知识图谱构建文献综述---------------非常全面,仅供参考
摘要
知识图谱是以图的形式表现客观世界中的概念和实体及其之间关系的知识库,是语义搜索、智能问答、决策支持等智能服务的基础技术之一。从知识图谱的定义和技术架构出发,对架构知识图谱涉及的关键技术进行了自底向上的全面解析。1)对知识图谱的定义和内涵进行了说明,并给出了构建知识图谱的技术框架、知识图谱的分类以及数据来源;2)按照输入的知识素材的抽象程度将其划分为3个层次:信息抽取层、知识融合和知识加工层; 3)对知识图谱构建技术当前面临的重大挑战和关键问题进行了总结。
关键词:知识图谱;语义网;本体;语义搜索引擎;信息检索;自然语言处理
Abstract
A knowledge graph is a knowledge base that represents objective concepts / entities and their relationship in the form of graph, which is one of the fundamental technologies for intelligent services such as semantic retrieval, intelligent answering, decision, support, etc. In the paper, we introduce the key techniques involved in the construction of knowledge graph in a bottom-up way, starting from a clearly defined concept and a technical architecture of the knowledge graph. Firstly, the definition and connotation of the knowledge graph are explained, and the technical framework for constructing the knowledge graph, the classification of the knowledge graph, and the data source are given. Secondly, according to the abstraction level of the input knowledge material, it is divided into 3 levels: information extraction layer, knowledge integration layer and the knowledge processing layer. Finally, five major research challenges in this area are summarized, and the corresponding key research issues are highlighted.
Keywords:knowledge graph; semantic Web; ontology; semantic search engine; information retrieval; natural language processing
1、知识图谱定义
知识图谱 (knowledge graph) 是以图的形式表现客观世界中的实体、概念及其之间关系的知识库。本质上, 知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,其构成一张巨大的语义网络图,节点表示实体或概念,边则由属性或关系构成。
现在的知识图谱已被用来泛指各种大规模的知识库。知识图谱中包含以下几种节点:
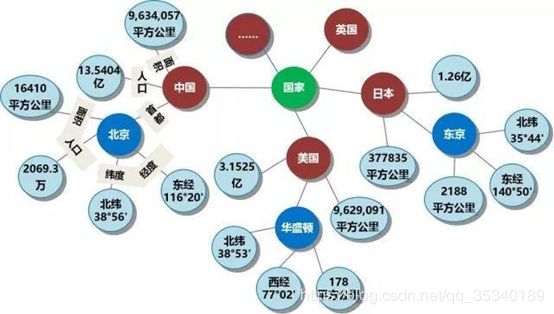
实体: 指的是具有可区别性且独立存在的某种事物。如某一个人、某一个城市、某一种植物等、某一种商品等等。世界万物由具体事物组成,此指实体。如图1-1的“中国”、“美国”、“日本”等。,实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。
语义类(概念):具有同种特性的实体构成的集合,如国家、民族、书籍、电脑等。 概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等。
内容: 通常作为实体和语义类的名字、描述、解释等,可以由文本、图像、音视频等来表达。
属性(值): 从一个实体指向它的属性值。不同的属性类型对应于不同类型属性的边。属性值主要指对象指定属性的值。如图1-1所示的“面积”、“人口”、“首都”是几种不同的属性。属性值主要指对象指定属性的值,例如960万平方公里等。
关系: 形式化为一个函数,它把k个点映射到一个布尔值。在知识图谱上,关系则是一个把k个图节点(实体、语义类、属性值)映射到布尔值的函数。
基于上述定义。基于三元组是知识图谱的一种通用表示方式,即G=(E, R, S),其中 E=e1, e2, …, e|E| 是知识库中的实体集合,共包含|E|种不同实体;R=r1,r2,…,r|E|是知识库中的关系集合,共包含|R|种不同关系;S⊆E×R×E代表知识库中的三元组集合。三元组的基本形式主要包括(实体1-关系-实体2)和(实体-属性-属性值)等。每个实体(概念的外延)可用一个(全局唯一确定的pair,AVP)可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
如下图1的知识图谱例子所示,中国是一个实体,北京是一个实体,中国-首都-北京 是一个(实体-关系-实体)的三元组样例北京是一个实体 ,人口是一种属性2069.3万是属性值。北京-人口-2069.3万构成一个(实体-属性-属性值)的三元组样例。
知识图谱的概念最早由Google提出。2012年5月17日,Google启动知识图谱项目,并以此为基础构建下一代智能化搜索引擎。其中的关键技术包括如何从互联网网页中抽取出实体及其属性信息,以及实体间的关系。以此为基础构建的搜索引擎十分适用于解决与实体相关的智能问答问题,极大地提高搜索引擎的能力,增强了用户的搜索质量以及搜索体验。用户的搜索请求不再局限于简单的关键词匹配,搜索将根据用户查询的情境与意图进行推理,实现概念检索。与此同时,用户的搜索结果也呈现出层次化、结构化等重要特征。与此同时,对于知识图谱的研究与应用也不断发展,越来越多的研究者通过知识图谱将来自互联网等渠道的信息、数据以及关系聚集为知识,根据应用要求构建出各类语义知识库。
2、研究背景
2.1、相关文献
自Google提出知识图谱的概念以来,知识图谱被广泛关注和研究。
实际上,在谷歌提出该概念之前,Tim Berners-Lee就于2006年提出了Linked Data,一种万维网数据上创建语义关联的方法。更早之前,语义链网络(Semantic Link Network)已经开始了系统性的研究,目标是创立一个自组织的语义互联方法来表达知识支持智能应用, 系统性的理论和方法作为专著发表于2004年。而语义链网络研究还可追溯到1998年继承规则的定义和2003年主动文档框架的研发ADF。再往前,可以追溯至上世纪信息学中的本体论。在知识图谱概念与技术的发展过程中,涌现出大量极具价值的学术文献与实践成果。
国内对知识图谱的研究实践也不少。成果包括:清华大学建成了第一个大规模中英文跨语言知识图谱XLore,中国科学院计算技术研究所基于开放知识网络(OpenKN)建立了“人立方、事立方、知立方”原型系统,中国科学院数学与系统科学研究院陆汝钤院士 提出知件(Knowware)的概念,上海交通大学构建并发布了中文知识图谱研究平台zhishi.me等等。
在dblp网站检索最新的知识图谱相关文献,可以了解目前学术界对知识图谱近期的研究进展与热点。近两年,针对知识图谱的研究主要集中于知识图谱构建、知识图谱嵌入、知识图谱应用等方面。近期的学术成果有:SoYeop Yoo总结了知识图谱自动构建与扩展的相关方法,Jia Shu提出了一种针对知识图谱嵌入的半监督模型,Rui Wang利用GAT模型实现知识图谱的嵌入,Anmol Nayak尝试了基于知识图谱实现软件工程测试用例的自动生成等等。
2.2、实际应用
随着研究进展以及知识图谱技术的实践应用,它已发展成为语义搜索、智能问答、决策支持等智能服务的基础技术之一。
☛语义搜索
Google提出知识图谱的概念后,便尝试利用其进行网页的语义搜索,国内的搜索引擎如百度等也致力于利用知识图谱技术来提升用户的搜索体验。传统搜索引擎基于用户输入的关键词检索后台数据库中的 Web 网页,将包含搜索关键词的网页反馈给用户。而语义搜索则首先将用户输入的关键词映射至知识图谱中的一个或一组实体或概念,然后根据知识图谱中的概念层次结构进行解析和推理,向用户返回丰富的相关知识。
基于知识图谱的语义搜索能够实现:
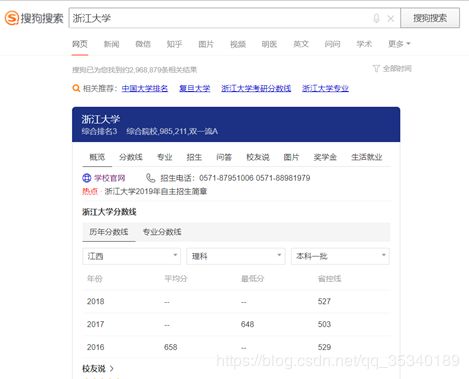
(1)以知识卡片的形式提供结构化的搜索结果。例如,当用户搜索浙江大学时,知识卡片呈现出的内容,包括有学校的地址、邮编、简介、创办年份等相关信息。
(2)通过已有知识图谱中实体的关联,扩展用户搜索结果,发现更多内容,反馈丰富的关联结果。例如,当用户搜索肺炎时,除了对肺炎的介绍之外,搜索结果还能返回“武汉肺炎最新消息”,“最新疫情地图实时数据报告”等信息。
智能问答指用户以自然语言提问的形式提出信息查询需求,系统依据对问题的分析,从各种数据资源中自动找出准确的答案。问答系统是一种信息检索的高级模式,能提升效率、降低人工参与成本。问答系统对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成对知识图谱的查询,最后在知识图谱中查询出需要的答案。
用户提出的问题可以关注某实体的属性,也可以是一些开放性的问题,能通过一定的推理分析查询出相关实体。
智能问答的应用在搜索引擎和语音助手等领域已有所表现。例如,我们可以利用百度搜索如“新型冠状病毒肺炎的主要症状?”,则返回对应的症状;又比如我们可以询问Siri、小爱等智能语音助手问题,获得相应反馈。
☛决策支持
知识图谱的构建推理能支持知识图谱的构建,通过检测原有的知识是否存在逻辑矛盾以及从已知知识中发现未知的关系,保证知识图谱的一致性与完整性,又能丰富和扩展知识图谱。另一方面,知识图谱的应用推理也值得关注。通过添加领域内的知识规则,知识图谱的应用推理可以实现领域知识的推论,辅助自动决策、智能问答和预测等。尤其是面向特定领域的行业知识图谱,能够进行知识推理,实现辅助分析及决策支持等功能,如汽车行业知识图谱等,但这类知识图谱对专业性与准确度的要求高。
3、知识图谱的架构
知识图谱由数据层(data layer)和模式层(schema layer)两部分构成。
模式层是知识图谱的概念模型和逻辑基础,对数据层进行规范约束。如果不需支持推理,则知识图谱可以只有数据层而没有模式层。在知识图谱的模式层,节点表示本体概念,边表示概念间的关系。在数据层,事实以“实体-关系-实体”或“实体-属性-属性值”的三元组存储,形成一个图状知识库。其中,实体是知识图谱的基本元素,指具体的人名、组织机构名、地名、日期、时间等。关系是两个实体之间的语义关系,是模式层所定义关系的实例。属性是对实体的说明,是实体与属性值之间的映射关系。属性可视为实体与属性值之间的hasValue关系,从而也转化为以“实体-关系-实体”的三元组存储。在知识图谱的数据层,节点表示实体,边表示实体间关系或实体的属性。
模式层可利用关系型数据库来存储,包括以下设计:
- 类层次结构
概念类具有层次结构。有些知识图谱采用的是树状的类结构,每个子类继承其祖先节点的属性。 - 类关系定义
类之间存在相互的关系,类之间可以定义单向的关系,也可以定义双向的关系。如果需要定义主逆关系,需要约定其主关系及逆关系。例如歌手指向歌曲的关系是演唱歌曲,歌曲指向歌手的关系是被演唱。 - 类领域定义
为了管理方便,可以定义多个领域便于将概念类进行分组管理。例如音乐域之下会有歌曲,专辑,歌手等类,电影域之下会有影片,导演,演员等类。 - 类属性定义
可以抽取基础属性作为公共属性,例如名称,创建时间之类。另外每个类也有自己的专有属性。
数据存储则可以使用图数据库,类使用图节点存储,关系是用图的边来存储。
4、知识图谱的分类
按构建过程是否依赖自动抽取技术来看,知识图谱大致可分为两类。一类是早期的本体,如WordNet、CYC、HowNet等。这类知识图谱大多由专业人士手工构建,规模较小;但其知识质量高,能够确保准确性与完整性。另一类是从开放的互联网信息中自动抽取实体与关系构建的,如YAGO、DBPedia类知识图谱规模大;但因其数据源的复杂多样及抽取算法的不完全准确,可能会有大量不完整信息、噪声等。近年来,随着知识图谱成为学界及商界的热点,国内也重视知识图谱的研究发展,中文的知识图谱纷纷涌现,如CN-DBpedia、zhishi.me等。
从覆盖范围来看,知识图谱也可分为通用知识图谱与行业知识图谱两类。通用知识图谱(generic knowledge graph)描述全面的常识性的知识,主要应用于语义搜索,对知识的准确度要求不高,如百科类的DBpedia、zhishi.me和语言学类的WordNet、大词林等。通用知识图谱强调知识的广度,大多采用自底向上的方式构建,侧重实体层的扩充,因此也导致其大部分较难构建规范的本体层。行业知识图谱(domain knowledge graph)面向特定领域,能够进行知识推理,实现辅助分析及决策支持等功能,如GeoNames、中医医案知识图谱等。行业知识图谱对等。这对专业性与准确度的要求高,这也要求其必须有严格的本体层模式,通常采用自底向上与自顶向下结合的方式进行构建。通用知识图谱可作为行业知识图谱的构建基础,行业知识图谱也可在构建完成后补充融合至通用知识图谱中。一般来说,通用知识图谱的使用率更高,是现有知识图谱的基础;而行业知识图谱则推进了知识图谱技术融入生活,服务于民。
行业知识图谱广泛应用于金融、电商、医疗等行业。
金融行业通常应用知识图谱进行反欺诈。通过知识图谱,一方面有利于组织相关的知识碎片,通过深入的语义分析与推理,可对信息内容的一致性充分验证,从而识别或提前发现欺诈行为;另一方面,知识图谱本身就是一种基于图结构的关系网络,基于这种图结构能够帮助人们更有效地分析复杂税务关系中存在的潜在风险。在精准营销方面,知识图谱可通过链接的多个数据源,形成对用户或用户群体的完整知识体系描述,从而更好地去认识、理解、分析用户或用户群体的行为。例如,金融公司的市场经理用知识图谱去分析待销售用户群体之间的关系,去发现他们的共同爱好,从而更有针对性地对这类用户人群制定营销策略。
又比如医疗行业知识图谱的应用,医疗图谱将涉及到医院、医师、疾病等等各个方面,通过医疗的认知计算,提供各种医疗临床辅助决策服务。
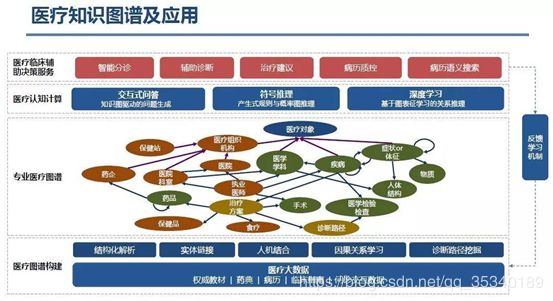
除此之外,很多些垂直行业也可以引入知识图谱,如教育科研行业、图书馆、证券业以及需要进行大数据分析的一些行业。这些行业对整合性和关联性的资源需求迫切,知识图谱可以为其提供更加精确规范的行业数据以及丰富的表达,帮助用户更加便捷地获取行业知识。
5、数据来源
构建知识图谱的数据源主要有:百科类半结构化的网页、结构化程度较低的普通网页、语料库、已构建好的知识库等。所用的数据源影响知识图谱的质量,也影响构建过程。
百科网站有固定的页面模版,每一页面都针对某一概念或实体进行详细的介绍。这样的半结构化形式,更易于实施知识抽取。并且,大多数百科网站知识质量高,权威性强,出错率较低,抽取所得知识的质量更高。广义来讲,符合这些特征的网站都可视为百科网站,如购物网站、电影、音乐网站等,也可以通过相似的方法构建相关领域的知识图谱。
结构化程度较低的普通网页是知识图谱的另一大数据来源。普通网页数据的格式丰富多样,没有较为一致的规范,且包含的知识可能存在大量的冗余和错误,准确率较低。因此,基于普通网页的知识抽取工作的复杂度较高,知识融合的难度更大。此类知识图谱的构建工作重点在于知识抽取与知识融合。卡内基梅隆大学的——“永不停止的语言学习”项目(Never-Ending Language Learning,NELL),就是从上亿个网页中进行知识的抽取。
另外,尤其是行业知识图谱,部分来源于专业知识中,需要从专业的知识库中抽取数据。以电商行业知识图谱为例,电商网站在以商品为中心上,构建起了一种商品概念目录层级以及商品与品牌,品牌与品牌之间的关联关系。从而电商网站中的商品分类目录能够供我们构建起一个商品概念体系,基于商品首页,我们可以得到商品与商品品牌之间的关系,商品的属性以及属性的取值信息。基于这类信息,又可以进一步得到商品的画像以及商品品牌的画像。基于该画像。可以对自然语言处理处理的几个下游应用带来帮助,如商品品牌识别,商品对象及属性级别情感分析,商品评价短语库构建,商品品牌竞争关系梳理等。
很多行业的知识图谱是相对封闭的,一般是由一些专家去构建、去标注。从图谱服务的角度,通用图谱可以让大家都去应用,但是行业图谱是针对特定行业的需求,定制化程度比较高,也有不同的应用方向。所以,相应数据也要求更加专业、有效,满足业务需求。
在数据抽取的同时,需要进行知识更新。随着人们对客观世界的认知加深,信息与知识量不断增加,知识图谱的内容也需要与时俱进,迭代更新,增加新的知识,删除过时的知识。根据知识图谱的逻辑结构,知识图谱的更新可分为模式层更新和数据层更新。模式层更新是指本体中元素的更新,包括概念的增加、修改、删除,概念属性的更新以及概念之间关系的更新等。其中,概念属性的更新操作会直接影响到所有与其直接或间接相关的子概念和实体。因此,模式层更新多数情况下是在人工干预的情况下完成的,需要人工定义规则,人工处理冲突等,实施起来有一定的复杂度。数据层更新指的是实体元素的更新,包括实体以及实体间关系和属性值的增加、修改、删除。由于数据层的更新对知识图谱的整体架构影响较小,通过在可靠数据源(如百科类网站)自动抽取的方式即可完成。根据更新的方式,知识图谱的更新可分为增量更新和完全更新。增量更新是以知识图谱数据源(维基百科等)发布出的更新内容为基础对知识图谱进行部分更新。也可以基于用户在语义搜索平台上的行为,如反馈信息过时或搜索了一个知识图谱中没有的新词而进行相应的更新。完全更新是指间隔一定的周期,重新将知识图谱数据源的全部数据进行一次抽取解析。完全更新的优点在于:能较大程度保证知识图谱更新过程中的逻辑一致性,适用于模式层的更新。但该方法代价昂贵,且耗时长,不能保证时效性。
