FiBiNET:结合特征重要性和双线性特征交互进行CTR预估
简介
最近忙于工作,没怎么看新的论文,今天把之前写的一点记录分享一下~
本文主要介绍新浪微博机器学习团队发表在RecSys19上的一项工作。
文章标题为 FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
文章指出当前的许多通过特征组合进行CTR预估的工作主要使用特征向量的内积或哈达玛积来计算交叉特征,这种方法忽略了特征本身的重要程度。提出通过使用Squeeze-Excitation network (SENET) 结构动态学习特征的重要性以及使用一个双线性函数来更好的建模交叉特征。
下面对该模型进行一个简单的介绍并提供核心代码实现以及运行demo,细节问题请参阅论文。
模型结构
整体结构
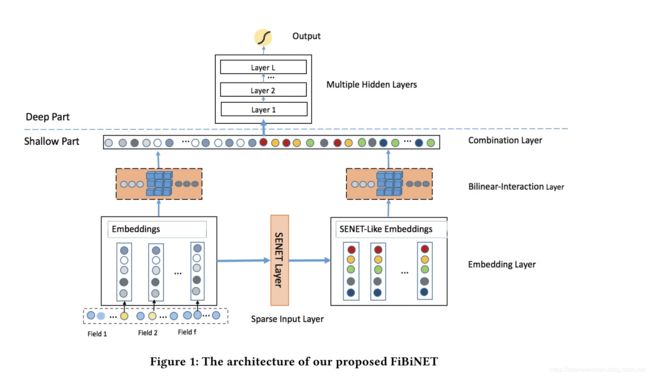
图中可以看到相比于我们熟悉的基于深度学习的CTR预估模型,主要增加了SENET Layer和Bilinear-Interaction Layer两个结构。下面就针对这两个结构进行简单的说明。
SENET Layer
SENET Layer的主要作用是学习不同特征的一个重要程度,对重要特征加权,对蕴含信息量不多的特征进行削弱。对于该结构的更详细的介绍可以参考论文Squeeze-and-Excitation Networks
该使用特征组的embedding向量作为输入,产生一个特征组权重向量 A = [ a 1 , . . . , a i , . . . a f ] A=[{a_1,...,a_i,...a_f}] A=[a1,...,ai,...af],最后将原始特征组embedding向量 E E E乘上 A A A得到一组新的embedding向量 V = [ v 1 , . . . , v i , . . . v f ] V=[{v_1,...,v_i,...v_f}] V=[v1,...,vi,...vf]
具体来说,分为3个步骤:
Squeeze
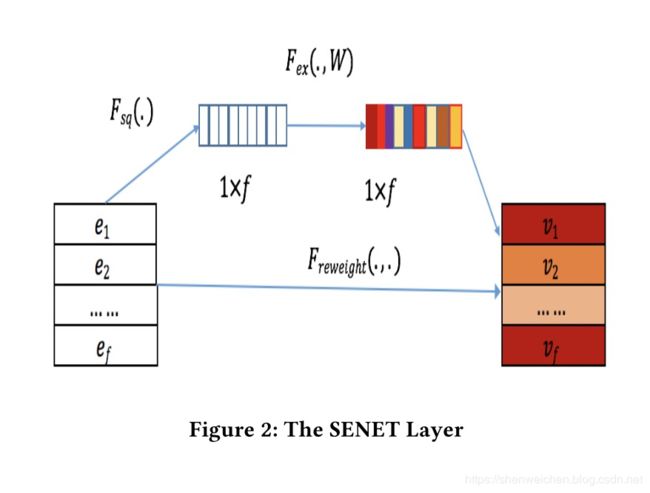
这一步主要是对每个特征组中的embedding向量进行汇总统计量的操作。文章使用了池化操作来对原始特征组embedding向量 E = [ e 1 , . . . , e f ] E=[e_1,...,e_f] E=[e1,...,ef]进行压缩表示得到统计向量 Z = [ z 1 , . . . , z i , . . . z f ] Z=[z_1,...,z_i,...z_f] Z=[z1,...,zi,...zf],其中 z i z_i zi表示第 i i i个特征的全局信息。 z i z_i zi可以通过如下的平均池化的方式计算得到:
z i = F s q ( e i ) = 1 k ∑ t = 1 k e i ( t ) z_i=F_{sq}(e_i)=\frac{1}{k}\sum_{t=1}^ke_i^{(t)} zi=Fsq(ei)=k1∑t=1kei(t)
当然,也可以使用最大池化的方式,文章表示平均池化效果要好于最大池化。
Excitation
这一步基于特征组的压缩统计量来学习特征组的重要性权重,文章使用两层的神经网络来学习。第一层为一个维度缩减层,第二层为维度提升层。形式化表示为:
A = F e x ( Z ) = σ 2 ( W 2 σ 1 ( W 1 Z ) ) A=F_{ex}(Z)=\sigma_2(W_2\sigma_1(W_1Z)) A=Fex(Z)=σ2(W2σ1(W1Z)),其中 A ∈ R f A\in R^f A∈Rf是一个向量, σ 1 \sigma_1 σ1和 σ 2 \sigma_2 σ2是激活函数,需要学习的参数为 W 1 ∈ R f × f r W_1\in R^{f \times\frac{f}{r}} W1∈Rf×rf, W 2 ∈ R f r × f W_2\in R^{\frac{f}{r} \times f} W2∈Rrf×f, r r r为缩减比例参数。
Re-Weight
这一步利用Excitation操作得到的特征重要性权重来对原始的特征组embedding向量重新赋权,
新的embedding向量通过如下的方式计算得到
