分布式常用组件面试准备
一、基本说明
上一节已经讲了分布式系统的常见面试题,但是玩过分布式的应该都知道,你一个分布式架构光靠什么dubbo或者spring cloud等是玩不通的。最起码分布式锁啊,分布式事务啊,分布式session啊,,,这些你总要考虑吧?
你们刚才在聊的面试topic,是分布式系统,他其实已经跟你聊完了spring cloud以及相关的一些问题,确认,你现在分布式服务框架,rpc框架,基本都有一些认知。可能开始要跟你聊分布式相关的其他问题了。。。
二、zookeeper的使用场景
1、面试题
zk都有哪些使用场景?
2、面试官心里分析
分布式锁这个东西,很常用的,你做java系统开发,分布式系统,可能会有一些场景会用到。最常用的分布式锁就是zookeeper来做分布式锁。
其实说实话,问这个问题,一般就是看看你是否了解zk,因为zk是分布式系统中很常见的一个基础系统。而且问的话常问的就是说zk的使用场景是什么?看你知道不知道一些基本的使用场景。但是其实zk挖深了自然是可以问的很深很深的。
3、面试题剖析
大致来说,zk的使用场景如下,我就举几个简单的:
分布式协调
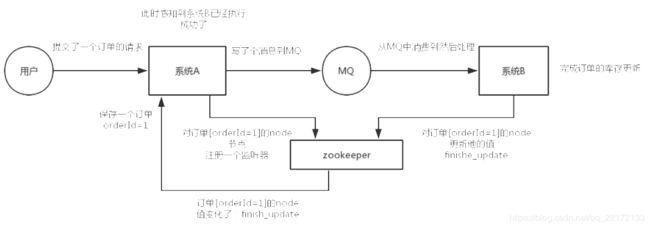
这个其实是zk很经典的一个用法,简单来说,就好比,你A系统发送个请求到mq,然后B消息消费之后处理了。那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作。A系统发送请求之后可以在zk上对某个节点的值注册个监听器,一旦B系统处理完了就修改zk那个节点的值,A立马就可以收到通知,完美解决。
分布式锁
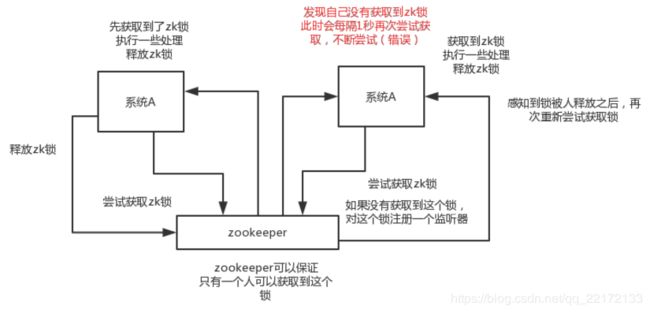
对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行另外一个机器再执行。那么此时就可以使用zk分布式锁,一个机器接收到了请求之后先获取zk上的一把分布式锁,就是可以去创建一个znode,接着执行操作;然后另外一个机器也尝试去创建那个znode,结果发现自己创建不了,因为被别人创建了。那只能等着,等第一个机器执行完了自己再执行。
元数据/配置信息管理
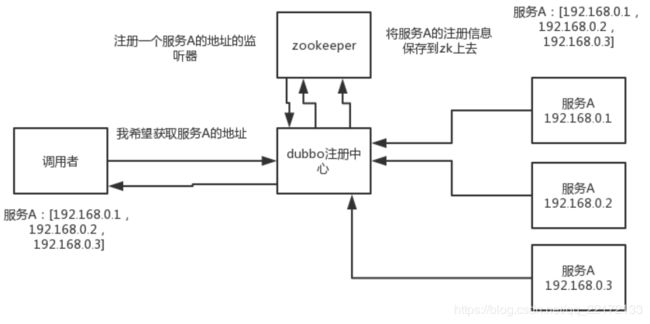
zk可以用作很多系统的配置信息的管理,比如kafka、storm等等很多分布式系统都会选用zk来做一些元数据、配置信息的管理,包括dubbo注册中心不也支持zk么。
HA高可用性
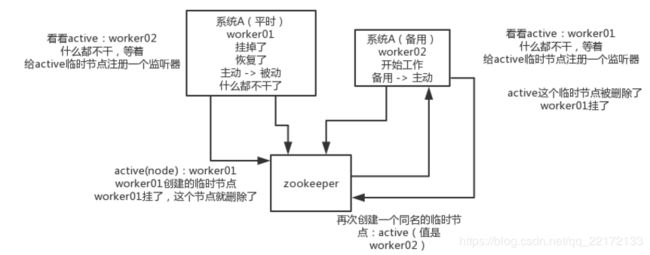
这个应该是很常见的,比如hadoop、hdfs、yarn等很多大数据系统,都选择基于zk来开发HA高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过zk感知到切换到备用进程。
三、分布式锁
1、面试题
一般实现分布式锁都有哪些方式?使用redis如何设计分布式锁?使用zk来设计分布式锁可以吗?这两种分布式锁的实现方式哪种效率比较高?
