Python数据结构:栈队列哈希合集(10+1),复现几遍,包你学会
欢迎关注微信公众号:简说Python
关注后回复:1024,可以领取精选编程学习电子书籍。
这两天和几个朋友组了个互相督促学习群,想着督促一下自己学习,也督促自己的原创输出,其实很多时候都是懒,真不是没有东西可以写了,这不,我在我的免费知识星球简说编程里开了个新的标签日常编程问题,后面我会把自己学习工作中遇到的一些问题和解决方法记录到里面,有些可以扩展的点,我会写到微信公众号里。
我定的目标是:

我简单写了个规则,大家说可以,然后,我们就开始吧,我习惯把该做的事情提前一天做(如果有时间的话)。

今天给大家分享的书籍《Python程序员面试算法宝典》第二章栈队列哈希的所有小节及引申部分。
如果你是第一次看,也许,你可以看看本系列下面的文章:
Python数据结构:链表合集(12+7),复现几遍,包你学会
Smaller Python数据结构:自己动手实现栈
Smaller Python数据结构:自己动手实现队列
Smarter Python数据结构:如何翻转栈
Smarter Python数据结构:根据入栈序列来判断可能的出栈序列
Smarter Python数据结构:利用O(1)的时间复杂度求栈中最小元素
Smarter Python数据结构:如何利用两个栈模拟队列操作
Smarter Python数据结构:用队列实现一个排序系统(关于人员入队列与出队列)
一、今日问题1:实现LUR(最近最少使用)缓存方案
"""
目标:写一个程序,实现LUR(最近最少使用)缓存方案
最近使用的页面排序越靠前
输入:size:3 (缓存大小) 1 2 5 1 6 7(页面使用顺序)
输出::7 6 1
Goal: write a program to implement the LUR (least recently used)
caching scheme
More recent page sorting
Input: size: 3 1 2 5 1 6 7 (page order)
Output:: 7 6 1
"""
解题方法:双向队列法
"""
Method One : 双向队列法
核心思想:双向队列存储缓存页面编号,头出尾进;哈希表存储页面编号和对应结点,
每次访问页面时,先看在不在缓存队列(通过哈希表查询,时间复杂度O(1)),如果在,
则再判断在不在队首,如果在队首则不移动,否则,移动到队首;如果不在缓存队列,
先看缓存队列是否已经满了,满了就先移除最后一个缓存页面(最近最少使用),然后
将当前访问页面加入到队首。
Method one: two way queue method
Core idea: two way queue stores cache page number, head out and tail
in; hash table stores page number and corresponding node. When visiting
a page, first look at the queue that is not in the cache (query through
hash table, time complexity O (1)); if it is, then judge whether it is
in the queue head; if it is in the queue head, then it will not move;
otherwise, it will move to the queue head; if it is not in the cache queue,
first look If the cache queue is full, first remove the last cache page
(least recently used), and then add the current access page to the queue head.
"""
思路图解
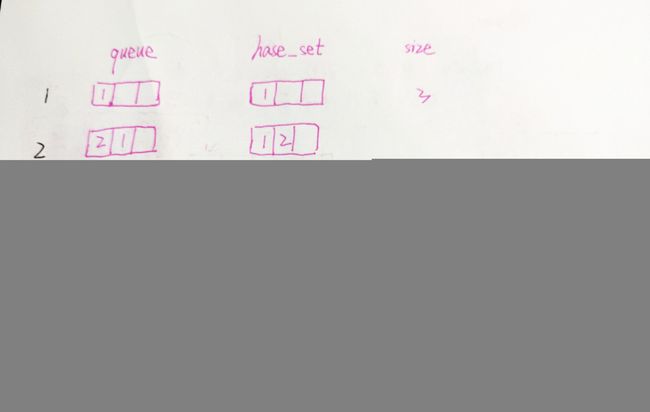
代码
from collections import deque
class LRU:
def __init__(self, size):
self.cache_size = size # 规定缓存大小
self.queue = deque() # 双向缓存队列,只记录最近使用页面
self.hash_set = set() # 记录页面和对于页面(结点)值
# 判断缓存是否已经满了
def is_full(self):
return self.cache_size == len(self.queue)
# 添加页
def en_queue(self, page_number):
if self.is_full(): # 如果缓存区满了
self.hash_set.remove(self.queue[-1]) # 从哈希表移除在缓存区的最后一个(最近最少使用的)
self.queue.pop() # 从缓存队列移除
self.queue.appendleft(page_number) # 添加当前访问页面到缓存队列队首
self.hash_set.add(page_number) # 添加当前页到哈希表
# 访问页
def access_page(self, page_number):
print("当前访问页面:", page_number)
if page_number not in self.hash_set: # 访问页面不在缓存
print("该访问页面不在缓存中,正在加入...")
