WebRTC之beamforming算法
我的书:

购买链接:
京东购买链接
淘宝购买链接
当当购买链接
坐标问题
这里以笔记本为例进行说明,当笔记本按如下方式打开:

首先是键盘和液晶屏呈90度,然后鼠标上方,也就是液晶屏上方正中间是camera,把平行于键盘的面看成是xy平面,把液晶屏所在的面看成是xz平面,所有平面的原点都在Camera的位置。
方位角:从原点开始,Camera的右侧是0度,逆时针方向是正,也就是液晶屏和键盘交界的那条线的左边是x正方向(靠esc键盘),右边是负半轴,正中间,也就是Camera的位置是原点,x的正方向向着ThinkPad的小红点转,这时得到的角度是正值,转到红点方向正好是90度。
俯仰角:把和xy平面(平行于键盘,但是原点在Camera位置)线,从图中鼠标到Camera的方向称为z轴的正向,从x的正半轴方向向z的正方向转动是俯仰角的正方向。
最后的一个参数radius,是声源到Camera的直线距离。
可执行测试程序的编译
gsc@gsc-250:~/webrtc-checkout/src/webrtc/modules/audio_processing$ 目录下的"audio_processing_tests.gypi" 文件的153 行,如下:
该文件是gypi(generated your project included)格式的文件,语法类似json和python。编译的目标是nonlinear_beamformer_test。该文件编译的源文件是
beamformer/nonlinear_beamformer_test.cc
查找该目标的所在位置:

如果需要修改源文件,并编译生成nonlinear_beamformer_test这个测试文件,参考下面的文章,写这篇博文时,WebRTC的版本是2016年5月1日,下面链接中网盘里的版本比这里的稍早。
http://blog.csdn.net/shichaog/article/details/50246155
执行该可执行测试文件如下,该文件编译生成方法见上面链接博文。
关键数据结构
class NonlinearBeamformer
: public Beamformer,
public LappedTransform::Callback {
public:
static const float kHalfBeamWidthRadians;
explicit NonlinearBeamformer(
const std::vector& array_geometry,
SphericalPointf target_direction =
SphericalPointf(static_cast(M_PI) / 2.f, 0.f, 1.f));
// Sample rate corresponds to the lower band.
// Needs to be called before the NonlinearBeamformer can be used.
void Initialize(int chunk_size_ms, int sample_rate_hz) override;
// Process one time-domain chunk of audio. The audio is expected to be split
// into frequency bands inside the ChannelBuffer. The number of frames and
// channels must correspond to the constructor parameters. The same
// ChannelBuffer can be passed in as |input| and |output|.
void ProcessChunk(const ChannelBuffer& input,
ChannelBuffer* output) override;
void AimAt(const SphericalPointf& target_direction) override;
bool IsInBeam(const SphericalPointf& spherical_point) override;
// After processing each block |is_target_present_| is set to true if the
// target signal es present and to false otherwise. This methods can be called
// to know if the data is target signal or interference and process it
// accordingly.
bool is_target_present() override { return is_target_present_; }
protected:
// Process one frequency-domain block of audio. This is where the fun
// happens. Implements LappedTransform::Callback.
void ProcessAudioBlock(const complex* const* input,
size_t num_input_channels,
size_t num_freq_bins,
size_t num_output_channels,
complex* const* output) override;
private:
FRIEND_TEST_ALL_PREFIXES(NonlinearBeamformerTest,
InterfAnglesTakeAmbiguityIntoAccount);
typedef Matrix MatrixF;
typedef ComplexMatrix ComplexMatrixF;
typedef complex complex_f;
void InitLowFrequencyCorrectionRanges();
void InitHighFrequencyCorrectionRanges();
void InitInterfAngles();
void InitDelaySumMasks();
void InitTargetCovMats();
void InitDiffuseCovMats();
void InitInterfCovMats();
void NormalizeCovMats();
// Calculates postfilter masks that minimize the mean squared error of our
// estimation of the desired signal.
float CalculatePostfilterMask(const ComplexMatrixF& interf_cov_mat,
float rpsiw,
float ratio_rxiw_rxim,
float rmxi_r);
// Prevents the postfilter masks from degenerating too quickly (a cause of
// musical noise).
