centos7部署ELK+kafka集群
架构图
 服务分布
服务分布
10.0.13.105 Elasticsearch Logstash kibana
10.0.13.238 Elasticsearch zookeeper kafka
10.0.13.239 Elasticsearch zookeeper kafka
10.0.13.240 Filebeat zookeeper kafka
所有机器关闭防火墙,关闭selinux,集群主机名统一改为ELK-server,安装jdk1.8,此次部署采用rpm包安装(上次已经安装过单节点ELK6.2版本,此次在之前的基础上做集群,注意版本要统一!!!)
我这里的版本和最新版本的elk配置上会有一些不同,建议去官网下载和我一样的版本,或者用新版本的若是同样配置出错,一定要找日志查看
官网地址:https://www.elastic.co/cn/downloads/
- filebeat部署(我部署的这台是用来监控nginx为例的)
rpm -ih filebeat-6.2.4-x86_64.rpm
vim /etc/filebeat/filebeat.yml


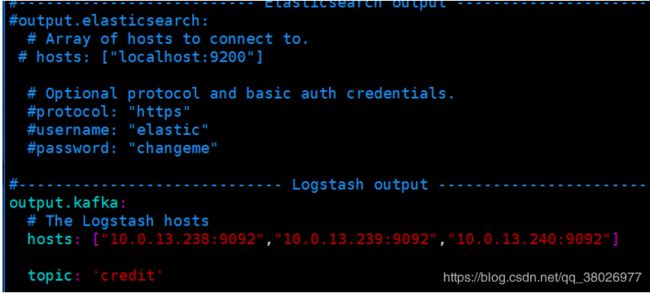 注意上面图中第一个output.elasticsearch要注释掉,因为我们的日志是通过下面的kafka传输
注意上面图中第一个output.elasticsearch要注释掉,因为我们的日志是通过下面的kafka传输
hosts中的三台是kafka主机,topic建议和我设置的一样,后面要用
- 重启
systemctl start filebeat
systemctl enable filebeat
- 配置kafka集群
自行到kafka官网下载
这里采用tar包安装,安装目录在/usr/local/kafka下
解压kafka包 tar xvf xxxxxxx.tar -C /usr/local
 可以看到,zookeeper默认一起装好了
可以看到,zookeeper默认一起装好了
配置zookeeper
①给zookeeper 创建data 目录和logs 目录
mkdir /usr/local/kafka/zookeeper/{data,logs} -p
②创建myid 文件
echo 1 > /usr/local/kafka/zookeeper/data/myid #集群其他服务器需要改动,其他两台分别设为2和3
③配置zookeeper配置文件
vim /usr/local/kafka/config/zookeeper.properties
 #server.myid=ip:followers_connect to the leader:leader_election # server 是固定的,myid 是需要手动分配,第一个端口是follower是链接到leader的端口,第二个是用来选举leader 用的port
#server.myid=ip:followers_connect to the leader:leader_election # server 是固定的,myid 是需要手动分配,第一个端口是follower是链接到leader的端口,第二个是用来选举leader 用的port
- 配置kafka
vim /usr/local/kafka/config/server.properties
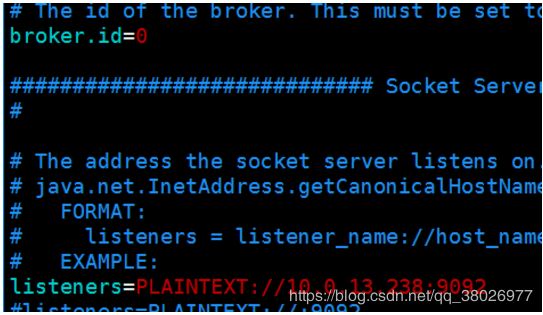 其他两台把broker.id设为1和2,listeners都改为自己的
其他两台把broker.id设为1和2,listeners都改为自己的


