Python之正则表达式
一 Python中通配符的使用
1.表示方式
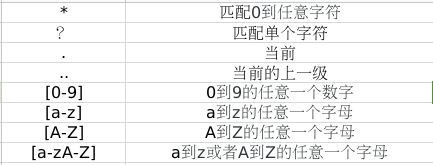
注意:以下内容在Linux Shell中可以识别,但在Python中不能被识别
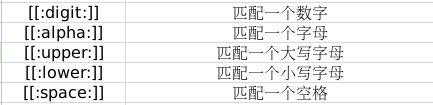
2.Python中的使用
glob模块
glob模块可使用Unix shell风格的通配符匹配符合特定格式的文件和文件夹,跟windows的文件搜索功能差不多。glob模块并非调用一个子shell实现搜索功能,而是在内部调用了os.listdir()和fnmatch.fnmatch()。用来查找目录或者文件
常用的两个方法是glob.glob和glob.iglob
- glob.glob:返回所有匹配正则的路径(返回的是一个列表)
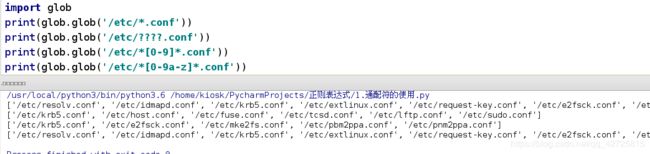
虽然glob模块可以很轻松地匹配特定文件和文件夹,但是仅仅支持少量的通配符.
没办法像正则表达式一样匹配更复杂的字符串
glob.iglob:返回所有匹配正则的路径(返回的是生成器),当有大量的文件时iglob更节约内存
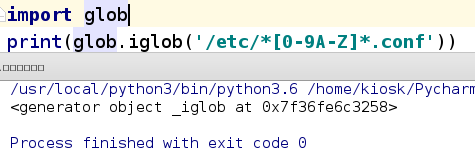
二 正则表达式
python标准库中用于正则表达式的为re模块
re = regular expression 正则表达式
作用: 对于字符串进行处理, 会检查这个字符串内容是否与你写的正则表达式匹配,如果匹配, 拿出匹配的内容; 如果不匹配,忽略不匹配内容;
. [ ] ^ $
这四个字符是所有语言都支持的正则表达式,所以这四个是基础的正则表达式
1.编写正则的规则
正则表达式描述了一种字符串匹配的模式(pattern),
可以用来检查一个串是否含有某种子串,将匹配的子串替换或者从某个串中取出符合某个条件的子串等.即将需要匹配的字符串的样式表示出来,一般为pattern = r’str’ (str为需要匹配的字符串)
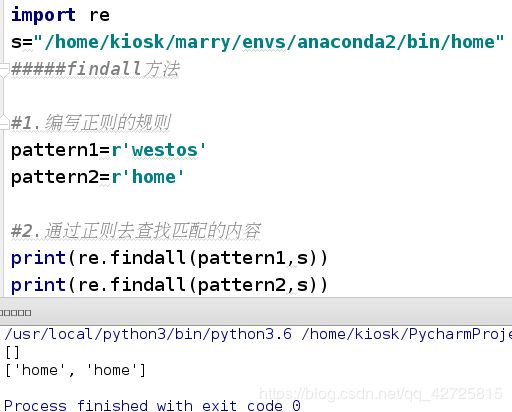
- findall方法
在表达了所要搜寻的字符串之后,使用findall()方法在指定范围中寻找。
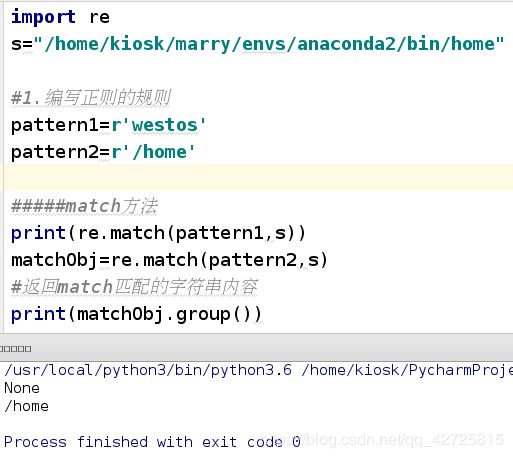
- match方法
match尝试从字符串的起始位置开始匹配,
- 如果起始位置没有匹配成功, 返回一个None;
- 如果起始位置匹配成功, 返回一个对象;
- search方法
search()会扫描整个字符串, 只返回第一个匹配成功的内容
- 如果能找到,返回一个对象,通过group方法获取对应的字符串
- 找不到的话就会报错

