深度学习之梯度下降优化算法
一、梯度下降的变种算法
1、BGD
批量梯度下降法更新一次参数需要计算整个数据集所有样本的梯度,因此更新速度非常慢,对于凸优化问题会收敛到全局最优点、而非凸优化问题则会收敛到局部最优点,这种方法有可能无法将大量的数据放入内存,也不能进行在线学习。
![]()
2、SGD
随机梯度下降法更新一次参数只需计算一个样本的梯度,更新速度很快、参数方差波动大,适用于在线学习,有可能跳出局部最优到达全局最优。训练时每个epoch结束后注意必须要shuffle训练集:
![]()
SGD是在线学习最基本的模式,因为SGD训练得到的特征不具有稀疏性,从工程的角度来说占用内存过大。L1-norm在在线学习中效果不佳,因为梯度的方向不是全局的方向,而是沿着样本的梯度方向,会造成每次没有被充分训练的样本错误地将系数归零。
3、MBGD
小批量梯度下降法既减少了SGD参数方差的波动性,又可以利用深度学习库中高度优化的矩阵运算的便捷性,一般mini-batch size在50到256之间,每次参数更新计算小批量样本的梯度,也需要在每个epoch后shuffle数据集。
![]()
以上3种方法的challenges在于:
(1)选择合适的学习率比较困难,如果学习率过小,则J很长时间才能收敛;学习率过大,则J会震荡甚至发散。
(2)可以通过诸如退火annealing,即根据预先确定的学习率或当两次epoch间发生的变化低于一个阈值时,降低学习率的值。这些规划和阈值必须提前定义,因此无法动态适应数据集的特征。
(3)由于所有参数的更新使用相同的学习率,对于稀疏数据且出现频率差别非常大的特征,我们可能不想让它们更新相同的程度,如对于很少出现的特征进行较大的更新、对经常出现的特征进行较小的更新,这样以上的方法都不能满足要求。
(4)容易困在鞍点(SGD尤甚,因为鞍点处所有维度梯度趋近于0),只收敛到局部最优点。
二、梯度下降的优化算法
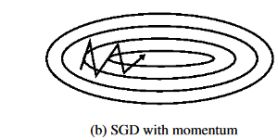
1、Momentum
Momentum是模拟物理学动量的概念,累积之前的动量加入梯度,能够在相关方向加速SGD,抑制震荡,从而加快收敛速度:

![]()
![]()
通过加入衰减分量γ更新向量v,一般γ=0.9或其他类似的值,令早期的梯度对当前的梯度影响越来越小,如果没有衰减值,模型往往会震荡、难以收敛,甚至发散。

此方法可以理解为小球从山顶落向山谷,因动量的累积使得速度越来越快,由于空气阻力的存在γ<1。同样地,在参数更新时:与梯度方向相同的维度动量增加、在梯度改变方向的维度动量减少,这样就能得到更快的收敛和减少振荡。
2、Nesterov accelerated gradient(NAG)
这一次的小球变得更加聪明,不会盲目地沿着坡滚动,例如在山坡快要上升的时候知道需要减速。NAG是赋予动量项这种“先见之明”的方法,使用 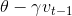 近似地作为参数下一步的值,这样在计算梯度时,就不是在当前位置,而是在未来的位置上进行:
近似地作为参数下一步的值,这样在计算梯度时,就不是在当前位置,而是在未来的位置上进行:
![]()
![]()
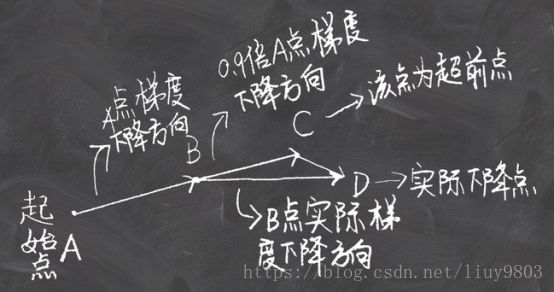

Momentum过程首先计算当前梯度(短的蓝色向量),然后在更新后的累积梯度的方向进行一个大的跳跃(长的蓝色向量);NAG首先在之前累积的梯度方向进行一个大的跳跃(棕色向量),然后衡量梯度进行修正校正(绿色向量)。这种预期的更新避免了更新速度过快、提高了结果的响应性,并极大地提高了RNN在许多任务上的性能。
NAG与Momentum的区别是,梯度计算不同,NAG先用当前的速度v更新一遍参数,再用更新的临时参数计算梯度,相当于添加了二阶校正因子的Momentum。这两种方法可以在更新梯度时顺应J的梯度来调整速度,并且对SGD进行加速。除此之外我们还希望可以根据参数的重要性而对不同的参数进行不同程度的更新。