void ApplyMaskTimeSmoothing();
void ApplyMaskFrequencySmoothing();
// The postfilter masks are unreliable at low frequencies. Calculates a better
// mask by averaging mid-low frequency values.
void ApplyLowFrequencyCorrection();
// Postfilter masks are also unreliable at high frequencies. Average mid-high
// frequency masks to calculate a single mask per block which can be applied
// in the time-domain. Further, we average these block-masks over a chunk,
// resulting in one postfilter mask per audio chunk. This allows us to skip
// both transforming and blocking the high-frequency signal.
void ApplyHighFrequencyCorrection();
// Compute the means needed for the above frequency correction.
float MaskRangeMean(size_t start_bin, size_t end_bin);
// Applies both sets of masks to |input| and store in |output|.
void ApplyMasks(const complex_f* const* input, complex_f* const* output);
void EstimateTargetPresence();
static const size_t kFftSize = 256;
static const size_t kNumFreqBins = kFftSize / 2 + 1;
// Deals with the fft transform and blocking.
size_t chunk_length_;
std::unique_ptr lapped_transform_;
float window_[kFftSize];
// Parameters exposed to the user.
const size_t num_input_channels_;
int sample_rate_hz_;
const std::vector array_geometry_;
// The normal direction of the array if it has one and it is in the xy-plane.
const rtc::Optional array_normal_;
// Minimum spacing between microphone pairs.
const float min_mic_spacing_;
// Calculated based on user-input and constants in the .cc file.
size_t low_mean_start_bin_;
size_t low_mean_end_bin_;
size_t high_mean_start_bin_;
size_t high_mean_end_bin_;
// Quickly varying mask updated every block.
float new_mask_[kNumFreqBins];
// Time smoothed mask.
float time_smooth_mask_[kNumFreqBins];
// Time and frequency smoothed mask.
float final_mask_[kNumFreqBins];
float target_angle_radians_;
// Angles of the interferer scenarios.
std::vector interf_angles_radians_;
// The angle between the target and the interferer scenarios.
const float away_radians_;
// Array of length |kNumFreqBins|, Matrix of size |1| x |num_channels_|.
ComplexMatrixF delay_sum_masks_[kNumFreqBins];
ComplexMatrixF normalized_delay_sum_masks_[kNumFreqBins];
// Arrays of length |kNumFreqBins|, Matrix of size |num_input_channels_| x
// |num_input_channels_|.
ComplexMatrixF target_cov_mats_[kNumFreqBins];
ComplexMatrixF uniform_cov_mat_[kNumFreqBins];
// Array of length |kNumFreqBins|, Matrix of size |num_input_channels_| x
// |num_input_channels_|. ScopedVector has a size equal to the number of
// interferer scenarios.
ScopedVector interf_cov_mats_[kNumFreqBins];
// Of length |kNumFreqBins|.
float wave_numbers_[kNumFreqBins];
// Preallocated for ProcessAudioBlock()
// Of length |kNumFreqBins|.
float rxiws_[kNumFreqBins];
// The vector has a size equal to the number of interferer scenarios.
std::vector rpsiws_[kNumFreqBins];
// The microphone normalization factor.
ComplexMatrixF eig_m_;
// For processing the high-frequency input signal.
float high_pass_postfilter_mask_;
// True when the target signal is present.
bool is_target_present_;
// Number of blocks after which the data is considered interference if the
// mask does not pass |kMaskSignalThreshold|.
size_t hold_target_blocks_;
// Number of blocks since the last mask that passed |kMaskSignalThreshold|.