V = F R e W e i g h t ( A , E ) = [ a 1 ⋅ e 1 , . . . , a f ⋅ e f ] = [ v 1 , . . . , v f ] V=F_{ReWeight}(A,E)=[a_1\cdot e_1,...,a_f\cdot e_f]=[v_1,...,v_f] V=FReWeight(A,E)=[a1⋅e1,...,af⋅ef]=[v1,...,vf],其中 a i ∈ R , e i ∈ R k , v i ∈ R k a_i \in R,e_i \in R^k,v_i \in R^k ai∈R,ei∈Rk,vi∈Rk
Bilinear-Interaction
传统的特征交叉方式广泛采用了内积(fm,ffm等)和哈达玛积(AFM,NFM等)。而这两种方式在稀疏数据上很难有效对特征交叉进行建模。
文章提出结合内积和哈达玛积并引入一个额外的参数矩阵 W W W来学习特征交叉,

交叉向量 p i j p_{ij} pij可以通过一下三种方式计算得到:
Field-All Type
p i j = v i ⋅ W ⊙ v j p_{ij}=v_i\cdot W\odot v_j pij=vi⋅W⊙vj
这种情况下,所有特征组交叉时共享一个参数矩阵 W W W,额外参数量为 k × k k\times k k×k
Field-Each Type
p i j = v i ⋅ W i ⊙ v j p_{ij}=v_i\cdot W_i\odot v_j pij=vi⋅Wi⊙vj
这种情况下,每个特征组 i i i维护一个参数矩阵 W i W_i Wi,额外参数量为 ( f − 1 ) × k × k (f-1)\times k\times k (f−1)×k×k
Filed-Interaction Type
p i j = v i ⋅ W i j ⊙ v j p_{ij}=v_i\cdot W_{ij}\odot v_j pij=vi⋅Wij⊙vj
每对交互特征 p i j p_{ij} pij都有一个参数矩阵 W i j W_{ij} Wij,额外参数量为 f ( f − 1 ) 2 × k × k \frac{f(f-1)}{2}\times k\times k 2f(f−1)×k×k
最终,交叉层由原始的特征组embedding向量 E E E以及SENET层输出的embedding向量 V V V分别得到交叉向量 p = [ p 1 , . . . , p i , . . . p n ] p=[p_1,...,p_i,...p_n] p=[p1,...,pi,...pn]和 q = [ q 1 , . . . , q i , . . . q n ] q=[q_1,...,q_i,...q_n] q=[q1,...,qi,...qn],其中 p i , q i ∈ R k p_i,q_i\in R^k pi,qi∈Rk为向量。
Combination Layer
组合层将交叉向量 p p p和 q q q进行拼接操作,得到结果向 c = F c o n c a t ( p , q ) = [ p 1 , . . . , p i , . . . p n , q 1 , . . . , q i , . . . q n ] = [ c 1 , . . . , c 2 n ] c=F_{concat}(p,q)=[p_1,...,p_i,...p_n,q_1,...,q_i,...q_n]=[c_1,...,c_{2n}] c=Fconcat(p,q)=[p1,...,pi,...pn,q1,...,qi,...qn]=[c1,...,c2n]
若直接对 c c c向量中的元素进行求和并使用一个sigmoid函数输出,则得到一个浅层的CTR预估模型,若将该向量输入深度神经网络,则得到一个深度CTR预估模型。
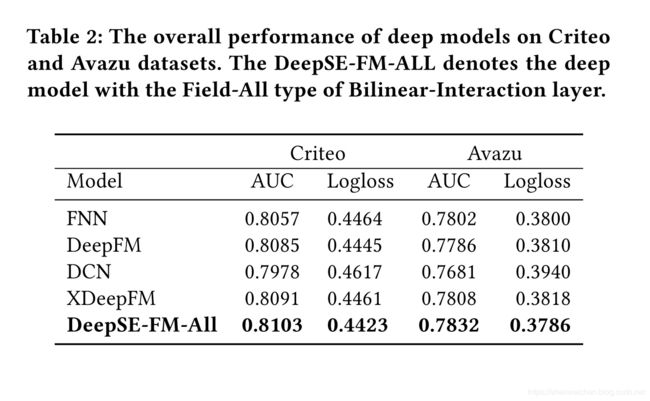
实验结果对比
文章在criteo和avazu两个公开数据集上进行了大量的对比实验,这里只贴出FiBiNET相比于其他模型的一个对比结果,其他实验细节请参阅论文~
浅层FiBiNET

深层FiBiNET
核心代码
这边只简单贴一下运行部分的代码,预处理和构造参数的代码请参考