3、适应性梯度算法Adagrad
在传统机器学习中,一种加速迭代的方法就是将数值归一化到一个以原点为中心的空间内。Adagrad通过累积梯度约束学习率,提升SGD的robustness,并且能让不频繁出现的参数进行较大的更新、频繁出现的参数进行较小的更新,尤其适用于稀疏数据的情况。由于每一步每个参数的学习率都不相同,令 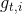 为t时刻第i个参数
为t时刻第i个参数  的目标函数的梯度:
的目标函数的梯度:
![]()
对于SGD,参数 在每一时刻的梯度更新公式为:
![]()
令  为对角矩阵,表示前t步参数 梯度的累加,矩阵对角线上的元素(i,i)是t时刻参数 的梯度平方和;ϵ为平滑项(类似1e-8之类极小的数)避免分母为0,则Adagrad的参数更新公式为:
为对角矩阵,表示前t步参数 梯度的累加,矩阵对角线上的元素(i,i)是t时刻参数 的梯度平方和;ϵ为平滑项(类似1e-8之类极小的数)避免分母为0,则Adagrad的参数更新公式为:
![]()
![]()
Adagrad的优点在于不需要对学习率进行手动调节,一般default为0.01后就不用管了,让它在学习的过程中自己变化。缺点在于分母中G累积了平方梯度后不断增大,这导致了学习率逐渐衰减为一个很小的数,尽管真实情况是参数的更新随着梯度增大而增大,但是到了后期由于分母越来越大,网络不再能够学到更多的知识,训练将提前结束。
4、Adadelta
Adadelta的基本思想是用一阶的方法近似模拟二阶牛顿法,是Adagrad的扩展,仍然是对学习率进行自适应约束,但进行了计算上的简化,只递归累加之前固定数量w个的梯度平方之和,并且也不直接存储这些项,仅近似计算对应的平均值。Adadelta将Adagrad公式中的对角矩阵G替换为 ![E[g^{2}]_{t}](http://img.e-com-net.com/image/info8/d8f8b55efe4e44aaab34e5f325ebdcc6.gif) , 表示t时刻之前w个梯度平方的动态衰减平均值:
, 表示t时刻之前w个梯度平方的动态衰减平均值:
![]()
![]()
![]()
其中γ为类似动量项的超参,在0.9左右。这个分母相当于梯度的均方根误差root mean squared error(RMSE)。为了使更新有与参数相同的假设单元,定义一个指数衰减平均值,这次不是梯度平方 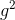 而是参数平方的更新
而是参数平方的更新![]() :
:
![]()
![]()
此时参数的更新仍然依赖全局学习率。经过近似牛顿法将学习率η替换为 ![]() 之后:
之后:
![]()
![]()
Adadelta就不依赖于全局学习率η了。这种方法在训练初、中期,加速效果很好;但到了训练后期,会反复在局部最小值附近抖动,主要体现在验证集错误率上,摆脱不了局部极小值吸引盆。此时切换为动量SGD,并将学习率降低一个量级,就可以使验证集正确率有2%~5%的提升。
Adadelta算法流程:
Require:DecayRate γ,Constant ϵ,InitialParam 
Initialize accumulation variables ![]()
For t=1 to T:
Compute gradients: ![]()
Accumulate gradient: ![]()
Compute update: ![]()
Accumulate updates: ![]()
Apply update: ![]()
5、均方根传播RMSprop
