内存计算指数据事先存储于内存,各步骤中间结果不落硬盘的计算方式,适合性能要求较高,并发较大的情况。
HANA、TimesTen等内存数据库可实现内存计算,但这类产品价格昂贵结构复杂实施困难,总体拥有成本较高。本文介绍的集算器同样可实现内存计算,而且结构简单实施方便,是一种轻量级内存计算引擎。
下面就来介绍一下集算器实现内存计算的一般过程。
一、 启动服务器
集算器有两种部署方式:独立部署、内嵌部署,区别首先在于启动方式有所不同。
l 独立部署
作为独立服务部署时,集算器与应用系统分别使用不同的JVM,两者可以部署在同一台机器上,也可分别部署。应用系统通常使用集算器驱动(ODBC或JDBC)访问集算服务,也可通过HTTP访问。
n Windows下启动独立服务,执行“安装目录esProcbinesprocs.exe”,然后点击“启动”按钮。
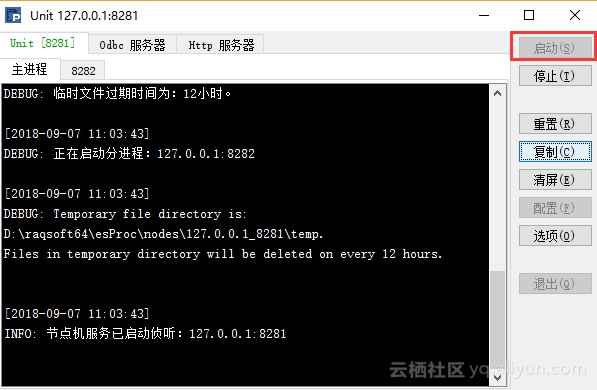
n Linux下应执行“安装目录/esProc/bin/ServerConsole.sh”。
启动服务器及配置参数的细节,请参考: http://doc.raqsoft.com.cn/esproc/tutorial/fuwuqi.html 。
l 内嵌部署
作为内嵌服务部署时,集算器只能与JAVA应用系统集成,两者共享JVM。应用系统通过JDBC访问内嵌的集算服务,无需特意启动。
详情参考 http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html 。
二、 加载数据
加载数据是指通过集算器脚本,将数据库、日志、WebService等外部数据读入内存的过程。
比如Oracle中订单表如下:
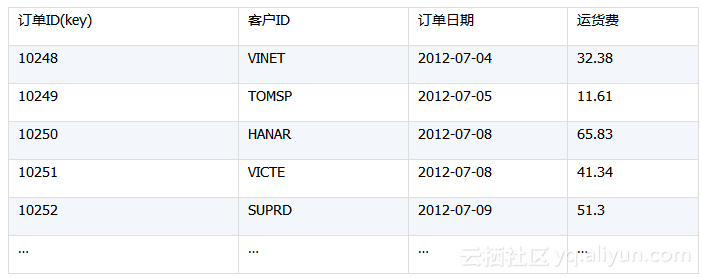
订单明细如下:
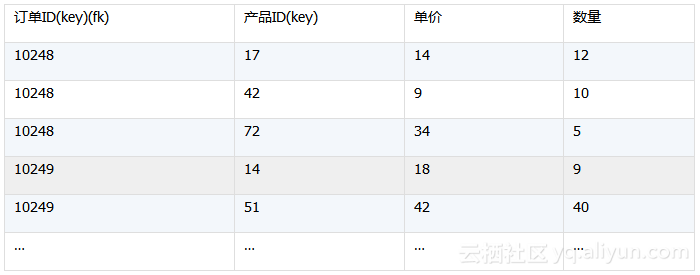
将上述两张表加载到内存,可以使用下面的集算器脚本(initData.dfx):