size_t interference_blocks_count_;
}; 源文件
前问说道nonlinear_beamformer_test.cc文件,该文件所采用的算法是非线性波束形成算法,这里非线性是针对频域而言的。
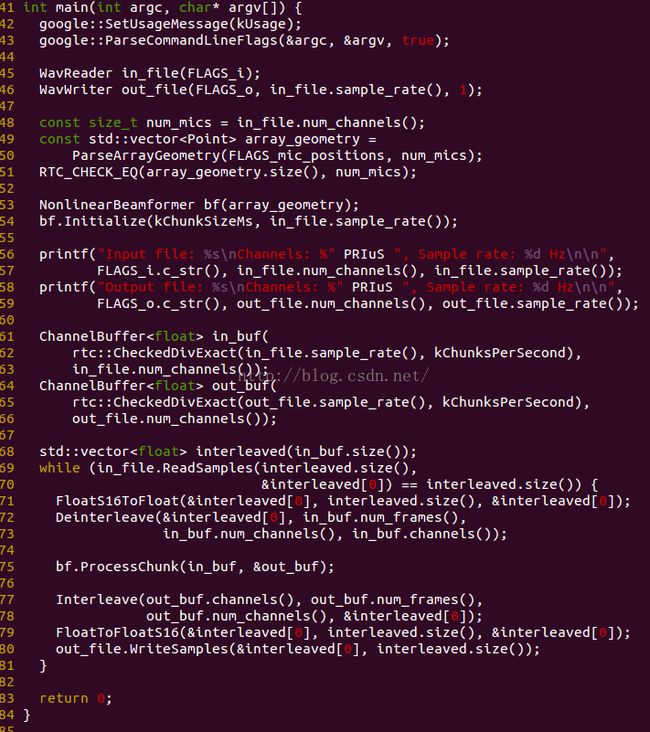
该文件处理流程比较清晰,首先根据读入的wav文件,获得采样率和通道数(麦克风个数),然后获得麦克的物理位置,

从输出可以看出,输入信号采样率是16k,三通道,输出信号的采样率是16k,一个通道,将三个通道合成为了一个通道。根据这个可执行程序,就可以一步步打印相关的中间执行结果,这有利于更好的弄懂webRTC的beamforming算法。
激励麦克风阵列声源产生
该算法涉及的信号处理方法比较多,此外还有矩阵相关的知识,如果不是信号处理专业出身,估计比较难自己看懂。闲话不说,接着往下看。
在上面截图中有一个out2.wav的文件,该文件是输入测试激励文件。该文件使用一路麦克风采集而来,外加matlab处理而成,这样可以软硬件并行话。
[y,Fs] = audioread('test.wav');
y_left=y(:, 1);
y_right=y(:,1);
X=[y_left y_right y_left];
audiowrite('out2.wav',X,Fs);之所以y_left和y_right表达式一样,是因为这里的test.wav是单声道音源。X那行将其组成三路,模拟三个麦克风的输入,最后一行将其写入到out2.wav文件中,该wav文件用于测试。
有了测试程序和测试输入激励,接下来就方便一步步分析了。
测试源程序:
![]()
由编译规则,可以知道,编译的源文件是nonlinear_beamformer_test.cc
下面的英文节选部分PPT内容,是用以指导麦克风阵列设计
SNR :Microphone Array Evaluation Criteria
SNR(signal to noise ratio)
SNR(dB)=10lg(Ps/Pn),
Ps=signal power, Pn=noise power.
If SNR=0, then Ps=Pn,
If SNR=3dB, then Ps=2Pn
Major factors influence SNR
- Input ambient noise,(human,animal, home appliance…)
- Number of Microphones
- Microphone aperture
- Electric factors(LED high freqency noise, TEM, audio, subwoofer)
- Mechanical structure of Pebble
- Influence of microphone self,(temperature drift, consistency, lifetime)
SNR vs ASR intelligibility
every 4 - 5dB improvement of the Signal to Noise Ratio (SNR) may raise the speech intelligibility by 50%--- Development of a directional hearing instrument based on array technology,1993
Number of Microphones
Output SNR =N*SNR
Input ambient noise
Microphone aperture-1
d ≤ λ /2 = c/2f=343000/(2*4000)=42.857mm
Microphone aperture-2
Min=L;
Echo:75mm,f<4.573KHz
Microphone aperture-3
Distance between microphone vs spatial resolution.