RMSprop是Hinton在Coursera公开课上提出的一种自适应学习率方法,和Adadelta一样都是为了解决Adagrad学习率急剧下降的问题。RMSprop同样使用指数加权平均来消除梯度下降中摆动,但仍依赖于全局学习率η,效果介于Adagrad和Adadelta之间。
![]()
![]()
超参数设置建议为γ=0.9,η=0.001。这种方法适用于非稳态non-stationary和在线问题,对RNN效果很好。
6、Adaptive Moment Estimation
Adam也是一种为每个参数计算自适应学习率的方法,相当于带有动量项的Adadelta/RMSprop,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,即除了和Adadelta/RMSprop一样存储了过去梯度平方  的指数衰减平均值,也像Momentum一样保持了过去梯度
的指数衰减平均值,也像Momentum一样保持了过去梯度  的指数衰减平均值:
的指数衰减平均值:
![]()
![]()
和 分别为梯度的一阶矩估计和二阶矩估计,可以看作对期望 ![]() ,
,![]() 的估计;
的估计; 、
、 的值接近于1,因此矩估计的偏差接近于0,通过计算偏差修正bias-corrected后的估计
的值接近于1,因此矩估计的偏差接近于0,通过计算偏差修正bias-corrected后的估计 ![]() 和
和 ![]() ,并得到Adam的参数更新公式:
,并得到Adam的参数更新公式:
![]()
![]()
![]()
超参数设置建议为 ![]() 。可以看出直接对梯度的矩估计对内存需求较小,而且可以根据梯度进行动态调整;而对学习率形成一个动态约束,且有明确的范围。
。可以看出直接对梯度的矩估计对内存需求较小,而且可以根据梯度进行动态调整;而对学习率形成一个动态约束,且有明确的范围。
Adam的偏差修正令其在梯度变得稀疏时要比RMSprop更加快速和优秀,同时又结合了RMSprop善于处理非平稳目标的优点,因此Adam(以及SGD+NAG动量法)是深度学习领域内十分流行的算法。
7、AdaMax
AdaMax是一种基于无穷范数(infinity norm)的Adam变体,对学习率的上限提供了一个更简单的范围。Adam中参数的更新规则是,将其梯度与过去&当前梯度的L2范数 ![]() 成反比例缩放,推广到基于Lp范数的更新规则后,这样的变体虽然随着p值变大而在数值上变得不稳定(因此一般只使用L1或L2),但在特例p→∞时会得到一个及其稳定和简单的算法。在使用Lp范数时,时间t下的步长和
成反比例缩放,推广到基于Lp范数的更新规则后,这样的变体虽然随着p值变大而在数值上变得不稳定(因此一般只使用L1或L2),但在特例p→∞时会得到一个及其稳定和简单的算法。在使用Lp范数时,时间t下的步长和 ![]() 成反比例变化,推导如下:
成反比例变化,推导如下:
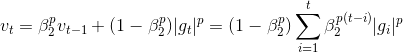
令p→∞并定义:
其中初始值 ![]() 。由于
。由于 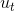 取最大值的操作不容易向0偏置,因此不需要像Adam中的 和 一样修正初始化偏差,AdaMax参数更新公式为:
取最大值的操作不容易向0偏置,因此不需要像Adam中的 和 一样修正初始化偏差,AdaMax参数更新公式为:
![]()
超参数设置建议为 ![]() 。
。
8、Nadam
Nadam相当于NAG+Adam,为了将NAG动量项加入Adam,需要修改动量项 ,回顾之前的动量更新公式,γ为动量衰减项:
![]()
![]()
![]()
NAG允许我们在梯度方向上执行一个更精确的步骤,方法是在计算梯度之前用动量步骤更新参数。这样只需要修改  即可实现NAG:
即可实现NAG:
![]()
使用look-ahead动量 代替 ![]() 直接更新当前的参数
直接更新当前的参数 ![]() :
