12306:妈妈再也不用担心我抢不到票了(2)
一、写在前面
上一篇中,我们实现了 12306的模拟登录(破解验证码),这里是传输门,本篇推文,我将带大家进行进一步的操作车票预订第一步—实现车票查询功能。
项目源码地址
二、一顿骚操作
注: 以下所有操作可以不用登录(即不需要进行我们上一步的操作)
1.车票预订地址
https://kyfw.12306.cn/otn/leftTicket/init
- 页面显示

- 参数分析
四个参数:
必填数据:出发地、目的地、出发日期
选填数据:返回日期
2.页面详情分析
(1)谷歌浏览器下,F12,输入出发地、目的地、出发日期后,点击查询。
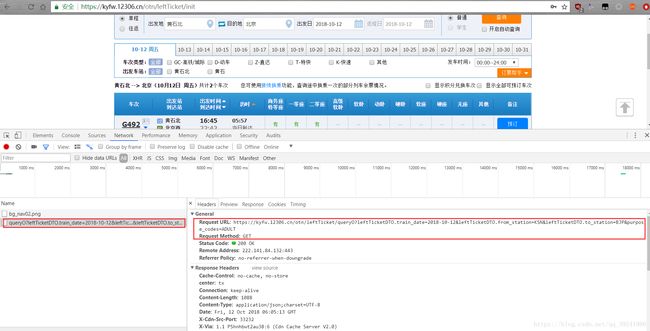
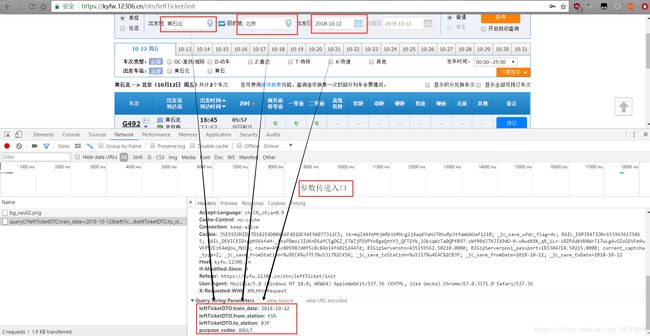
(2)通过上面图片分析我们可以发现,点击查询后,多加载了一个xhr页面,get请求,有四个参数,返回内容为json格式数据。
- 请求
Request URL: https://kyfw.12306.cn/otn/leftTicket/queryO?leftTicketDTO.train_date=2018-10-12&leftTicketDTO.from_station=KSN&leftTicketDTO.to_station=BJP&purpose_codes=ADULT
Request Method: GET
- 参数
# 出发日期
leftTicketDTO.train_date: 2018-10-12
# 出发站
leftTicketDTO.from_station: KSN
# 目的站
leftTicketDTO.to_station: BJP
# 车票类型:成人
purpose_codes: ADULT
通过参数我发现,出发站和目的站并不是我们直接输入的汉字,而是对应站点的英文缩写,接下来我们会讲怎么处理这个问题,大家也可以停在这里思考一下。
- 返回数据

- 页面实际数据

通过我们获取到的数据与原页面数据显示比较,我们发现,我们想要的页面车次信息在json文件的data下的result中,我们只需根据实际数据与获取数据对比即可判断、提取出相应数据。
3.动手动脑敲代码
(1)解决站点名称转换问题
想了很久,也看了光城学长之前写的方法,觉得还是太麻烦了,我想要是有全国所有站点的中文名和英文缩写就好了,百度一下,几经搜索,果然有这样的网站存在。
https://im0x.com/C/detail/1.55
那就简单了,把数据爬取下来,然后存储到csv文件即可,查询时直接访问本地文件,比发送请求要简单的多吧~
def csm():
url = 'https://im0x.com/C/detail/1.55'
date = requests.get(url)
html = date.text
# 正则提取站点中文名和英文缩写
city_code =re.findall('[a-z]\|(.*?)\|(.*?)\|.*?\|.*?\|\d',html,re.S)
list_info = []
for i in range(len(city_code)):
list_0 = [city_code[i][0],city_code[i][1]]
print(list_0)
list_info.append(list_0)
# 文件操作函数,和之前推文思想是一样的
# 点击阅读原文可查看所有源码
file_do(list_info)
运行结果:

