作者 | Mason MA
【Arthas 官方社区正在举行征文活动,参加即有奖品拿哦~点击投稿】
Arthas 是个不错的工具,这里要再安利一波,当然整个过程还用到了其他工具,如 MAT、YourKIT(这个是付费的),结合起来使用更加便于发现和解决问题。期间还和开发大佬多次沟通,分别获取了不同的信息。
一键安装并启动 Arthas
- 方式一:通过 Cloud Toolkit 实现 Arthas 一键远程诊断
Cloud Toolkit 是阿里云发布的免费本地 IDE 插件,帮助开发者更高效地开发、测试、诊断并部署应用。通过插件,可以将本地应用一键部署到任意服务器,甚至云端(ECS、EDAS、ACK、ACR 和 小程序云等);并且还内置了 Arthas 诊断、Dubbo工具、Terminal 终端、文件上传、函数计算 和 MySQL 执行器等工具。不仅仅有 IntelliJ IDEA 主流版本,还有 Eclipse、Pycharm、Maven 等其他版本。
推荐使用 IDEA 插件下载 Cloud Toolkit 来使用 Arthas:http://t.tb.cn/2A5CbHWveOXzI7sFakaCw8
- 方式二:直接下载
地址:https://github.com/alibaba/arthas。
现象
- 建索引的后台应用,感觉用不到那么大内存,现在用到了并且隔两天就会 oom,需要重启;
- 有全量数据和增量数据,OOM 大多发生在全量数据写入阶段,且 OOM 基本都在凌晨首次触发全量数据更新时出现;
- 业务应用使用了 G1 收集器(高级高级...)。
内心 OS:糟糕,G1 还不熟可怎么办,先想个办法把大佬们支开,我自己再慢慢研究。
我还有点别的事儿,我等会再看
苟胆假设
在现有掌握的信息下判断,大胆假设一下,反正猜错了又不会赔钱。
- 是否是因为全量数据写入,超过了堆的承载能力,导致了 OOM?
- 业务是否有 static 容器使用不当,一直没回收,一直往里 put 元素,所以需要两天 OOM 一次?
- 内存不够,是哪些对象占用最多,先找出来看看?
- 有没有大对象?
发抖求证
基本信息
进程启动参数
-Xms12g
-Xmx12g
-XX:+UseG1GC
-XX:InitiatingHeapOccupancyPercent=70
-XX:MaxGCPauseMillis=200
-XX:G1HeapWastePercent=20
-XX:+PrintAdaptiveSizePolicy
-XX:+UseStringDeduplication
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintTenuringDistribution
-Xloggc:/home/search/fse2/gc.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=2
-XX:GCLogFileSize=512M
-XX:+UnlockDiagnosticVMOptions
-XX:+PrintNMTStatistics
-XX:NativeMemoryTracking=summary
可以看到,使用了 G1 收集器,这个之前做业务开发的时候还不常见呢,毕竟是为大内存打造的追求低延迟的垃圾回收器。关于 G1 收集器的一些基本特性,大家可以去搜集一些资料。大概主要包括以下几项:
- Region 分区机制
- SATB,全称是 Snapshot-At-The-Beginning,由字面理解,是 GC 开始时活着的对象的一个快照
- Rset,全称是 Remembered Set,是辅助 GC 过程的一种结构,空间换时间思想
- Pause Prediction Model 即停顿预测模型
从 G1 的这些属性来看,它期望做到减少人为操作调优,实现自动化的调优(说到这里,感觉本次出现的 OOM 似乎跟垃圾收集器本身关联并不大,并不是因为业务量大堆内存不够用,可能根本原因在代码逻辑层面),并且适应在硬件成本降低,大内存堆逐渐变多的场景(后面还有 ZGC 和 Shenandoah,同样是可以管理超大内存并停顿很低的神奇垃圾收集器)。
已经有GC日志了,那先看看日志,发现一处异常:
#### 这里Heap回收的还只是300多M内存
[Eden: 316.0M(956.0M)->0.0B(1012.0M) Survivors: 48.0M->44.0M Heap: 359.2M(12.0G)->42.0M(12.0G)]
[Times: user=0.31 sys=0.01, real=0.05 secs]
2020-06-09T02:59:23.489+0800: 2020-06-09T02:59:23.489+0800: 35.922: Total time for which application threads were stopped: 0.0578199 seconds, Stopping threads took: 0.0000940 seconds
35.922: [GC concurrent-root-region-scan-start]
......
