前言
生产环境中运行的组件,只要有数据存储,定时备份、灾难恢复是必修课,mysql数据库的备份方案已经非常成熟,Elasticsearch也同样有成熟的数据备份、恢复方案,我们来了解一下。
概要
本篇介绍Elasticsearch生产集群数据的数据备份、恢复和升级的常规操作。
curl命令
curl是Linux操作的必备工具,Elasticsearch生产环境的搭建,不能保证都能使用kibana访问到,而Elasticsearch Restful API都可以使用curl工具来完成访问。
使用curl还有一个好处:有些操作需要一连串的请求才能完成,我们可以使用shell脚本将这些关联的操作,封装到脚本里,后续使用起来就非常方便。
如果有定时执行的命令,也是使用shell将一系列操作封装好,运用Linux自带的crontab进行触发。
后续的一些操作命令,将会用curl来完成,并且只需要将完整的curl请求拷贝到kibana的dev tools上,kibana能够自动转化成我们之前常见的请求,非常方便。
在Linux下的请求命令:
[esuser@elasticsearch02 ~]$ curl -XGET 'http://elasticsearch02:9200/music/children/_search?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"match_all": {}
}
}
'完整的命令拷贝到dev tools里时,自动会变成:
GET /music/children/_search
{
"query": {
"match_all": {}
}
}这工具真是强大,不过反过来操作不行的,我已经试过了。
curl命令,有Body体的,记得加上-H 'Content-Type: application/json',?pretty参数可以让响应结果格式化输出。
数据备份
我们知道Elasticsearch的索引拆分成多个shard进行存储在磁盘里,shard虽然分了primary shard和replica shard,可以保证集群的数据不丢失,数据访问不间断,但如果机房停电导致集群节点全部宕机这种重大事故时,我们就需要提前定期地对数据进行备份,以防万一。
既然是磁盘文件存储,那存储介质的选择就有很多了:本地磁盘,NAS,文件存储服务器(如FastDFS、HDFS等),各种云存储(Amazon S3, 阿里云OSS)等
同样的,Elasticsearch也提供snapshot api命令来完成数据备份操作,可以把集群当前的状态和数据全部存储到一个其他目录上,本地路径或网络路径均可,并且支持增量备份。可以根据数据量来决定备份的执行频率,增量备份的速度还是很快的。
创建备份仓库
我们把仓库地址暂定为本地磁盘的/home/esuser/esbackup目录,
首先,我们需要在elasticsearch.yml配置文件中加上
path.repo: /home/esuser/esbackup
并重启Elasticsearch。
启动成功后,发送创建仓库的请求:
[esuser@elasticsearch02 ~]$ curl -XPUT 'http://elasticsearch02:9200/_snapshot/esbackup?pretty' -H 'Content-Type: application/json' -d '
{
"type": "fs",
"settings": {
"location": "/home/esuser/esbackup",
"max_snapshot_bytes_per_sec" : "50mb",
"max_restore_bytes_per_sec" : "50mb"
}
}
'
{"acknowledged":true}
[esuser@elasticsearch02 ~]$ 参数解释:
- type: 仓库的类型名称,请求里都是fs,表示file system。
- location: 仓库的地址,要与
elasticsearch.yml配置文件相同,否则会报错 - max_snapshot_bytes_per_sec: 指定数据从Elasticsearch到仓库(数据备份)的写入速度上限,默认是20mb/s
- max_restore_bytes_per_sec: 指定数据从仓库到Elasticsearch(数据恢复)的写入速度上限,默认也是20mb/s
用于限流的两个参数,需要根据实际的网络进行设置,如果备份目录在同一局域网内,可以设置得大一些,便于加快备份和恢复的速度。
也有查询命令可以看仓库的信息:
[esuser@elasticsearch02 ~]$ curl -XGET 'http://elasticsearch02:9200/_snapshot/esbackup?pretty'
{"esbackup":{"type":"fs","settings":{"location":"/home/esuser/esbackup","max_restore_bytes_per_sec":"50mb","max_snapshot_bytes_per_sec":"50mb"}}}
