内存_Highmemory
linux高端内存映射
从0x00000000 到 0xbfffffff的线性地址,无论用户态还是内核态的进程都可以寻址。
从0xc0000000 到 0xffffffff的线性地址,只有内核态的进程才能寻址。
当进程运行在用户态时,它产生的线性地址小于0xc0000000;当进程运行在内核态时,它执行内核代码,所产生的线性地址大于等于 0xc0000000、且所有进程共享。如果是多核CPU,那么就会出现多个进程并发访问这些地址的现象,这里就要牵扯到临界区资源,也就是我们将来在介 绍同步与互斥内容中要重点讨论的。宏PAGE_OFFSET产生的值就是0xc0000000,这就是进程在线性地址空间中的偏移量,也是内核生存空间的 开始之处。
页全局目录被分成了两部分,的第一部分表项映射的线性地址小于0xc0000000(共1024项,在PAE未启用时是前768项,PAE启动时是前3项),具体大小依赖特定进程。相反,剩余的表项对所有进程来说都应该是相同的,它们等于主内核页全局目录的相应表项。那么,什么又是主内核页全局目录呢?内核维持着一组自己使用的页表,驻留在所谓主内核页全局目录(master kernel Page Global Directory)中。系统初始化后,这组页表还从未被任何进程或任何内核线程直接使用,主要用来为系统中每个普通进程对应的页全局目录项提供参考模 型。内核如何初始化自己的页表?这个过程分为两个阶段。事实上,内核映像刚刚被装入内存后,CPU仍然运行于实模式,所以分页功能没有被启用。
第一个阶段,内核创建一个有限的地址空间,包括内核的代码段和数据段、初始页表和用于存放动态数据结构的共128KB大小的空间。这个最小限度的地址空间仅足够将内核装入RAM和对其初始化的核心数据结构。
第二个阶段,内核充分利用剩余的RAM并适当地建立分页表。
1.1 内核页表的初始化
Linux为什么要建立一个内核页表呢?Linux建立内核页表的目的有二,第一是对内核的数据结构进行动态的管理,例如将内核态进程暂时不使用的数据结构交换出去;第二是为进程的页表提供一个参考,后面的博文里还将详细讨论。
在系统初始化时,首先要建立一个最原始的页表,即内核临时页表。指向这个页表的临时页全局目录是在内核编译过程中静态地初始化的,而临时页表是由startup_32( )汇编语言函数(定义于arch/i386/kernel/head.S)初始化的。
内核编译后,临时页全局目录地址存放在swapper_pg_dir变量中。临时页表在pg0变量处开始存放,紧接在内核未初始化的数据段(这里不 清楚的兄弟可以查查内存布局那一篇博文)后面。建立内核临时页表的目的就是为了初始化内核阶段提供一个映射机制。一般来说,初始化阶段内核使用的段、临时 页表和128KB的内存范围能容纳于RAM前8MB空间里。那么为了映射RAM前8MB的空间,我们只需要用到两个页表,因为一个页表有1024个下 标,2*1024*4K就正好是8MB。分页第一个阶段的目标是允许在实模式下和保护模式下都能很容易地对这8MB寻址,目的在于做一个由实模式向保护模式的转换 。因此,内核必须创建一个映射,把从0x00000000到 0x007fffff的线性地址和从0xc0000000 到0xc07fffff的线性地址映射到从0x00000000 到 0x007fffff的物理地址。看晕了吧?那我们换个说法:内核在初始化的第一阶段,可以通过与物理地址相同的线性地址或者通过从0xc0000000 开始的8MB线性地址对物理RAM的前8MB进行寻址。还晕?那没辙了,画个图再反复将上面的文字琢磨琢磨吧。
内核通过把swapper_pg_dir所有项都填充为0来创建期望的映射(1024项),不过,0、1、0x300(十进制的第768项)和 0x301(十进制的第769项)这四项除外;后两项包含了从0xc0000000到0xc07fffff 间的,也就是从0xc0000000开始的8MB所有线性地址。0、1、0x300和0x301按以下方式初始化:
? 0项和0x300项的地址字段置为pg0的物理地址,而1项和0x301项的地址字段置为紧随pg0后的页框的物理地址。
? 把这四个项中的Present,、Read/Write和 User/Supervisor标志置位。
? 把这四个项中的Accessed 、Dirty、PCD、PWD和Page Size标志清0。