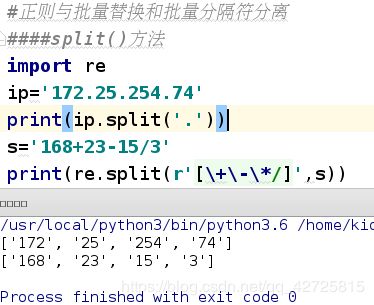
-split方法
-sub方法


2.正则表达式特殊字符类
. : 匹配除了\n之外的任意字符; [.\n]
\d: 匹配一个数字字符, 等价于[0-9]
\D: 匹配一个非数字字符, 等价于[^0-9]
\s: space(广义的空格: 空格, \t, \n, \r), 匹配单个任何的空白字符;
\S: 匹配除了单个任何的空白字符;
\w: 字母数字或者下划线,等价于 [a-zA-Z0-9_]
\W: 除了字母数字或者下划线, 等价于[^a-zA-Z0-9_]
import re
#字符类
s='westos1234westos'
pattern1=r'[^0-9]'
pattern2=r'[^aoeiu]'
print(re.findall(pattern1,s))
print(re.findall(pattern2,s))
print(re.findall(r'[^0-9]','westos1234westos'))
print(re.findall(r'[0-9]','westos1234westos'))
print(re.findall(r'[^aoeiu]','westos1234westos'))
#特殊字符类
print(re.findall(r'.','westos1234west\nos'))
print(re.findall(r'\d','当前文章阅读量为80'))
print(re.findall(r'\D','当前文章阅读量为800'))
print(re.findall(r'\s','我\n爱\tzhong\r国,$521'))
print(re.findall(r'\S','我\n爱\tzhong\r国,$521'))
print(re.findall(r'\w','我\n爱\tzhong\r国_啊,$521'))
print(re.findall(r'\W','我\n爱\tzhong\r国_啊,$521'))

3.语法与释义:
基础语法 “^([ ]{ })([ ]{ })([ ]{ })$”
正则字符串 = "开始([包含内容]{长度})([包含内容]{长度})([包含内容]{长度})结束"
实例
字符串;tel:086-0666-88810009999
原始正则:"^tel:[0-9]{1,3}-[0][0-9]{2,3}-[0-9]{8,11}$"
速记理解:开始 “tel:普通文本”[0-9数字]{1至3位}"-普通文本"[0数字][0-9数字]{2至3位}"-普通文本"[0-9数字]{8至11位} 结束"
等价简写后正则写法:"^tel:\d{1,3}-[0]\d{2,3}-\d{8,11}$",简写语法不是所有语言都支持
4.指定字符出现指定次数
: 代表前一个字符出现0次或者无限次; d*、 .*
+: 代表前一个字符出现一次或者无限次; d+
?: 代表前一个字符出现1次或者0次;
{m}: 前一个字符出现m次;
{m,}: 前一个字符至少出现m次; * == {0,}、+ ==={1,}
{m,n}: 前一个字符出现m次到n次; ? === {0,1}
import re
print(re.findall(r'd*', ''))
print(re.findall(r'd*', 'ddd'))
print(re.findall(r'd*', 'dwww'))
print(re.findall(r'.*', 'westos'))
print(re.findall(r'd+', ''))
print(re.findall(r'd+', 'ddd'))
print(re.findall(r'd+', 'dwww'))
print(re.findall(r'd+', 'westos'))
print(re.findall(r'188-?', '188 6543'))
print(re.findall(r'188-?', '188-6543'))
print(re.findall(r'188-?', '148-6543'))
pattern = r'\d{3}[\s-]?\d{4}[\s-]?\d{4}'
print(re.findall(pattern,'188 6754 7645'))
print(re.findall(pattern,'18867547645'))
print(re.findall(pattern,'188-6754-7645'))