[esuser@elasticsearch02 ~]$使用hdfs创建仓库
大数据这块跟hadoop生态整合还是非常推荐的方案,数据备份这块可以用hadoop下的hdfs分布式文件存储系统,关于hadoop集群的搭建方法,需要自行完成,本篇末尾有补充说明,可供参考。
对Elasticsearch来说,需要安装repository-hdfs的插件,我们的Elasticsearch版本是6.3.1,对应的插件则使用repository-hdfs-6.3.1.zip,hadoop则使用2.8.1版本的。
插件下载安装命令:
./elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-6.3.1.zip
如果生产环境的服务器无法连接外网,可以先在其他机器上下载好,上传到生产服务器,解压到本地,再执行安装:
./elasticsearch-plugin install file:///opt/elasticsearch/repository-hdfs-6.3.1
安装完成后记得重启Elasticsearch节点。
查看节点状态:
[esuser@elasticsearch02 ~]$ curl -XGET elasticsearch02:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.17.137 38 95 2 0.03 0.03 0.05 mdi * node-1创建hdfs仓库
先查看节点的shard信息
[esuser@elasticsearch02 ~]$ curl -XGET 'http://elasticsearch02:9200/_count?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"match_all": {}
}
}'
{
"count" : 5392,
"_shards" : {
"total" : 108,
"successful" : 108,
"skipped" : 0,
"failed" : 0
}
}
创建一个hdfs的仓库,名称为hdfsbackup
[esuser@elasticsearch02 ~]$ curl -XPUT 'http://elasticsearch02:9200/_snapshot/hdfsbackup?pretty' -H 'Content-Type: application/json' -d '
{
"type": "hdfs",
"settings": {
"uri": "hdfs://elasticsearch02:9000/",
"path": "/home/esuser/hdfsbackup",
"conf.dfs.client.read.shortcircuit": "false",
"max_snapshot_bytes_per_sec" : "50mb",
"max_restore_bytes_per_sec" : "50mb"
}
}'
{
"acknowledged" : true
}验证仓库
仓库创建好了之后,可以用verify命令验证一下:
[esuser@elasticsearch02 ~]$ curl -XPOST 'http://elasticsearch02:9200/_snapshot/hdfsbackup/_verify?pretty'
{
"nodes" : {
"A1s1uus7TpuDSiT4xFLOoQ" : {
"name" : "node-1"
}
}
}索引备份
仓库创建好并验证完成后,可以执行snapshot api对索引进行备份了,
如果不指定索引名称,表示备份当前所有open状态的索引都备份,还有一个参数wait_for_completion,表示是否需要等待备份完成后才响应结果,默认是false,请求提交后会立即返回,然后备份操作在后台异步执行,如果设置为true,请求就变成同步方式,后台备份完成后,才会有响应。建议使用默认值即可,有时备份的整个过程会持续1-2小时。
示例1:备份所有的索引,备份名称为snapshot_20200122
[esuser@elasticsearch02 ~]$ curl -XPUT 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122?pretty'
{
"accepted" : true
}示例2:备份索引music的数据,备份名称为snapshot_20200122_02,并指定wait_for_completion为true
[esuser@elasticsearch02 ~]$ curl -XPUT 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122_02?wait_for_completion=true&pretty' -H 'Content-Type: application/json' -d '