当建立好临时内核页表后,我们就得马上使用这个映射了,因为初始化期间,你得进入保护模式来初始化内核的各个数据结构啊,怎么使用呢?是初始化期间 由汇编语言函数startup_32()来启用分页单元的:通过向cr3控制寄存器装入swapper_pg_dir的地址及设置cr0控制寄存器的PG 标志来达到这一目的。下面是等价的代码片段:
movl $swapper_pg_dir-0xc0000000,%eax
movl %eax,%cr3 /*设置页表指针…*/…
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /*……设置分页(PG)位*/
建立好临时内核页表后,我们终于可以离开实模式了,之后的故事就是利用80x86体系CPU的保护模式实现内核及各个进程的虚拟化存储管理。不过, 这个内核临时页表只有8MB的映射,只是用来对初始化阶段的内核来进行寻址,还不能满足对整个内存管理的要求。那么我们进行第二步,建立内核最终页表。在 32位80X86体系中,内核最终页表的建立要根据RAM的实际大小来进行:
1.2 RAM小于896MB时的最终内核页表
由内核页表所提供的最终映射必须把从0xc0000000开始的线性地址转化为从0开始的物理地址。宏__pa用于把从PAGE_OFFSET开始 的线性地址转换成相应的物理地址,而宏__va做相反的转化。主内核页全局目录仍然保存在swapper_pg_dir变量中。它由 paging_init() 函数初始化。该函数进行如下操作:
1. 调用pagetable_init()适当地建立页表项。
2. 把swapper_pg_dir的物理地址写入cr3控制寄存器中。
3. 如果CPU支持PAE并且如果内核编译时支持PAE,将cr4控制寄存器的PAE标志置位。
4. 调用flush_tlb_all()使TLB的所有项无效。
1.3 当RAM大小在896MB和4096MB之间时的最终内核页表
在这种情况下,并不把RAM全部映射到内核地址空间。Linux在初始化阶段只是把一个具有896MB的RAM映射到内核线性地址空间。如果一个程 序需要对现有RAM的其余部分寻址,那就必须把某些其他的线性地址间隔映射到所需的RAM,做法就是修改某些页表项的值。内核使用与前一种情况相同的代码 来初始化页全局目录。
1.4 当RAM大于4096MB时的最终内核页表
现代计算机,特别是些高性能的服务器内存远远超过4GB,那么内核页表初始化怎么做呢;更确切地说,我们处理以下发生的情况:
? CPU模式支持物理地址扩展(PAE)
? RAM容量大于4GB
? 内核以PAE支持来编译
尽管PAE处理36位物理地址,但是线性地址依然是32位地址。如前所述,Linux映射一个896MB的RAM到内核地址空间;剩余RAM留着不 映射,并由动态重映射来处理。与前一种情况的主要差异是使用三级分页模型。其实,即使我们的CPU支持PAE,但是也只能有寻址能力为64GB的内核页 表,所以,如果要建立更高性能的服务器,建议改善动态重映射算法,或者干脆升级为64位的处理器。
2 固定映射的线性地址
我们看到内核线性地址第四个GB的前896MB部分映射系统的物理内存。但是,至少128MB的线性地址总是留作他用,因为内核使用这些线性地址实现非连续内存分配 和固定映射的线性地址。非连续内存分配仅仅是动态分配和释放内存页的一种特殊方式,将在以后博文描述。本节我们集中讨论固定映射的线性地址。Linux内核中提供了一段虚拟地址用于固定映射,也就是fixed map。固定映射的线性地址(fix-mapped linear address)是一个固定的线性地地址,它所对应的物理地址不是通过简单的线性转换得到的,而是人为强制指定的。每个固定的线性地址都映射到一块物理内存页。固定映射线性地址能够映射到任何一页物理内存。固定映射线性地址是从整个线性地址空间的最后4KB即线性地址0xfffff000向低地址进行分配的。在最后4KB空间与固定映射线性地址空间的顶端空留一页(未知原因),固定映射线性地址空间前面的地址空间叫做vmalloc分配的区域,他们之间也空有一页。固定映射的线性地址基本上是一种类似于0xffffc000这样的常量线性地址,其对应的物理地址不必等于线性地址减去0xc000000,而是通过页表以任意方式建立。因此,每个固定映射的线性地址都映射一个物理内存的页框。
每个固定映射的线性地址都由定义于enum fixed_addresses枚举数据结构中的整型索引来表示:
enum fixed_addresses {
FIX_HOLE,
FIX_VSYSCALL,
FIX_APIC_BASE,
FIX_IO_APIC_BASE_0,
...
