FLEN: 利用场信息缓解梯度耦合的大规模CTR预测模型
本文是由美图公司,腾讯公司和厦门大学共同发表的一篇文章,题目为FLEN: Leveraging Field for Scalable CTR Prediction
文章提出了field-wise bi-interaction pooling技术,解决了在大规模应用特征field信息时存在的时间复杂度和空间复杂度高的困境,同时提出了一种缓解梯度耦合问题的方法,dicefactor。该模型已应用于美图的大规模推荐系统中,持续稳定地取得业务效果的全面提升。
下面将从论文背景,梯度耦合问题简介,FLEN模型结构以及实验对比几个方面为大家介绍这篇文章~
背景
点击率预估问题中,建模特征交互对于模型的效果起着至关重要的作用。然而,大部分基于因子分解的模型都存在着一个梯度耦合的问题。
本文提出了一个Field-Leveraged Embedding Network (FLEN) 模型,该模型能够以一种时空高效的方法缓解广泛存在的梯度耦合问题,从而得以在生产环境中部署服务。
FLEN使用了一个filed-wise bi-interaction pooling技术。通过利用特征所属的场的信息,filed-wise bi-interaction pooling能够以更少的模型参数量和更短的计算时间消耗来同时捕获inter-filed和intra-filed之间的特征交互。
同时提出一种dropout策略Dicefactor。Dicefactor随机丢弃一定的bi-linear交互的结果(元素级别)来帮助缓解梯度耦合问题。
FLEN也是首次公开提出的能够将不同的浅层模型如FM,MF,FwFM通过一个统一的框架表达的模型。
关于梯度耦合问题
FM存在的梯度耦合问题
-
假设有如下表达式
y ^ F M = b + w 男 + w 伦 敦 + w 周 二 + < v 男 , v 伦 敦 > + < v 男 , v 周 二 > + < v 伦 敦 , v 周 二 > \hat y_{FM}=b+w_{男}+w_{伦敦}+w_{周二}+
其中 v v v为FM模型的隐向量 -
利用反向传播算法更新隐向量梯度时
关于 v 男 v_{男} v男的梯度为 ∇ v 男 y ^ F M = v 伦 敦 + v 周 二 \nabla_{v_{男}}\hat y_{FM}=v_{伦敦}+v_{周二} ∇v男y^FM=v伦敦+v周二
如果我们假设性别和星期是独立的,那么理想情况下应该有 v 男 v_{男} v男和 v 周 二 v_{周二} v周二是正交的,但是上述梯度会持续朝着 v 周 二 v_{周二} v周二的方向更新 v 男 v_{男} v男,反过来, v 周 二 v_{周二} v周二也会朝着 v 男 v_{男} v男的方向被更新。
以上就是我们说的梯度耦合问题,由于FM使用了相同的隐含向量和不同场内的特征进行交互,在一定程度上损失了模型的表达能力,
- 如何解决这个问题
FFM模型提出了利用特征所属的场的信息来缓解梯度耦合方法,每个特征与不同场下的特征交互时都使用了不同的隐向量。
y ^ F F M = b + w 男 + w 伦 敦 + w 周 二 + < v 男 ( 与 地 点 ) , v 伦 敦 ( 与 性 别 ) > + < v 男 ( 与 星 期 ) , v 周 二 ( 与 性 别 ) > + < v 伦 敦 ( 与 星 期 ) , v 周 二 ( 与 地 点 ) > \hat y_{FFM}=b+w_{男}+w_{伦敦}+w_{周二}+