{
"indices": "music",
"ignore_unavailable": true,
"include_global_state": false,
"partial": true
}'
{
"snapshot" : {
"snapshot" : "snapshot_20200122_02",
"uuid" : "KRXnzc6XSWagCQO92EQx6A",
"version_id" : 6030199,
"version" : "6.3.1",
"indices" : [
"music"
],
"include_global_state" : false,
"state" : "SUCCESS",
"start_time" : "2020-01-22T07:11:06.594Z",
"start_time_in_millis" : 1579677066594,
"end_time" : "2020-01-22T07:11:07.313Z",
"end_time_in_millis" : 1579677067313,
"duration_in_millis" : 719,
"failures" : [ ],
"shards" : {
"total" : 5,
"failed" : 0,
"successful" : 5
}
}
}这条命令中几个参数介绍:
- indices:索引名称,允许写多个,用","分隔,支持通配符。
- ignore_unavailable:可选值true/false,如果为true,indices里不存在的index就可以忽略掉,备份操作正常执行,默认是false,如果某个index不存在,备份操作会提示失败。
- include_global_state:可选值true/false,含义是要不要备份集群的全局state数据。
- partial:可选值true/false,是否支持备份部分shard的数据。默认值为false,如果索引的部分primary shard不可用,partial为false时备份过程会提示失败。
使用snapshot api对数据的备份是增量进行的,执行snapshotting的时候,Elasticsearch会分析已经存在于仓库中的snapshot对应的index file,在前一次snapshot基础上,仅备份创建的或者发生过修改的index files。这就允许多个snapshot在仓库中可以用一种紧凑的模式来存储,非常节省存储空间,并且snapshotting过程是不会阻塞所有的Elasticsearch读写操作的。
同样的,snapshot作为数据快照,在它之后写入index中的数据,是不会反应到这次snapshot中的,snapshot数据的内容包含index的副本,也可以选择是否保存全局的cluster元数据,元数据里面包含了全局的cluster设置和template。
每次只能执行一次snapshot操作,如果某个shard正在被snapshot备份,那么这个shard此时就不能被移动到其他node上去,这会影响shard rebalance的操作。只有在snapshot结束之后,这个shard才能够被移动到其他的node上去。
查看snapshot备份列表
- 查看仓库内所有的备份列表
curl -XGET 'http://elasticsearch02:9200/_snapshot/hdfsbackup/_all?pretty'- 查看单个备份数据
[esuser@elasticsearch02 ~]$ curl -XGET 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122_02?pretty'
{
"snapshots" : [
{
"snapshot" : "snapshot_20200122_02",
"uuid" : "KRXnzc6XSWagCQO92EQx6A",
"version_id" : 6030199,
"version" : "6.3.1",
"indices" : [
"music"
],
"include_global_state" : false,
"state" : "SUCCESS",
"start_time" : "2020-01-22T07:11:06.594Z",
"start_time_in_millis" : 1579677066594,
"end_time" : "2020-01-22T07:11:07.313Z",
"end_time_in_millis" : 1579677067313,
"duration_in_millis" : 719,
"failures" : [ ],
"shards" : {
"total" : 5,
"failed" : 0,
"successful" : 5
}
}
]
}删除snapshot备份