5.常用运算符与表达式
^ :开始
( ):域段
[ ]: 包含,默认是一个字符长度
[^]: 不包含,默认是一个字符长度
{n,m}: 匹配长度
. :任何单个字符(. 字符点)
| :或
\ :转义
$ :结尾
6.正则中需要转移的字符
因为这些字符在正则中有特殊含义, 所以必须转义:
表示分组:
| : 匹配| 左右任意一个表达式即可;
(ab): 将括号中的字符作为一个分组
\num: 引用分组第num个匹配到的字符串
(?P): 分组起别名
import re
print(re.findall(r'westos|hello','whellowestos1haha'))
print(re.match(r'westos|hello','whellowestos1haha'))
print(re.match(r'westos|hello','hellowestos1haha').group())
#当使用分组时,findall方法只能获取到分组里面的内容
print(re.findall(r'(westos|hello)\d+','westoshello'))
print(re.findall(r'(westos|hello)\d+','hello2westos33'))
pattern = r'(\d+)'
s = '31'
print(re.findall(pattern, s))
#findall不能满足时,考虑使用search或者match
Obj=re.search(r'(westos|hello)(\d+)','westos2hello3')
if Obj:
print(Obj.group())
print(Obj.groups())
else:
print('Not find')
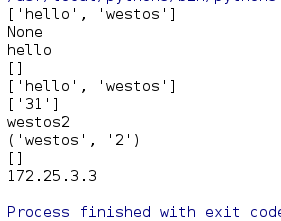
# 匹配IP
pattern = r'(([1-9]\d{0,2}\.){3}[1-9]\d{0,2})'
print(re.findall(pattern, '172.25.0.3'))
print(re.findall(pattern, '172.25.3.3')[0][0])
# \num
s = 'CSDN技术博客 '
# 目前有三个分组, \1: 代指第一个分组的内容, \2: 代指第一个分组的内容,
pattern = r'<(\w+)><(\w+)>(\w+)'
print(re.findall(pattern, s))
s1 = 'http://www.westos.org/linux/book/'
pattern = 'http://[\w\.]+/(?P\w+)/(?P\w+)/'
#print(re.findall(pattern, s1))
Obj = re.match(pattern, s1)
if Obj:
print(Obj.group())
print(Obj.groups())
print(Obj.groupdict())
else:
print('Not Found')
#身份证号:随便编写一个
s = '610897199004154534'
pattern = r'(?P\d{3})[\s-]?(?P\d{3})[\s-]?(?P\d{4})[\s-]?' \
r'(?P\d{2})(?P\d{2})(\d{4})'
Obj = re.search(pattern, s)
if Obj:
print(Obj.groupdict())
else:
print('Not Found')

三 正则表达式案例
1.匹配邮箱
匹配一个163邮箱;([email protected]) —>如果想在正则里面匹配真实的
xdshcdshvfhdvg(可以由字母数字或者下划线组成, 但是不能以数字或者下划线开头; 位数是6-12之间)
首先写出所需要邮箱的正则表达式:pattern = r’[A-z]\w{5,11}@qq.com’
1.163邮箱
提供以@163.com为后缀的免费邮箱,3G空间,支持超大20兆附件,280兆网盘。精准过滤超过98%的垃圾邮件。
2.新浪邮箱
提供以@sina.com为后缀的免费邮箱,容量2G,最大附件15M,支持POP3。
3.雅虎邮箱
提供形如@yahoo.com.cn的免费电子邮箱,容量3.5G,最大附件20m,支持21种文字。
4.搜狐邮箱
提供以@sohu.com结尾的免费邮箱服务,提供4G超大空间,支持单个超大10M附件。强大的反垃圾邮件系统为您过滤近98%的垃圾邮件。
5.QQ邮箱
提供以@qq.com为后缀的免费邮箱,容量无限大,最大附件50M,支持POP3,提供安全模式,内置WebQQ、阅读空间等。
import re
pattern=r'[A-z]\w{5,11}@qq\.com'
s="""
你好,各种格式的邮箱入下所示:
1. [email protected]
2. [email protected]
[email protected]
[email protected]
3. [email protected]
4. [email protected]
[email protected]
5. [email protected]
6. [email protected]
7. [email protected]
8. [email protected]
9. [email protected]
"""
dataLi = re.findall(pattern, s)
with open('email.txt', 'w') as f:
for email in dataLi:
f.write(email + '\n')
匹配IP地址
import re
pattern = r'[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}\.[1-9]\d{0,2}'
print(re.findall(pattern, '172.25.0.2'))
print(re.findall(pattern, '172.25.1.2'))
print(re.findall(pattern, '172.25.1.278'))
# | 代表或者的意思
pattern1 = r'^(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)$'
Obj = re.match(pattern1, '172.25.1.178')
if Obj:
print("查找到匹配的内容:", Obj.group())
else:
print('No Found')
Obj = re.match(pattern1, '172.25.1.278')
if Obj:
print("查找到匹配的内容:", Obj.group())
else:
print('No Found')