:![]() ,为了将Nesterov动量加入Adam,可以近似地将前一个动量替换为当前动量,由Adam更新公式(不对 进行修正):
,为了将Nesterov动量加入Adam,可以近似地将前一个动量替换为当前动量,由Adam更新公式(不对 进行修正):
![]()
![]()
再次将 ![]() 替换为
替换为 ![]() 即可得到Nadam的更新公式:
即可得到Nadam的更新公式:
![]()
可以看出Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。
9、FTRL
Follow-The-Regularized-Leader是Google经过三年时间(2010-2013)从理论研究到实际工程化的一种在线学习算法,在处理诸如逻辑回归之类的带非光滑正则项(L1-norm)的凸优化问题的性能非常出色。在线学习不需要cache所有的数据,以流式处理方式就可以处理任意数量的样本,分为在线凸优化和在线Bayesian两种:
在线凸优化的方法有很多,如Truncated Gradient、FOBOS、RDA(Regularized Dual Averaging)、FTRL等;
在线Bayesian方法有AdPredictor算法、基于内容的在线矩阵分解算法等。
FTRL是一种适合处理超大规模数据的、含大量稀疏特征的在线学习常见的优化算法,常用于更新在线的CTR预估模型;结合了FOBOS精度较高和RDA稀疏性好的优势,在L1范数或其他非光滑的正则项下,FTRL比前两者更加有效。

三、优化算法的选择和比较
(1)对于稀疏数据,尽量使用学习率可以自适应的优化方法,不需要手动调节η;
(2)RMSprop是Adagrad的扩展,解决了Adagrad学习率迅速下降的问题;与Adadelta类似,后者使用RMS的参数更新方法;Adam是添加了偏置校正和动量项的RMSprop。Adagrad,Adadelta,RMSprop,Adam都是比较相近的算法,在相似的情况下表现良好。Adam在优化后期梯度变得稀疏时效果比RMSprop稍好一些,因此推荐使用Adam算法;
(3)一般在想要使用带动量项的RMSprop或Adam时,大多数都可以使用Nadam取得更好的效果。
(4)SGD通常训练时间很长,容易陷入鞍点,但是在采取robust的初始化、退火规划annealing schedule、data shuffling和early stopping等合理措施的情况下,结果更加可靠;
(5)如果需要更快的收敛,且需要训练较深较为复杂的网络时,推荐使用学习率自适应的优化方法;

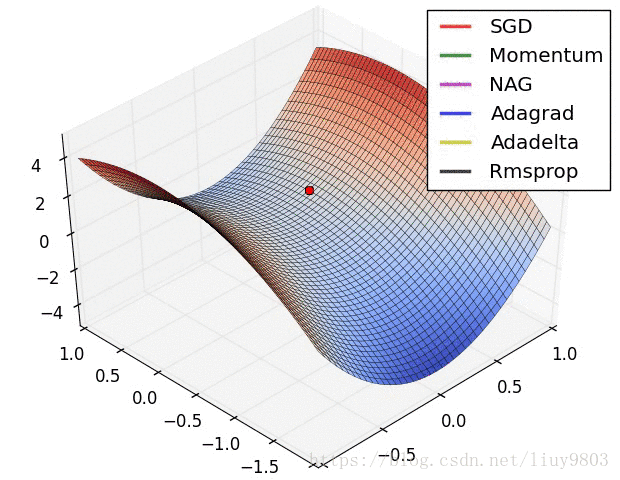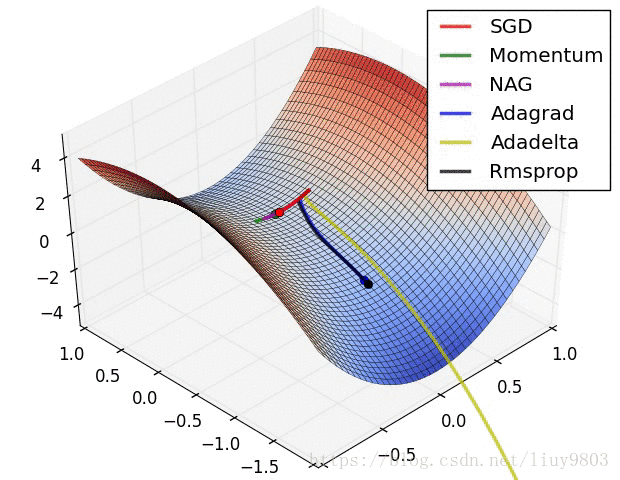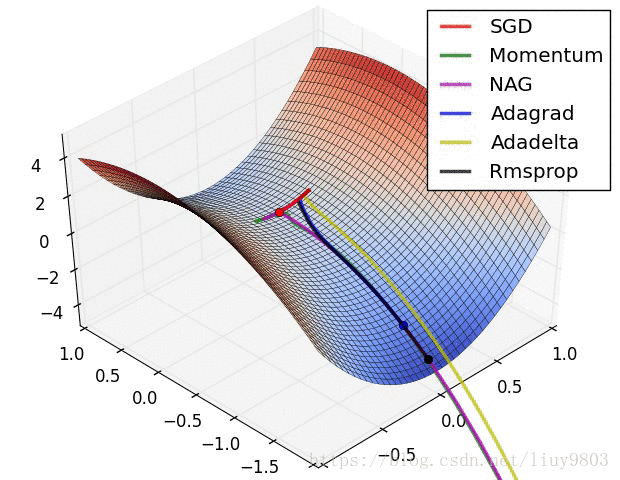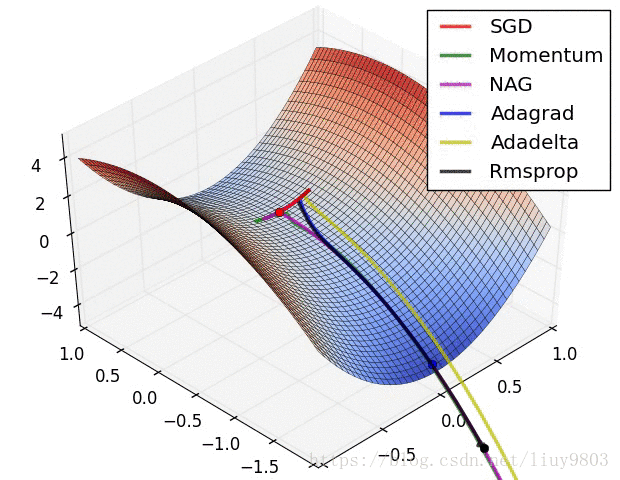
参考资料
https://arxiv.org/pdf/1609.04747.pdf
https://blog.csdn.net/tsyccnh/article/details/76270707
https://www.cnblogs.com/guoyaohua/p/8542554.html
https://blog.csdn.net/leadai/article/details/79178787
https://www.cnblogs.com/neopenx/p/4768388.html
https://blog.csdn.net/u012759136/article/details/52302426
http://www.cnblogs.com/EE-NovRain/p/3810737.html
https://blog.csdn.net/u012767526/article/details/51407443