2、面试官心里分析
其实一般问问题,都是这么问的,先问问你zk,然后其实是要过度的zk关联的一些问题里去,比如分布式锁。因为在分布式系统开发中,分布式锁的使用场景还是很常见的。
3、面试题剖析
1.redis分布式锁
官方叫做RedLock算法,是redis官方支持的分布式锁算法。这个分布式锁有3个重要的考量点,互斥(只能有一个客户端获取锁),不能死锁,容错(大部分redis节点或者这个锁就可以加可以释放)。
第一个最普通的实现方式,如果就是在redis里创建一个key算加锁。
SET my:lock 随机值 NX PX 30000这个命令就ok,这个的NX的意思就是只有key不存在的时候才会设置成功,PX 30000的意思是30秒后锁自动释放。别人创建的时候如果发现已经有了就不能加锁了。
释放锁就是删除key,但是一般可以用lua脚本删除,判断value一样才删除。关于redis如何执行lua脚本,自行百度。
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end为啥要用随机值呢?因为如果某个客户端获取到了锁,但是阻塞了很长时间才执行完,此时可能已经自动释放锁了,此时可能别的客户端已经获取到了这个锁,要是你这个时候直接删除key的话会有问题,所以得用随机值加上面的lua脚本来释放锁。
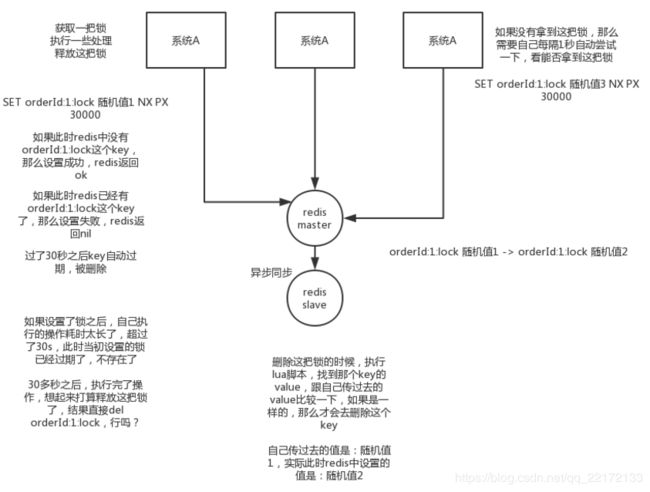
但是这样是肯定不行的。因为如果是普通的redis单实例,那就是单点故障。或者是redis普通主从,那redis主从异步复制,如果主节点挂了,key还没同步到从节点,此时从节点切换为主节点,别人就会拿到锁。
第二个问题,RedLock算法。
这个场景是假设有一个redis cluster,有5个redis master实例。然后执行如下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒
- 跟上面类似,轮流尝试在每个master节点上创建锁,过期时间较短,一般就几十毫秒
- 尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1)
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
- 要是锁建立失败了,那么就依次删除这个锁
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
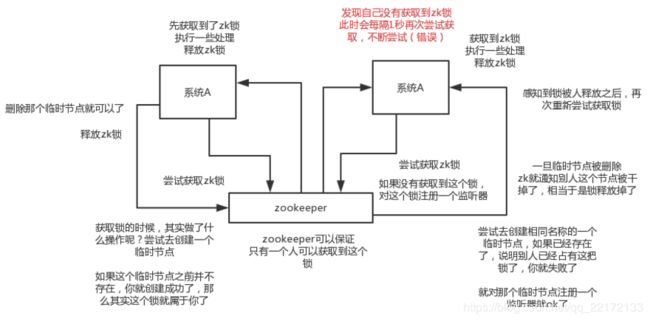
2.zk分布式锁
zk分布式锁,其实可以做的比较简单,就是某个节点尝试创建临时znode,此时创建成功了就获取了这个锁;这个时候别的客户端来创建锁会失败,只能注册个监听器监听这个锁。释放锁就是删除这个znode,一旦释放掉就会通知客户端,然后有一个等待着的客户端就可以再次重新枷锁。
