用谷歌的GPU跑你的代码----Colaboratory使用记录
1.1新建

1.2运行模式改为GPU
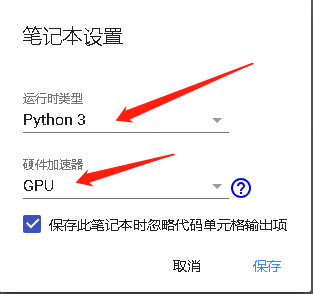
1.3代码执行
直接在代码单元格里写代码就行,然后点击左边的运行标志,代码就开始执行。
import tensorflow as tf
import numpy as np
with tf.Session():
input1 = tf.constant(1.0, shape=[2, 3])
input2 = tf.constant(np.reshape(np.arange(1.0, 7.0, dtype=np.float32), (2, 3)))
output = tf.add(input1, input2)
result = output.eval()
result执行结果

二、上传、下载数据
由于我们每次打开 Colaboratory都是Google 随机给我们分配一台服务器,所以我们每次的数据都不能保存,所以我们需要掌握如何上传数据和下载数据
2.1上传数据
2.1.1网络上数据集
由于 Colaboratory其实本质上是linux服务器,我们可以通过linux命令来下载数据。但由于在 Colaboratory上,所以我们需要注意 Colaboratory不能直接执行linux命令,我们可以通过在命令前面加上!来执行命令(大部分linux命令在前面加上“!”都能实现),比如我们下载Stanford Dogs数据集,可以通过下面命令:
!wget http://vision.stanford.edu/aditya86/ImageNetDogs/images.tar执行效果如下:

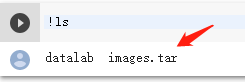
可以看到文件下载下来啦,我下载下来的是压缩包,利用linux命令来解压就行,只要在命令前加上英文的感叹号就可以执行。
2.1.2本地上传数据
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
files.upload返回上传文件的字典。字典是由文件名键入的,值是上传的数据。
这段代码我没有试过,我也是在无意中看见的,应该可以执行
2.2下载数据
当你的代码执行完成,你需要将你运行后保存的文件(假设你有保存文件),可以通过以下代码来下载数据。
from google.colab import files
with open('123.txt', 'w') as f:
f.write('some content')
files.download('123.txt')由于每次都是Google随机给你分配的服务器,所以你每次的数据都无法保存,如果可以的话,你还是把需要的数据及时下载下来。
三、其他
还有一些其他的命令和ipython上可以执行,也可以在Colaboratory执行,下面是我的一些总结
%cd directory 更改工作目录
%pwd 返回系统当前工作目录
%env 以字典形式返回系统环境变量以上是我目前所用到的Colaboratory相关的知识,后序我将继续更新我的其他学习知识。
注:Colaboratory是在谷歌云盘上的,需要出去才能使用,所以你需要才能使用Colaboratory。如果你有能,那你可以尽情的使用谷歌的GPU,如果你没有的技术,那我只能说这种事你可以花点钱吗,花点。