【Tensorflow2.0】2、tensorflow2.0更新内容
文章目录
- 1、主要特征和提升
- 重点
- 突破性改变
- 2、 tensorflow2.0的十大重要更新
- 2.1 默认支持eager方式
- 2.2 tf.function 和 AutoGraph
- 2.3 不再有tf.variable_scope
- 2.4 更加容易自定义网络结构
- 2.5 更灵活的模型训练
- 2.6 tensorflow datasets
- 2.7 自动精度混合 mixed precision
- 2.8 分布式训练
- 2.9 jupyter notebook中显示tensorboard
- 2.10 Tensorflow for swift
总述一下tensorflow2.0: easier for beginners and more powerful for experts,所以还是有点厉害的。
Tensorflow2.0RC0版本发布有二十多天,这个版本应该与正式版本有很多的相同之处,作为一个从Tensorflow1.0便开始用的tensorflow boy,在学习新的版本之前,先了解一下tensorflow2.0的更新之处。
tensorflow2.0的改进有两个方向变的更加more pythonic 和 easy use ,它的eager模式使得和pytorch有些相似,流程更加清淅,api更加简单,构建整个算法pipeline(data,model,deployment)更加方便。
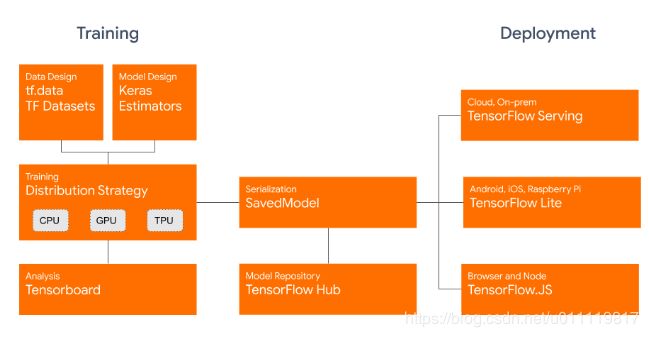
1、主要特征和提升
tensorflow2.0关注简洁和易用,有以下更新:
- 使用eager和keras,构建模型更简捷
- 模型更稳健,可在所有平台部署到产品
- 功能强大,可用于研究
- API简捷单一,去掉重复和无用的部分
重点
- Tensorflow2.0把keras作为核心的高级api,用keras构建和训练深度学习模型。keras提供了几个构建模型的api,比如序列式(sequential)、函数式(functional)和配合eager使用的子类式(subclassing),可以实现立即完成迭代输出结果并进行调试;另外提供了tf.data,来构建更加方便高效的数据读取方式。更多细节参看https://www.tensorflow.org/beta/
- Tensorflow2.0的分布式策略:通过使用tf.distribute.Strategy 的api使分布式训练修改代码最少,便捷使用。该策略支持keras中model.fit或者自定义的模型迭代训练。当前支持单机多卡,多机多卡将来也会支持。
- 不再使用tf.Session,将使用tf.function。tensorflow1.x通过先构建静态图,然后通过tf.Session来执行。tensorflow2.0则将使用正常的python编程方式,tf.function做为装饰器来使用,可以将函数转换成图,帮助优化和序列化。
- 统一tf.train.Optimizers和tf.keras.Optimizers。在tf2.0中将统一使用tf.keras.Optimizers。另外,将使用GradientTape来取代compute_gradient计算梯度。
- AutoGraph的使用。可以将python的流程控制代码转换成tensorflow格式,可以在tf.function中直接使用python完成。AutoGraph还应用到了tf.data,tf.kears,tf.distribute的函数中。
- 统一Tensorflow生态体系所有保存模型的格式为SavedModel。生态包括tensorflow lite,tensorflow js,tensorflow serving,tensorflow hub 。
- api的改变:许多api改名,参数也改变,变提一致有效
- api的移除:tf.app,tf.flags这一些
突破性改变
- 对向后不兼容的api进行了整合,变得有一致性。
- tf.contrib中的内容被加到tensorflow 核心代码中,或者tensorflow/addson和 tensorflow/io中,其余的则全部舍弃。
2、 tensorflow2.0的十大重要更新
学习了解这十大更新并尝试实现它们。tensorflow2.0的发布,将会对深度学习届的研究人员、开发人员产生较大影响,能够更加便捷使用先进的深度学习,推动深度学习发展。
读本文之前,要有一些Tensorflow和keras的基础知识,可以看下面两份材料:
- tesorflow初学者教程
- keras简易教程
有些内容需要用到数据集,这里将使用Adult dataset
import pandas as pd
columns = ["Age", "WorkClass", "fnlwgt", "Education", "EducationNum",
"MaritalStatus", "Occupation", "Relationship", "Race", "Gender",
"CapitalGain", "CapitalLoss", "HoursPerWeek", "NativeCountry", "Income"]
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data',
header=None,
names=columns)
data.head()
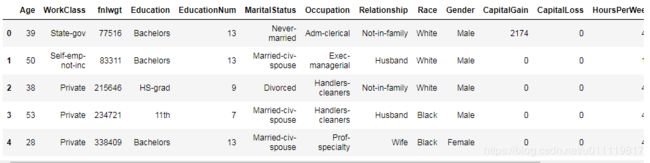
这个数据集是用来做二分类的,判断一个人的年收入是否超过5万美元。
做一些基本的数据预处理,并把数据4:1分成二份
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import numpy as np
#label Encode
le = LabelEncoder()
data=data.apply(le.fit_transform)
#分离数据特征并转换成numpy arrays
X = data.iloc[:,0:-1].values
y= data['Income'].values
#4:1分开