https://github.com/shenweichen/DeepCTR/blob/master/deepctr/layers/interaction.py
SENET Layer
Z = tf.reduce_mean(inputs,axis=-1,)
A_1 = tf.nn.relu(self.tensordot([Z,self.W_1]))
A_2 = tf.nn.relu(self.tensordot([A_1,self.W_2]))
V = tf.multiply(inputs,tf.expand_dims(A_2,axis=2))
Bilinear Interaction Layer
if self.type == "all":
p = [tf.multiply(tf.tensordot(v_i,self.W,axes=(-1,0)),v_j) for v_i, v_j in itertools.combinations(inputs, 2)]
elif self.type == "each":
p = [tf.multiply(tf.tensordot(inputs[i],self.W_list[i],axes=(-1,0)),inputs[j]) for i, j in itertools.combinations(range(len(inputs)), 2)]
elif self.type =="interaction":
p = [tf.multiply(tf.tensordot(v[0],w,axes=(-1,0)),v[1]) for v,w in zip(itertools.combinations(inputs,2),self.W_list)]
运行用例
首先确保你的python版本为2.7,3.4,3.5或3.6,然后pip install deepctr[cpu]或者pip install deepctr[gpu], 再去下载一下demo数据 然后直接运行下面的代码吧!
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import FiBiNET
from deepctr.inputs import SparseFeat, DenseFeat,get_fixlen_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.count #unique features for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, data[feat].nunique())
for feat in sparse_features] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
fixlen_feature_names = get_fixlen_feature_names(linear_feature_columns + dnn_feature_columns)
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2)
train_model_input = [train[name] for name in fixlen_feature_names]
test_model_input = [test[name] for name in fixlen_feature_names]
# 4.Define Model,train,predict and evaluate
model = FiBiNET(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
参考文献
- FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
- Squeeze-and-Excitation Networks
想要了解更多关于推荐系统,点击率预测算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!
. . . . . . . 