∇ v 男 ( 与 地 点 ) y ^ F F M = v 伦 敦 ( 与 性 别 ) \nabla_{v_{男(与地点)}}\hat y_{FFM}=v_{伦敦(与性别)} ∇v男(与地点)y^FFM=v伦敦(与性别)
∇ v 男 ( 与 星 期 ) y ^ F F M = v 周 二 ( 与 性 别 ) \nabla_{v_{男(与星期)}}\hat y_{FFM}=v_{周二(与性别)} ∇v男(与星期)y^FFM=v周二(与性别)
在上式的隐向量更新过程中, v 男 v_{男} v男的更新被分为了 v 男 ( 与 地 点 ) v_{男(与地点)} v男(与地点)和 v 男 ( 与 星 期 ) v_{男(与星期)} v男(与星期), v 男 ( 与 地 点 ) v_{男(与地点)} v男(与地点)不再受到和性别相关的特征的干扰,从而缓解了梯度耦合的问题。
FFM及基于FFM的神经网络方法虽然能够缓解梯度耦合问题,但是其带来的参数量的增加和训练时间的延长使得其难以被大规模部署,下面就看看本文提出的FLEN是如何以一种时空高效的方法缓解该问题的。
FLEN
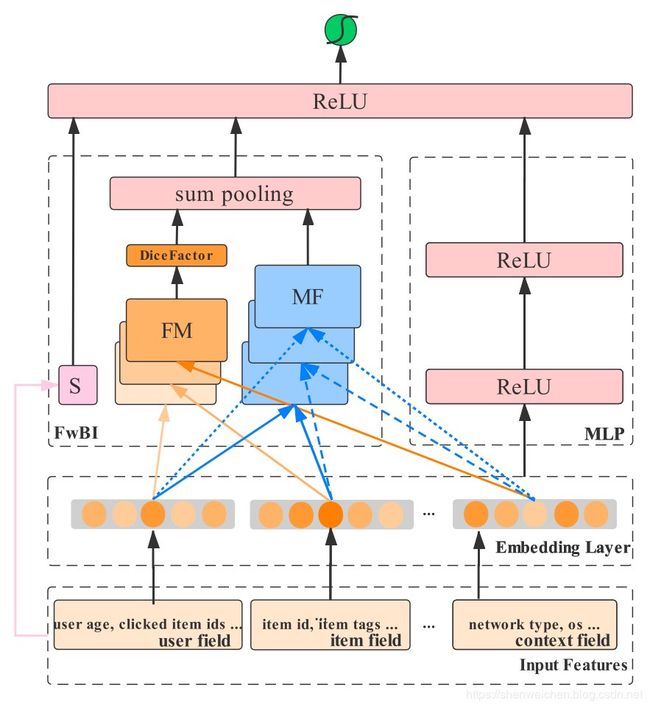
Feature Representation
特征在输入到模型时按照其所属的大类别分别被划分成了user field,item field和context field。
下图只展示了user field和item field

Embedding Layer
将每一个特征 x n x_n xn通过embedding层映射为稠密向量 f n f_n fn。
与传统的embedding层不同的是,FLEN模型中额外使用了一个filed-wise embedding vector,通过将同一个大类(如user filed或者item field)中的embedding 向量进行求和得到大类对应的embedding向量 e m e_m em。
e m = ∑ n ∣ F ( n ) = m f n e_m=\sum\limits_{n|F(n)=m}f_n em=n∣F(n)=m∑fn
Field-Wise Bi-Interaction Component
这部分主要分为三个小块,分别为
- 所有特征线性组合以及全局偏置项
- 特征大类之间的交叉组合MF
- 特征大类内部的交叉组合FM
线性部分
第一项可以看作一个简单的lr,输出为所有特征的线性组合加一个偏置项。
MF模块
第二项叫做MF模块,主要用来学习大类特征组(user,item or context)之间的特征组合。
h M F = ∑ i = 1 M ∑ j = i + 1 M e i ⊙ e j ∗ r [ i ] [ j ] h_{MF}=\sum_{i=1}^M\sum_{j=i+1}^Me_i\odot e_j*r[i][j] hMF=∑i=1M∑j=i+1Mei⊙ej∗r[i][j]
其中M是大类特征组的个数(若分成user,item,context,则M=3), e i e_i ei是前面提到的filed-wise embedding vector, r [ i ] [ j ] r[i][j] r[i][j]为表示大类特征组 i i i和 j j j之间的相关性强度的参数。
FM模块
第三项叫做FM模块,用来学习每一个大类特征组内部的特征两辆之间的组合。这里使用FM中常用的计算化简技巧,将 O ( n 2 ) O(n^2) O(n2)的时间复杂度化简到了 O ( n ) O(n) O(n)。