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=7)
2.1 默认支持eager方式
tensorflow2.0中不用再用session,也不用再定义图。eager execution,而是直接像numpy那样来使用。
#tensorflow2.0
model.fit(X_train,y_train,validation_data=(X_valid,y_valid),epochs=12,batch_size=256,callbacks=[es_cb])
#tensorflow1.10及以后,加入keras
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.table_initializer())
model.fit(X_train,y_train,validation_data=(X_valid,y_valid),epochs=12,batch_size=256,callbacks=[es_cb])
2.2 tf.function 和 AutoGraph
eager executin可以使我们实现命令行方式编程,简单快速,但是在分布式训练和部署时,tensorflow1.x的图方式更有优势。tensorflow2.0同样保持了这个优点,可以通过tf.function和autograph来实现。
tf.function可以使python编程方式内容通过autograph功能来实现静态图的功能,目前支持if-else,for loop,while loop,迭代器等。但还有一些限制.tf.function将作为decorator装饰器来起作用。
import tensorflow as tf
import time
#定义前向运算,加tf.function
@tf.function
def single_layer1(x,y):
return tf.nn.relu(tf.matmul(x,y))
#定义前向,不加tf.fucntion
def single_layer2(x,y):
return tf.nn.relu(tf.matmul(x,y))
#生成随机数
x = tf.random.uniform((2,3))
y = tf.random.uniform((3,5))
start1= time.time()
single_layer1(x,y)
duration1 = time.time()-start1
start2= time.time()
single_layer2(x,y)
duration2 = time.time()-start2
print("tf.function:",duration1)
print("no tf.function:",duration2)
对这种情况,加tf.function并没有特别效果,需要做另外专用的配置,这里不再叙述。
2.3 不再有tf.variable_scope
tensorflow1.x中tf.variable_scope使同一个scope中的变量容易收集起来,并复用。tensorflow2.0中不再需要,使用keras后所有变量的控制和获取变得简单。
#定义模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dropout(rate=0.2,input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(units=64,activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=64,activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(units=1,activation='sigmoid')
])
out_probs = model(X_train.astype(np.float32), training=True)
print(out_probs)
#以上代码输出数据的原始输入,只是一次前向运算。training=True只是用来控制dropout。
#也可以进行训练
model.compile(optimizer='adam',loss = 'binary_crossentropy',metrics=['accuracy'])
model.fit(X_train,y_train,validation_data=(X_test,y_test),epochs=5,batch_size=64)

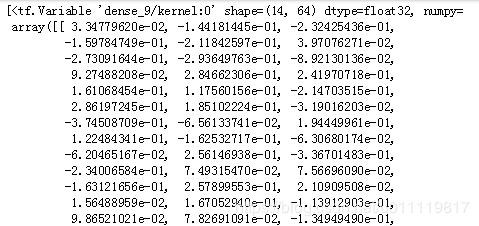
#可以获得模型的可训练参数
model.trainable_variables # 与model.trainable_weights相同
2.4 更加容易自定义网络结构
研究人员或企业人员,会根据需求自定义一些模型结构。Tensorflow2.0会支持更便捷基于现有层来自定义。自定义需要用到Layer这个类,
tf.keras.layers.Layer基于这个类来按需定义。先自定义一个层,然后再使用这个层来自定义一个模型来做前向运算。
#查看tf.keras.Layer功能
help(tf.keras.Layer)
#部分输出,指出我们需要实现Layer中的那些内容
We recommend that descendants of `Layer` implement the following methods:
|
| * `__init__()`: Save configuration in member variables
| * `build()`: Called once from `__call__`, when we know the shapes of inputs
| and `dtype`. Should have the calls to `add_weight()`, and then
| call the super's `build()` (which sets `self.built = True`, which is
| nice in case the user wants to call `build()` manually before the
| first `__call__`).