__end_of_fixed_addresses
};
每个固定映射的线性地址都存放在线性地址第四个GB的末端。fix_to_virt( )函数计算从给定索引开始的常量线性地址:
inline unsigned long fix_to_virt(const unsigned int idx)
{
if (idx >= _ _end_of_fixed_addresses)
__this_fixmap_does_not_exist( );
return (0xfffff000UL (idx << PAGE_SHIFT));
}
例如:让我们假定某个内核函数调用fix_to_virt(FIX_IOAPIC_BASE_0)。因为该函数声明为“inline”,所以C编译程序不调用fix_to_virt( ),而是仅仅把它的代码插入到调用函数中。此外,运行时从不对这个索引值执行检查。根据枚举的概念,FIX_IOAPIC_BASE_0是个等于3的常量,因此编译程序可以去掉if语句,因为它的条件在编译时为假。相反,如果条件 为真,或者fix_to_virt( )的参数不是一个常量,则编译程序在连接阶段产生一个错误,因为符号__this_fixmap_does_not_exist 在别处没有定义。最后, 编译程序计算0xfffff000(3< 我们在前面分析过了,在linux内存管理中,内核使用3G-4G的线性地址空间,总共1G的大小。其中80x86中,内核页表的896M大小的线性地址与物理地址一一对应,而剩余128MB的线性地址留作他用(实现非连续内存分配 和固定映射的线性地址 )。通常,我们把物理地址 超过896M的区域称为高端内存。内核怎样去管理高端内存呢?今天就来分析这个问题。内核有三种方式管理高端内存。第一种是非连续映射。这里我们只简单提一下,在vmalloc中请求页面的时候,如果请求的是高端内存,则映射到VMALLOC_START与VMALLOC_END之间。第二种方式是永久内核映射。最后一种方式叫临时内核映射。接下来,详细的分析一下第二种和第三种方式。 内核中有一个全局变量,叫做high_memory,它被设置为0x38000000,也就是896MB。896MB边界以上的空间(未启动PAE 的32位80x86的地址范围3GB+128MB)并不映射在内核线性地址空间的第4个GB,因此,内核不能直接访问它们。这就意味着,返回所分配页框线 性地址的页分配函数,即__get_free_pages(GFP_HIGHMEM, 0)类似的函数,不适用于高端内存,即不适用于ZONE_HIGHMEM内存管理区中的页。 高端内存页框的分配只能通过alloc_pages()函数和它的快捷函数alloc_page()。这些函数不返回第一个被分配页框的线性地址, 因为如果该页框属于高端内存,那么这样的线性地址根本不存在。取而代之的是:这些函数返回第一个被分配页框的页描述符的线性地址。这些线性地址总是存在 的,因为所有页描述符一旦被分配,则必在低端内存中。它们在内核初始化阶段就以被分配,且始终不会改变。 别高兴,虽然可以利用alloc_pages()函数在高端区分配一个页,但是这个页没有线性地址,不能被内核访问。因此,内核线性地址空间最后 128MB中的一部分专门用于映射高端内存页框。当然,这种映射是暂时的,否则只有128MB的高端内存可以被访问。取而代之的是:通过重复使用线性地 址,使得整个高端内存能够在不同的时间被访问。 永久内核映射允许内核建立高端页框到内核地址空间的长期映射。它们只使用主内核页表中一个专门的页表(注意,只有一个页表) ,其地址存放在pkmap_page_table变量中。页表中的表项数由LAST_PKMAP宏产生。页表照样包含512或1024项,这取决于PAE 是否被激活;因此内核一次最多只能访问2MB或4MB固定内存映射的高端内存。也就是说,这个空间是 4M 或 2M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。该页表映射的线性地址从PKMAP_BASE(注意,这些都是一些宏)开始。pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table 页表中的每一项都有一个。我们区分以下三种情况: 计数器为0:对应的页表项没有映射任何高端内存页框,并且是可用的。 计数器为1:对应的页表项没有映射任何高端内存页框,但是它不能使用,因为自从它最后一次使用以来,其相应的TLB表现还未被刷新。 计数器为n(远大于1):相应的页表项映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。 为了记录高端内存页框与永久内核映射包含的线性地址之间的联系,内核使用了page_address_htable散列表。该表包含一个 page_address_map数据结构,用于为高端内存中的每一个页框进行当前映射。