深入解析Ceph分布式存储的内核客户端
作者:Prashant Murthy 原文地址:https://engineering.salesforce.com/deep-dive-into-cephs-kernel-client-edea75787528
译者:Sunny Zhang
随着云计算的发展,Ceph已经成为目前最为流行的分布式存储系统,俨然存储界的Linux操作系统。Ceph集块存储、文件存储和对象存储于一身,适用场景广泛,用户众多。本文是介绍Ceph客户端在内核部分的实现的文章,本号特以翻译成中文。(译者)
Ceph是一个开源,统一的分布式存储系统,我们在Salesforce中用作块存储服务。Ceph的块存储通过一个客户端模块实现,这个客户端可以直接从数据守护进程读写数据(不需要经过一个网关)。根据客户端整合生态系统的差异(译者注:也就是应用场景),客户端有两种实现方式:
- librbd (用户态)
- krbd (内核态)
Librbd是一个典型的应用就是在虚拟机环境中(例如KVM或者QEMu),而krbd则是用在容器和裸金属环境。在Salesforce, 我们将Ceph作为Docker容器并且在应用容器运行主机上安装krbd模块。
本文将描述Ceph内核客户端的一些内部实现。下面是本文涵盖的内容:
- 初始化
- Ceph的配置是如何被内核模块获取的
- 处理配置的代码入口点
- 连接处理
- 安全
- 连接状态机
krbd 初始化
krbd是一个内核模块。其在内核中以一个块设备的方式加以实现。整个Ceph客户端都是以内核模块的方式实现(没有与之相关的用户态进程或者守护进程)。
Ceph客户端需要一个配置文件(ceph.conf)以知道如何连接集群,并且需要知道集群的属性。该配置文件通常包括Monitor的IP地址、用户证书和Ceph认证的安全属性(Cephx)。在初始化的时候,所有这些配置都需要加载到内核模块当中。一旦完成这一步,剩下的诸如镜像或者卷生命周期、连接管理、认证和状态机等所有实现都可以在内核模块中完成。
将CEPH配置推送到内核模块
当你运行ceph-deploy去安装客户端的时候,它将安装在Ceph客户端(以rbd为前缀的命令)CLI命令调用的二进制文件。
rbd CLI
第一个客户端命令是:
rbd map --pool
默认情况下,rbd从配置文件/etc/ceph/ceph.conf中读取配置信息。该文件包含诸如Monitor地址(客户端通过该地址与Monitor联系)、OSD闲时ttl、OSD超时时间、OSD请求超时和加密等内容。关于配置项的全量列表可以从这个地址获取:http://docs.ceph.com/docs/jewel/man/8/rbd/#kernel-rbd-krbd-options。
OSD

krbd 初始化
rbd map命令行命令实际上读取ceph.conf文件的内容,并且通过Linux的“总线”接口(/sys/bus/<extension> - 我们的场景下是 /sys/bus/rbd/add)推送这些配置信息给krbd内核模块。
定义依赖这里: https://github.com/torvalds/linux/blob/master/include/linux/device.h
总线(bus)是处理器和一个或者多个设备间的通道。其目的是实现设备模型,所有设备由总线连接,甚至可以是一个内部的、虚拟的平台(platform)总线。总线之间可以彼此连接,比如一个USB控制器通常是一个PCI设备。设备模型代表总线和它们所控制设备的实际连接。
在Linux设备模型中,bus_type结构体代表一个总线,在linux/device.h中定义。该结构体如下:
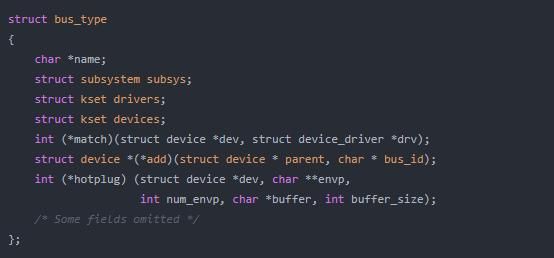
本实现的源代码在ceph/ceph git库,具体如下:https://github.com/ceph/ceph/blob/master/src/krbd.cc
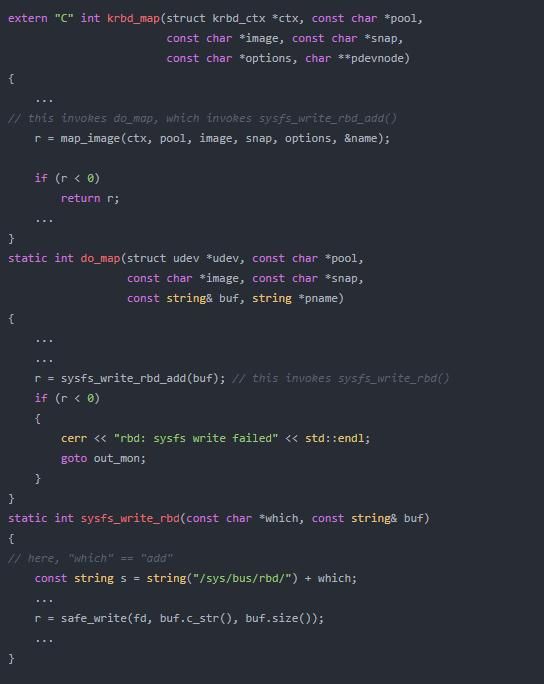
KRBD 配置解析
在内核模块中,处理配置文件的入口点定义在drivers/block/rbd.c 中(https://github.com/ceph/ceph-client/blob/for-linus/drivers/block/rbd.c):
static ssize_t rbd_add(struct bus_type *bus, const char *buf, size_t count)
连接设置
内核模块全权负责建立与Monitor和OSD的TCP连接,检测这些连接,并且进行在出现问题的时候重建连接,以及认证工作。这些工作都是在内核中进行的。

