Tensorflow-风格迁移
1.概述:
原始图像的VGG19的conv5_1作为内容,风格图片的VGG19的某几个层的gram矩阵作为风格。
计算风格损失和内容损失,不断迭代噪声+原始图像的像素值,最后得到结果。
2.风格损失原理:
Gram矩阵:n维欧式空间中任意k个向量之间两两的内积所组成的矩阵,称为这k个向量的格拉姆矩阵(Gram matrix)

简单来说就是内积可以反映出两个向量之间的某种关系或联系。Gram矩阵是两两向量的内积组成的,所以Gram矩阵可以反映出该组向量中各个向量之间的某种关系。
Gram Matrix可看做是图像各特征之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),Gram计算的是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等。另一方面,Gram的对角线元素,还体现了每个特征在图像中出现的量。
内积(点乘):


点乘的几何意义是可以用来表征或计算两个向量之间的夹角,以及在b向量在a向量方向上的投影。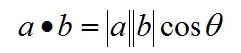

a·b>0 方向基本相同,夹角在0°到90°之间
a·b=0 正交,相互垂直
a·b<0 方向基本相反,夹角在90°到180°之间
叉乘:向量a和向量b的叉乘结果是法向量,该向量垂直于a和b向量构成的平面。
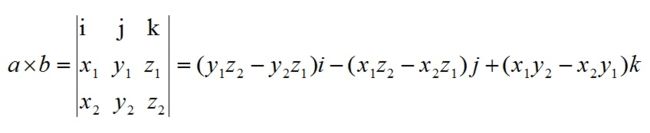