3.redis分布式锁和zk分布式锁的对比
redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能;zk分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小。
另外一点就是,如果是redis获取锁的那个客户端bug了或者挂了,那么只能等待超时时间之后才能释放锁;而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁。
redis分布式锁大家没发现好麻烦吗?遍历上锁,计算时间等等。。。zk的分布式锁语义清晰实现简单。所以先不分析太多的东西,就说这两点,我个人实践认为zk的分布式锁比redis的分布式锁牢靠、而且模型简单易用。
四、分布式session方案
1、面试题
集群部署时的分布式session如何实现?
2、面试官心里分析
面试官问了你一堆dubbo是怎么玩儿的,你会玩儿dubbo就可以把单块系统弄成分布式系统,然后分布式之后接踵而来的就是一堆问题,最大的问题就是分布式事务、接口幂等性、分布式锁,还有最后一个就是分布式session。
当然了,分布式系统中的问题何止这么一点,非常之多,复杂度很高,但是这里就是说下常见的几个,也是面试的时候常问的几个。
3、面试题剖析
session是啥?浏览器有个cookie,在一段时间内这个cookie都存在,然后每次发请求过来都带上一个特殊的jsessionid cookie,就根据这个东西,在服务端可以维护一个对应的session域,里面可以放点儿数据。
一般只要你没关掉浏览器,cookie还在,那么对应的那个session就在,但是cookie没了,session就没了。常见于什么购物车之类的东西,还有登录状态保存之类的。
但是你单块系统的时候这么玩儿session没问题啊,但是你要是分布式系统了呢,那么多的服务,session状态在哪儿维护啊?其实方法很多,但是常见常用的是两种:
1.tomcat + redis
这个其实还挺方便的,就是使用session的代码跟以前一样,还是基于tomcat原生的session支持即可,然后就是用一个叫做Tomcat RedisSessionManager的东西,让所有我们部署的tomcat都将session数据存储到redis即可。在tomcat的配置文件中,配置一下
搞一个类似上面的配置即可,你看是不是就是用了RedisSessionManager,然后指定了redis的host和 port就ok了。
还可以用上面这种方式基于redis哨兵支持的redis高可用集群来保存session数据,都是ok的。
2.spring session + redis
分布式会话的这个东西重耦合在tomcat中,如果我要将web容器迁移成jetty,难道你重新把jetty都配置一遍吗?