self.en_queue(page_number) # 加入缓存队列
elif page_number != self.queue[0]: # 访问页面在缓存队列,但不在队首
print("该访问页面在缓存中,不在队首,正在移动...")
self.queue.remove(page_number) # 先移除
self.queue.appendleft(page_number) # 然后移至队首
print("对页面%d的访问结束。" % page_number)
# 打印当前缓存队列
def print_queue(self):
for i in self.queue: # 遍历循环
print(i, end=" ")
# 当然,也许还有别的方法,比如建一个辅助的链表
# 欢迎你说出你的想法
# 程序入口,测试函数功能
if __name__ == "__main__":
lru_test = LRU(3) # 初始化,设置缓存大小为3
access_list = [1, 2, 5, 1, 6, 7] # 访问列表
for i in access_list: # for 循环遍历访问
lru_test.access_page(i)
# 打印缓存队列
lru_test.print_queue()
运行结果

二、今日问题2:从给定的车票中找出旅程路线
"""
目标:写一个程序,从给定的车票中找出旅程路线
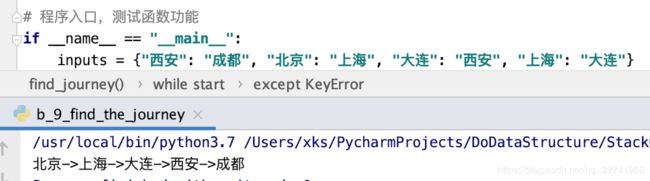
输入:("西安", "成都"), ("北京", "上海"), ("大连", "西安"), ("上海", "大连")
输出::北京->上海->大连->西安->成都
Goal: write a program to find the journey from a given ticket
Input: ("Xi'an", "Chengdu"), ("Beijing", "Shanghai"), ("Dalian", "Xi'an"), ("Shanghai", "Dalian")
Output: Beijing - > Shanghai - > Dalian - > Xi'an - > Chengdu
"""
解题方法:翻转查找法
"""
Method One : 翻转查找法
核心思想:默认不存在重复路线,即最开始的出发点不会成为目的地,所以我们只需要找到出发点即可,
可以先将元素数据存储到字典(目的地:出发地),然后遍历,判断出发点在不在目的地的哈希表里(字典),
如果在,说明该站既是出发点,又是目的地,如果不在,说明该站为起始地,然后从起始地开始遍历,找到旅程路径。
Method one: flip search
Core idea: by default, there is no duplicate route, that is, the starting point
will not be the destination, so we just need to find the starting point. We can
first store the element data in the dictionary (destination: starting point),
and then traverse it to determine whether the starting point is in the hash table
(Dictionary) of the destination. If it is, it means that the station is both the
starting point and the destination, such as If not, it means that the station is
the starting point, and then start to traverse from the starting point to find
the journey path.
