一集合(连通块)
代码省略。
如果是稠密图(边多)使用prim,如果是稀疏图(边少)使用kruskal。
关键路径
除了最小路径和最小生成树,还有一个问题,就是关键路径问题。
想要理解关键路径,那么就需要从左往右了解概念
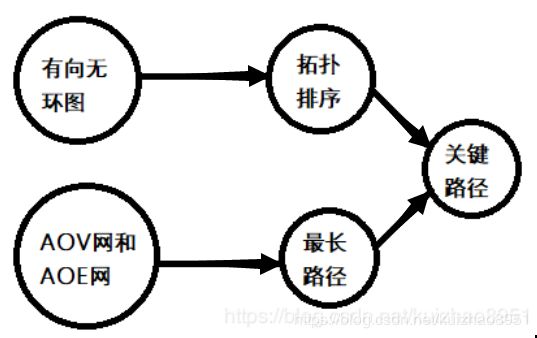
- 上图就是一个有向无环图,有向就是有向图,无环就是任意顶点都不能形成环。
- 拓扑排序就是将有向无环图->线性序列(满足任意u->v(如 有向无环图->拓扑排序),那么u在序列中一定在v前面),实现思想就是利用队列,一开始压入所有入度为0的点,然后弹出的时候就使得下一个v的入度-1,如果下一个v入度为0了,就入队,直到队空,如果这时候序列长度不为图的顶点数,那么就说明有环。
- AOV网是指用顶点表示活动,边表示活动关系,如上图;AOE图是带权边构成的有向无环图,带权边表示活动,权值表示活动花费时长,顶点表示事件,一般事件为前边活动已经结束,可以开始下一个边的活动。AOV如果顶点带权可以转换成AOE,比如学习拓扑排序需要一分钟,这个拓扑排序就可以变成,开始学习拓扑排序,一分钟的学习拓扑排序(边),学习拓扑排序结束且可以开始下一个学习内容。这样的话原来的无权边就需要变成权为0的边。
- 为什么要求最长路径呢?因为比如上图,我们需要学习完了拓扑以及最长路径才可以学关键路径,那么这两个分支都结束再加上学习关键路径的时间就是完成整个工程所需要的最长路径,也就是最短的时间。所以求最短时间就是求最长路径;而最长路径的求解一般是从一个起点到一个终点的最长路径,但是你看这里有两个起点怎么办呢,其实不论多少个起点和终点,我们可以通过超级起点、超级终点来化简成一个起点一个终点的问题。
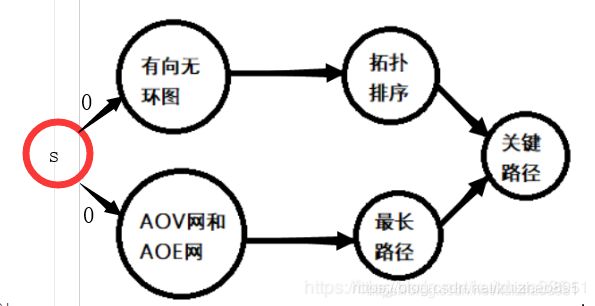
- 如上图我们就是用一个超级起点,到两个原起点的权都是0,如果有多个终点也是如法炮制(当然这里还是AOV,还没有转成AOE)
- 最长的路径,也被称为关键路径,关键路径上的活动必须紧锣密鼓的进行,一个延迟,那么就是延迟了整个工程的完成时间,所以路径上的活动也称为关键活动。
求解关键路径
不写了,自己找吧
详情参考:https://www.cnblogs.com/Braveliu/p/3461649.html