因为上面那种tomcat + redis的方式好用,但是会严重依赖于web容器,不好将代码移植到其他web容器上去,尤其是你要是换了技术栈咋整?比如换成了spring cloud或者是spring boot之类的。还得好好思忖思忖。
所以现在比较好的还是基于java一站式解决方案,spring了。人家spring基本上包掉了大部分的我们需要使用的框架了,spirng cloud做微服务了,spring boot做脚手架了,所以用sping session是一个很好的选择。实现我们引入依赖:
org.springframework.session
spring-session-data-redis
1.2.1.RELEASE
redis.clients
jedis
2.8.1
spring配置文件中
web.xml
springSessionRepositoryFilter
org.springframework.web.filter.DelegatingFilterProxy
springSessionRepositoryFilter
/*
示例代码
@Controller
@RequestMapping("/test")
public class TestController {
@RequestMapping("/putIntoSession")
@ResponseBody
public String putIntoSession(HttpServletRequest request, String username){
request.getSession().setAttribute("name", “leo”);
return "ok";
}
@RequestMapping("/getFromSession")
@ResponseBody
public String getFromSession(HttpServletRequest request, Model model){
String name = request.getSession().getAttribute("name");
return name;
}
}上面的代码就是ok的,给sping session配置基于redis来存储session数据,然后配置了一个spring session的过滤器,这样的话,session相关操作都会交给spring session来管了。接着在代码中,就用原生的session操作,就是直接基于spring sesion从redis中获取数据了。

实现分布式的会话,有很多种很多种方式,我说的只不过比较常见的两种方式,tomcat + redis早期比较常用;近些年,重耦合到tomcat中去,通过spring session来实现。
五、分布式事务
1、面试题
分布式事务了解吗?你们如何解决分布式事务问题的?
2、面试官心里分析
只要聊到你做了分布式系统,必问分布式事务,你对分布式事务一无所知的话,确实会很坑,你起码得知道有哪些方案,一般怎么来做,每个方案的优缺点是什么。
现在面试,分布式系统成了标配,而分布式系统带来的分布式事务也成了标配了。因为你做系统肯定要用事务吧,那你用事务的话,分布式系统之后肯定要用分布式事务吧。先不说你搞过没有,起码你得明白有哪几种方案,每种方案可能有啥坑?比如TCC方案的网络问题、XA方案的一致性问题
3、面试题剖析
1.两阶段提交方案/XA方案
也叫做两阶段提交事务方案,这个举个例子,比如说你要约几个朋友一块去爬山吧,然后一般会有个牵头的那个人。
第一个阶段,牵头人会提前一个星期问一下团队里的每个人,说,大家伙,下周六我们去爬山,去吗?这个时候牵头人开始等待每个人的回答,如果所有人都说ok,那么就可以决定一起去爬山。如果这个阶段里,任何一个人回答说,我有事不去了,那么就会取消这次活动。
第二个阶段,那下周六大家就一起去爬山了。
所以这个就是所谓的XA事务,两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复ok,那么就正式提交事务,在各个数据库上执行操作;如果任何一个数据库回答不ok,那么就回滚事务。
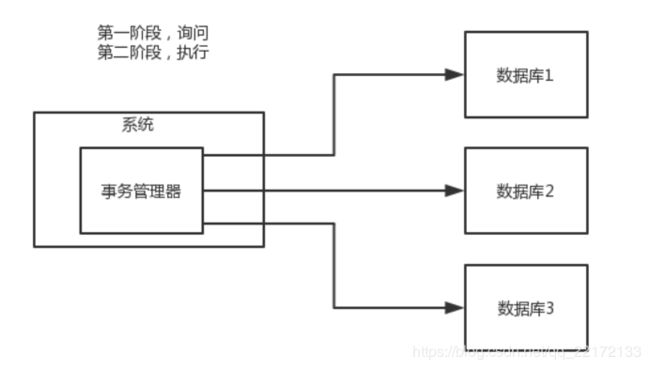
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。如果要玩儿,那么基于spring + JTA就可以搞定,自己随便搜个demo看看就知道了。
这个方案,其实很少用,一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。现在微服务,一个大的系统分成几百个服务,几十个服务。一般来说,我们的规定和规范,是要求说每个服务只能操作自己对应的一个数据库。
如果你要操作别的服务对应的库,不允许直连别的服务的库,违反微服务架构的规范,你随便交叉胡乱访问,几百个服务的话,全体乱套,这样的一套服务是没法管理的,没法治理的,经常数据被别人改错,自己的库被别人写挂。
如果你要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许你交叉访问别人的数据库!