6、知识图谱构建方式
知识图谱有自顶向下和自底向上两种构建方式。所谓自顶向下构建是指借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中;所谓自底向上构建,则是借助一定的技术手段,从公平采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
在知识图谱技术发展初期,多数参与企业和科研机构都是采用自顶向下的方式构建基础知识库,例如,Freebase项目就是采用维基百科作为主要数据来源。随着自动知识抽取与加工技术的不断成熟,目前的知识图谱大多采用自底向上的方式构建,其中最具影响力的例子包括谷歌的Knowledge Vault和微软的Satori知识库,都是以公开采集的海量网页数据为数据源,通过自动抽取资源的方式来构建、丰富和完善现有的知识库。
6.1、知识图谱的数据结构
从知识图谱数据组织的架构来看,可以把知识图谱的数据分为两个层次,一个是数据模型层,数据模型是按照本体论的思想,勾画出来的数据组织模式,数据模型可以展示数据的组织方式,数据之间的相互关系,创建动植物的数据模型,可以按照动植物的通用分类标准,使用七个主要级别:界、门、纲、目、科、属、种 。可以将动植物的数据按照这个模型进行组织。数据模型可以看作是元数据,依据数据模型,数据才能得到有效的组织。数据模型除了确定对象之间的分类、关系,还要明确对象的属性,针对不同的知识图谱,需要收集的数据的内容也不相同,内容范围由对象的属性确定。数据模型的分类,关系反映了数据之间的关系特征,数据模型的属性反映了数据的内在特征。另一个就是具体数据层,具体数据是一条条的知识,它是依据数据模型组织起来的。我们可以把数据模型看作是骨架,把具体数据看作是肌肉,两部分共同组成了一个健壮的整体,就是我们的知识图谱。不同类型的知识图谱,组织数据的方式也有所不同,涉及到具体数据,具体数据的内容也有差别。比如对于一个人物来说,如果是历史知识图谱,可能人物数据的内容主要侧重于人物的生平、主要事迹、人物关系等等,如果是文学知识图谱,人物数据的内容则会主要侧重人物的主要作品、师承关系、作品流派等等。 将知识图谱的数据分成了两个层次,在构建知识图谱的时候,是先确定数据模型再收集具体数据,还是先收集具体数据再确定数据模型,这就形成了两种构建知识图谱的方式。
6.2、自顶向下的构建方式
自顶向下的构建方式,是指先确定知识图谱的数据模型,再根据模型去填充具体数据,最终形成知识图谱。数据模型的设计,是知识图谱的顶层设计,根据知识图谱的特点确定数据模型,就相当于确定了知识图谱收集数据的范围,以及数据的组织方式。这种构建方式,一般适用于行业知识图谱的构建,对于一个行业来说,数据内容,数据组织方式相对来说比较容易确定。比如对于法律领域的知识图谱,可能会以法律分类,法律条文,法律案例等等的方式组织。再比如建立一个三国时期人物的知识图谱,可能会以某个历史时期,魏蜀吴三个国家将人物进行分类,统计人物的师承,上下属,朋友,敌对等等关系,依据这些关系设计数据模型,然后再收集具体人物数据,形成人物的知识图谱。总起来说,自顶向下的构建方式,适用于那些知识内容比较明确,关系比较清晰的领域构建知识图谱。
6.3、自底向上的构建方式
自下向上的构建方式,是指先按照三元组的方式收集具体数据,然后根据数据内容来提炼数据模型。采用这种方式构建知识图谱,是因为在开始构建知识图谱的时候,还不清楚收集数据的范围,也不清楚数据怎么使用,就是先把所有的数据收集起来,形成一个庞大的数据集,然后再根据数据内容,总结数据的特点,将数据进行整理、分析、归纳、总结,形成一个框架,也就是数据模型。一般公共领域的知识图谱采用这种方式,因为公共领域的知识图谱,涉及到海量数据,并且包括方方面面的知识,做出来的效果是大而全,这在构建初期,很难想清楚数据的整体架构,只能是根据数据的内容总结提炼特征,形成数据框架模型。比如google,百度的知识图谱,属于典型的公共领域知识图谱,现实中,使用他们的搜索工具进行内容搜索时,用户可能输入的内容千差万别,各个领域的问题都可能问到,也就使得他们的后台知识图谱内容也要覆盖所有知识,在构建他们这种公共领域的知识图谱过程中,随着数据的不断积累,才会对数据知识进行分类,慢慢呈现出知识架构。
当然,两种构建方式也不是一成不变的,在构建初期两种方式区别很明显,在知识图谱构建后期,两种方式可能会结合使用。对于自顶向下的构建方式,随着数据量的不断积累,可能会发现原来的数据模型并不完善,有很多数据可能没有包含在数据模型的体系中,这时候就需要修订数据模型,根据数据的特点,完善数据模型。同样,在自底向上的构建方式中,慢慢形成的数据模型,对于后期的数据收集,也有一定的指导作用,按照形成的数据模型,可以快速准确地收集相关数据。总之,数据和数据模型之间,是一个相辅相成的关系,二者在构建知识图谱的过程中缺一不可。
7、知识图谱构建过程
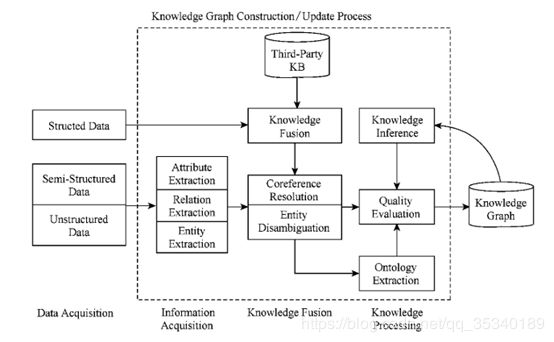
采用自底向上的方式构建知识图谱的过程是一个迭代更新的过程,每一轮更新包括3个步骤:1)信息抽取,即从各种类型的数据源中提取出实体(概念)、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;2)知识融合,在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;3)知识加工,对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。新增数据之后,可以进行知识推理、拓展现有知识、得到新知识。
7.1、信息抽取
信息抽取(information extraction)是知识图谱构建的第一步,其中的关键问题是如何从异构数据源中自动抽取信息得到候选知识单元。信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
7.1.1、实体抽取
实体抽取,也称为命名实体识别(named entity recognition, NER),是指从文本数据集中自动识别出命名实体。实体抽取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息抽取中最为基础和关键的部分。
早期对实体抽取方法的研究主要面向单一领域(如特定行业或特定业务),关注如何识别出文本中的人名、地名等专有名词和有意义的时间等实体信息。1991年,Rau采用启发式算法与人工编写规则相结合的方法,首次实现了从文本中自动抽取公司名称的实体抽取原型系统。然而,基于规则的方法具有明显的局限性,不仅需要耗费大量人力,而且可扩展性较差,难以适应数据的变化.随后,人们开始尝试采用统计机器学习方法辅助解决命名实体抽取问题,例如,Liu等人利用K-最近邻(K-Nearest Neighbors)算法和条件随机场模型,实现了对Twitter文本数据中包含实体的识别.然而迄今为止,单纯基于有监督学习的实体抽取方法,在准确率和召回率上的表现都不够理想,且算法的性能依赖于训练样本的规模,对此类方法的发展形成了制约。最近有学者采用有监督学习与规则(先验知识)相结合的方法,取得了一些积极的研究成果,例如Lin等人采用字典辅助下的最大熵算法,在基于Medline论文摘要的GENIA数据集上取得了实体抽取准确率和召回率均超过70% 的实验结果。
随着命名实体识别技术不断取得进展,学术界开始关注开放域(open domain)的信息抽取问题,即不再限定于特定的知识领域,而是面向开放的互联网,研究和解决全网信息抽取问题。为此,需要首先建立一个科学完整的命名实体分类体系,一方面用于指导算法研究;另一方面便于对抽取得到的实体数据进行管理。早在2002年,Sekine等人就提出了一个层次结构的命名实体分类体系,将网络中所有的命名实体划分为150个分类。该项成果引起了学术界对建立命名实体分类体系的重视,并对后续的命名实体识别研究产生了深远的影响。2012年,Ling等人借鉴Freebase的实体分类方法,归纳出112种实体类别,并基于条件随机场模型进行实体边界识别,最后采用自适应感知机算法实现了对实体的自动分类,其实验结果显著优于Stanford NER等当前主流的命名实体识别系统。
然而,互联网中的内容是动态变化的,Web 2.0技术更进一步推动了互联网的概念创新,采用人工预定义实体分类体系的方式已经很难适应时代的需求。面向开放域的实体抽取和分类技术能够较好地解决这一问题,该方法的基本思想是对于任意给定的实体,采用统计机器学习的方法,从目标数据集(通常是网页等文本数据)中抽取出与之具有相似上下文特征的实体,从而实现实体的分类和聚类。