Mon 客户端初始化
入口函数: ceph_monc_init()
该函数首先通过挂载时提供的IP地址构建一个临时的monmap(build_initial_monmap()) ,这个操作发生在客户端与Monitor建立新连接的时候。之后,其初始化认证数据结构,进一步准备如下消息以完成连接后的初步握手:
- CEPH_MSG_MON_SUBSCRIBE (msg Id: 15)
- CEPH_MSG_MON_SUBSCRIBE_ACK (msg Id: 16)
- CEPH_MSG_AUTH (msg Id: 17)
- CEPH_MSG_AUTH_REPLY (msg Id: 18)
连接初始化
入口函数: ceph_con_init()
这时,调用ceph_con_init() (在net/ceph/messenger.c中) 函数完成与Monitor连接的初始化,并且通过一个状态机转换连接。ceph_con_init() 初始化套接字,发起一个工作队列函数,该函数通过异步的方式实现连接的设置。

ceph_con_workfn() 函数通过如下套接字状态(ceph_connection -> sock_state)遍历连接,并将其转换为ESTABLISHED状态。
/*
* Socket state - transitions (connection state is different from socket state)
* --------
* | NEW* | transient initial state
* --------
* | con_sock_state_init()
* v
* ----------
* | CLOSED | initialized, but no socket (and no
* ---------- TCP connection)
* ^
* | con_sock_state_connecting()
* | ----------------------
* |
* + con_sock_state_closed()
* |+---------------------------
* |
* | -----------
* | | CLOSING | socket event;
* | ----------- await close
* | ^ |
* | | |
* | + con_sock_state_closing() |
* | / | |
* | / --------------- | |
* | / v v
* | / --------------
* | / -----------------| CONNECTING | socket created,
* | | / -------------- TCP connect
* | | | initiated
* | | | con_sock_state_connected()
* | | v
* -------------
* | CONNECTED | TCP connection established
* -------------
*
* State values for ceph_connection->sock_state; NEW is assumed to be 0.
*/
/*
* Connection state - transitions
* --------
* | CLOSED |<----<-----------------<-----------<-
* -------- | | |
* | | On failures | |
* v | | |
* -------- | | |
* ---->| PREOPEN |---- | |
* | -------- ^ ^
* | | ceph_tcp_connect() | |
* | v | |
* ^ ------------- | |
* | | CONNECTING |----------------------- |
* | ------------- |
* | | Read and process banner ("ceph v027"), |
* | | prepare capabilities to send to peer |
* | | |
* | v |
* | -------------- |
* | | NEGOTIATING |----------------------------------
* | --------------
* ------- | Read connect_reply, auth capabilites
* |STANDBY| | from peer
* ------- |
* | v
* | -----
* <----- |OPEN |--------------------------------------->
* ----- (Complete final handshake ack)
*
Connection Callback Registrations
下面是在include/linux/ceph/messenger.h中定义的数据结构,这个数据结构定义了在Monitor连接中处理连接事件的回调函数(包括连接到OSD的连接):


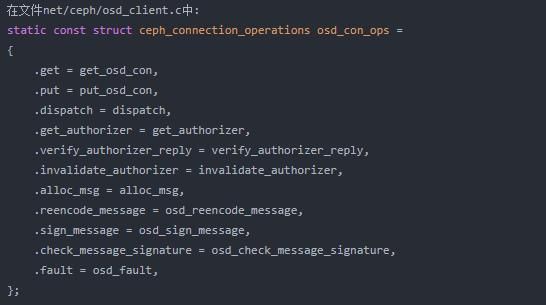
一旦客户端完成连接,它将收到如下内容:
- Mon map (ceph_monc_handle_map() 在 net/ceph/mon_client.c)
- Osd map (ceph_osdc_handle_map() 在 net/ceph/osd_client.c)
如果Ceph客户端的配置文件中包含集群中所有Monitor的信息,客户端将与所有的Monitor建立连接。但是,如果在你的集群中有5个Monitor,但是配置文件中只有一个Monitor。这时,客户端与配置文件中的这个Monitor建立连接。如果与Monitor的连接中断,客户端将随机选取一个Monitor建立连接(客户端通过其接收的monmap获得所有Monitor的列表)。
当Monitor连接触发创建OSD客户端数据结构和连接的时候,客户端会收到OSD map的信息。
krbd在内核的源码目录
源文件:
- drivers/block/rbd.c
- drivers/block/rbd_types.h
- net/ceph/
头文件:
- include/linux/ceph
包装
本文深入介绍了Ceph客户端krbd,并且介绍了其在内核中的实现。同时,还介绍了在内核中实现的客户端的各种功能的入口函数。
总结(译者注)
本文介绍了Ceph客户端块存储部分的初始化和实现的部分细节。Ceph在内核中还有另外一部分,这部分就是大名鼎鼎的Ceph文件系统。这部分内容比较复杂,后面译者将另外写一篇文章进行介绍。
另外,这里需要补充的是,在Linux内核中Ceph的内容主要涉及3个方面,一个是krbd的实现(在 drivers/block/rbd.c中),也就是块设备的实现;第二个是Ceph文件系统(在 fs/ceph目录中)的实现,这里类似与NFS,它通过网络的方式实现对Ceph集群分布式文件系统的访问;第三个是网络部分(在 net/ceph目录中),这部分是公用的,块设备和文件系统都用到了该部分的内容。