而该数据结构还包含一个指向页描述符的指针和分配给该页框的线性 地址。 page_address()函数返回页框对应的线性地址,如果页框在高端内存中并且没有被映射,则返回NULL。这个函数接受一个页描述符指针page作为其参数,并区分以下两种情况: 1.如果页框不在高端内存中(PG_highmem标志为0),则线性地址总是存在并且是通过计算页框下标,然后将其转换成物理地址,最后根据相应的物理 地址得到线性地址。这是由下面的代码完成的:__va((unsigned long)(page - mem_map) << 12) kmap()函数建立永久内核映射。本质上它等价于下列代码: 如果页框确实属于高端内存,则调用kmap_high()函数。这个函数本质上等价于下列代码: 该函数获取kmap_lock自旋锁,以保护页表免受多处理器系统上的并发访问。接下来,kmap_high()函数检查页框是否已经通过调用 page_address()被映射。如果不是,该函数调用map_new_virtual()函数把页框的物理地址插入到 pkmap_page_table 的一个项中并在page_address_htable散列表中加入一个元素。然后,kmap_high()使页框的线性地址所对应的计数器加1 来将调用该函数的新内核成分考虑在内。最后,kmap_high()释放kmap_lock自旋锁并返回对该页框进行映射的线性地址。 map_new_virtual()函数本质上执行两个嵌套循环: for (;;) { 在内循环中,该函数扫描pkmap_count 中的所有计数器直到找到一个空值。当在pkmap_count中找到了一个未使用的项时,大的if代码块运行。这段代码确定该项对应的线性地址,为它在 pkmap_page_table页表中创建一个项,将count置1,因为该项现在已经被使用了,调用set_page_address()函数插入一 个新元素到page_address_htable散列表中,并返回线性地址。 函数从上次停止的地方开始,穿越pkmap_count 数组执行循环。这是函数通过将pkmap_page_table页表中上次使用过页表项的索引保存在一个名为last_pkmap_nr的变量中做到的。 因此,搜索从上次因调用map_new_virtual()函数而跳出的地方重新开始。 当在pkmap_count中搜索到最后一个计数器时,就又从下标为0 的计数器重新开始搜索。不过,在继续之前,map_new_virtual()调用flush_all_zero_pkmaps()函数来开始寻找计数器 为1 的另一趟扫描。每个值为1的计数器都表示在pkmap_page_table页表中表项是空闲的,但不能使用,因为相应的TLB 表项还没有被刷新。flush_all_zero_pkmaps()把它们的计数器重置为0,删除page_address_htable 散列表中对应的元素,并在pkmap_page_table的所有项上进行TLB 刷新。 如果内循环在pkmap_count中没有找到空的计数器,map_new_virtual()函数就阻塞当前进程,直到某个进程释放了 pkmap_page_table 页表中的一个表项。通过把current 插入到pkmap_map_wait等待队列,把current状态设置为 TASK_UNINTERRUPTIBLE并调用schedule()放弃CPU来达到此目的。一旦进程被唤醒,该函数就通过调用 page_address()检查是否存在另一个进程已经映射了该页;如果还没有其他进程映射该页,则内循环重新开始。 kunmap()函数撤销先前由kmap()建立的永久内核映射。如果页确实在高端内存中,则调用kunmap_high()函数,它本质上等价于下列代码: 中括号内的表达式从页的线性地址计算出pkmap_count数组的索引。计数器被减1 并与1 相比。匹配成功表明没有进程在使用页。该函数最终能唤醒由map_new_virtual()添加在等待队列中的进程(如果有的话)。 好了,我们来总结一下,如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间? 每个CPU都有它自己的包含13个窗口的集合,它们用enum km_type数据结构表示。该数据结构中定义的每个符号,如KM_BOUNCE_READ、KM_USER0 或KM_PTE0,标识了窗口的线性地址。 内核必须确保同一窗口永不会被两个不同的控制路径同时使用。因此,km_type结构中的每个符号只能由一种内核成分使用,并以该成分命名。最后一个符号KM_TYPE_NR 本身并不表示一个线性地址,但由每个CPU 用来产生不同的可用窗口数。 在km_type中的每个符号(除了最后一个)都是固定映射的线性地址的一个下标(见“固定映射的线性地址”博文)。 