搭建ES-filebeat-logstrash-kibana的心路历程
1:各部分组件功能
Es 全文索引
filebeat 日志采集器
logstash 对filebeat的日志进行解析提取
kibana连接es进行数据展示,统计报表
2:Es在linux\windows下的安装
直接下载对应系统的安装文件解压,修改elasticsearch.yml
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: G:\es\data\es\data
#
# Path to log files:
#
path.logs: G:\es\data\es\log
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
修改jvm.options
-Xms1g
-Xmx1g
直接启动(
linux用户不能再root账户中启动,增加es用户并赋予文件夹权
*****给用户组下的用户授予文件夹拥有者 chown -R es:root / 或者开放文件夹权限,或者将当前用户添加到root用户组等等 ****
启动./bin/elasticsearch)
windows用户直接双击elasticsearch.bat
3:logstash启动配置
下载对应系统logstash解压
修改jvm.options
-Xms1g
-Xmx1g
修改logstash-sample.conf 为logstash.conf
内容为
input {
beats {
port => "5044"
}
}
filter {
grok {
match =>{
"message" => "%{INT: timestamp} %{IPV4:client} %{HOSTNAME:domain} %{URIPATHPARAM:request} %{INT:size1} %{INT:size2} %{INT:size3} %{INT:size4} %{WORD:name} %{INT:size5}"
}
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
其中filter部分可以不要 需要对message字段进行提取解析则需要配置grok表达式
linux启动logstash bin/logstash -e -f ./config/logstash.conf
windows启动 logstash.bat -e -f ./config/logstash.conf
具体启动参数列表见https://blog.csdn.net/jiankunking/article/details/67636487
logstash 常用解析插件:https://segmentfault.com/a/1190000011721483
logstah 自动监听配置文件更新:https://blog.csdn.net/qq_32292967/article/details/78622647
4:filebeat使用
下载解压对应系统版本
修改filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- G:\es\origindata\*
输出到logstash关闭输出到es的配置
================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Enabled ilm (beta) to use index lifecycle management instead daily indices.
#ilm.enabled: false
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
启动:
linux启动 ./filebeat -e -c filebeat.yml -d "public"
windows启动 cmd 到filebeat目录 执行 filebeat -e -c filebeat.yml -d "public"
5:kibana的使用
配置kibana.yml 端口指定下就行
windows直接运行kibana.bat linux执行 ./kibana
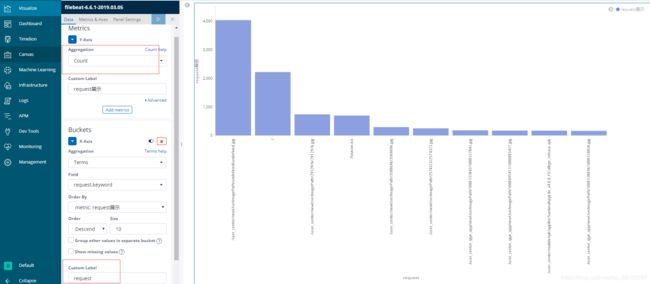
kibana制作图表
在配置了logstash的grok的前提下
在kibana的managerment里面 Elasticsearch->Index management>点击文件夹(索引)可以看到右侧索引的信息,mapping中可以看到gro看信息提取的结果
在kibana的managerment里面 Kibana->Index Parteners->create index pattern (创建日志文件匹配,根据文件名比如源日志文件名aaa.log、aaabb.log 、aa.log 那么填写aaa*将匹配前两个文件,创建完成后可以在visualize创建各个维度的图形,保存后可以集中显示在dashboard
最下面为grok提取的字段名称