在面向开放域的实体识别和分类研究中,不需要(也不可能)为每个领域或每个实体类别建立单独的语料库作为训练集。因此,该领域面临的主要挑战是如何从给定的少量实体实例中自动发现具有区分力的模式。针对该问题,Whitelaw等人提出了一种迭代扩展实体语料库的解决方案,基本思路是根据已知的实体实例进行特征建模,利用该模型对处理海量数据集得到新的命名实体列表,然后针对新实体建模,迭代地生成实体标注语料库。
另一种思路是通过搜索引擎的服务器日志获取新出现的命名实体.例如Jain等人提出了一种面向开放域的无监督学习算法,即事先并不给出实体分类,而是基于实体的语义特征从搜索日志中识别出命名实体,然后采用聚类算法对识别出的实体对象进行聚类,该方法已经在搜索引擎技术中得到应用,用于根据用户输入的关键字自动补全信息。
7.1.2、关系抽取
文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体(概念)联系起来,才能够形成网状的知识结构。研究关系抽取技术的目的,就是解决如何从文本语料中抽取实体间的关系这一基本问题。
早期的关系抽取研究方法主要是通过人工构造语法和语义规则,据此采用模式匹配的方法来识别实体间的关系。这种方法有两点明显的不足:1)要求制定规则的人具有良好的语言学造诣,并且对特定领域有深入的理解和认知;2)规则制定工作量大,难以适应丰富的语言表达风格,且难以拓展到其他领域。为此学术界开始尝试采用统计机器学习方法,通过对实体间关系的模式进行建模,替代预定义的语法和语义规则。例如Kambhatla等人利用自然语言中的词法、句法以及语义特征进行实体关系建模,通过最大熵方法成功地实现了不借助规则硬编码的实体关系抽取。
随后,出现了大量基于特征向量或核函数的有监督学习方法,关系抽取的准确性也不断提高。例如,刘克彬等人借助知网(HowNet)提供的本体知识库构造语义核函数,在开放数据集上对ACE定义的6类实体关系进行抽取,准确率达到了88%。然而,有监督学习方法也存在明显不足,为了确保算法的有效性,需要人工标注大量的语料作为训练集。因此,近年来的研究重点逐渐转向半监督和无监督的学习方式。例如,Carlson等人提出了一种基于Bootstrap算法的半监督学习方法,能够自动进行实体关系建模。陈立玮等人针对弱监督学习中标注数据不完全可靠的问题,基于Bootstrapping算法设计思想,提出了一种协同训练方法,通过向传统模型中引入N-Gram特征进行协同训练,实现了对弱监督关系抽取模型的强化,在中文和英文数据集上关系抽取性能均得到了提升。Zhang等人采用基于实例的无监督学习方法,在公开语料库上获得了较好的实验结果,能够对实体间的雇佣关系、位置关系以及生产关系等多元关系进行精准识别。
以上研究成果的共同特点是需要预先定义实体关系类型,如雇佣关系、整体部分关系以及位置关系等。然而在实际应用中,要想定义出一个完美的实体关系分类系统是十分困难的。为了解决这一制约关系抽取技术走向实际应用的关键问题,2007年,华盛顿大学图灵中心的Banko等人提出了面向开放域的信息抽取方法框架(open information extraction,OIE),并发布了基于自监督(self-supervised)学习方式的开放信息抽取原型系统(TextRunner)。该系统采用少量人工标记数据作为训练集,据此得到一个实体关系分类模型,再依据该模型对开放数据进行分类,依据分类结果训练朴素贝叶斯模型来识别“实体-关系-实体”三元组,经过大规模真实数据测试,取得了显著优于同时期其他方法的结果。
面向开放域的关系抽取技术直接利用语料中的关系词汇对实体关系进行建模,因此不需要预先指定关系的分类,这是一个很大的进步,例如,Wu等人在OIE的基础上,发布了面向开放域信息抽取的WOE系统,该系统能够利用维基百科网页信息框(infobox)提供的属性信息,自动构造实体关系训练集,性能优于早期的TextRunner系统,这项工作也为批量构造高质量的训练语料提供了新的思路。Fader等人通过对TextRunner系统和WOE系统的实体关系抽取结果进行分析,发现其中错误的部分主要是一些无意义或不合逻辑的实体关系三元组,据此引入语法限制条件和字典约束,采用先识别关系指示词,然后再对实体进行识别的策略,有效提高了关系识别准确率。Mausam等人针对上述系统均无法识别非动词性关系的局限,通过引入上下文分析技术,提出了一个支持非动词性关系抽取的OILLIE系统,有效提高了自动关系抽取的准确率和召回率。
由于当前的面向开放域的关系抽取方法在准确率和召回率等综合性能指标方面与面向封闭领域的传统方法相比仍有一定的差距,因此有部分学者开始尝试将两者的优势结合起来。例如Banko等人提出了一种基于条件随机场的关系抽取模型(H-CRF),当目标数据集中拥有的关系数量不大,而且有预先定义好的实体关系分类模型可用的情况下,采用传统的机器学习算法进行关系抽取,而对于没有预先定义好的实体关系模型或者关系数量过多的情况,则采用开放域关系抽取方法。微软公司人立方项目所采用的StatSnowball模型也是基于这种策略实现其关系抽取功能。
当前流行的OIE系统在关系抽取方面存在两个主要问题。1)当前研究的重点是如何提高二元实体间关系(三元组模式)的抽取准确率和召回率,很少考虑到在现实生活中普遍存在的高阶多元实体关系;2)所采用的研究方法大多只关注发掘词汇或词组之间的关系模式,而无法实现对隐含语义关系的抽取。对此,学术界有着清醒的认识,例如Alan等人采用N元关系模型对OIE系统进行改进,提出了KRAKEN模型,能够有效提高IOE系统对多元实体关系的识别能力。在隐含关系识别方面,McCallum提出采用后期关系推理的方法,提高OIE系统对隐含实体关系的发现能力。这些工作都是该领域值得重视的研究动向,然而在OIE关系抽取研究领域,要实现算法性能由量变到质变的飞跃,还需要一段时间的积累。
7.1.3、属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
由于可以将实体的属性视为实体与属性值之间的一种名词性关系,因此也可以将属性抽取问题视为关系抽取问题。例如郭剑毅等人将人物属性抽取问题转化为实体关系抽取问题,采用支持向量机算法实现了人物属性抽取与关系预测模型。
百科类网站提供的半结构化数据是当前实体属性抽取研究的主要数据来源。例如Suchanek等人设计了基于规则和启发式算法的属性抽取算法,能够从Wikipedia和WordNet网页信息框中自动提取属性名和属性值信息,据此得到了扩展性良好的本体知识库(YAGO),其抽取准确率高达95%。受YAGO和Freebase项目的启发,DBpedia项目以维基百科作为研究对象,从维基百科网页信息框中抽取了超过458万个实体和超过30亿条实体关系信息。作为Linked Data项目的重要组成部分,DBpedia构建了一个维基百科之上的知识网络,反过来促进了维基百科的应用创新,如关系查询、多维度搜索等,DBpedia也因此成为了目前世界上最庞大的多领域本体知识库之一。
尽管可以从百科类网站获取大量实体属性数据,然而这只是人类知识的冰山一角,还有大量的实体属性数据隐藏在非结构化的公开数据中。如何从海量非结构化数据中抽取实体属性是值得关注的理论研究问题。一种解决方案是基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取;另一种方案是采用数据挖掘的方法直接从文本中挖掘实体属性与属性值之间的关系模式,据此实现对属性名和属性值在文本中的定位。这种方法的基本假设是属性名和属性值之间有位置上的关联关系,事实上在真实语言环境中,许多实体属性值附近都存在一些用于限制和界定该属性值含义的关键词(属性名),在自然语言处理技术中将这类属性称为有名属性,因此可以利用这些关键字来定位有名属性的属性值。
7.2、知识融合
通过信息抽取,实现了从非结构化和半结构化数据中获取实体、关系以及实体属性信息的目标,然而,这些结果中可能包含大量的冗余和错误信息,数据之间的关系也是扁平化的,缺乏层次性和逻辑性,因此有必要对其进行清理和整合。知识融合包括两部分内容:实体链接和知识合并。通过知识融合,可以消除概念的歧义,剔除冗余和错误概念,从而确保知识的质量。
7.2.1、实体链接
实体链接(entity linking)是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
实体链接的基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。早期的实体链接研究仅关注如何将从文本中抽取到的实体链接到知识库中,忽视了位于同一文档的实体间存在的语义联系,近年来学术界开始关注利用实体的共现关系,同时将多个实体链接到知识库中,称为集成实体链接(collective entity linking)。例如Han等人提出的基于图的集成实体链接方法,能够有效提高实体链接的准确性。