6mic/8cm,3d-20°
Microphone aperture-conclusion
6mic/80mm
Aliasing and spectral leakage < 4.287K Hz
Spatial resolution 20°(3dB)
程序相关定义变量的意义
chunk_length:每个通道采样点个数。
window:回调函数callback使用的参数,window 的长度应当和block_length等长。
block_length:一个block的长度(以采样点数计算)。后面的FFT处理是以block为单位进行的。
shift_amount:也是以采样点数计算,重叠变换法中移位的点数。
callback:输入通道的每一个block应该调用的处理函数。
chunk_length:每个channel的采样点数,一个channel对应于一路麦克风。
new LappedTransform(num_input_channels_,
1,
chunk_length_,
window_,
kFftSize,
kFftSize / 2,
this));
重叠变换法:
LappedTransform(size_t num_in_channels,
size_t num_out_channels,
size_t chunk_length,
const float* window,
size_t block_length,
size_t shift_amount,
Callback* callback);Blocker的主要是处理接收到的音频帧长不等于变换的长度。例如,多数FFT变换为了使效率最高,通常做2的指数为长度做FFT的变换。但是如果我们接收到20ms采样率为48K是音频数据,则有960(48000*0.02)帧frame。但960并不是2的指数倍。Blocker允许我们在不限制变换长度(对于读是block_size_,对于接收音频size是chunk_size_)的前提下指定变换算法以及通过Process()回调函数完成的其它的一些处理。
Blocker负责处理如下问题:
当处理chunk的边缘潜在的不连续问题时阻塞audio
在送入process之前对块进行加窗
在返回一个处理chunk之前,对处理的block进行加窗处理,并采用重叠相加法进行重组chunk。
在使用blocker时:
1.实现一个BlockerCallback对象|bc|
2.例化一个Blocker对象|b|,将|bc|传递给|b|
3.当接收到audio数据时,调用b.ProcessChunk()获得处理过的audio
modules/audio_processing/beamformer/nonlinear_beamformer.h:170: ComplexMatrixF uniform_cov_mat_[kNumFreqBins];LappedTransform::BlockThunk::ProcessBlock:首先对每一个channel做FFT变换,
NonlinearBeamformer::Initialize
f(k)=k*(fs/n)====>f(k)=k*(16000/256)=k*125Hz(每个点)
static const size_t kFftSize = 256;
static const size_t kNumFreqBins = kFftSize / 2 + 1;256点FFT,原始模拟信号最高频率8KHz,采样率为16KHz;n的范围是0,1,2,...,255;16KHz的频率被分成了256份。每一份是62.5Hz,这就意味这8K范围的信号只需要关注前128个点,即62.5Hz*128=8KHz.
hold_target_blocks_ = kHoldTargetSeconds * 2 * sample_rate_hz / kFftSize;
NonlinearBeamformer::NonlinearBeamformer
{
//x1 y1 z1 x2 y2 z2
const int kChunksPerSecond = 100;
const int kChunkSizeMs = 1000 / kChunksPerSecond;
num_input_channels_:是输入麦克风阵列的个数。
array_geometry_:是坐标的平均值,x1'=(x1+x2+...+xn)/N-x1,以此类推。
array_normal_:似乎是在求解正规矩阵,如果是正规矩阵,分线阵和面阵两种情况,如果是线阵则正规矩阵取前两个麦克风计算所得向量(x2-x1,y2-y1,z2-z1),
min_mic_spacing_:所有两个麦克风之间距离的最小值。
target_angle_radians_:球坐标下声源方位角的弧度值。
away_radians_:声源和干扰源分辨的角度(弧度单位),min(pi, max(kMinAwayRadians = 0.2f,kAwaySlope = 0.008f*pi/min_mic_spacing_));
window_:WindowGenerator::KaiserBesselDerived(kKbdAlpha, kFftSize, window_),凯撒贝塞尔窗函数,参考公式。
}
NonlinearBeamformer::Initialize{
const int kChunksPerSecond = 100;
const int kChunkSizeMs = 1000 / kChunksPerSecond;
首先是传递给该函数的两个参数的意义。
chunk_size_ms:表示的意义是1ms对应的chunk大小,chunk是频域一次处理数据量的大小。
sample_rate_hz:输入信号的采样率,16k
chunk_length_ =(sample_rate_hz / (1000.f / chunk_size_ms))= 16000/(1000/10)=1600;
sample_rate_hz_ = 16k;(由输入音源决定)
high_pass_postfilter_mask_ = 1.f;
is_target_present_ = false;
// 超过kMaskTargetThreshold,则将被认为是声音而非干扰,每当后置滤波器有大的改变,则其也要被跟新。
const float kMaskTargetThreshold = 0.01f;
// 如果mask小于|kMaskTargetThreshold|,则其后kHoldTargetSeconds时间内的数据将被认为是干扰。
const float kHoldTargetSeconds = 0.25f;
hold_target_blocks_ = kHoldTargetSeconds * 2 * sample_rate_hz / kFftSize;=0.25()*2*16000=8000;
interference_blocks_count_=hold_target_blocks_;
//重叠变换法reset.