A1:连接Oracle数据库。
A2-A3:执行SQL查询,分别取出订单表和订单明细表。query@x表示执行SQL后关闭连接。函数keys可建立主键,如果数据库已定义主键,则无需使用该函数。
A4-A5:将两张表常驻内存,分别命名为订单和订单明细,以便将来在业务计算时引用。函数env的作用是设置/释放全局共享变量,以便在同一个JVM下被其他算法引用,这里将内存表设为全局变量,也就是将全表数据保存在内存中,供其他算法使用,也就实现了内存计算。事实上,对于外存表、文件句柄等资源也可以用这个办法设为全局变量,使变量驻留在内存中。
脚本需要执行才能生效。
对于内嵌部署的集算服务,通常在应用系统启动时执行脚本。如果应用系统是JAVA程序,可以在程序中通过JDBC执行initData.dfx,关键代码如下:
1. com.esproc.jdbc.InternalConnection con=null;
2. try {
3. Class.forName("com.esproc.jdbc.InternalDriver");
4. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://");
5. ResultSet rs = con.executeQuery("call initData()");
6. } catch (SQLException e){
7. out.println(e);
8. }finally{
9. if (con!=null) con.close();
10. }
这篇文章详细介绍了JAVA调用集算器的过程 http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html
如果应用系统是JAVA WebServer,那么需要编写一个Servlet,在Servlet的init方法中通过JDBC执行initData.dfx,同时将该servlet设置为启动类,并在web.xml里进行如下配置:
myServlet
com.myCom.myProject.myServlet
3
对于独立部署的集算服务器,JAVA应用系统同样要用JDBC接口执行集算器脚本,用法与内嵌服务类似。区别在于脚本存放于远端,所以需要像下面这样指定服务器地址和端口:
st = con.createStatement();
st.executeQuery("=callx(“initData.dfx”;[“127.0.0.1:8281”])");
如果应用系统非JAVA架构,则应当使用ODBC执行集算器脚本,详见 http://doc.raqsoft.com.cn/esproc/tutorial/odbcbushu.html
对于独立部署的服务器,也可以脱离应用程序,在命令行手工执行initData.dfx。这种情况下需要再写一个脚本(如runOnServer.dfx):

然后在命令行用esprocx.exe调用runOnServer.dfx:
D:raqsoft64esProcbin>esprocx runOnServer.dfx
Linux下用法类似,参考 http://doc.raqsoft.com.cn/esproc/tutorial/minglinghang.html
三、 执行运算获得结果
数据加载到内存之后,就可以编写各种算法进行访问,执行计算并获得结果,下面举例说明:以客户ID为参数,统计该客户每年每月的订单数量。
该算法对应的Oracle中的SQL语句如下:
select to_char(订单日期,'yyyy') AS 年份,to_char(订单日期,'MM') AS 月份, count(1) AS 订单数量 from 订单 where客户ID=? group by to_char(订单日期,'yyyy'),to_char(订单日期,'MM')
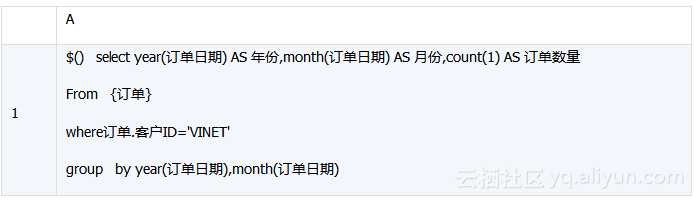
在集算器中,应当编写如下业务算法(algorithm_1.dfx)

为方便调试和维护,也可以分步骤编写:

A1:按客户ID过滤数据。其中,“订单”就是加载数据时定义的全局变量,pCustID是外部参数,用于指定需要统计的客户ID,函数select执行查询。@m表示并行计算,可显著提高性能。
A2:执行分组汇总,输出计算结果。集算器默认返回有表达式的最后一个单元格,也就是A2。如果要返回指定单元的值,可以用return语句
当pCustID=”VINET”时,计算结果如下:
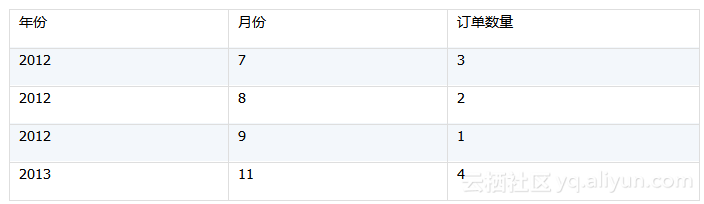
需要注意的是,假如多个业务计算都要对客户ID进行查询,那不妨在加载数据时把订单按客户ID排序,这样后续业务算法中就可以使用二分法进行快速查询,也就是使用select@b函数。具体实现上,initData.dfx中SQL应当改成:
=A1.query("select 订单ID,客户ID,订单日期,运货费 from 订单 order by 客户ID")
相应的,algorithm_1.dfx中的查询应当改成:
=订单.select@b(客户ID==pCustID)
执行脚本获得结果的方法,前面已经提过,下面重点说说报表,这类最常用的应用程序。
由于报表工具都有可视化设计界面,所以无需用JAVA代码调用集算器,只需将数据源配置为指向集算服务,在报表工具中以存储过程的形式调用集算器脚本。
对于内嵌部署的集算服务器,调用语句如下:
call algorithm_1(”VINET”)
由于本例中算法非常简单,所以事实上可以不用编写独立的dfx脚本,而是在报表中直接以SQL方式书写表达式:
=订单.select@m(客户ID==”VINET”).groups(year(订单日期):年份, month(订单日期):月份;count(1):订单数量)
对于独立部署的集算服务器,远程调用语句如下:
=callx(“algorithm_1.dfx”,”VINET”;[“127.0.0.1:8281”])
有时,需要在内存进行的业务算法较少,而web.xml不方便添加启动类,这时可以在业务算法中调用初始化脚本,达到自动初始化的效果,同时也省去编写servlet的过程。具体脚本如下:
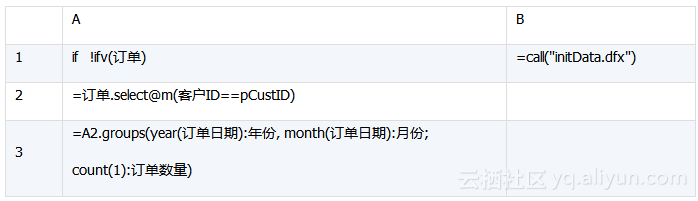
A1-B1:判断是否存在全局变量“订单明细”,如果不存在,则执行初始化数据脚本initData.dfx。
A2-A3:继续执行原算法。
四、 引用思维
前面例子用到了select函数,这个函数的作用与SQL的where语句类似,都可进行条件查询,但两者的底层原理大不相同。where语句每次都会复制一遍数据,生成新的结果集;而select函数只是引用原来的记录指针,并不会复制数据。以按客户查询订单为例,引用和复制的区别如下图所示:
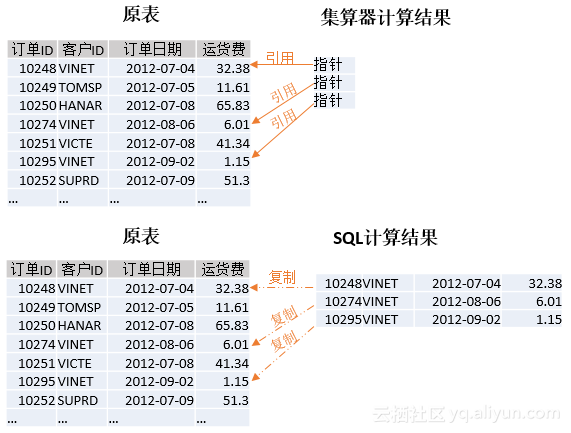
可以看到,集算器由于采用了引用机制,所以计算结果占用空间更小,计算性能更高(分配内存更快)。此外,对于上述计算结果还可再次进行查询,集算器中新结果集同样引用最初的记录,而SQL就要复制出很多新记录。
除了查询之外,还有很多集算器算法都采用了引用思维,比如排序、集合交并补、关联、归并。
五、 常用计算
回顾前面案例,可以看到集算器语句和SQL语句存在如下的对应关系:

事实上,集算器支持完善的结构化数据算法,比如:
l GROUP BY…HAVING

l ORDER BY…ASC/DESC

l DISTINCT

l UNION/UNION ALL/INTERSECT/MINUS
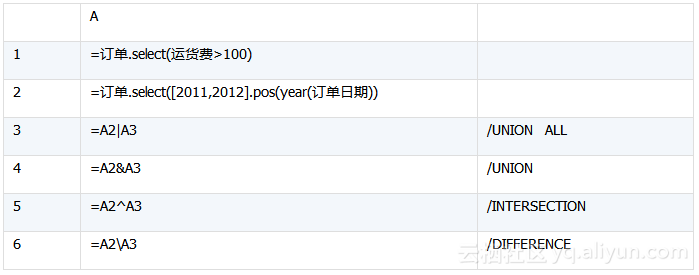
与SQL的交并补不同,集算器只是组合记录指针,并不会复制记录。
l SELECT … FROM (SELECT …)

l SELECT (SELECT … FROM) FROM

l CURSOR/FETCH
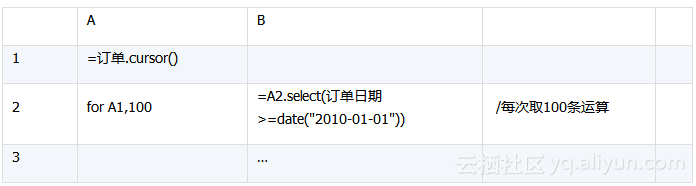
游标有两种用法,其一是外部JAVA程序调用集算器,集算器返回游标,比如下面脚本:

JAVA获得游标后可继续处理,与JDBC访问游标的方法相同。
其二,在集算器内部使用游标,遍历并完成计算。比如下面脚本:
集算器适合解决复杂业务逻辑的计算,但考虑到简单算法占大多数,而很多程序员习惯使用SQL语句,所以集算器也支持所谓“简单SQL”的语法。比如algorithm_1.dfx也可写作:
上述脚本通用于任意SQL,
表 示 执 行 默 认 数 据 源 ( 集 算 器 ) 的
语 句 , 如 果 指 定 数 据 源 名 称 比 如
()表示执行默认数据源(集算器)的SQL语句,如果指定数据源名称比如 (orcl),则可以执行相应数据库(数据源名称是orcl的Oracle数据库)的SQL语句。
from {}语句可从任意集算器表达式取数,比如:from {订单.groups(year(订单日期):年份;count(1):订单数量)}
from 也可从文件或excel取数,比如:from d:/emp.xlsx
简单SQL同样支持join…on…语句,但由于SQL语句(指任意RDB)在关联算法上性能较差,因此不建议轻易使用。对于关联运算,集算器有专门的高性能实现方法,后续章节会有介绍。
简单SQL的详情可以参考: http://doc.raqsoft.com.cn/esproc/func/dbquerysql.html#db_sql_
六、 有序引用
SQL基于无序集合做运算,不能直接用序号取数,只能临时生成序号,效率低且用法繁琐。集算器与SQL体系不同,能够基于有序集合运算,可以直接用序号取数。例如:

函数m()可按指定序号获取成员,参数为负表示倒序。参数也可以是集合,比如m([3,4,5])。而利用函数to()可按起止序号生成集合,to(3,5)=[3,4,5]。
前面例子提到过二分法查询select@b,其实已经利用了集算器有序访问的特点。
有时候我们想取前 N名,常规的思路就是先排序,再按位置取前N个成员,集算器脚本如下:
=订单.sort(订单日期).m(to(100))
对应SQL写法如下:
select top(100) * from 订单 order by 订单日期 --MSSQL
select from (select from 订单 order by 订单日期) where rownum<=100 --Oracle
但上述常规思路要对数据集大排序,运算效率很低。除了常规思路,集算器还有更高效的实现方法:使用函数top。
=订单.top(100;订单日期)
函数top只排序出订单日期最早的N条记录,然后中断排序立刻返回,而不是常规思路那样进行全量排序。由于底层模型的限制,SQL不支持这种高性能算法。
函数top还可应用于计算列,比如拟对订单采取新的运货费规则,求新规则下运货费最大的前100条订单,而新规则是:如果原运货费大于等于1000,则运货费打八折。
集算器脚本为:
=订单.top(-100;if(运货费>=1000,运货费*0.8,运货费))
七、 关联计算
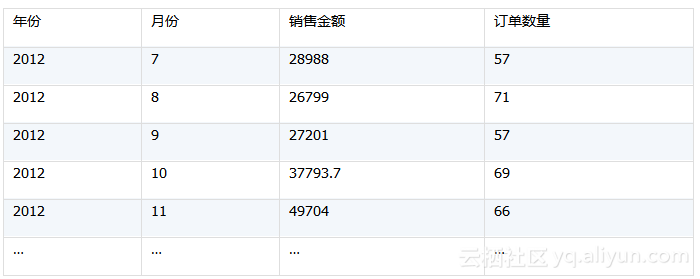
关联计算是关系型数据库的核心算法,在内存计算中应用广泛,比如:统计每年每月的订单数量和订单金额。
该算法对应Oracle的SQL语句为:
select to_char(订单.订单日期,'yyyy') AS 年份,to_char(订单.订单日期,'MM') AS 月份,sum(订单明细.单价*订单明细.数量) AS 销售金额,count(1) AS 订单数量
from 订单明细 left join 订单 on 订单明细.订单ID=订单.订单ID
group by to_char(订单.订单日期,'yyyy'),to_char(订单.订单日期,'MM')
用集算器实现上述算法时,加载数据的脚本不变,业务算法如下(algorithm_2.dfx)
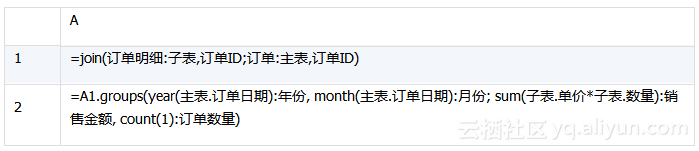

可以看到,集算器join函数与SQL join语句虽然作用一样,但结构原理大不相同。函数join关联形成的结果,其字段值不是原子数据类型,而是记录,后续可用“.”号表达关系引用,多层关联非常方便。
A2:分组汇总。
计算结果如下:
关联关系分很多类,上述订单和订单明细属于其中一类:主子关联。针对主子关联,只需在加载数据时各自按关联字段排序,业务算法中就可用归并算法来提高性能。例如:
=join@m(订单明细:子表,订单ID;订单:主表,订单ID)
函数join@m表示归并关联,只对同序的两个或多个表有效。
集算器的关联计算与RDB不同,RDR对所有类型的关联关系都采用相同的算法,无法进行有针对性的优化,而集算器采取分而治之的理念,对不同类型的关联关系提供了不同的算法,可进行有针对性的透明优化。
除了主子关联,最常用的就是外键关联,常用的外键表(或字典表)有分类、地区、城市、员工、客户等。对于外键关联,集算器也有相应的优化方法,即在数据加载阶段事先建立关联,如此一来业务算法就不必临时关联,性能因此提高,并发时效果尤为明显。另外,集算器用指针建立外键关联,访问速度更快。
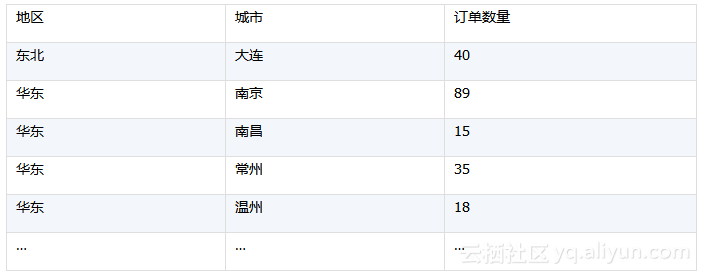
比如这个案例:订单表的客户ID字段是外键,对应客户表(客户ID、客户名称、地区、城市),需要统计出每个地区每个城市的订单数量。
数据加载脚本(initData_3.dfx)如下:

A4:用函数switch建立外键关联,将订单表的客户ID字段,替换为客户表相应记录的指针。
业务算法脚本如下(algorithm_3.dfx)如下

加载数据时已经建立了外键指针关联,所以A1中的“客户ID”表示:订单表的客户ID字段所指向的客户表记录,“客户ID.地区”即客户表的地区字段。
脚本中多处使用“.”号表达关联引用,语法比SQL直观易懂,遇到多表多层关联时尤为便捷。而在SQL中,关联一多如同天书。
上述计算结果如下:
八、 内外混合计算
内存计算虽然快,但是内存有限,因此通常只驻留最常用、并发访问最多的数据,而内存放不下或访问频率低的数据,还是要留在硬盘,用到的时候再临时加载,并与内存数据共同参与计算。这就是所谓的内外混合计算。
下面举例说明集算器中的内外混合计算。
案例描述:某零售行业系统中,订单明细访问频率较低,数据量较大,没必要也没办法常驻内存。现在要将订单明细与内存里的订单关联起来,统计出每年每种产品的销售数量。
数据加载脚本(initData_4.dfx)如下:
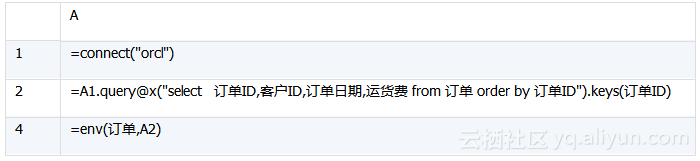
业务算法脚本(algorithm_4.dfx)如下:
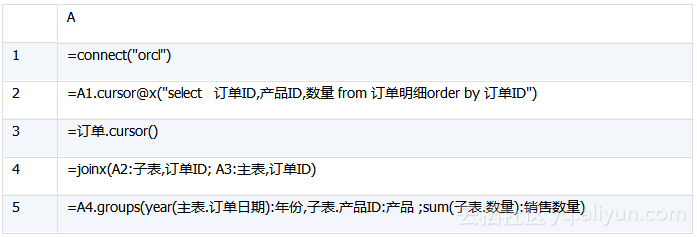
A2:执行SQL,以游标方式取订单明细,以便计算远超内存的大量数据。
A3:将订单表转为游标模式,下一步会用到。
A4:关联订单明细表和订单表。函数joinx与join@m作用类似,都可对有序数据进行归并关联,区别在于前者对游标有效,后者对序表有效。
A5:执行分组汇总。
九、 数据更新
数据库中的物理表总会变化,这种变化应当及时反映到共享的内存表中,才能保证内存计算结果的正确,这种情况下就需要更新内存。如果物理表较小,那么解决起来很容易,只要定时执行初始化数据脚本(initData.dfx)就可以了。但如果物理表太大,就不能这样做了,因为初始化脚本会进行全量加载,本身就会消耗大量时间,而且加载时无法进行内存计算。例如:某零售巨头订单数据量较大,从数据库全量加载到内存通常超过5分钟,但为保证一定的实时性,内存数据又需要5分钟更新一次,显然,两者存在明显的矛盾。
解决思路其实很自然,物理表太大的时候,应该进行增量更新,5分钟的增量业务数据通常很小,增量不会影响更新内存的效率。
要实现增量更新,就需要知道哪些是增量数据,不外乎以下三种方法:
方法A:在原表加标记字段以识别。缺点是会改动原表。
方法B:在原库创建一张“变更表”,将变更的数据记录在内。好处是不动原表,缺点是仍然要动数据库。
方法C:将变更表记录在另一个数据库,或文本文件Excel中。好处是对原数据库不做任何改动,缺点是增加了维护工作量。
集算器支持多数据源计算,所以方法B、C没本质区别,下面就以B为例更新订单表。
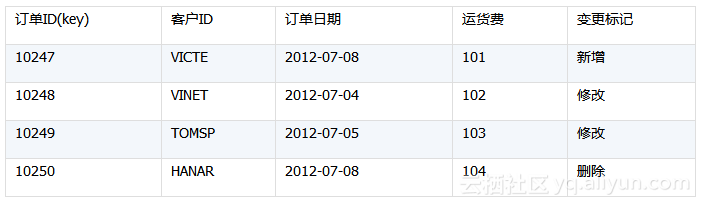
第一步,在数据库中建立“订单变更表”,继承原表字段,新加一个“变更标记”字段,当用户修改原始表时,需要在变更表同步记录。如下所示的订单变更表,表示新增1条修改2条删除1条。
第二步,编写集算器脚本updatemem_4.dfx,进行数据更新。