实体链接的一般流程是:1)从文本中通过实体抽取得到实体指称项;2)进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义;3)在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
实体消歧
实体消歧(entity disambiguation)是专门用于解决同名实体产生歧义问题的技术。在实际语言环境中,经常会遇到某个实体指称项对应于多个命名实体对象的问题,例如“李娜”这个名词(指称项)可以对应于作为歌手的李娜这个实体,也可以对应于作为网球运动员的李娜这个实体,通过实体消歧,就可以根据当前的语境,准确建立实体链接。实体消歧主要采用聚类法。
聚类法是指以实体对象为聚类中心,将所有指向同一目标实体对象的指称项聚集到以该对象为中心的类别下。聚类法消歧的关键问题是如何定义实体对象与指称项之间的相似度,常用方法有四种。
① 空间向量模型(词袋模型)。典型的方法是取当前语料中实体指称项周边的词构成特征向量,然后利用向量的余弦相似度进行比较,将该指称项聚类到与之最相近的实体指称项集合中。例如Bagga等人采用该方法,在MUC6(Message Understanding Conference)数据集上取得了很高的消歧精度(F值高达84.6%)。然而该方法的缺点在于没有考虑上下文语义信息,这种信息损失会导致在某些情况下算法性能恶化,如短文本分析。
② 语义模型。该模型与空间向量模型类似,区别在于特征向量的构造方法不同,语义模型的特征向量不仅包含词袋向量,而且包含一部分语义特征。例如Pedersen等人采用奇异值分解技术对文本向量空间进行分解,得到给定维度的浅层语义特征,以此与词袋模型相结合,能够得到更精确的相似度计算结果。
③ 社会网络模型。该模型的基本假设是物以类聚、人以群分,在社会化语境中,实体指称项的意义在很大程度上是由与其相关联的实体所决定的。建模时,首先利用实体间的关系将与之相关的指称项链接起来构成网络,然后利用社会网络分析技术计算该网络中节点之间的拓扑距离(网络中的节点即实体的指称项),以此来判定指称项之间的相似度。例如Malin等人利用随机漫步模型对演员合作网络数据进行实体消歧,得到了比基于文本相似度模型更好的消歧效果。
④ 百科知识模型。百科类网站通常会为每个实体(指称项)分配一个单独页面,其中包括指向其他实体页面的超链接,百科知识模型正是利用这种链接关系来计算实体指称项之间的相似度。例如Han等人利用维基百科条目之间的关联关系计算实体指称项之间的相似度,实验结果表明这种方式能够有效消除同名实体间的歧义。Bunescu等人以维基百科作为知识库,基于实体所在页面的上下文信息和指称项所在语料的上下文信息,利用词袋模型构造特征向量作为实体链接时进行相似度比较的依据,实现了实体消歧。在此基础上,Sen进一步采用主题模型作为相似度计算依据,在维基百科人物数据集上获得了高达86%的消歧准确率。Shen等人提出的Linden模型则同时考虑到了文本相似性和主题一致性,基于维基百科和Wordnet知识库,取得了当前最好的实体消歧实验结果。然而,由于百科类知识库中的实体数非常有限,此类方法的推广性较差。
为了充分利用海量公开数据中包含的实体区分性证据,Li等人基于生成模型提出了一种增量证据挖掘算法,在Twitter数据集上实现了实体消歧准确率的大幅提升。该方法降低了消歧算法对于知识库的依赖,提供了一种很有希望的算法新思路。
实体消歧技术能够帮助搜索引擎更好地理解用户的搜索意图,从而给出更好的上下文推荐结果,提高搜索服务质量。其中还有一个很重要的问题是如何对存在歧义的实体进行重要性评估,以确定推荐内容的优先级。当前的主要研究思路是为实体赋予权重,用于表示该实体出现的频率或先验概率。例如Ratinov等人通过统计维基百科中的实体出现的频率以此作为实体推荐时排序的依据。Ochs等人则借助搜索引擎的关键词日志和DBpedia知识库,构建了一个知名人物本体库,据此实现了一个本体搜索引擎原型系统,为解决人物实体的重要性评估提供了一种新的思路。
共指消解
共指消解(entity resolution)技术主要用于解决多个指称项对应于同一实体对象的问题。例如在一篇新闻稿中,“Barack Obama”,“President Obama”,“the president”等指称项可能指向的是同一实体对象,其中的许多代词如“he”,“him”等,也可能指向该实体对象。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象。由于该问题在信息检索和自然语言处理等领域具有特殊的重要性,吸引了大量的研究努力,因此学术界对该问题有多种不同的表述,典型的包括:对象对齐(object alignment)、实体匹配(entity matching)以及实体同义(entity synonyms)。
共指消解问题的早期研究成果主要来自自然语言处理领域,近年来统计机器学习领域的学者越来越多地参与到这项工作中。基于自然语言处理的共指消解是以句法分析为基础的,代表性方法是Hobbs算法和向心理论(centering theory)。Hobbs算法是最早的代词消解算法之一,主要思路是基于句法分析树进行搜索,因此适用于实体与代词出现在同一句子中的场景,有一定的局限性。早期的Hobbs算法完全基于句法分析(朴素Hobbs算法),后来则加入了语义分析并沿用至今。向心理论的基本思想是:将表达模式(utterance)视为语篇(discourse)的基本组成单元,通过识别表达模式中的实体,可以获得当前和后续语篇中的关注中心(实体),根据语义的局部连贯性和显著性,就可以在语篇中跟踪受关注的实体。向心理论的提出最初并不是为了解决代词消解问题,而是为了对语篇中关注中心的局部连贯性进行建模,因此它虽然一段时间内成为主要的代词消解手段,但却不是最佳的理论模型。近年来,学术界开始尝试在向心理论的基础上,利用词性标注和语法分析技术,提高实体消解方法的适用范围和准确性。例如Lappin等人基于句法分析和词法分析技术提出了消解算法,能够识别语篇中的第三人称代词和反身代词等回指性代词在语篇中回指的对象,其性能优于Hobbs算法和基于向心理论的实体消解方法。
随着统计机器学习方法被引入该领域,共指消解技术进入了快速发展阶段。McCarthy等人首次将C4.5决策树算法应用于解决共指消解问题,结果在MUC-5公开数据集的多数任务中均取得了优胜。Bean等人通过实验发现,语义背景知识对于构造共指消解算法非常有帮助,他们利用Utah大学发布的AutoSlog系统从原始语料中抽取实体上下文模式信息,应用Dempster-Shafer概率模型对实体模式进行建模,在两个公开数据集上(MUC-4的恐怖主义数据集和路透社自然灾害新闻数据集)分别取得了76%和87%的共指消解准确率。
除了将共指消解问题视为分类问题之外,还可以将其作为聚类问题来求解。聚类法的基本思想是以实体指称项为中心,通过实体聚类实现指称项与实体对象的匹配。其关键问题是如何定义实体间的相似性测度。Turney基于点互信息(pointwise mutual information,PMI)来求解实体所在文档的相似度,并用于求解TOEFL和ESL考试中的同义词测试问题,取得了74%的正确率。Cheng等人通过对搜索引擎的查询和点击记录进行研究,发现可以根据用户查询之后的点击行为对实体进行区分。据此,通过查询和点击记录建立实体指称项与相关网页URL之间的关联,进而计算出实体指称项之间的点击相似度(click similarity),结果表明该方法能够有效实现共指消解,从而提高搜索覆盖率。
基于统计机器学习的共指消解方法通常受限于两个问题:训练数据的(特征)稀疏性和难以在不同的概念上下文中建立实体关联。为解决该问题,Pantel等人基于Harris提出的分布相似性模型,提出了一个新的实体相似性测度模型,称为术语相似度(term similarity),借助该模型可以从全局语料中得到所有术语间的统计意义上的相似性,据此可以完成实体合并,达到共指消解的目的。Chakrabarti等人则将网页点击相似性和文档相似性这两种测度相结合,提出了一种新的查询上下文相似性测度(query context similarity),通过在Bing系统上进行测试,该测度能够有效识别同义词,并显著提高查全率。值得注意的是,上述两种方法均支持并行计算,二者均采用了MapReduce框架,其中,前者在200个4核处理器上,用时50h得到了5亿条术语的相似度矩阵,而后者则已经在Bing搜索引擎的商品和视频搜索中取得应用。
7.2.2、知识合并
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据获取知识输入。例如,关联开放数据项目(linked open data)会定期发布其经过积累和整理的语义知识数据,其中既包括前文介绍过的通用知识库DBpedia和YAGO,也包括面向特定领域的知识库产品,如MusicBrainz和DrugBank等。
1) 合并外部知识库