import tensorflow as tf
import numpy as np
import scipy.io
import scipy.misc
import os
#1一些参数
CONTENT_IMG = './images/test.jpg'
STYLE_IMG = './images/pink.jpg'
OUTOUT_DIR = './results'
OUTPUT_IMG = 'results.jpg'
VGG_MODEL = '/szl/imagenet-vgg-verydeep-19.mat'
ITERATION = 5000
#2噪声比例
INI_NOISE_RATIO = 0.1
#3风格权重
STYLE_STRENGTH = 0.2
#4所使用的VGG19内容层和风格层
CONTENT_LAYERS =[('conv5_1',1.)]
STYLE_LAYERS=[('conv1_1',1.),('conv2_1',1.),('conv3_1',1.),('conv4_1',1.),('conv5_1',1.)]
#5图像均值
MEAN_VALUES = np.array([127, 127, 127]).reshape((1,1,1,3))
#6根据传入的ntype(卷积/池化类型),nin(输入-上一层输出),nwb(偏置项),返回一个TF的操作
def build_net(ntype, nin, nwb=None):
if ntype == 'conv':
return tf.nn.relu(tf.nn.conv2d(nin, nwb[0], strides=[1, 1, 1, 1], padding='SAME')+ nwb[1])
elif ntype == 'pool':
return tf.nn.avg_pool(nin, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#7从VGG19中获取偏置
def get_weight_bias(vgg_layers, i,):
weights = vgg_layers[i][0][0][0][0][0]
weights = tf.constant(weights)
bias = vgg_layers[i][0][0][0][0][1]
bias = tf.constant(np.reshape(bias, (bias.size)))
return weights, bias
#8调用 ‘6’build_net 构建VGG19网络,返回一个net的操作
def build_vgg19(path):
net = {}
vgg_rawnet = scipy.io.loadmat(path)
vgg_layers = vgg_rawnet['layers'][0]
net['input'] = tf.Variable(np.zeros((1, IMAGE_H, IMAGE_W, 3)).astype('float32'))
net['conv1_1'] = build_net('conv',net['input'],get_weight_bias(vgg_layers,0))
net['conv1_2'] = build_net('conv',net['conv1_1'],get_weight_bias(vgg_layers,2))
net['pool1'] = build_net('pool',net['conv1_2'])
net['conv2_1'] = build_net('conv',net['pool1'],get_weight_bias(vgg_layers,5))
net['conv2_2'] = build_net('conv',net['conv2_1'],get_weight_bias(vgg_layers,7))
net['pool2'] = build_net('pool',net['conv2_2'])
net['conv3_1'] = build_net('conv',net['pool2'],get_weight_bias(vgg_layers,10))
net['conv3_2'] = build_net('conv',net['conv3_1'],get_weight_bias(vgg_layers,12))
net['conv3_3'] = build_net('conv',net['conv3_2'],get_weight_bias(vgg_layers,14))
net['conv3_4'] = build_net('conv',net['conv3_3'],get_weight_bias(vgg_layers,16))
net['pool3'] = build_net('pool',net['conv3_4'])
net['conv4_1'] = build_net('conv',net['pool3'],get_weight_bias(vgg_layers,19))
net['conv4_2'] = build_net('conv',net['conv4_1'],get_weight_bias(vgg_layers,21))
net['conv4_3'] = build_net('conv',net['conv4_2'],get_weight_bias(vgg_layers,23))
net['conv4_4'] = build_net('conv',net['conv4_3'],get_weight_bias(vgg_layers,25))
net['pool4'] = build_net('pool',net['conv4_4'])
net['conv5_1'] = build_net('conv',net['pool4'],get_weight_bias(vgg_layers,28))
net['conv5_2'] = build_net('conv',net['conv5_1'],get_weight_bias(vgg_layers,30))
net['conv5_3'] = build_net('conv',net['conv5_2'],get_weight_bias(vgg_layers,32))
net['conv5_4'] = build_net('conv',net['conv5_3'],get_weight_bias(vgg_layers,34))
net['pool5'] = build_net('pool',net['conv5_4'])
return net
#9构建内容损失,给定两个tensor p和x 返回它们的MSE差值作为loss
def build_content_loss(p, x):
M = p.shape[1]*p.shape[2]
N = p.shape[3]
loss = (1./(2* N**0.5 * M**0.5 )) * tf.reduce_sum(tf.pow((x - p),2))
return loss
#10计算gram矩阵
def gram_matrix(x, area, depth):
x1 = tf.reshape(x,(area,depth))
g = tf.matmul(tf.transpose(x1), x1)
return g
#11计算gram矩阵
def gram_matrix_val(x, area, depth):
x1 = x.reshape(area,depth)
g = np.dot(x1.T, x1)
return g
#12构建风格损失,给定两个tensor a和x ,计算两者的gram矩阵,返回两者gram矩阵的MSE作为loss
def build_style_loss(a, x):
M = a.shape[1]*a.shape[2]
N = a.shape[3]
A = gram_matrix_val(a, M, N )
G = gram_matrix(x, M, N )
loss = (1./(4 * N**2 * M**2)) * tf.reduce_sum(tf.pow((G - A),2))
return loss
#13使用scipy读取图像,并减去均值
def read_image(path):
image = scipy.misc.imread(path)
image = scipy.misc.imresize(image,(IMAGE_H,IMAGE_W))
image = image[np.newaxis,:,:,:]
image = image - MEAN_VALUES
return image
#14使用scipy写入图像,并限制像素值范围
def write_image(path, image):
image = image + MEAN_VALUES
image = image[0]
image = np.clip(image, 0, 255).astype('uint8')#限制像素范围,0-255
scipy.misc.imsave(path, image)
#15主函数
def main():
net = build_vgg19(VGG_MODEL)#net是VGG16的op
sess = tf.Session()#创建sess
sess.run(tf.initialize_all_variables())#初始全局变量
style_img = read_image(STYLE_IMG)#读取风格图片
content_img = read_image(CONTENT_IMG)#读取内容图片
noise_img = np.random.uniform(-10, 10, (1, IMAGE_H, IMAGE_W, 3)).astype('float32')#生成噪声图
sess.run([net['input'].assign(content_img)])#将内容图片feed网络
cost_content = sum(map(lambda l,: l[1]*build_content_loss(sess.run(net[l[0]]) , net[l[0]])
, CONTENT_LAYERS))#output=sess.run(net[l[0]]),input=net[l[0]],计算两者内容损失
sess.run([net['input'].assign(style_img)])#将风格图片feed网络
cost_style = sum(map(lambda l: l[1]*build_style_loss(sess.run(net[l[0]]) , net[l[0]])
, STYLE_LAYERS))#output=sess.run(net[l[0]]),input=net[l[0]],计算两者风格损失
cost_total = (1 - STYLE_STRENGTH) * cost_content + STYLE_STRENGTH * cost_style#总损失
optimizer = tf.train.AdamOptimizer(2.0)#优化器
train = optimizer.minimize(cost_total)#训练op
sess.run(tf.initialize_all_variables())#初始化后续变量
sess.run(net['input'].assign( INI_NOISE_RATIO* noise_img + (1.-INI_NOISE_RATIO) * content_img))#将噪声图片以一个因子累加到内容图片上去,作为feed网络的输入
if not os.path.exists(OUTOUT_DIR):
os.mkdir(OUTOUT_DIR)
for i in range(ITERATION):
sess.run(train)
if i%100 ==0:
result_img = sess.run(net['input'])#feed噪声内容图片输入,得到结果
print (sess.run(cost_total))
write_image(os.path.join(OUTOUT_DIR,'%s.jpg'%(str(i).zfill(4))),result_img)#保存结果
write_image(os.path.join(OUTOUT_DIR,OUTPUT_IMG),result_img)
if __name__ == '__main__':
image = scipy.misc.imread(CONTENT_IMG)
IMAGE_H,IMAGE_W,C= image.shape
print (IMAGE_W)
print (IMAGE_H)
#IMAGE_W = IMAGE_W/2
#IMAGE_H = IMAGE_H/2
print ("init params ok")
main()