A1:建立数据库连接。
A2:将内存中的订单复制一份,命名为订单cp。下面过程只针对订单cp进行修改,修改完毕再替代内存中的订单,期间订单仍可正常进行业务计算。
A3:取数据库订单变更表。
A4-B5:取出订单变更表中需删除的记录,在订单cp中找到这些记录,并删除。
A6-B6:取出订单变更表中需新增的记录,在订单cp中追加。
A7-B9:这一步是修改订单cp,相当于先删除再追加。也可用modify函数实现修改。
A10:将修改后的订单cp常驻内存,命名为订单。
A11-A12:清空“变更表”,以便下次取新的变更记录。
上述脚本实现了完整的数据更新,而实际上很多情况下只需要追加数据,这样脚本还会简单很多。
脚本编写完成后,还需第三步:定时5分钟执行该脚本。
定时执行的方法有很多。如果集算器部署为独立服务,与Web应用没有共用JVM,那么可以使用操作系统自带的定时工具(计划任务或crontab),使其定时执行集算器命令(esprocx.exe或esprocx.sh)。
有些web应用有自己的定时任务管理工具,可定时执行某个JAVA类,这时可以编写JAVA类,用JDBC调用集算器脚本。
如果web应用没有定时任务管理工具,那就需要手工实现定时任务,即编写JAVA类,继承java内置的定时类TimerTask,在其中调用集算器脚本,再在启动类中调用定时任务类。
其中启动类myServle4为:
1. import java.io.IOException;
2. import java.util.Timer;
3. import javax.servlet.RequestDispatcher;
4. import javax.servlet.ServletContext;
5. import javax.servlet.ServletException;
6. import javax.servlet.http.HttpServlet;
7. import javax.servlet.http.HttpServletRequest;
8. import javax.servlet.http.HttpServletResponse;
9. import org.apache.commons.lang.StringUtils;
10. public class myServlet4 extends HttpServlet {
11. private static final long serialVersionUID = 1L;
12. private Timer timer1 = null;
13. private Task task1;
14. public ConvergeDataServlet() {
15. super();
16. }
17. public void destroy() {
18. super.destroy();
19. if(timer1!=null){
20. timer1.cancel();
21. }
22. }
23. public void doGet(HttpServletRequest request, HttpServletResponse response)
24. throws ServletException, IOException {
25. }
26. public void doPost(HttpServletRequest request, HttpServletResponse response)
27. throws ServletException, IOException {
28. doGet(request, response);
29. }
30. public void init() throws ServletException {
31. ServletContext context = getServletContext();
32. // 定时刷新时间(5分钟)
33. Long delay = new Long(5);
34. // 启动定时器
35. timer1 = new Timer(true);
36. task1 = new Task(context);
37. timer1.schedule(task1, delay 60 1000, delay 60 1000);
38. }
39. }
定时任务类Task为:
11. import java.util.TimerTask;
12. import javax.servlet.ServletContext;
13. import java.sql.*;