将外部知识库融合到本地知识库需要处理两个层面的问题。① 数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余;② 通过模式层的融合,将新得到的本体融入已有的本体库中。
为促进知识库融合的标准化,Mendes等人提出了开放数据集成框架(linked data integration framework,LDIF),用于对LOD知识库产品进行融合。其中包括四个步骤:① 获取知识;② 概念匹配,由于不同本体库中的概念表达使用的词汇可能不同,因此需要对概念表达方式进行统一化处理;③ 实体匹配,由于知识库中有些实体含义相同但是具有不同的标识符,因此需要对这些实体进行合并处理;④ 知识评估,知识融合的最后一步是对新增知识进行验证和评估,以确保知识图谱的内容一致性和准确性,通常采用的方法是在评估过程中为新加入的知识赋予可信度值,据此进行知识的过滤和融合。
2)合并关系数据库
在知识图谱构建过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。业界和学术界将这一数据转换过程形象地称为RDB2RDF,其实质就是将关系数据库的数据换成RDF的三元组数据。根据W3C的调查报告显示,当前已经出现了大量RDB2RDF的开源工具(如Triplify,D2RServer,OpenLink Virtuoso,SparqlMap等),然而由于缺少标准规范,使得这些工具的推广应用受到极大制约。为此,W3C于2012年推出了两种映射语言标准:Direct Mapping(A direct mapping of relational data to RDF)和R2RML(RDB to RDF mapping language)。其中,Direct Mapping采用直接映射的方式,将关系数据库表结构和数据直接输出为RDF图,在RDF图中所用到的用于表示类和谓词的术语与关系数据库中的表名和字段名保持一致。而R2RML则具有较高的灵活性和可定制性,允许为给定的数据库结构定制词汇表,可以将关系数据库通过R2RML映射为RDF数据集,其中所用的术语如类的名称,谓词均来自定义词汇表。
除了关系型数据库之外,还有许多以半结构化方式存储(如XML,CSV,JSON等格式)的历史数据也是高质量的知识来源,同样可以采用RDF数据模型将其合并到知识图谱当中。当前已经有许多这样的工具软件,例如XSPARQL支持从XML格式转化为RDF,Datalift支持从XML和CSV格式转化为RDF,经过RDF转化的知识元素,经实体链接之后,就可以加入到知识库中,实现知识合并。
7.3、知识加工
通过信息抽取,可以从原始语料中提取出实体、关系与属性等知识要素。再经过知识融合,可以消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。然而,事实本身并不等于知识,要想最终获得结构化、网络化的知识体系,还需要经历知识加工的过程。知识加工主要包括三方面内容:本体构建、知识推理和质量评估。
7.3.1、本体构建
本体(ontology)是对概念进行建模的规范,是描述客观世界的抽象模型,以形式化方式对概念及其之间的联系给出明确定义。本体的最大特点在于它是共享的,本体中反映的知识是一种明确定义的共识。虽然在不同时代和领域,学者们对本体曾经给出过不同的定义,但这些定义的内涵是一致的,即:本体是同一领域内的不同主体之间进行交流的语义基础。本体是树状结构,相邻层次的节点(概念)之间具有严格的“IsA”关系,这种单纯的关系有助于知识推理,但却不利于表达概念的多样性。在知识图谱中,本体位于模式层,用于描述概念层次体系是知识库中知识的概念模板。
本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以采用计算机辅助,以数据驱动的方式自动构建,然后采用算法评估和人工审核相结合的方式加以修正和确认。对于特定领域而言,可以采用领域专家和众包的方式人工构建本体。然而对于跨领域的全局本体库而言,采用人工方式不仅工作量巨大,而且很难找到符合要求的专家。因此,当前主流的全局本体库产品,都是从一些面向特定领域的现有本体库出发,采用自动构建技术逐步扩展得到的。例如微软发布的Probase本体库就是采用数据驱动的自动化构建方法,利用统计机器学习算法迭代地从网页文本数据中抽取出概念之间的“IsA”关系,然后合并形成概念层次。目前,Probase中包含了超过270万条概念,准确率高达92.8%,在规模和准确性方面居于领先地位。
数据驱动的自动化本体构建过程包含三个阶段:实体并列关系相似度计算、实体上下位关系抽取以及本体的生成。1)实体并列关系相似度是用于考察任意给定的两个实体在多大程度上属于同一概念分类的指标测度,相似度越高,表明这两个实体越有可能属于同一语义类别。所谓并列关系,是相对于纵向的概念隶属关系而言的。例如“中国”和“美国”作为国家名称的实体,具有较高的并列关系相似度;而“美国”和“手机”这两个实体,属于同一语义类别的可能性较低,因此具有较低的并列关系相似度。2)实体上下位关系抽取是用于确定概念之间的隶属(IsA)关系,这种关系也称为上下位关系,例如,词组(导弹,武器)构成上下位关系,其中的“导弹”为下位词,“武器”为上位词。3)本体生成阶段的主要任务是对各层次得到的概念进行聚类,并对其进行语义类的标定(为该类中的实体指定1个或多个公共上位词)。
当前主流的实体并列关系相似度计算方法有两种:模式匹配法和分布相似度法。其中,模式匹配法采用预先定义实体对模式的方式,通过模式匹配取得给定关键字组合在同一语料单位中共同出现的频率,据此计算实体对之间的相似度。分布相似度(distributional similarity)方法的前提假设是:在相似的上下文环境中频繁出现的实体之间具有语义上的相似性。在具体计算时,首先将每个实体表示成1个N维向量,其中,向量的每个维度表示1个预先定义的上下文环境,向量元素值表示该实体出现在各上下文环境中的概率,然后就可以通过求解向量间的相似度,得到实体间的并列关系相似度。
实体上下位关系抽取是该领域的研究重点,主要的研究方法是基于语法模式(如Hearst模式)抽取IsA实体对。当前主流的信息抽取系统,如KnowItAll,TextRunner,NELL等,都可以在语法层面抽取实体上下位关系,而Probase则是采用基于语义的迭代抽取技术,以逐步求精的方式抽取实体上下位关系。基于语义的迭代抽取技术,一般是利用概率模型判定IsA关系和区分上下位词,通常会借助百科类网站提供的概念分类知识来帮助训练模型,以提高算法精度。例如Probase在处理“domestic animals other than dogs such as cats”这样的句子时,可以通过抽取IsA实体对中的上下位词得到两个备选事实:(cat,IsA,dog)和(cat,IsA,domestic animal)。如果Probase中已经有关于这些实体的概念,就可以得到正确的结果。
除了数据驱动的方法,还可以用跨语言知识链接的方法来构建本体库。例如Wang等人利用跨语言知识链接方法得到的知识对,在分别生成中英文本体模型的过程中,使二者相互确认,同时提高了中文关系和英文关系预测的准确度。
当前对本体生成方法的研究工作主要集中于实体聚类方法,主要的挑战在于经过信息抽取得到的实体描述非常简短,缺乏必要的上下文信息,导致多数统计模型不可用。例如Wang等人利用基于主题进行层次聚类的方法得到本体结构,为了解决主题模型不适用于短文本的问题,提出了一个基于单词共现网络(term co-occurrence network)的主题聚类和上位词抽取模型(CATHY),实现了基于短文本的主题聚类。Liu等人则采用贝叶斯模型对实体关键词进行分层聚类,经过改进的算法具有近似线性的复杂度(O(nlogn)),能够在1h内从100万关键词中抽取出特定领域的本体。
7.3.2、知识推理
知识推理是指从知识库中已有的实体关系数据出发,经过计算机推理,建立实体间的新关联,从而拓展和丰富知识网络。知识推理是知识图谱构建的重要手段和关键环节,通过知识推理,能够从现有知识中发现新的知识。例如已知(乾隆,父亲,雍正)和(雍正,父亲,康熙),可以得到(乾隆,祖父,康熙)或(康熙,孙子,乾隆)。知识推理的对象并不局限于实体间的关系,也可以是实体的属性值、本体的概念层次关系等。例如已知某实体的生日属性,可以通过推理得到该实体的年龄属性。根据本体库中的概念继承关系,也可以进行概念推理,例如已知(老虎,科,猫科)和(猫科,目,食肉目),可以推出(老虎,目,食肉目)。