2.TCC方案
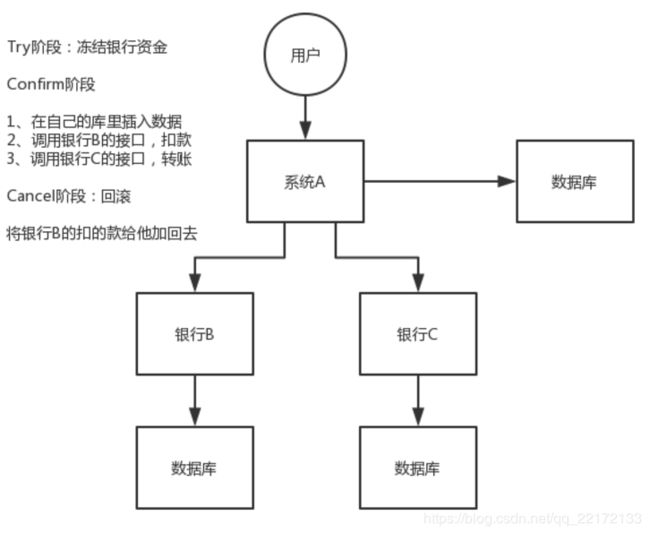
TCC的全称是Try Confirm Cancel,这个其实是用到了补偿的概念,分为了三个阶段:
- Try阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留;
- Confirm阶段:这个阶段说的是在各个服务中执行实际的操作;
- Cancel阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。
给大家举个例子吧,比如说跨银行转账的时候,要涉及到两个银行的分布式事务,如果用TCC方案来实现,思路是这样的:
- Try阶段:先把两个银行账户中的资金给它冻结住就不让操作了;
- Confirm阶段:执行实际的转账操作,A银行账户的资金扣减,B银行账户的资金增加;
- Cancel阶段:如果任何一个银行的操作执行失败,那么就需要回滚进行补偿,就是比如A银行账户如果已经扣减了,但是B银行账户资金增加失败了,那么就得把A银行账户资金给加回去。
这种方案说实话几乎很少用人使用,但是也有使用的场景。因为这个事务回滚实际上是严重依赖于你自己写代码来回滚和补偿了,会造成补偿代码巨大,非常之恶心。
比如说我们,一般来说跟钱相关的,跟钱打交道的,支付、交易相关的场景,这个会用TCC,严格严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,在资金上出现问题。
比较适合的场景,这个就是除非你是真的一致性要求太高,是你系统中核心之核心的场景,比如常见的就是资金类的场景,那你可以用TCC方案了,自己编写大量的业务逻辑,自己判断一个事务中的各个环节是否ok,不ok就执行补偿/回滚代码。而且最好是你的各个业务执行的时间都比较短。
但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码很难维护。
3.本地消息表
国外的ebay搞出来的这么一套思想,这个大概意思是这样的:
- A系统在自己本地一个事务里操作同时,插入一条数据到消息表;
- 接着A系统将这个消息发送到MQ中去;
- B系统接收到消息之后,在一个事务里,往自己本地消息表里插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了,那么此时这个事务会回滚,这样保证不会重复处理消息;
- B系统执行成功之后,就会更新自己本地消息表的状态以及A系统消息表的状态;
- 如果B系统处理失败了,那么就不会更新消息表状态,那么此时A系统会定时扫描自己的消息表,如果有没处理的消息,会再次发送到MQ中去,让B再次处理;
- 这个方案保证了最终一致性,哪怕B事务失败了,但是A会不断重发消息,直到B那边成功为止。
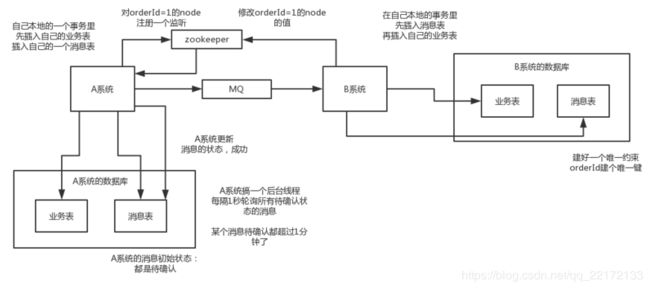