如果需要删除某个snapshot备份快照,一定要使用delete命令,造成别自个跑到服务器目录下做rm操作,因为snapshot是增量备份的,里面有各种依赖关系,极可能损坏backup数据,记住不要上来就自己干文件,让人家标准的命令来执行,命令如下:
[esuser@elasticsearch02 ~]$ curl -XDELETE 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122?pretty'
{
"acknowledged" : true
}查看备份进度
备份过程长短视数据量而定,wait_for_completion设置为true虽然可以同步得到结果,但时间太长的话也不现实,我们是希望备份操作后台自己搞,我们时不时的看看进度就行,其实还是调用的snapshot的get操作命令,加上_status参数即可,备份过程中会显示什么时间开始的,有几个shard在备份等等信息:
curl -XGET 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122_02/_status?pretty'
取消备份
正在备份的数据可以执行取消,使用的是delete命令:
curl -XDELETE 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122?pretty'
这个命令有两个作用:
- 如果备份正在进行中,那么取消备份操作,并且删除备份了一半的数据。
- 如果备份已经完成,直接删除备份数据。
数据恢复
生产环境的备份操作,是定期执行的,执行的频率看实际的数据量,有1天执行1次的,有4小时一次的,简单的操作是使用shell脚本封装备份的命令,然后使用Linux的crontab定时执行。
既然数据有备份,那如果数据出现异常,或者需要使用到备份数据时,恢复操作就能派上用场了。
常规恢复
数据恢复使用restore命令,示例如下:
[esuser@elasticsearch02 ~]$ curl -XPOST 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122_02/_restore?pretty'
{
"accepted" : true
}注意一下被恢复的索引,必须全部是close状态的,否则会报错,关闭索引的命令:
[esuser@elasticsearch02 ~]$ curl -XPOST 'http://elasticsearch02:9200/music/_close?pretty'恢复完成后,索引自动还原成open状态。
同样有些参数可以进行选择:
[esuser@elasticsearch02 ~]$ curl -XPOST 'http://elasticsearch02:9200/_snapshot/hdfsbackup/snapshot_20200122_02/_restore
{
"indices": "music",
"ignore_unavailable": true,
"include_global_state": true
}默认会把备份数据里的索引全部还原,我们可以使用indices参数指定需要恢复的索引名称。同样可以使用wait_for_completion参数,ignore_unavailable、partial和include_global_state与备份时效果相同,不赘述。
监控restore的进度
与备份类似,调用的recovery的get操作命令查看恢复的进度:
curl -XGET 'http://elasticsearch02:9200/music/_recovery?pretty'
music为索引名称。
取消restore
与备份类似,delete正在恢复的索引可以取消恢复过程:
curl -XDELETE 'http://elasticsearch02:9200/music'
集群升级
我们现在使用的版本是6.3.1,目前官网最新版本已经是7.5.2了,如果没有重大的变更或严重bug报告的情况下,一般是不需要做升级,毕竟升级有风险,发布要谨慎。
这里就简单说一下通用的步骤,谨慎操作:
- 查看官网最新版本的文档,从当前版本到目标版本的升级,有哪些变化,新加入的功能和修复的bug。
- 在开发环境或测试环境先执行升级,相应的插件也做一次匹配升级,稳定运行几个项目版本周期后,再考虑生产环境的升级事宜。
- 升级前对数据进行全量的备份,万一升级失败,还有挽救的余地。
- 申请生产环境升级的时间窗口,逐个node进行升级验证。
补充hadoop集群搭建
Elasticsearch的数据备份,通常建议的实践方案是结合hadoop的hdfs文件存储,这里我们搭建一个hadoop的集群环境用作演示,hadoop相关的基础知识请自行了解,已经掌握的童鞋可以跳过。
版本环境:
hadoop 2.8.1
虚拟机环境
hadoop集群至少需要3个节点。我们选用elasticsearch02、elasticsearch03、elasticsearch04三台机器用于搭建。
- 下载解压
官网下载hadoop-2.8.1.tar.gz,解压至/opt/hadoop目录