lapped_transform_.reset(new LappedTransform(num_input_channels_,
1,
chunk_length_(1600),
window_(凯撒贝塞尔窗函数),
kFftSize(256),
kFftSize / 2,
this));
for (size_t i = 0; i < kNumFreqBins(256); ++i)[
time_smooth_mask_[i] = 1.f;
final_mask_[i] = 1.f;
float freq_hz = (static_cast(i) / kFftSize) * sample_rate_hz_;
wave_numbers_[i] = 2 * M_PI * freq_hz / kSpeedOfSoundMeterSeconds;
]
NonlinearBeamformer::InitLowFrequencyCorrectionRanges
low_mean_start_bin_ = kLowMeanStartHz = 200;
low_mean_end_bin_ = int kLowMeanEndHz = 400;
NonlinearBeamformer::InitDiffuseCovMats()
for (size_t i = 0; i < kNumFreqBins; ++i)[
uniform_cov_mat_:坐标的协方差矩阵,和array_geometry_以及wave_numbers_有关,其还做了0介贝塞尔。使用第一个元素先归一化然后乘以(1 - kBalance);
]
} Deinterleave:原来是通道一然后通道2...;现在变成通道1第一个点,通道2第一个点.....
//每一个chunck会处理一次,其内部将数据进行分块block,将它们变换到频域,对每一个block调用callback回调函数进行处理,
//并且将去block的时域结果存在第二个参数中,其lapped_transform_的实现在Lapped_transform.cc文件。
NonlinearBeamformer::ProcessChunk()
{
old_high_pass_mask = high_pass_postfilter_mask_;保存前一次mask值。
lapped_transform_->ProcessChunk(input.channels(0), output->channels(0));//使用重叠变换法处理一帧数据。
|
------- blocker_.ProcessChunk(in_chunk, chunk_length_, num_in_channels_,
num_out_channels_, out_chunk);
frame_offset_:初始值是0,构造函数默认将其设置为0.
frames [0.0 0.1 ...]
[1.0 1.1 ...]
}
NonlinearBeamformer::Initialize
|
|
------LappedTransform(num_input_channels_,
1,
chunk_length_(1600),
window_(凯撒贝塞尔),
kFftSize,
kFftSize / 2,
this));
|
|
----- blocker_(chunk_length_(1600),
block_length_(kFftSize),
num_in_channels_,
num_out_channels_,
window(kaiserbesselderived),
shift_amount(kFftSize / 2),
&blocker_callback_(LappedTransform)),
|
|
-----LappedTransform::BlockThunk::ProcessBlock()
fft_->Forward,对每一行(路)麦克风做FFT变换。(重叠变换法)
block_processor_->ProcessAudioBlock 核心函数(重中之重)
fft_->Inverse,逆FFT返回时域。
void NonlinearBeamformer::ProcessAudioBlock(const complex_f* const* input, //麦克风阵列FFT结果输入
size_t num_input_channels, //num_input_channels_
size_t num_freq_bins, //等于kNumFreqBins,kFftSize / 2+1
size_t num_output_channels, //1
complex_f* const* output)
LappedTransform* const parent_;
webRTC中apm是audio processing module的简称。其原型定义如下
RERL:residual echo return loss
ERL:echo return loss
ERLE:echo return loss enhancement