enum_fixed_addresses 数据结构包含符号FIX_KMAP_BEGIN 和FIX_KMAP_END;把后者赋给下标FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1。在这种方式下,系统中的每个 CPU 都有KM_TYPE_NR个固定映射的线性地址。此外,内核用fix_to_virt(FIX_KMAP_BEGIN)线性地址对应的页表项的地址初始化 kmap_pte变量。 为了建立临时内核映射,内核调用kmap_atomic()函数,它本质上等价于下列代码: current_thread_info( )->preempt_count++; type 参数和CPU 标识符(通过smp_processor_id())指定必须用哪个固定映射的线性地址映射请求页。如果页框不属于高端内存,则该函数返回页框的线性地 址;否则,用页的物理地址及Present、Accessed、Read/Write 和Dirty 位建立该固定映射的线性地址对应的页表项。最后,该函数刷新适当的TLB 项并返回线性地址。 为了撤销临时内核映射,内核使用kunmap_atomic()函数。在80x86 结构中,这个函数减少当前进程的preempt_count;因此,如果在请求临时内核映像之前能抢占内核控制路径,那么在同一个映射被撤销后可以再次抢 占。此外,kunmap_atomic()检查当前进程的TIF_NEED_RESCHED 标志是否被置位,如果是,就调用schedule()。 好了,现在我们来总结一下临时内核映射。前边提到从线性地址4G向前倒数若干的页面有一个空间称为“固定映射空间”,在这个空间中,有一部分用于高端内存的临时映射。 最后我们用网上的一个图来总结今天的博文: 内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。 对应高端内存的3部分,高端内存映射有三种方式: 持久内核映射(permanent kernel mapping) 临时映射(temporary kernel mapping) 这块空间具有如下特点: 当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。896M边界以上的页框并不映射在内核线性地址空间的第4个GB,因此内核不能直接访问它们。所以,返回所分配页框线性地址的页分配器函数并不对高端内存可用。在64位平台上不存在这个问题,因为可以使用的线性地址空间大于能安装的RAM,也就是说这些体系结构的ZONE_HIGHMEM是空的。linux使用如下方法来使用高端内存: 1)高端内存页框的分配只能通过alloc_pages( )函数和它的快捷函数alloc_page( )。这些函数不返回线性地址,而是返回第一分配页框的页描述符的线性地址。 2)没有线性地址的高端内存中的页框不能被内核访问。 内核采用三种不同的机制将页框映射到高端内存:永久内核映射、临时内核映射、非连续内存分配。本节讨论前两种。建立永久内核映射可能阻塞当前进程;也就是高端内存上没有页表项可以用作页框的窗口的时候。因此,这种方法不能用在中断处理函数和可延迟函数。临时内核映射不会阻塞当前进程,但是只有很少的临时内核映射可以建立起来。需要注意的是,无论哪种方法,128M的线性地址用于高端内存映射,无法保证寻址范围同时到达的物理内存。 2.永久内核映射:注意,下列多有函数应用的范围是内核空间 宏定义与关键变量定义: pkmap_page_table:高端内存主内核页表中,一个用于永久内核映射的专用页表锁在的地址 LAST_PKMAP: 上述页表所含有的表项(512或者1024) PKMAP_BASE:该页表所映射线性地址的start地址 pkmap_count:对页表项提供计数器的数组 page_address_htable:散列表,用于记录高端页框与永久内核映射的线性地址之间的关系 page_address_map:一个数据结构,包含指向页描述符的指针和分配给页框的线性地址;用于为高端内存的每个页框提供当前映射,它被包含在page_address_htable这个hansh表中 关键函数: page_address( page):返回页框对应的线性地址 Void * kmap(struct page * page):返回对应page的线性地址 Void * kmap_high(struct page * page): 同上,不过接受的参数是高端内存的页框描述符 map_new_virtual( ):插入页框的物理地址到pkmap_page_table,在page_address_htable散列表中加入一个元素 它是高端页框到内核地址空间的长期映射。使用主内核页表中的一个专门页表,地址存放在pkmap_page_table变量中。页表中的表项数由LAST_PKMAP宏产生。页表照样包含512或者1024项,这取决于PAE是否激活,因此,内核一次访问最多2M或者4M的高端内存。 