h F M = ∑ m ( h f m − h t m ) ∗ r [ m ] [ m ] h_{FM}=\sum_m(hf_m-ht_m)*r[m][m] hFM=∑m(hfm−htm)∗r[m][m]
h f m = e m ⊙ e m = ( ∑ n ∣ F ( n ) = m f n ) ⊙ ( ∑ n ∣ F ( n ) = m f n ) hf_m=e_m\odot e_m=(\sum\limits_{n|F(n)=m}f_n)\odot (\sum\limits_{n|F(n)=m}f_n) hfm=em⊙em=(n∣F(n)=m∑fn)⊙(n∣F(n)=m∑fn)
h t m = ∑ n ∣ F ( n ) = m f n ⊙ f n ht_m=\sum\limits_{n|F(n)=m}f_n\odot f_n htm=n∣F(n)=m∑fn⊙fn
r [ m ] [ m ] r[m][m] r[m][m]表达的是每个大类特征组自身的相对重要性。
Field-Wise Bi-Interaction的输出
MF和FM组件的输出分别是包含了特征组之间和特征组内部特征交叉的 K e K_e Ke维的向量。
将两个向量求和与一阶项的结果进行拼接,经过一次非线性变换得到最终的输出
h F w B I = σ ( W F w B I T [ h S , h M F + h F M ] ) h_{FwBI}=\sigma(W_{FwBI}^T[h_S,h_{MF}+h_{FM}]) hFwBI=σ(WFwBIT[hS,hMF+hFM])
得到的 h F w B I h_{FwBI} hFwBI的维度为 K e + 1 K_e+1 Ke+1
FwBI组件之所以能缓解梯度耦合问题,是因为其将传统的所有特征直接进行交互组合的方式变为了分组交互的方式。
在FwBI中,若取MF中 r [ i ] [ j ] = 1 r[i][j]=1 r[i][j]=1和 F M FM FM中的 r [ m ] [ m ] = 0.5 r[m][m]=0.5 r[m][m]=0.5,则FwBI退化成了NFM中的Bi-Interaction Pooling。
理想情况下,相关性弱的特征组之间的 r [ i ] [ j ] r[i][j] r[i][j]应该是一个较低的值,这样则可以减少特征向量受到无关特征向量的影响。
MLP component
除了使用FwBI建模二阶交互外,还使用了一个多层全连接网络隐式地学习高阶特征组合。
Prediction Layer
最终将FwBI的输出 h F w B i h_{FwBi} hFwBi和MLP的输出 h L h_L hL进行拼接,经过一次非线性变换得到最终的模型打分 z z z。
z = s i g m o i d ( W F T h F ) z=sigmoid(W^T_Fh_F) z=sigmoid(WFThF)
其中 h F = c o n c a t ( h F w B I , H L ) h_F=concat(h_{FwBI,H_L}) hF=concat(hFwBI,HL)
Dicefactor:Dropout Technique
在Field-Wise Bi-Interaction中,MF组件通过引入参数 r [ i ] [ j ] r[i][j] r[i][j]来缓解大类特征组之间存在的梯度耦合问题。然而,对于每个特征组内部,仍然可能存在该问题。本文使用了一个Dicefactor技巧来环境特征组内部的梯度耦合问题。

如图,对于两个 K e K_e Ke维的embedding vector,两两交互可以形成 K e K_e Ke条交互路径(这里每条交互路径是元素级别的,一个embedding vector由 K e K_e Ke个元素构成)。