| * `call()`: Called in `__call__` after making sure `build()` has been called
| once. Should actually perform the logic of applying the layer to the
| input tensors (which should be passed in as the first argument).
可以看出,我们需要做如下定义:
- 定义层输出个数
- 在
build()方法中填加变量参数 - 在
call()方法中实现前向运算环节
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self,num_units=None):
super().__init__()
self.units=num_units
def build(self,input_shape):
self.kernel = self.add_weight("kernel",shape=[input_shape[-1],self.units])#input_shape这个参数名随便起
self.bias = self.add_variable("bias",shape=[self.units,])#可以看来add_weight和add_variable是一样的
#定义前向运算
def call(self,inputs):
return tf.nn.relu(tf.matmul(inputs,self.kernel)+self.bias)
#初始化layer
layer = MyDenseLayer(10)
#输入数据
output = layer(tf.random.uniform((10,3)))
print(output)
#显示变量
print(layer.variables)#layer.weights也是一样的

通过层的堆叠,可以实现model。
2.5 更灵活的模型训练
tensorflow2.0支持自动微分,可以自动求损失对模型参数的梯度。tf.GradientTape 提供对变量梯度的记录。
tf.keras.backend.clear_session()
class CustomModel(tf.keras.models.Model):
def __init__(self):
super().__init__()
self.do1 = tf.keras.layers.Dropout(rate=0.2,input_shape=(14,))
self.fc1= tf.keras.layers.Dense(units=64,activation='relu')
self.do2 = tf.keras.layers.Dropout(rate=0.2)
self.fc2 = tf.keras.layers.Dense(units=64,activation='relu')
self.do3 = tf.keras.layers.Dropout(rate=0.2)
self.out = tf.keras.layers.Dense(units=1,activation='sigmoid')
def call(self,inputs):
x = self.do1(inputs)
x = self.fc1(x)
x = self.do2(x)
x = self.fc2(x)
x = self.do3(x)
return self.out(x)
model = CustomModel()
如上代码,与我们之前定义的模型是一模一样的,要训练这个模型,需要定义优化和损失函数
loss_func = tf.keras.losses.BinaryCrossentropy(from_logits=True)#from_logits=True写不写都行,默认是认为y_pred是概率,但写了可能会更稳定(这是说明文档中的原话)
optimizer = tf.keras.optimizers.Adam()
还需要定义评价指标来评估模型训练过程中的性能。
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_acc = tf.keras.metrics.BinaryAccuracy(name='train_acc')
test_loss = tf.keras.metrics.Mean(name='valid_loss')
test_acc = tf.keras.metrics.BinaryAccuracy(name='valid_acc')
tf.data提供了通用的数据读取方法,特别是数据量大的时候。
X_train,y_train = X_train.astype(np.float32),y_train.astype(np.int32)
X_test,y_test = X_test.astype(np.float32),y_test.astype(np.int32)
y_train,y_test = y_train.reshape(-1,1),y_test.reshape(-1,1)
#batch size =64
train_ds = tf.data.Dataset.from_tensor_slices((X_train,y_train)).batch(64)
test_ds = tf.data.Dataset.from_tensor_slices((X_test,y_test)).batch(64)
接着就可以基于tf.GradientTape来训练模型。
#训练模型
@tf.function
def train_on_batch(features,labels):
#定义GradientTape
with tf.GradientTape() as tape:
#前向运算
logits = model(features)
#求损失
loss = loss_func(labels,logits)#交换顺序也没关系
#计算梯度
gradients = tape.gradient(loss,model.trainable_variables)
optimizer.apply_gradients(zip(gradients,model.trainable_variables))
train_loss.update_state(loss)
train_acc.update_state(labels,logits)#这两个写不写updata_state都可以,以后默认就不写了,省事
#测试模型
@tf.function
def test_on_batch(features,labels):
logits = model(features)
t_loss = loss_func(labels,logits)
test_loss(t_loss)
test_acc(labels,logits)
#用上边两个函数完成5个epoch训练
start = time.time()
for epoch in range(5):
for i,(features,labels) in enumerate(train_ds):
train_on_batch(features,labels)
for i,(features,labels) in enumerate(test_ds):