- 设置环境变量
演示环境拥有root权限,就介绍一种最简单的设置方法,修改/etc/profile文件,添加变量后记得source一下该文件。
[root@elasticsearch02 ~]# vi /etc/profile
# 文件末尾添加
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.1
export PATH=${HADOOP_HOME}/bin:$PATH
[root@elasticsearch02 ~]# source /etc/profile- 创建hadoop数据目录,启动hadoop时我们使用esuser账户,就在/home/esuser下创建目录,如
/home/esuser/hadoopdata - 修改hadoop的配置文件,在
/opt/hadoop/hadoop-2.8.1/etc/hadoop目录下,基本上是添加配置,涉及的配置文件:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- slaves(注:我们选定elasticsearch02为master,其余两个为slave)
示例修改如下:
core-site.xml
fs.defaultFS
hdfs://elasticsearch02:9000
hdfs-site.xml
dfs.namenode.name.dir
/home/esuser/hadoopdata/namenode
dfs.datanode.data.dir
/home/esuser/hadoopdata/datanode
yarn-site.xml
yarn.resourcemanager.hostname
elasticsearch02
mapred-site.xml
mapreduce.framework.name
yarn
slaves
elasticsearch03
elasticsearch04- 拷贝设置后的文件到另外两台机器上
scp -r /opt/hadoop/hadoop-2.8.1 esuser@elasticsearch03:/opt/hadoop/hadoop-2.8.1
scp -r /opt/hadoop/hadoop-2.8.1 esuser@elasticsearch04:/opt/hadoop/hadoop-2.8.1拷贝的文件有点大,需要等一会儿,拷贝完成后,在elasticsearch03、elasticsearch04再设置一次HADOOP_HOME环境变量
- 启动集群
格式化namenode,在hadoop master节点(elasticsearch02),HADOOP_HOME/sbin目录下执行hdfs namenode -format
执行启动命令:start-dfs.sh
这个启动过程会建立到elasticsearch03、elasticsearch04的ssh连接,输入esuser的密码即可,也可以提前建立好免密ssh连接。
我们只需要用它的hdfs服务,其他的组件可以不启动。
验证启动是否成功,三台机器分别输入jps,看下面的进程,如无意外理论上应该是这样:
elasticsearch02:NameNode、SecondaryNameNode
elasticsearch03:DataNode
elasticsearch04:DataNode
同时在浏览器上输入hadoop master的控制台地址:http://192.168.17.137:50070/dfshealth.html#tab-overview,应该能看到这两个界面: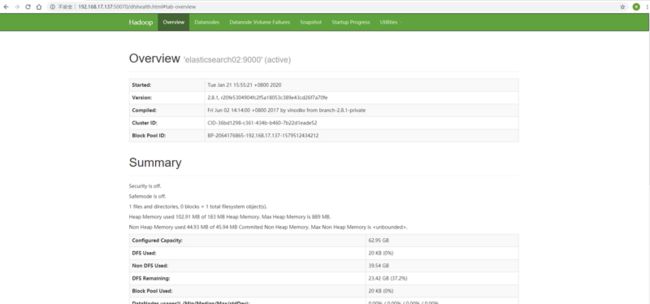
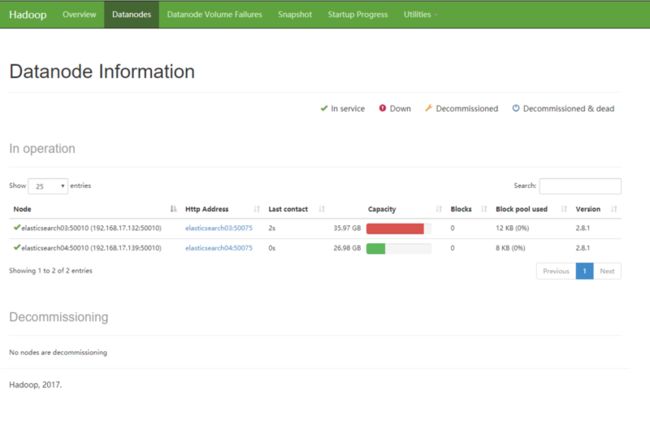
datanodes看到2个结点,表示集群启动成功,如果只能看到一个或一个都没有,可以查看相应的日志:/opt/hadoop/hadoop-2.8.1/logs
Error: JAVA_HOME is not set and could not be found 错误解决办法
这个明明已经设置了JAVA_HOME,并且export命令也能看到,启动时死活就是不行,不跟他杠了,直接在/opt/hadoop/hadoop-2.8.1/etc/hadoop/hadoop-env.sh文件加上
export JAVA_HOME="/opt/jdk1.8.0_211"
小结
本篇主要以hadoop分布式文件存储为背景,讲解了Elasticsearch数据的备份与恢复,可以了解一下。集群版本升级这类操作,实践起来比较复杂,受项目本身影响比较大,这里就简单提及要注意的地方,没有作详细的案例操作,真要有版本升级的操作,请各位慎重操作,多验证,确保测试环境充分测试后再上生产,记得数据要备份。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
可以扫左边二维码添加好友,邀请你加入Java架构社区微信群共同探讨技术