"""
思路图解

代码
def find_journey(inputs):
# 第一步:翻转出发地与目的地,存入字典
reverse_dict = {}
for k,v in inputs.items():
if not k or not v:
print("旅程输入有误,请仔细检查")
return
reverse_dict[v] = k
# 第二步:遍历原字典,找到旅程起始点
for k in inputs.keys():
if k not in reverse_dict:
# 说明这个点为起始点
start = k # 记录起始点
break # 找到起始点后,跳出循环
# 第三步:从起始点开始遍历字典,写出完整旅程
print(start, end="") # 先打印起始点
# start = inputs[start]
while start: # 遍历
try:
print("->" + inputs[start], end="") # 打印途径站
start = inputs[start] # 后移遍历
except KeyError:
# 遍历到最后一站,
# 执行start = inputs[start]会报错,
# 获取错误,跳出完成遍历
break
# 当然,也许还有别的方法,比如建一个辅助的链表
# 欢迎你说出你的想法
# 程序入口,测试函数功能
if __name__ == "__main__":
inputs = {"西安": "成都", "北京": "上海", "大连": "西安", "上海": "大连"}
find_journey(inputs)
运行结果
三、今日问题3:从数组中找出满足a+b = c+d的两个数对
"""
目标:写一个程序,从数组中找出满足a+b = c+d的两个数对
输入:[1, 2, 3, 4, 5]
输出::(1,4)与(2,3) (1,5)与(2,4)
Goal: write a program to find two pairs of numbers satisfying a + B = C + D from the array
Input: [1, 2, 3, 4, 5]
Output:: (1,4) and (2,3) (1,5) and (2,4)
"""
解题方法:遍历查找
"""
Method One : 遍历查找
核心思想:双层循环遍历数组,找出所有的两数之和(重复),将数对和数对和存入字典(数对和:数对),
每次计算数对和时都先判断数对和在不在字典内,如果不在字典内继续遍历,否则,返回当前数对和字典里对应的
数对。
Method one: traversal search
Core idea: double layer loop traverses array, finds out the sum of all two numbers (repetition),
stores the sum of number pair and number pair in dictionary (number pair and: number pair),
judges whether the sum of number pair is in the dictionary first each time when calculating
the sum of number pair, if it is not in the dictionary to continue traversing, otherwise,
returns the current number pair and the corresponding number pair in the dictionary.
"""
代码
def find_nums_pair(num_list):
# 双层遍历列表
# 一边求可能的两个数之和
# 一遍把结果存入字典
sum_dict = {}
for i in range(len(num_list)): # 一层for遍历
for j in range(i+1, len(num_list)): # 二层for向后遍历,求和
sum_two = num_list[i] + num_list[j] # 计算两数和
if sum_two in sum_dict: # 如果该和与之前计算和相等,则直接返回两个数对
return [(num_list[i], num_list[j]),sum_dict[sum_two]]
sum_dict[sum_two] = (num_list[i], num_list[j]) # 记录到字典中,继续遍历
return None # 没找到,返回None
# 当然,也许还有别的方法,比如建一个辅助的链表
# 欢迎你说出你的想法
# 程序入口,测试函数功能
if __name__ == "__main__":
num_list = [11, 13, 2, 4]
result = find_nums_pair(num_list)
if result:
print("该数组中存在这样的数对,他们是{0}和{1}".format(result[0], result[1]))
else:
print("该数组中不存在这样的数对")
运行结果

四、唯一引申:给栈排序
本引申源:Smarter Python数据结构:如何翻转栈
"""
目标:写一个程序,给栈排序
输入:1,3,5,2,7
输出:1,2,3,5,7
Goal: write a program to sort stacks
Input: 1, 3, 5, 2, 7
Output: 1, 2, 3, 5, 7
"""
解题方法:遍历查找
"""
Method One : 遍历查找
核心思想:双层循环遍历数组,找出所有的两数之和(重复),将数对和数对和存入字典(数对和:数对),
每次计算数对和时都先判断数对和在不在字典内,如果不在字典内继续遍历,否则,返回当前数对和字典里对应的
数对。
Method one: traversal search
Core idea: double layer loop traverses array, finds out the sum of all two numbers (repetition),
stores the sum of number pair and number pair in dictionary (number pair and: number pair),
judges whether the sum of number pair is in the dictionary first each time when calculating
the sum of number pair, if it is not in the dictionary to continue traversing, otherwise,
returns the current number pair and the corresponding number pair in the dictionary.