知识的推理方法可以分为两大类:基于逻辑的推理和基于图的推理。基于逻辑的推理主要包括一阶谓词逻辑、描述逻辑以及基于规则的推理。一阶谓词逻辑建立在命题的基础上,在一阶谓词逻辑中,命题被分解为个体(individuals)和谓词(predication)两部分。个体是指可独立存在的客体,可以是一个具体的事物,例如奥巴马,也可以是一个抽象的概念,例如学生。谓词是用来刻画个体的性质及事物关系的词,例如三元组(A,friend,B)中friend就是表达个体A和B关系的谓词。举例来说,对于人际关系可以采用一阶谓词逻辑进行推理,方法是将关系视为谓词,将人物视为变元,采用逻辑运算符号表达人际关系,然后设定关系推理的逻辑和约束条件,就可以实现简单关系的逻辑推理。对于复杂的实体关系,可以采用描述逻辑进行推理。描述逻辑(description logic)是一种基于对象的知识表示的形式化工具,是一阶谓词逻辑的子集,它是本体语言推理的重要设计基础。基于描述逻辑的知识库一般包含TBox(terminology box)与ABox(assertion box),其中,TBox是用于描述概念之间和关系之间的关系的公理集合,ABox是描述具体事实的公理集合。借助这两个工具,可以将基于描述逻辑的推理最终归结为ABox的一致性检验问题,从而简化并最终实现关系推理。
当基于本体的概念层次进行推理时,对象主要是以Web本体语言(OWL)描述的概念,OWL提供丰富的语句,具有很强的知识描述能力。然而在描述属性合成和属性值转移方面,网络本体语言的表达能力就显得不足,为了实现推理,可以利用专门的规则语言(如semantic Web rule language,SWRL)对本体模型添加自定义规则进行功能拓展。例如Lu等人借助SWRL规则向本体库添加实体隐含关系推理规则,据此实现了网络服务的匹配机制。
基于图的推理方法主要基于神经网络模型或Path Ranking算法。例如Socher等人将知识库中的实体表达为词向量的形式,进而采用神经张量网络模型(neural tensor networks)进行关系推理,在WordNet和FreeBase等开放本体库上对未知关系进行推理的准确率分别达到86.2%和90.0%。
Path Ranking算法的基本思想是将知识图谱视为图(以实体为节点,以关系或属性为边),从源节点开始,在图上执行随机游走,如果能够通过一个路径到达目标节点,则推测源和目的节点间可能存在关系。例如假设两个节点(X,Y)共有1个孩子Z,即存在路径 X□(→┴Parentof ) Z□(←┴Parentof ) Y,据此推测X和Y之间可能存在MarriedTo关系。
开放域信息抽取技术极大地拓展了知识图谱的知识来源,知识库内容的极大丰富为知识推理技术的发展提供了新的机遇和挑战,现有的知识推理技术已经明显滞后于需求。由于推理得到的知识准确性低、冗余度高,因此在将其加入到知识库之前,通常需要进行可证明性检查、矛盾性检查、冗余性检查以及独立性检查,以确保推理的知识加入知识库后不会产生矛盾和冗余。在实际应用中,知识库的构建者为保证知识库应用的时效性,通常仅保留部分与业务密切相关的知识,而放弃其他推理结果。
此外,跨知识库的知识推理也是大趋势,同时也带来新的挑战,已经有部分学者开始关注这一问题。例如卢道设等人通过对描述逻辑的表现形式进行扩展,提出了一种基于组合描述逻辑的Tableau算法,基于概念的相似性对不同领域的概念进行关联。实验结果表明,基于组合描述逻辑的推理方法可以利用不同知识库中的已有知识进行推理,该成果为跨知识库的知识推理方法研究提供了新的思路。
7.3.3、质量评估
质量评估也是知识库构建技术的重要组成部分。1)受现有技术水平的限制,采用开放域信息抽取技术得到的知识元素有可能存在错误(如实体识别错误、关系抽取错误等),经过知识推理得到的知识的质量同样也是没有保障的,因此在将其加入知识库之前,需要有一个质量评估的过程;2)随着开放关联数据项目的推进,各子项目所产生的知识库产品间的质量差异也在增大,数据间的冲突日益增多,如何对其质量进行评估,对于全局知识图谱的构建起着重要的作用。引入质量评估的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识,可以保障知识库的质量。
为解决知识库之间的冲突问题,Mendes等人在LDIF框架基础上提出了一种新的质量评估方法(Sieve方法),支持用户根据自身业务需求灵活定义质量评估函数,也可以对多种评估方法的结果进行综合考评以确定知识的最终质量评分。
在对REVERB系统的信息抽取质量进行评估时,Fader等人采用人工标注方式对1000个句子中的实体关系三元组进行了标注,并以此作为训练集,得到了一个逻辑斯蒂回归模型,用于对REVERB系统的信息抽取结果计算置信度。谷歌的Knowledge Vault项目从全网范围内抽取结构化的数据信息,并根据某一数据信息在整个抽取过程中抽取到的频率对该数据信息的可信度进行评分,然后利用从可信知识库Freebase中得到先验知识对先前的可信度信息进行修正,实验结果表明,这一方法可以有效降低对数据信息正误判断的不确定性,提高知识图谱中知识的质量。
对于用户贡献的结构化知识的评估,与通过信息抽取获得的知识评估方法稍有不同。谷歌提出了一种依据用户的贡献历史和领域,以及问题的难易程度进行自动评估用户贡献知识质量的方法。用户提交知识后,该方法可以立刻计算出知识的可信度。使用该方法对大规模的用户贡献知识的评估准确率达到了91%,召回率达到了80%。
7.4、知识更新
人类所拥有的信息和知识量都是时间的单调递增函数,因此知识图谱的内容也需要与时俱进,其构建过程是一个不断迭代更新的过程。
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。数据层的更新主要是新增或更新实体、关系和属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗余等问题)等多方面因素。当前流行的方法是选择百科类网站等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。知识的更新也可以采用众包的模式(如Freebase),而对于概念层的更新,则需要借助专业团队进行人工审核。
知识图谱的内容更新有两种方式:数据驱动下的全面更新和增量更新。所谓全面更新是指以更新后的全部数据为输入,从零开始构建知识图谱。这种方式比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;而增量更新,则是以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
8、总结
知识图谱是一个新概念,从2012年提出到现在不过8年时间,然而通过对知识图谱构建技术体系进行深入观察和分析,可以看出它事实上是建立在多个学科领域研究成果基础之上的一门实用技术,堪称是信息检索(information retrieval)、自然语言处理(natural language processing)、万维网(WWW)和人工智能(artificial intelligence)等领域交汇处的理论研究热点和应用技术集大成者。
虽然谷歌的Knowledge Vault和微软的Satori等项目已经部分揭示出知识图谱技术的魅力和前景但通过以上分析不难看出,在知识图谱构建的各关键环节都面临着一些巨大的困难和挑战。
1)在信息抽取环节,面向开放域的信息抽取方法研究还处于起步阶段,部分研究成果虽然在特定(语种、领域、主题等)数据集上取得了较好的结果,但普遍存在算法准确性和召回率低、限制条件多、扩展性不好的问题。因此,要想建成面向全球的知识图谱,第1个挑战来自开放域信息抽取,主要的问题包括实体抽取、关系抽取以及属性抽取。其中,多语种、开放领域的纯文本信息抽取问题是当前面临的重要挑战。
2)在知识融合环节,如何实现准确的实体链接是一个主要挑战。虽然关于实体消歧和共指消解技术的研究已经有很长的历史,然而迄今为止所取得的研究成果距离实际应用还有很大距离。主要的研究问题包括开放域条件下的实体消歧、共指消解、外部知识库融合和关系数据库知识融合等问题。当前受到学术界普遍关注的问题是如何在上下文信息受限(短文本、跨语境、跨领域等)条件下,准确地将从文本中抽取得到的实体正确链接到知识库中对应的实体。
3)知识加工是最具特色的知识图谱技术,同时也是该领域最大的挑战之所在。主要的研究问题包括:本体的自动构建、知识推理技术、知识质量评估手段以及推理技术的应用。目前,本体构建问题的研究焦点是聚类问题,对知识质量评估问题的研究则主要关注建立完善的质量评估技术标准和指标体系。知识推理的方法和应用研究是当前该领域最为困难,同时也是最为吸引人的问题,需要突破现有技术和思维方式的限制,知识推理技术的创新也将对知识图谱的应用产生深远影响。
4)在知识更新环节,增量更新技术是未来的发展方向,然而现有的知识更新技术严重依赖人工干预。可以预见随着知识图谱的不断积累,依靠人工制定更新规则和逐条检视的旧模式将会逐步降低比重,自动化程度将不断提高,如何确保自动化更新的有效性,是该领域面临的又一重大挑战。
5)最具基础研究价值的挑战是如何解决知识的表达、存储与查询问题,这个问题将伴随知识图谱技术发展的始终,对该问题的解决将反过来影响前面提出的挑战和关键问题。当前的知识图谱主要采用图数据库进行存储,在受益于图数据库带来的查询效率的同时,也失去了关系型数据库的优点,如SQL语言支持和集合查询效率等。在查询方面,如何处理自然语言查询,对其进行分析推理,翻译成知识图谱可理解的查询表达式以及等价表达式等也都是知识图谱应用需解决的关键问题。
