RabbitMQ入门 用途说明和深入理解
RabbitMQ 在上一家公司已经接触过了, 但是懵懵懂懂的. 不是很清楚. 具体怎么个逻辑.
这次公司打算搭建新的系统. 领导要求研究一下MQ.
经过研究得出的结论是. MSMQ的设计理念不适合做系统的底层框架. 他不适合做分布式系统. 最主要的是. MSMQ如果没有消费者, 默认消息是一直存在的.
而RabbitMQ的设计理念是.只要有接收消息的队列. 邮件就会存放到队列里. 直到订阅人取走. . 如果没有可以接收这个消息的消息队列. 默认是抛弃这个消息的…
下面就把我的研究结果写一下.
###如何在新的系统中使用RabbitMQ.
系统设计的两个重大问题.
第一条要满足未来的业务需求的不断变化和增加. 也就是可扩展性.
第二条要满足性能的可伸缩性. 也就是可集群性…通过增加机器能处理更多的请求
第三条要解耦合.
如果不解耦合, 未来业务增加或变更的时候你还在修改3年前写的代码.试问你有多大的把握保证升级好系统不出问题? 如何可以写新的代码而不用修改老代码所带来的好处谁都知道…
第四条简单易懂.
以上4条在任何一个系统中都要遵循的原则. 以前是无法做到的. 自从有了MQ以后. 这些都可以同时做到了.
以前的设计理念是把系统看作一个人,按照工作的指令从上到下的执行.
现在要建立的概念是, 把系统的各个功能看作不同的人. 人与人之间的沟通通过消息进行交流传递信息…
有了MQ以后把一个人的事情分给了不同的人, 分工合作所带来的好处是专业化, 并行化. 当然也引入了一些麻烦,性能开销多一些, 工作任务的完整性不能立即得到反馈.幸好我们可以通过最终一致性.来解决这个麻烦的问题…
下面进入正题.
###第一个问题RabbitMQ是如何支持可扩展性的.

如上图, 寄件人P是系统的一个功能模块. 用来发送消息. 一般是在某些重要的业务状态变更时发送消息. 例如: 新订单产生时, 订单已打包时, 订单已出库时, 订单已发出时.
那么当事件 新订单产生时, 我们需要把这个信息告诉谁呢? 给财务? 还是给仓库发货?
这个地方最大的重点是. 当事件产生时. 根本不关心. 该投递给谁.
我只要把我的重要的信息投到这个乱七八糟的MQ系统即可. 其它人你该干嘛干嘛. 反正我的任务完成了. (有没有甩手掌柜的感觉…)
我只要告诉系统,我的事件属于那一类.
例如: “某某省.某某市.某某公司.产生新订单”
那么这个地址就属于 投递地址在MQ中叫 RoutingKey… 至于这个地址具体投到哪个邮箱那是邮局的事情.
那么下一个问题来了, 邮局怎么知道 你的这个消息应该投递给谁?
参考我们现实世界中的邮寄系统.是默认的省市县这么投递的. 这是固定思维.
但是我们的MQ系统中不是这样的. 是先有收件人的邮箱. (队列Queue). MQ才能投递. 否则MQ系统也不知道该投递给谁, 默认会丢弃这个信息. 这也就是发布订阅模式的由来, 无人订阅的报纸最后就扔垃圾堆了…
所以MQ系统应该先有收件人的邮箱 Queue 也就是队列. 才能接收到信息.
再有邮局
再有发信息的人.
是倒过来的, .
系统第一次上线的时候要倒着启动. 先启动订阅端,再启动发布端. 后面再发布就无所谓了启动顺序了.因为投递关系MQ系统已经知道了
RabbitMQ能实现系统扩展的一个重要功能在于, 可以两个邮箱收同一个地址的信.
翻译成专业的话 RabbitMQ 可以 两个队列Queue订阅同一个RoutingKey的信息…
RabbitMQ在投递的时候,会把一份信息,投递到多个队列邮箱中Queue…
这是系统可扩展性的基础.
###第二个问题RabbitMQ如何满足性能的可伸缩性. 也就是可集群性
先上图

从上图, 可以看到. 性能扩展的关键点就在于 订阅人C1, 订阅人C2 轮流收到邮箱队列里面的信息, 订阅人C1和订阅人C2收到的信息内容不同, 但都属于同一类…
所以. 订阅人C1和订阅人C2是干同一种工作的客户端.用来提高处理能力.
上面说完了,如何使用. 下面再分析一下几个关注点.
###如果订阅人的down机了. 信息会丢失吗?
事实上是不会的. 只要有邮箱(队列Queue)存在.信息就一直存在, 除非订阅人去取走.
###如果订阅人一直down机, 邮箱队列能存多少信息?会不会爆掉?
理论上和实际上都是有上限的不可能无限多. 具体多少看硬盘吧…我没测到过上限.
我这篇文章并不打算讲解邮局的4种投递模式. 有其它文章讲的很好. 我只打算使用topic这种模式. 因为它更灵活一些.
再说一下我的另外两个观点.
不要在业务程序中用代码定义创建 邮局 ExChange. 和邮箱Queue队列 这属于系统设计者要构架的事情. 要有专门独立的程序和规则去创建. 这样可以统一管理事件类型.避免过多的乱七八糟的RoutingKey混乱.
以前建议如上,但是经过实践发现.以上建议并不实用, 新的建议是
RoutingKey要放在消息发送方的代码中定义, 命名规则最好是事件描述,
例如: 销售系统.新订单已审核
邮箱Queue队列名则一定是在消息接收方的代码中定义,命名规则最好是这个客户端接收到消息以后要做什么
例如: 财务系统.当销售订单审核后创建财务记账
至于RoutingKey 与Queue 队列之间的绑定关系, 目前持保守态度,不做建议.
我目前是放在消息接收端中用代码绑定的.
下图是一些功能截图.
同样的队列名称时
然后是关掉一个消息接收窗口后,剩下的窗口会一直接收这个消息.

不同的队列名称时
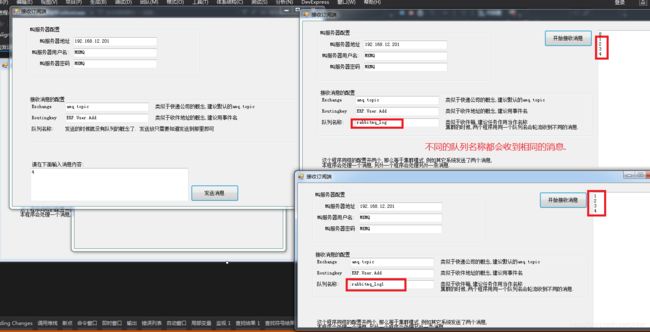
我的理解认为
消息系统的分布式可扩展的实现在于消息广播, 集群性的实现在于邮箱队列.
RabbitMQ是先广播后队列的.
Exchange: 就是邮局的概念等同于 中国邮政和顺丰快递、
routingkey: 就是邮件地址的概念.
queue: 就是邮箱接收软件,但是可以接收多个地址的邮件,通过bind实现。
producer: 消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
其它关于投递模式, 请参考下面的两篇文章.
参考文章:
http://blog.csdn.net/samxx8/article/details/47417133
http://www.cnblogs.com/zlfoak/p/5521673.html
我写的示例
https://download.csdn.net/download/phker/11272096