该页表映射的线性地址从PKMAP_BASE开始,pkmap_count数组包涵LAST_PKMAP个计数器,pkmap_page_table页表中的每一个项都有一个。我们区分下列三种情况 计数器为0:对应页表项没有映射任何的高端内存页框,并且是可用的。 计数器为1:对应的页表项没有映射任何内存页框,但是它不可用,因为从它最后一次使用以来,对应的TLB表项还未被刷新。 计数器为n:相应的页表项映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。当分配项的值等于0时为自由项,等于1时为缓冲项,大于1时为映射项。映射页面的分配基于分配表的扫描,当所有的自由项都用完时,系统将清除所有的缓冲项,如果连缓冲项都用完时,系统将进入等待状态。 为了记录高端内存页框与永久内核映射的线性地址之间的联系,内核使用了page_address_htable散列表。该表包含一个page_address_map数据结构,用于为高端内存的每个页框进行当前映射。而该数据结构还包涵一个指向页描述符号的指针和分配给该页框的线性地址。 对应数据结构关系图如下: page_address()函数返回页框对应的线性地址,如果页框在高端内存中并没有被映射,则返回NULL。这个函数接受一个页描述符指针page作为参数,并区分以下两种情况: 1)页框不在高端内存中: __va( ( unsigned long) (page - meme_map) << 12) 2) 页框在高端内存中,该函数就得到page_address_htable中寻找。如果在散列表中找到页框,page_address()就返回它的线性地址,否则就返回NULL。 代码实现如下: 临时内核映射实现简单,可以用在中断处理程序和可延迟函数的内部(这些函数不能被阻塞),因为临时内核映射从来不阻塞当前进程,因为它被设计成是原子的。对比永久内核映射,发现如果页框暂时没有空闲的虚拟地址可以映射,那么永久内核映射将要被阻塞。建立临时内核映射禁用内核抢占,这是必须的,因为映射对于每个处理器都是独特的,如果没有禁用抢占,那么哪个任务在哪个CPU上运行是不确定的。(这一段需要结合进程管理加以理解)撤销临时内核映射的函数实际上可以不进行任何实质性的操作,它仅仅允许内核抢占即可(这样新的进程被调度,可以直接使用临时内核映射区域,覆盖原来的映射关系)。 每个CPU都有它自己的包含13个窗口的集合,它们用enum km_type数据结构表示。该数据结构定义的每个符号,标识了一个窗口的线性地址。 km_type的每一个符号都是固定映射的线性地址的一个下标。enum fixed_addresses数据结构包含符号FIX——KMAP——BEGIN和FIX_KMP_END;把后者的值赋成下标FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1。在这种方式下,系统中的每个CPU有KM-TYPE-NR个固定映射的线性地址。此外,内核用fix_to _virt(FIX_KMAP_BEGIN )线性地址对应的页表项的地址初始化kmap_pte变量。 3 高端内存内核映射
3.1 永久内存映射
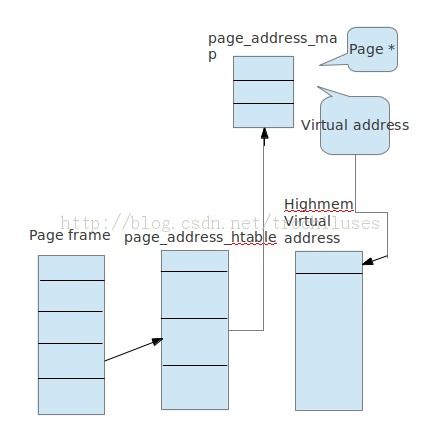
2.如果页框在高端内存(PG_highmem标志为1)中,该函数就到page_address_htable散列表中查找。如果在散列表中找到页框,page_address()就返回它的线性地址,否则返回NULL。
void * kmap(struct page * page)
{
if (!PageHighMem(page))
return page_address(page);
return kmap_high(page);
}
void * kmap_high(struct page * page)
{
unsigned long vaddr;
spin_lock(&kmap_lock);
vaddr = (unsigned long) page_address(page);
if (!vaddr)
vaddr = map_new_virtual(page);
pkmap_count[(vaddr-PKMAP_BASE) >> PAGE_SHIFT]++;
spin_unlock(&kmap_lock);
return (void *) vaddr;
}
int count;
DECLARE_WAITQUEUE(wait, current);
for (count = LAST_PKMAP; count > 0; --count) {
last_pkmap_nr = (last_pkmap_nr + 1) & (LAST_PKMAP - 1);
if (!last_pkmap_nr) {
flush_all_zero_pkmaps( );
count = LAST_PKMAP;
}
if (!pkmap_count[last_pkmap_nr]) {