这个方案说实话最大的问题就在于严重依赖于数据库的消息表来管理事务啥的???这个会导致如果是高并发场景咋办呢?咋扩展呢?所以一般确实很少用
4.可靠消息最终一致性方案
这个的意思,就是干脆不要用本地的消息表了,直接基于MQ来实现事务。大概的意思就是:
- A系统先发送一个prepared消息到mq,如果这个prepared消息发送失败那么就直接取消操作别执行了;
- 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉mq发送确认消息,如果失败就告诉mq回滚消息;
- 如果发送了确认消息,那么此时B系统会接收到确认消息,然后执行本地的事务;
- mq会自动定时轮询所有prepared消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认消息?那是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,别确认消息发送失败了;
- 这个方案里,要是系统B的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如B系统本地回滚后,想办法通知系统A也回滚;或者是发送报警由人工来手工回滚和补偿。
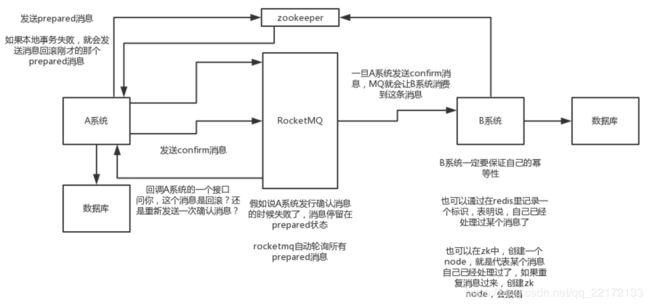
这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你举用RocketMQ支持的,要不你就自己基于类似ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的。
5.最大努力通知方案
这个方案的大致意思就是:
- 系统A本地事务执行完之后,发送个消息到MQ;
- 这里会有个专门消费MQ的最大努力通知服务,这个服务会消费MQ然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统B的接口;
- 要是系统B执行成功就ok了;要是系统B执行失败了,那么最大努力通知服务就定时尝试重新调用系统B,反复N次,最后还是不行就放弃。
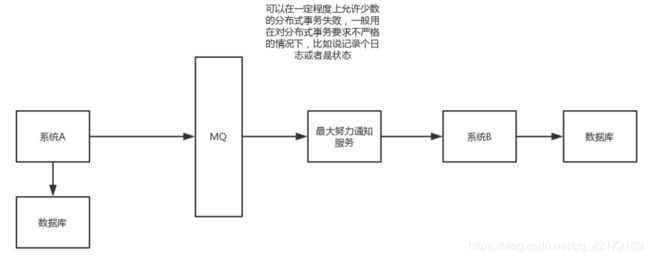
6.你们公司是如何处理分布式事务的?
如果你被问到,你可以这么说,我们某某特别严格的场景,用的是TCC来保证强一致性;然后其他的一些场景基于了RocketMQ来实现了分布式事务。
你找一个严格资金要求绝对不能错的场景,你可以说你是用的TCC方案;如果是一般的分布式事务场景,订单插入之后要调用库存服务更新库存,库存数据没有资金那么的敏感,可以用可靠消息最终一致性方案。
当然如果你愿意,你可以参考可靠消息最终一致性方案来自己实现一套分布式事务,比如基于rabbitmq来玩儿。
六、高并发系统架构
1、面试题
如何设计一个高并发系统?
2、面试官心里分析
说实话,如果面试官问你这个题目,那么你必须要使出全身吃奶劲了。为啥?