......
......
#### 这个点Heap回收的就是11G内存了
[Eden: 724.0M(1012.0M)->0.0B(540.0M) Survivors: 44.0M->72.0M Heap: 11.5G(12.0G)->355.6M(12.0G)]
[Times: user=1.51 sys=0.07, real=0.26 secs]
2020-06-09T03:12:36.329+0800: 828.762: Total time for which application threads were stopped: 0.2605902 seconds, Stopping threads took: 0.0000600 seconds
初次调试
增加 -XX:G1ReservePercent 选项的值,为“目标空间”增加预留内存量。
减少 -XX:InitiatingHeapOccupancyPercent 提前启动标记周期
怀疑在 GC 的当时,有大量数据全量写入,内存还没回收完,写进大量对象,导致了 OOM,于是调了启动周期,占比由 70 下降到55,提前触发,预留更多堆空间。
GC 变得频繁了,但是内存占用过大的问题并没有得到解释。并且是否会再次在凌晨出现 OOM 还需要等。。。于是还要继续看看有没有别的问题。
继续挖掘
有疑点没有解答,肯定是要继续挖掘的,抄起键盘就是干,一顿操作猛如虎。
Arthas
不知道哪位已经安装了,先拿来用用看吧,大概用到了以下几个命令:
dashboard
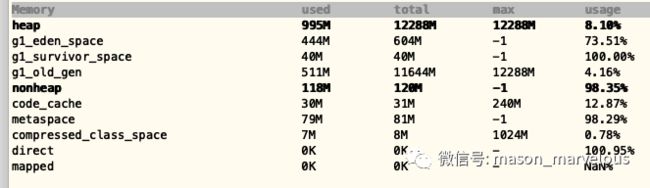
看看基本情况,线程数,堆大小,老年代大小,使用占比情况。首次看到这里时,eden 和 old 区的占用都挺高的, 70~80% 吧(当时忘了截图)。内存使用率比较高。
thread
看看线程数有没有异常,线程数正常,只是找出了资源占用比较高的线程,其中一个线程在后面其他信息统计中还会出现:
YJPAgent-Telemetry
ctrl-bidsearch-rank-shard1
YJPAgent-RequestListener
ctrl-bidsearch-rank-shard1
居然有两个线程是 YourKit 监控工具的 agent,看来这个监控工具对性能影响还挺大的。
profiler