- 创建kafka 日志文件
mkdir -p /usr/local/kafka/logs/
- 8.配置集群其他两台节点
只需要把这台配置好的安装包直接拷贝分发到不同的机器上,然后修改zookeeper的myid,kafka的broker.id和listeners就可以了,接下来启动,注意要先启动zookeeper,再启动kafka
kafka的启动有点麻烦,所以我们自己写到systemd中设置自启动
vim /etc/systemd/system/zookeeper.service
里面写入
[Unit]
Description=Zookeeper service
After=network.target
[Service]
#Type=simple
#Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/java/jdk-11.0.1/bin"
#User=root
#Group=root
ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
vim /etc/systemd/system/kafka.service
写入
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
#Type=simple
#Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/java/jdk-11.0.1/bin"
#User=root
#Group=root
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
- 启动服务
systemctl start zookeeper kafka
systemctl enable zookeeper kafka
systemctl status zookeeper kafka
查看服务是否正常 lsof -i:2181
- logstash部署
安装
rpm -ih logstash-6.2.4.rpm
vim /etc/logstash/conf.d/logstash.conf
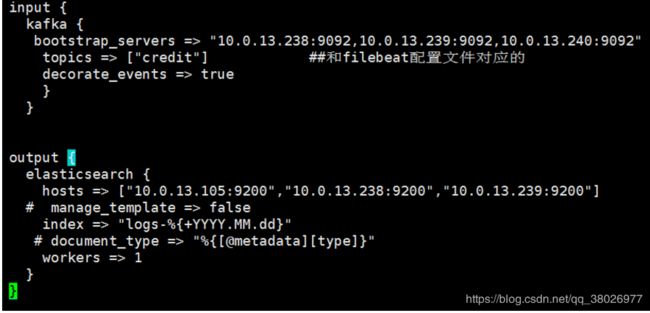
- 启动服务
systemctl start logstash
systemctl enable logstash
systemctl status logstash
检测配置文件是否正确(出现OK正确)
/usr/share/logstash/bin/logstash -t --path.settings /etc/logstash/ --verbose
- 安装部署Elasticsearch
rpm -ih elasticsearch-6.2.4.rpm
vim /etc/elasticsearch/elasticsearch.yml
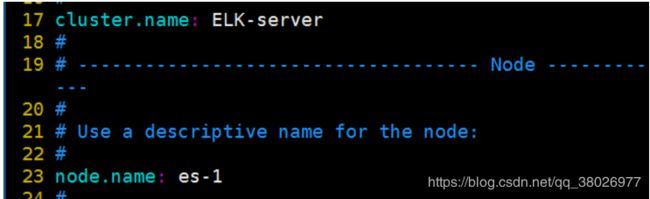 安装Elasticsearch的三台的cluster.name要一致,node.name分别为es-1,es-2,es-3
安装Elasticsearch的三台的cluster.name要一致,node.name分别为es-1,es-2,es-3
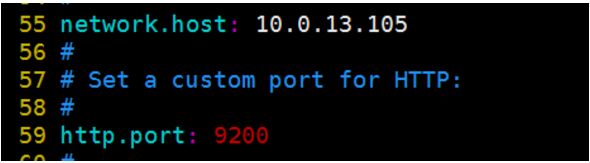 设为自己各自的ip
设为自己各自的ip
![]() 写入三台的ip
写入三台的ip
 创建目录
创建目录
配置中其他我没写的都注释掉
- 启动服务
systemctl start elasticsearch #开启服务
systemctl enable elasticsearch
9200是默认端口
9300是集群通信端口
es-2和es-3的安装和es-1步骤相同。不同之处为配置文件node.name:、network.host:可以直接拷贝文件过去用
检查Elasticsearch是否运行
curl -X GET "10.0.13.105:9200/"
curl -XGET 'http://10.0.13.105:9200/_cat/nodes' #任选一台机器
执行,出现三台ip即正确
带*号的是自动选举出来的master
- 安装kibana
rpm -ih xxxxxxxxx
vim /etc/kibana/kibana.yml

![]()
- 启动服务 网页访问该ip:5601即可
*kibana 的web页面操作请参考单节点部署那一节或自行百度,以后会深入写,要注意的是配置kibana日志日志源时注意名称要和logstash里配置的一样,注意看我配的是logs-开头,所以你写入时也要是logs-这种格式,否则没有日志出来

- 搭建Cerebro Elasticsearch监控
https://github.com/lmenezes/cerebro/releases
可以从该网址下载最新的cerebro,我的是最新的rpm包
rpm -ih cerebro-0.8.3-1.noarch (1).rpm
vim /etc/cerebro/application.conf
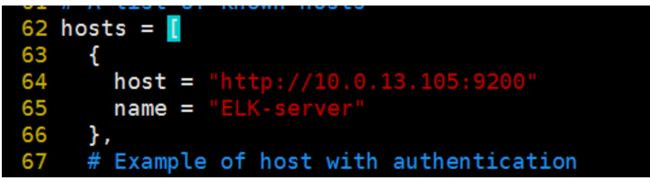 随便写入一台es就行,我写的是master那台
随便写入一台es就行,我写的是master那台
启动服务
systemctl start cerebro
systemctl status cerebro
默认是9000端口
访问10.0.13.105:9000可以访问
 出现三个节点即为部署成功
出现三个节点即为部署成功