因为真正干过高并发的人一定知道,脱离了业务的系统架构都是在纸上谈兵,真正在复杂业务场景而且还高并发的时候,那系统架构一定不是那么简单的,用个redis,用mq就能搞定?当然不是,真实的系统架构搭配上业务之后,会比这种简单的所谓“高并发架构”要复杂很多倍。
如果有面试官问你个问题说,如何设计一个高并发系统?那么不好意思,一定是因为你实际上没干过高并发系统。面试官看你简历就没啥出彩的,感觉就不咋地,所以就会问问你,如何设计一个高并发系统?其实说白了本质就是看看你有没有自己研究过,有没有一定的知识积累。
最好的当然是招聘个真正干过高并发的哥儿们咯,但是这种哥儿们人数稀缺,不好招。所以可能次一点的就是招一个自己研究过的哥儿们,总比招一个啥也不会的哥儿们好吧!
3、面试题剖析
其实所谓的高并发,如果你要理解这个问题呢,其实就得从高并发的根源出发,为啥会有高并发?为啥高并发就很牛逼?
很简单,就是因为刚开始系统都是连接数据库的,但是要知道数据库支撑到每秒并发两三千的时候,基本就快完了。所以才有说,很多公司,刚开始干的时候,技术比较low,结果业务发展太快,有的时候系统扛不住压力就挂了。
当然会挂了,凭什么不挂?你数据库如果瞬间承载每秒5000,8000,甚至上万的并发,一定会宕机,因为比如mysql就压根儿扛不住这么高的并发量。
所以为啥高并发牛逼?就是因为现在用互联网的人越来越多,很多app、网站、系统承载的都是高并发请求,可能高峰期每秒并发量几千,很正常的。如果是什么双十一了之类的,每秒并发几万几十万都有可能。
那么如此之高的并发量,加上原本就如此之复杂的业务,咋玩儿?真正厉害的,一定是在复杂业务系统里玩儿过高并发架构的人,但是你没有,那么我给你说一下你该怎么回答这个问题:
系统拆分,将一个系统拆分为多个子系统,用dubbo来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,不也可以抗高并发么。
缓存,必须得用缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家redis轻轻松松单机几万的并发啊。没问题的。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
MQ,必须得用MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,你要是用redis来承载写那肯定不行,人家是缓存,数据随时就被LRU了,数据格式还无比简单,没有事务支持。所以该用mysql还得用mysql啊。那你咋办?用MQ吧,大量的写请求灌入MQ里,排队慢慢玩儿,后边系统消费后慢慢写,控制在mysql承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用MQ来异步写,提升并发性。MQ单机抗几万并发也是ok的,这个之前还特意说过。
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来抗更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高sql跑的性能。
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
Elasticsearch,可以考虑用es。es是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来抗更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用es来承载,还有一些全文搜索类的操作,也可以考虑用es来承载。
上面的6点,基本就是高并发系统肯定要干的一些事儿,你都可以阐述阐述,表明你对这块是有点积累的。
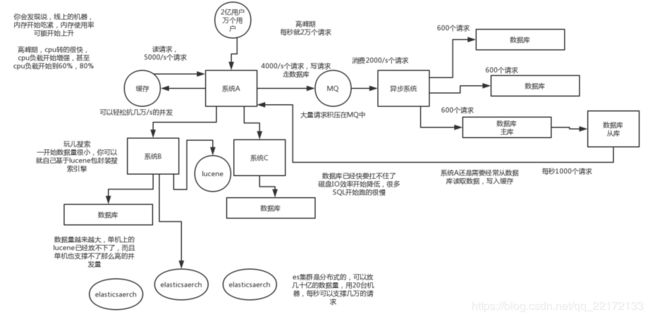
说句实话,毕竟真正你厉害的一点,不是在于弄明白一些技术,或者大概知道一个高并发系统应该长什么样?其实实际上在真正的复杂的业务系统里,做高并发要远远比这个图复杂几十倍到上百倍。你需要考虑,哪些需要分库分表,哪些不需要分库分表,单库单表跟分库分表如何join,哪些数据要放到缓存里去啊,放哪些数据再可以抗掉高并发的请求,你需要完成对一个复杂业务系统的分析之后,然后逐步逐步的加入高并发的系统架构的改造,这个过程是务必复杂的,一旦做过一次,一旦做好了,你在这个市场上就会非常的吃香。