14. import com.esproc.jdbc.*;
15. public class Task extends TimerTask{
16. private ServletContext context;
17. private static boolean isRunning = true;
18. public Task(ServletContext context){
19. this.context = context;
20. }
21. @Override
22. public void run() {
23. if(!isRunning){
24. com.esproc.jdbc.InternalConnection con=null;
25. try {
26. Class.forName("com.esproc.jdbc.InternalDriver");
27. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://");
28. ResultSet rs = con.executeQuery("call updatemem_4()");
29. }
30. catch (SQLException e){
31. out.println(e);
32. }finally{
33. //关闭数据集
34. if (con!=null) con.close();
35. }
36. }
37. }
38. }
十、 综合示例
下面,通过一个综合示例来看一下在数据源多样、算法复杂的情况下,集算器如何很好地实现内存计算:
案例描述:某B2C网站需要试算订单的邮寄总费用,以便在一定成本下挑选合适的邮费规则。大部分情况下,邮费由包裹的总重量决定,但当订单的价格超过指定值时(比如300美元),则提供免费付运。结果需输出各订单邮寄费用以及总费用。
其中订单表已加载到内存,如下:
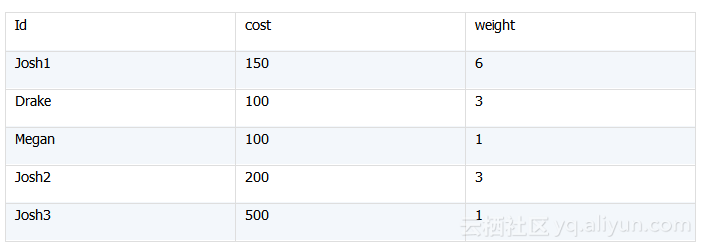
邮费规则每次试算时都不同,因此由参数“pRule”临时传入,格式为json字符串,某次规则如下:
[{"field":"cost","minVal":300,"maxVal":1000000,"Charge":0},
{"field":"weight","minVal":0,"maxVal":1,"Charge":10},
{"field":"weight","minVal":1,"maxVal":5,"Charge":20},
{"field":"weight","minVal":5,"maxVal":10,"Charge":25},
{"field":"weight","minVal":10,"maxVal":1000000,"Charge":40}]
上述json串表示各字段在各种取值范围内时的邮费。第一条记录表示,cost字段取值在300与1000000之间的时候,邮费为0(免费付运);第二条记录表示,weight字段取值在0到1(kg)之间时,邮费为10(美元)。
思路:将json串转为二维表,分别找出filed字段为cost和weight的记录,再对整个订单表进行循环。循环中先判断订单记录中的cost值是否满足免费标准,不满足则根据重量判断邮费档次,之后计算邮费。算完各订单邮费后再计算总邮费,并将汇总结果附加为订单表的最后一条记录。
数据加载过程很简单,这里不再赘述,即:读数据库表,并命名为“订单表”。
业务算法相对复杂,具体如下:
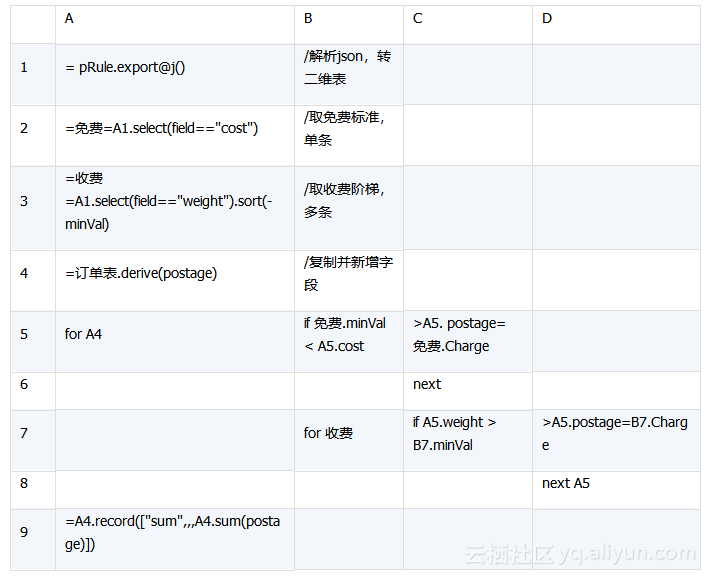
A1:解析json,将其转为二维表。集算器支持多数据源,不仅支持RDB,也支持NOSQL、文件、webService。
A2-A3:查询邮费规则,分为免费和收费两种。
A4:新增空字段postage。
A5-D8:按两种规则循环订单表,计算相应的邮费,并填入postage字段。这里多处用到流程控制,集算器用缩进表示,其中A5、B7为循环语句,C6、D8跳入下一轮循环,B5、C7为判断语句
A9:在订单表追加新纪录,填入汇总值。
计算结果如下:

至此,本文详细介绍了集算器用作内存计算引擎的完整过程,同时包括了常用计算方法和高级运算技巧。可以看到,集算器具有以下显著优点:
l 结构简单实施方便,可快速实现内存计算;
l 支持多种调用接口,应用集成没有障碍;
l 支持透明优化,可显著提升计算性能;
l 支持多种数据源,便于实现混合计算;
l 语法敏捷精妙,可轻松实现复杂业务逻辑。
关于内存计算,还有个多机分布式计算的话题,将在后续文章中进行介绍。