分别采集一下内存和 CPU 的火焰图数据:
# 内存
profiler start --event alloc
###
profiler stop
# 默认CPU
profiler start
###
profiler stop
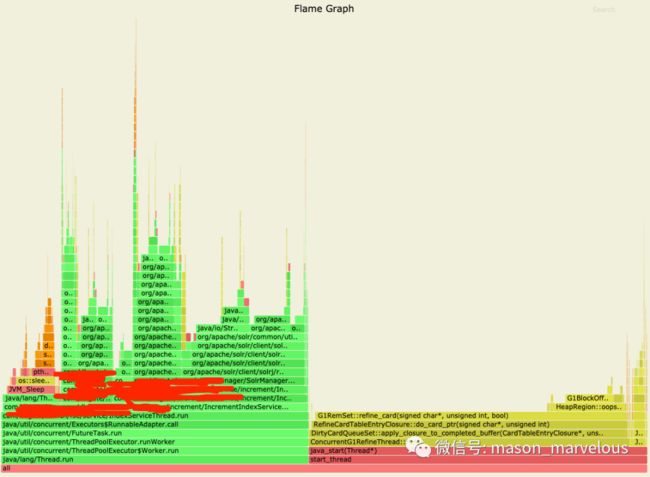
- CPU
- 内存
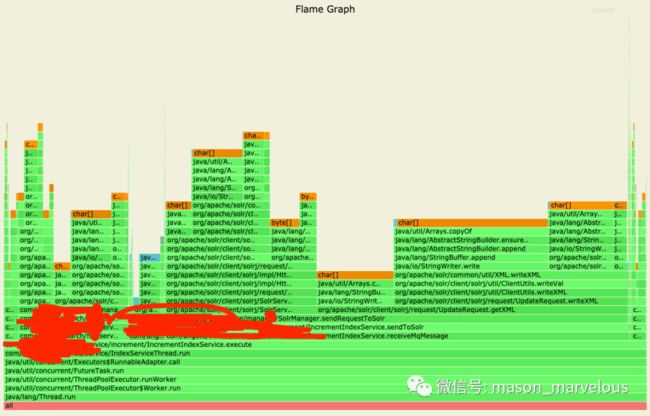
从 CPU 火焰图看到,G1 收集器线程居然占了一半资源,可能采集当时正在进行 GC,不过,除此之外,基本都能定位到是一个叫 IncrementIndexService 的类,使用了比较多的 CPU 和内存资源。
如果业务代码真的存在缺陷,那么一定在这个流程里,后来经过沟通,发现这个应用处理任务主要入口的确是在这里面。先持有保留意见。
thread 看到的线程和 profiler 看到的 class,都最终定位到是同一个业务流程。
开始验证之前的猜想:
1. 是否在全量数据写入的时候有大量对象涌入内存?
计算了一些业务代码获取数据的量,元数据大约也就在 1.3G 左右,就算全量写入,也不应该占用 12G 的堆内存,所以猜测全量数据写入时,代码逻辑可能有什么缺陷,导致 1.3G 的原数据被封装成远大于 1.3G 的对象了。
2. 是否有 static 容器?
有,但是经过 watch 观察,没有发现容器只 put 不 remove 的情况,命令如下:
watch com.xxx.classname method "{params,target}" -x 3
3. 有没有大对象?
对于 G1,默认将堆分成 2048 个 Region,12G 的堆,一个 Region 是 6M,超过 3M 才是大对象。
jmap histo 30123
至少输出的数据中,大对象不是 G1 定义的大对象。
MAT
既然没什么发现,就把堆 dump 出来吧。如果不想或者不能 dump,也可以用 jmap histo 查看内存占用,优点是不用 dump,缺点是通常不能很好的和业务代码之间建立关联。
警告:jmap 或者 Arthas 的 heapdump 操作之前一定要断开流量。好在我们这个服务没有线上流量,建索引有延迟,可能短暂影响搜索体验。
dump 出来之后,发现有 7 个 G,这么大的文件一般很难传到本地来分析了,于是用 MAT,占用服务器 1 个 G 内存进行分析,分析完成的结果下载到本地。