DiceFactor通过随机丢弃部分交互路径来防止 e i e_i ei和 e j e_j ej之间的相互影响。
每条路径被丢弃的概率 p [ i ] ∼ B e r n o u l l i ( β ) p[i]\sim Bernoulli(\beta) p[i]∼Bernoulli(β),该部分网络可以看作是 2 K e 2^{K_e} 2Ke个共享权重参数的网络集合。每次前向传播时随机选取集合中的一个进行训练。
ϕ F M = [ w 0 + ∑ i = 1 N w [ i ] x [ i ] + ∑ i = 1 M ∑ j = 1 & i ≠ j M p e i ⊙ e j ] \phi_{FM}=[w_0+ \sum\limits_{i=1}^Nw[i]x[i]+\sum\limits_{i=1}^M\sum\limits_{j=1\&i\neq j}^Mpe_i\odot e_j] ϕFM=[w0+i=1∑Nw[i]x[i]+i=1∑Mj=1&i=j∑Mpei⊙ej]
为了保证后续网络的输入的期望不变,在预测时需要对该部分的输出结果乘上 β \beta β,以补偿训练时由于随机丢弃造成的输出结果减小。
ϕ F M = [ w 0 + ∑ i = 1 N w [ i ] x [ i ] + ∑ i = 1 M ∑ j = 1 & i ≠ j M β e i ⊙ e j ] \phi_{FM}=[w_0+ \sum\limits_{i=1}^Nw[i]x[i]+\sum\limits_{i=1}^M\sum\limits_{j=1\&i\neq j}^M \beta e_i\odot e_j] ϕFM=[w0+i=1∑Nw[i]x[i]+i=1∑Mj=1&i=j∑Mβei⊙ej]
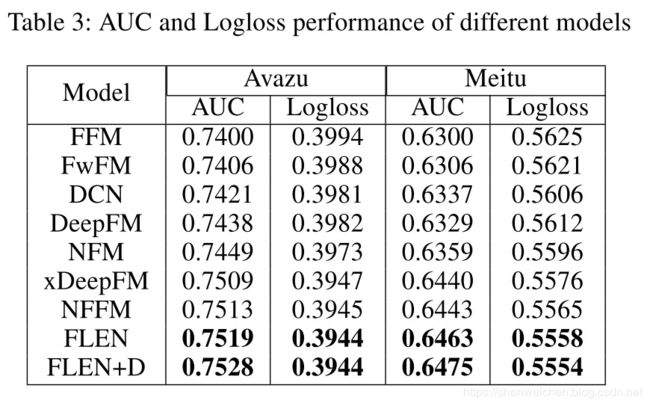
实验对比
实验环节验证FLEN在离线数据集和线上AB中的有效性,以及FLEN相比于其他利用场信息的模型在参数量级和训练时间上的优势,文章还对比了一些超参数对模型效果的影响。
数据集效果对比
在离线实验中,FLEN相比于同样利用特征场信息的NFFM模型能购达到相近的效果。同时,使用了Dicefactor的FLEN模型能够进一步提升效果。
参数量和训练时间对比
其中 N N N是特征个数,M是大类特征组的个数, K e K_e Ke是embedding size。
可以看到FLEN相比于利用场信息的FFM和NFFM,参数量缩小了一个数量级。

下图是不同数据集中,模型的每秒能够处理的样本条数和收敛速度,可以看到FLEN模型相比于xDeepFM和NFFM等单位时间内能够处理的样本更多,同时也收敛的更快。


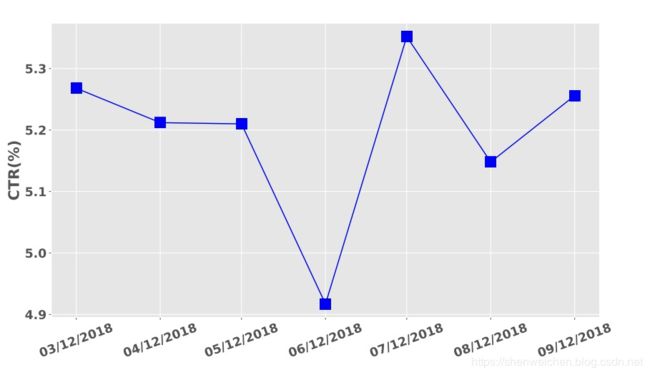
在线实验
在美图生产环境中的7天ab实验中,对比的基准桶为NFM模型。
线上CTR平均提升5.195%。
参考资料
- FLEN: Leveraging Field for Scalable CTR Prediction
文章给出了实验代码仓库地址,不过截至发文时该仓库还未上传代码,大家可以先关注下deepctr的代码仓库,之后我会更新在这里
https://github.com/shenweichen/deepctr
https://zhuanlan.zhihu.com/p/53231955
想要了解更多关于推荐系统,ctr预测算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!