一共2766个站点和英文缩写,等会来波骚操作。
(2)获取查询数据
def search_ticket(self):
train_date = input("请输入查询时间(2018-10-12):")
from_station = input("请输入始发站点(中文全称:黄石北):")
to_station = input("请输入终点站(中文全称:北京西):")
en_station = self.conversion(from_station,to_station)
search_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/queryO?leftTicketDTO.train_date={0}&leftTicketDTO.from_station={1}&leftTicketDTO.to_station={2}&purpose_codes=ADULT'.format(train_date,en_station[0],en_station[1])
# print(search_ticket_url)
headers = {
"Host": "kyfw.12306.cn",
"Referer": "https://kyfw.12306.cn/otn/leftTicket/init"
}
search_response = requests.get(search_ticket_url,headers = headers)
search_result = search_response.json()
print(search_result)
站点名称转换:
def conversion(self,from_station,to_station):
import csv
city_station = []
with open(r'H:\city_station.csv', 'r', encoding='utf_8_sig', newline='') as city_file:
# 读文件
reader = csv.reader(city_file)
i = 0
for row in reader:
if i != 0:
city_station.append([row[0], row[1]])
# print(row[1])
i = i + 1
# 转换为字典格式,方便查找
city_station_dict = {city_station[i][0]: city_station[i][1] for i in range(len(city_station))}
# print(city_station_dict)
if from_station in city_station_dict:
from_station_en = city_station_dict[from_station]
else:
print("出发站输入错误!")
if to_station in city_station_dict:
to_station_en = city_station_dict[to_station]
else:
print("目的站输入错误!")
return [from_station_en,to_station_en]
运行结果:

数据拿到了,就只剩下解析数据,用好看易懂的方式表示出来了。
(3)解析数据
接下来操作参考自光城学长的推文。
原文链接:https://mp.weixin.qq.com/s/7ECRtXmsx-ioV_t_lXmo-Q
- 数据名称分类
| 名称 | 变量名 |
|---|---|
| 车次 | checi |
| 始发站 | from_station |
| 终点站 | to_station |
| 出发时间 | from_time |
| 到达时间 | to_time |
| 历时 | total_time |
| 出发日期 | from_datetime |
| 高级软卧 | high_soft |
| 软卧 | common_soft |
| 无座 | no_seat |
| 动卧 | move_down |
| 商务座(特等座) | special_seat |
| 一等座 | first_seat |
| 二等座 | second_seat |
| 硬卧 | hard_seat |
- 实操代码
# 解析数据
# 这个过程需要大家耐心的观察我们获得的数据与页面显示数据异同点
# 找到之间关系,然后取出干净的数据
for each in tick_res:
# print("-----")
need_data = re.split(r'\|预订\|', each)[1]
need_data = need_data.split('|')
# print(need_data)
# print(len(need_data))
checi.append(need_data[1])
# print(checi)
conversion_ch_reslut = self.conversion_ch(need_data[2],need_data[3])
from_station.append(conversion_ch_reslut[0])
to_station.append(conversion_ch_reslut[1])
from_time.append(need_data[6])
to_time.append(need_data[7])
total_time.append(need_data[8])
from_datetime.append(need_data[11])
high_soft.append(need_data[-16])
common_soft.append(need_data[-14])
no_seat.append(need_data[-11])
move_down.append(need_data[-4])
special_seat.append(need_data[-5])
first_seat.append(need_data[-6])
second_seat.append(need_data[-7])
hard_seat.append(need_data[-9])
return search_res, from_station, to_station, checi, from_station, to_station, from_time, to_time, total_time, from_datetime, high_soft, common_soft, no_seat, move_down, special_seat, second_seat, first_seat, hard_seat
# 将提取到的数据用图表的格式打印出来
# 这里用到模块PrettyTable
# 安装方法:cmd下 :
# pip install prettytable
def print_TicketInfo(self, search_result, raw_from_station, raw_to_station):
search_res,checi, from_station, to_station, from_time, to_time, total_time, from_datetime, high_soft, common_soft, no_seat, move_down, special_seat, second_seat, first_seat, hard_seat = self.jx(
search_result)
pt = PrettyTable(['车次','始发站','终点站','出发时间','到达时间','历时','出发日期','软卧','无座','动卧', '商务座', '一等座', '二等座', '硬卧'])
pt.align["车次"] = "l"
pt.padding_width = 1
print("---------从" + str(raw_from_station) + '到' + str(raw_to_station) + '共' + str(
search_res) + '个车次' + '---------')
for i in range(len(checi)):
pt.add_row([checi[i],from_station[i],to_station[i],from_time[i],to_time[i],total_time[i],from_datetime[i],common_soft[i],no_seat[i],move_down[i],special_seat[i],second_seat[i],first_seat[i],hard_seat[i]])
pt.reversesort = True
return pt
- 运行结果:


通过对比,没有问题,到此,我们的车票查询功能就做完了,查看全部源码,点击阅读原文。
三、后话连篇
通过本次实验,我们实现了12306车票查询与显示,这个过程中比较麻烦的还是数据的清理上,需要多次对比数据才能从我们获得的数据中拿到原始数据,另外,在显示数据上,我们用到了prettytable这个模块,我也是第一次用,感觉还不错,比自己print要简单很多。
下一次在更新,也不知道是什么时候,那时候我会带大家实现将查询信息发送到qq邮箱、手机上,看哪个简单来哪个,(如果不难得话)顺便实现购票,哈哈哈,加油。