"""
代码
def change_stack_top(s):
top1 = s.get_stack_top() # 取出栈顶
# print(top1)
s.stack_pop() # 出栈
if not s.stack_is_empty(): # 栈不为空时一直递归遍历
change_stack_top(s) # 递归
top2 = s.get_stack_top() # 取出当前栈顶
if top1 > top2:
s.stack_pop() # 出栈
s.stack_push(top1) # 入栈
s.stack_push(top2) # 入栈,大的数先入栈
return
s.stack_push(top1) # 入栈
def stack_sort(s):
if s.stack_is_empty(): # 栈为空,直接返回
return
# 第一步:相邻元素比较大小,排序
change_stack_top(s)
# 第二步:取出当前栈顶,开始递归处理子栈
top = s.get_stack_top()
s.stack_pop()
stack_sort(s)
# 第三步:回溯时,将之前取出的栈顶元素入栈
s.stack_push(top)
# 当然,也许还有别的方法,比如建一个辅助的链表
# 欢迎你说出你的想法
# 程序入口,测试函数功能
if __name__ == "__main__":
s = LinkStack() # 初始化一个栈对象
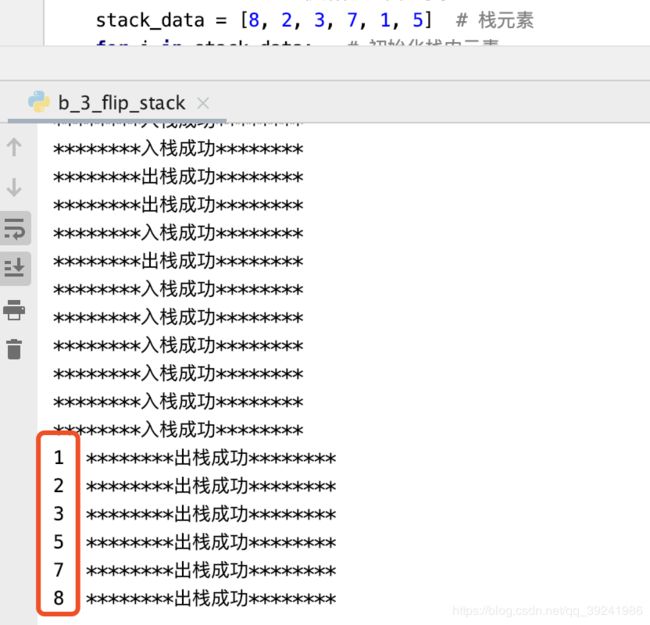
stack_data = [8, 2, 3, 7, 1, 5] # 栈元素
for i in stack_data: # 初始化栈内元素
s.stack_push(i) # 入栈
stack_sort(s) # 栈内元素排序
while not s.stack_is_empty(): # 遍历打印栈内元素
print(s.get_stack_top(), end=" ") # 打印当前栈顶元素
s.stack_pop() # 出栈
运行结果
到此第二章:栈队列哈希已经结束了,有时间,我会把数据结构中栈队列哈希操作和解题技巧归纳总结,发布到知识星球:简说编程。
本文代码思路部分来自书籍《Python程序员面试宝典》,书中部分代码有问题或未提供代码,文中已经修改过了,并添加上了丰厚的注释,方便大家学习,后面我会把所有内容开源放到Github上,包括代码,思路,算法图解(手绘或者电脑画),时间充裕的话,会录制视频。
希望大家多多支持。
大家好,我是老表
觉得本文不错的话,转发、留言、点赞,是对我最大的支持。
欢迎关注微信公众号:简说Python
关注后回复:1024,可以领取精选编程学习电子书籍。