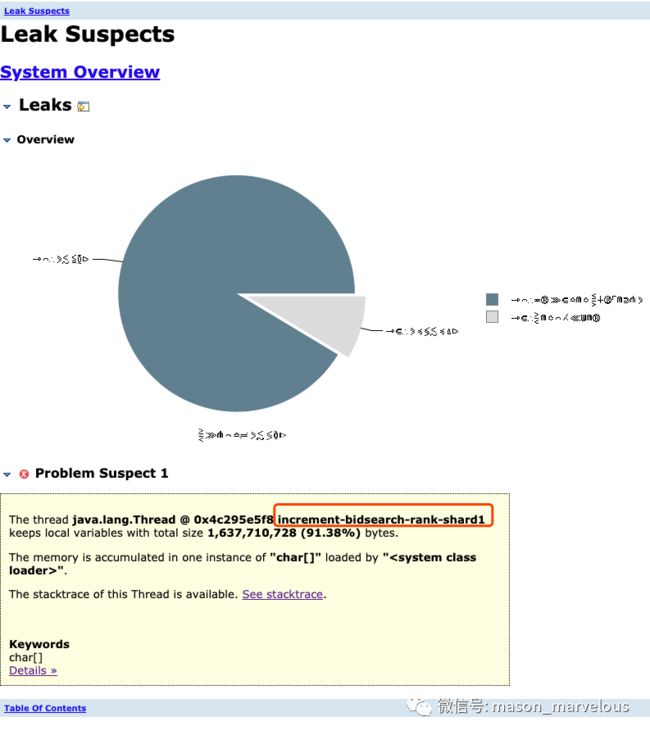
线程名称和之前发现的信息吻合,点开 detail 有惊喜。
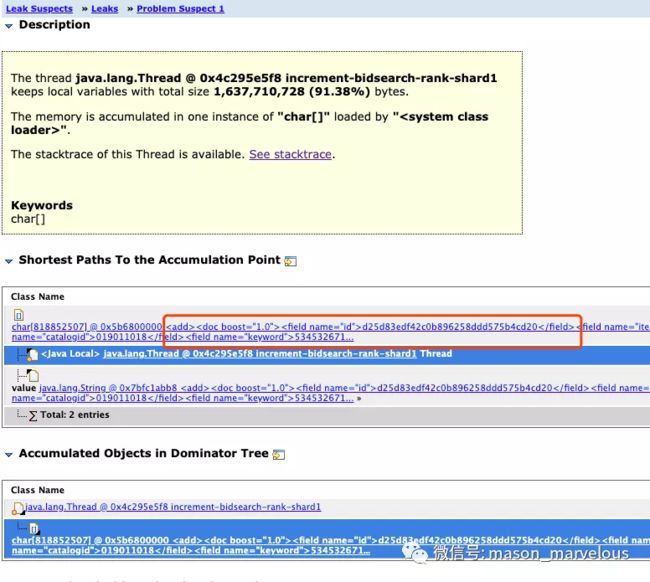
一串奇怪的字符串,有点像 XML,好像在拼装着什么,于是找到业务大佬请教,发现的确有拼装 solrDocument 的逻辑,而且,经过 YourKit 输出部分对象值的片段,可以发现有大部分是在重复拼装,大概意思如下:
...
CA
CA
CA
CA
CA
...n次重复
US
US
US
US
US
US
...n次重复
UK
UK
...
代码逻辑修改其实比较简单了,业务开发大佬们比较熟悉业务流程,很快就就有了修改方案。
调整之后发现,内存使用量下降了很多。

直接降到了 4-5G 左右,如果是这样的话,即便全量数据写入时,正在做垃圾回收,应该还是够用的。但是感觉这个代码逻辑里面,应该还有优化空间,不过,先解决问题,优化可以做下一步操作。
复盘
无论从哪个工具得出的数据,都显示 IncrementIndexService 这个类的逻辑可能有问题,最终问题的根本和 G1 参数设置好像也没什么关系,代码逻辑缺陷才是根源,再扩大内存可能或者调整 JVM 参数,也只能将故障缓解,但是不能解决。
-
从进程到线程到代码
-
获取 JVM 基本信息,收集器,启动参数等信息
-
查看现有的日志,GC 日志,业务日志
-
沟通业务场景,了解输入数据规模等等
-
猜想可能存在的原因,大胆的猜
-
使用工具(Arthas、MAT、YourKit、JDK 自带命令等等)挖掘信息,火焰图、耗能线程、线程栈 堆dump,占比分析 大对象 ...
-
结合数据重新梳理,发现业务代码的关联和可能存在的缺陷,可以尝试调整参数
-
业务代码若有 bug,修复 bug
Arthas 征文活动火热进行中
Arthas 官方正在举行征文活动,如果你有:
- 使用 Arthas 排查过的问题
- 对 Arthas 进行源码解读
- 对 Arthas 提出建议
- 不限,其它与 Arthas 有关的内容
欢迎参加征文活动,还有奖品拿哦~点击投稿
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”