test_on_batch(features,labels)
template='Epoch {}, train_loss: {} ,train_acc:{},test_loss:{},test_acc:{}'
print(template.format(epoch+1,train_loss.result(),train_acc.result()*100,test_loss.result(),test_acc.result()*100))
# Reset the metrics for the next epoch
train_loss.reset_states()
train_acc.reset_states()
test_loss.reset_states()
test_acc.reset_states()
duration=time.time()-start
print("total time:",duration)
可以将tf.function去掉做对比,看看训练时间的差异,可以得到eager模式与图模式的区别。
有tf.function的情况下:

无tf.function的情况下:

#另外数据如果加prefetch会加快训练
train_ds = tf.data.Dataset.from_tensor_slices((X_train,y_train)).batch(64).prefetch(128)
test_ds = tf.data.Dataset.from_tensor_slices((X_test,y_test)).batch(64).prefetch(128)
有tf.function时候,加prefetch(都是多次测量的结果)

无tf.function时候,加prefetch,感觉提升不是很多,可能是因为数据小,模型简单的原因。

2.6 tensorflow datasets
一个单独的模块叫做DataSets,提供数据集的准备工作,可以通过pip来安装。
可以从以下两个地方学习了解:
- https://www.youtube.com/watch?v=-nTe44WT0ZI
- https://github.com/tensorflow/datasets
如下,mnist的准备流程:
```python
import tensorflow_datasets as tfds
# You can fetch the DatasetBuilder class by string
mnist_builder = tfds.builder("mnist")
# Download the dataset
mnist_builder.download_and_prepare()
# Construct a tf.data.Dataset: train and test
ds_train, ds_test = mnist_builder.as_dataset(split=[tfds.Split.TRAIN, tfds.Split.TEST])
# Prepare batches of 128 from the training set
ds_train = ds_train.batch(128)
# Load in the dataset in the simplest way possible
for features in ds_train:
image, label = features["image"], features["label"]
import matplotlib.pyplot as plt
%matplotlib inline
# You can convert a TensorFlow tensor just by using
# .numpy()
plt.imshow(image[0].numpy().reshape(28, 28), cmap=plt.cm.binary)
plt.show()
2.7 自动精度混合 mixed precision
技术由英伟达提供,效果不错,详细参见算法原文。会利用fp16和fp32的优势。使用英伟达的显卡时,可以安装tensorflow2.0gpu版本来运行。
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
这个操作会自动使tensorflow的operations进行改变。会看到模型性能的提升。也可以自己优化tensorflow core operations.具体参看文档
2.8 分布式训练
tensorflow2.0提供更简单的分布式训练方法,单机多卡,多机多卡,都会易用。
首先指定分布式训练的策略:
mirrored_strategy = tf.distribute.MirroredStrategy()
#该策略使所有gpu有同的模型结构和参数
#如下开始使用
with mirrored_strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Dense(1,input_shape=(1,))
])
model.compile(optimizer='sgd',loss='mse')
model.fit(X_train,y_train,validation_data(X_test,y_test),batch_size=128,epochs=10)
以上内容只对单机多卡有用,多机多卡参见:文档
2.9 jupyter notebook中显示tensorboard
使用tensorboard可以在jupyter notebook中直接查看训练情况.新的tensorboard可以看memory profiling,confuse matrix,
可以查看文档.
#jupyter notebook中执行
%load_ext tensorboard.notebook
######################
from datetime import datetime
import os
# Make a directory to keep the training logs
os.mkdir("logs")
# Set the callback
logdir = "logs"
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)
# Define the model
model = tf.keras.Sequential([
tf.keras.layers.Dropout(rate=0.2, input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
# The TensorBoard extension
%tensorboard --logdir logs/
# Pass the TensorBoard callback you defined
model.fit(X_train, y_train,
validation_data=(X_test, y_test),
batch_size=64,
epochs=10,
callbacks=[tensorboard_callback],
verbose=False)
2.10 Tensorflow for swift
由于python比较慢,所以tensorflow团队开发了一个swift版本的,可以看一下官方文档.