互联网正从包含网页和网页之间超链接的文档万维网(Web of document)转变成包含大量描述各种实体和实体之间丰富关系的数据万维网(Web of data)。知识图谱作为下一代智能搜索的核心关键技术,具有重要的理论研究价值和现实的实际应用价值。本文从知识图谱构建的视角,对知识图谱的内涵,以及知识图谱构建关键技术的研究发展现状进行了全面调研和深入分析,并对知识图谱构建工作面临的重要挑战和关键问题进行了总结。
知识图谱的重要性不仅在于它是一个全局知识库,是支撑智能搜索和深度问答等智能应用的基础,而且在于它是一把钥匙,能够打开人类的知识宝库,为许多相关学科领域开启新的发展机会。从这个意义上来看,知识图谱不仅是一项技术,更是一项战略资产。
参考文献
- Cowie J, Lehner W (1996) Information extraction. Commun ACM 39(1):80–91
- Chinchor N, Marsh E.Muc-7information extraction task definition[C]//Proc of the 7th Message Understanding Conf.Philadelphia:Linguistic Data Consortium, 1998:359-367
- Rau L F.Extracting company names from text[C]//Proc of the 7th IEEE Conf on Artificial Intelligence Applications.Piscataway, NJ:IEEE, 1991:29-32
- Liu Xiaohua, Zhang Shaodian, Wei Furu, et al.Recognizing named entities in tweets[C]//Proc of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg, PA:ACL, 2011:359-367
- Lin Yifeng, Tsai Tzonghan, Chou Wenchi, et al.A maximum entropy approach to biomedical named entity recognition[C]//Proc of the 4th ACM SIGKDD Workshop on Data Mining in Bioinformatics.New York:ACM, 2004:56-61
- Sekine S, Sudo K, Nobata C.Extended named entity hierarchy[C]//Proc of the 3rd Language Resources Association, 2002:1818-1824
- Jain A, Pennacchiotti M.Open entity extraction from Web search query logs[C]//Proc of the 23rd Int Conf on Computational Linguistics.Stroudsburg, PA:ACL, 2010:510-518
- Anmol Nayak, Vaibhav Kesri, Rahul Kumar Dubey:Knowledge Graph based Automated Generation of Test Cases in Software Engineering. COMAD/CODS 2020: 289-295
- Rui Wang, Bicheng Li, Shengwei Hu, Wenqian Du, Min Zhang:Knowledge Graph Embedding via Graph Attenuated Attention Networks. IEEE Access 8: 5212-5224 (2020)
- Jia Zhu, Zetao Zheng, Min Yang, Gabriel Pui Cheong Fung, Yong Tang:A semi-supervised model for knowledge graph embedding. Data Min. Knowl. Discov. 34(1): 1-20 (2020)
- 刘峤,李杨,段宏,刘瑶,秦志光.知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600.
- 刘知远,孙茂松,林衍凯,谢若冰.知识表示学习研究进展[J].计算机研究与发展,2016,53(02):247-261.
- 阮彤,孙程琳,王昊奋,方之家,殷亦超.中医药知识图谱构建与应用[J].医学信息学杂志,2016,37(04):8-13.
- 徐增林,盛泳潘,贺丽荣,王雅芳.知识图谱技术综述[J].电子科技大学学报,2016,45(04):589-606.
- 魏瑞斌.国内知识图谱研究的可视化分析[J].图书情报工作,2011,55(08):126-130.
- Ming Li,Xiuzhi Lu,Lisheng Chen,Jun Wang. Knowledge map construction for question and answer archives[J]. Expert Systems With Applications,2020,141.
- SoYeop Yoo,OkRan Jeong. Automating the expansion of a knowledge graph[J]. Expert Systems With Applications,2020,141.
- Xiaojun Chen,Shengbin Jia,Yang Xiang. A review: Knowledge reasoning over knowledge graph[J]. Expert Systems With Applications,2020,141.
- Yu-Tien Cheng, Huan-Ming Chuang, Chan-Chao Wen. A Study on Applying Mind Mapping to Build a Knowledge Map of the Project Risk Management of Research and Development[P]. Innovative Computing, Information and Control (ICICIC), 2009 Fourth International Conference on,2009.
- Xiaowen Zhu, Yinglin Wang. A Relation Combination Model for Knowledge Maps[P]. Information Engineering and Computer Science, 2009. ICIECS 2009. International Conference on,2009.
- Xiaobing Pei, Chaoying Wang. A Study on the Construction of Knowledge Map in Matrix Organizations[P]. Management and Service Science, 2009. MASS '09. International Conference on,2009.
- Backhaus, W., Sattari, S., Hees, F., Henning, K… A Web-based Knowledge Map for integrating expert knowledge into higher education[P]. Information Technology Based Higher Education and Training, 2006. ITHET '06. 7th International Conference on,2006.
- Qi Xiong, Yingling Wang, Jianmei Guo, Guilin Wu. A Searchable Knowledge Map Based on Ontology[P]. Semantics, Knowledge and Grid, 2008. SKG '08. Fourth International Conference on,2008.
- Castles, R., Lohani, V.K., Kachroo, P… Knowledge Maps and their application to student and faculty assessment[P]. Frontiers in Education Conference, 2008. FIE 2008. 38th Annual,2008.