unsigned long vaddr = PKMAP_BASE +
(last_pkmap_nr << PAGE_SHIFT);
set_pte(&(pkmap_page_table[last_pkmap_nr]),
mk_pte(page, _ _pgprot(0x63)));
pkmap_count[last_pkmap_nr] = 1;
set_page_address(page, (void *) vaddr);
return vaddr;
}
}
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(&pkmap_map_wait, &wait);
spin_unlock(&kmap_lock);
schedule( );
remove_wait_queue(&pkmap_map_wait, &wait);
spin_lock(&kmap_lock);
if (page_address(page))
return (unsigned long) page_address(page);
}
void kunmap_high(struct page * page)
{
spin_lock(&kmap_lock);
if ((--pkmap_count[((unsigned long)page_address(page)
-PKMAP_BASE)>>PAGE_SHIFT]) == 1)
if (waitqueue_active(&pkmap_map_wait))
wake_up(&pkmap_map_wait);
spin_unlock(&kmap_lock);
}
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6 内核上,如果不指定PAE,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫“内核永久映射空间”或者“永久内核映射空间”
这个空间和其它空间使用同样的页全局目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3寄存器指向。
通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。
通过 kmap(), 可以把一个 page 映射到这个空间来
由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。3.2 临时内核映射
临时内核映射比永久内核映射的实现要简单。在高端内存的任一页框都可以通过一个“窗口”(为此而保留的一个页表项)映射到内核地址空间。留给临时内核映射的窗口数是非常少的。
void * kmap_atomic(struct page * page, enum km_type type)
{
enum fixed_addresses idx;
unsigned long vaddr;
if (!PageHighMem(page))
return page_address(page);
idx = type + KM_TYPE_NR * smp_processor_id( );
vaddr = fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, 0x063));
_ _flush_tlb_single(vaddr);
return (void *) vaddr;
}
这块空间具有如下特点:
1、每个 CPU 占用一块空间
2、在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。
通过 kmap_atomic() 可实现临时映射。
linux 高端内存页框治理:永久内核映射、临时内核映射以及非连续内存分配
1.高端内存的区域划分
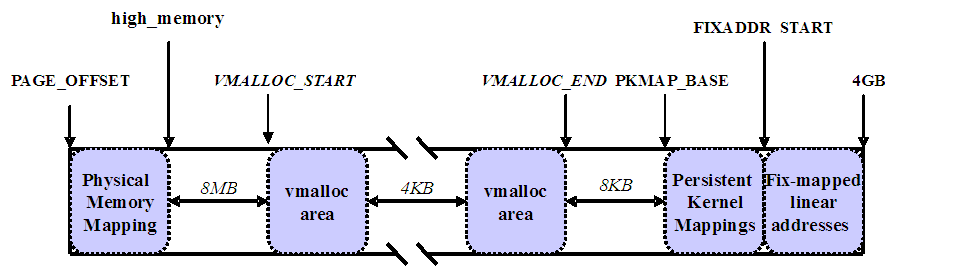
对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可(注意理解这句话:一个页表(不是页表项),大小为4K,可以映射4M的空间),内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
其中的一些宏定义内容如下:
map_new_virtual( )函数本质上是两个嵌套循环,完成的工作是:插入物理地址到hashtable和在对应hashtable中增加一个元素,代码如下:
然后,kunmap()函数撤销原来有kmap()建立的永久内核映射。如果页处在高端内存,调用kunmap_high()函数。代码如下:
3.临时内核映射:和进程控制有关
其中,内核要确保同一个窗口永远不会被两个不同的控制路径同时使用。最后一个符号非线性地址,但由每个CPU用来产生不同的可用窗口数。