GCD源码吐血分析(2)——dispatch_async/dispatch_sync/dispatch_once/dispatch group
上一章中,我们知道了获取GCD queue的底层实现。获取到queue后,就需要将任务提交到queue中进行处理。
我们有两种方式提交任务:
dispatch_async和dispatch_sync。一个是异步不等待任务完成就返回,另一个是同步任务,需要等待任务完成。这两种提交任务的方式有所不同:
dispatch_async :底层运用了线程池,会在和当前线程不同的线程上处理任务。
dispatch_sync :一般不会新开启线程,而是在当前线程执行任务(比较特殊的是main queue,它会利用main runloop 将任务提交到主线程来执行),同时,它会阻塞当前线程,等待提交的任务执行完毕。当target queue是并发线程时,会直接执行任务。而target queue是串行队列时,会检测当前线程是否已经拥有了该串行队列,如果答案是肯定的,则会触发crash,这与老版本GCD中会触发死锁不同,因为在新版GCD中,已经加入了这种死锁检测机制,从而触发crash,避免了调试困难的死锁的发生。
如下图所示,当我们在同一线程中的串行队列任务执行期间,再次向该队列提交任务时,会引发crash。

但是,目前这种检测死锁的机制也不是完美的,我们仍可以绕过crash来引发死锁(是不是没事找事儿?),具体可见下面的源码分析。
dispatch_sync
void
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_sync_f(dq, work, _dispatch_Block_invoke(work));
}
void
dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func)
{
// 串行队列走这里
return dispatch_barrier_sync_f(dq, ctxt, func);
}
// 并行队列走这里
_dispatch_sync_invoke_and_complete(dq, ctxt, func);
}
先来看一下串行队列会执行的dispatch_barrier_sync_f:
DISPATCH_NOINLINE
void
dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_tid tid = _dispatch_tid_self(); // 获取当前thread id
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dq, tid))) { // 当前线程尝试绑定获取串行队列的lock
return _dispatch_sync_f_slow(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT); // 线程获取不到queue的lock,则串行入队等待,当前线程阻塞
}
// 不需要等待,则走这里
_dispatch_queue_barrier_sync_invoke_and_complete(dq, ctxt, func);
}
我们重点看一下线程是如何尝试获取串行队列lock的,这很重要,这一步是后面的死锁检测的基础:
DISPATCH_ALWAYS_INLINE DISPATCH_WARN_RESULT
static inline bool
_dispatch_queue_try_acquire_barrier_sync(dispatch_queue_t dq, uint32_t tid)
{
uint64_t init = DISPATCH_QUEUE_STATE_INIT_VALUE(dq->dq_width);
uint64_t value = DISPATCH_QUEUE_WIDTH_FULL_BIT | DISPATCH_QUEUE_IN_BARRIER |
_dispatch_lock_value_from_tid(tid); // _dispatch_lock_value_from_tid 会去取tid二进制数的2到31位 作为值(从0位算起)
uint64_t old_state, new_state;
// 这里面有一堆宏定义的原子操作,事实是
// 尝试将new_state赋值给dq.dq_state。 首先会用原子操作(atomic_load_explicit)取当前dq_state的值,作为old_state。如果old_state 不是dq_state的默认值(init | role), 则赋值失败,返回false(这说明之前已经有人更改过dq_state,在串行队列中,一次仅允许一个人更改dq_state), 获取lock失败。否则dq_state赋值为new_state(利用原子操作atomic_compare_exchange_weak_explicit 做赋值), 返回true,获取lock成功。
return os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, acquire, {
uint64_t role = old_state & DISPATCH_QUEUE_ROLE_MASK;
if (old_state != (init | role)) { // 如果dq_state已经被修改过,则直接返回false,不更新dq_state为new_state
os_atomic_rmw_loop_give_up(break);
}
new_state = value | role;
});
}
上面代码会去取dispatch_queue_t中的dq_state值。当这个dq_state没有被别人修改过,即第一次被修改时,会将dq_state设置为new_state, 并返回true。此时,在new_state中标记了当前的queue被lock,同时记录了lock 当前queue的线程tid。
如果dq_state已经被修改过了, 则函数返回false,同时,保持dq_state值不变。
看过了_dispatch_queue_try_acquire_barrier_sync的内部实现,我们再回到上一级dispatch_barrier_sync_f中:
DISPATCH_NOINLINE
void
dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_tid tid = _dispatch_tid_self(); // 获取当前thread id
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dq, tid))) { // 当前线程尝试绑定获取串行队列的lock
return _dispatch_sync_f_slow(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT); // 线程获取不到queue的lock,则串行入队等待,当前线程阻塞
}
...
}
如果_dispatch_queue_try_acquire_barrier_sync 返回了false,则会进入到_dispatch_sync_f_slow中,在这里会尝试等待串行队列中上一个任务执行完毕:
DISPATCH_NOINLINE
static void
_dispatch_sync_f_slow(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (unlikely(!dq->do_targetq)) { // 如果dq没有target queue,走这里。这种情况多半不会发生,因为所有自定义创建的queue都有target queue是root queue之一
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
// 多数会走这里
_dispatch_sync_wait(dq, ctxt, func, dc_flags, dq, dc_flags);
}
我们来看一下_dispatch_sync_wait的实现的超级简略版:
DISPATCH_NOINLINE
static void
_dispatch_sync_wait(dispatch_queue_t top_dq, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_t dq, uintptr_t dc_flags)
{
pthread_priority_t pp = _dispatch_get_priority();
dispatch_tid tid = _dispatch_tid_self();
dispatch_qos_t qos;
uint64_t dq_state;
// Step 1. 检测是否会发生死锁,若会发生死锁,则直接crash
dq_state = _dispatch_sync_wait_prepare(dq);
// 如果当前的线程已经拥有目标queue,这时候在调用_dispatch_sync_wait,则会触发crash
// 这里的判断逻辑是lock的woner是否是tid(这里因为在dq_state的lock里面加入了tid的值,所有能够自动识别出死锁的情况:同一个串行队列被同一个线程做两次lock)
if (unlikely(_dq_state_drain_locked_by(dq_state, tid))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
"dispatch_sync called on queue "
"already owned by current thread");
}
// Step2. _dispatch_queue_push_sync_waiter(dq, &dsc, qos); // 将要执行的任务入队
// Step3. 等待前面的task执行完毕
if (dsc.dc_data == DISPATCH_WLH_ANON) {
// 等待线程事件,等待完成(进入dispach_sync的模式)
_dispatch_thread_event_wait(&dsc.dsc_event); // 信号量等待
_dispatch_thread_event_destroy(&dsc.dsc_event); // 等待结束 销毁thread event
// If _dispatch_sync_waiter_wake() gave this thread an override,
// ensure that the root queue sees it.
if (dsc.dsc_override_qos > dsc.dsc_override_qos_floor) {
_dispatch_set_basepri_override_qos(dsc.dsc_override_qos);
}
} else {
_dispatch_event_loop_wait_for_ownership(&dsc);
}
// Step4.
// 等待结束,执行client代码
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags);
}
这里我们重点看一下,GCD在Step1中是如何检测死锁的。其最终会调用函数
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
lock_value就是dq_state,一个32位的整数。通过判断((lock_value ^ tid) & DLOCK_OWNER_MASK)是否为0,来判断当前的串行队列是否已被同一个线程所获取。如果当前队列已经被当前线程获取,即当前线程在执行一个串行任务中,如果此时我们在阻塞等待一个新的串行任务,则会发生死锁。因此,在新版GCD中,当((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0 时,就会主动触发crash来避免死锁。
串行队列死锁的情况是:
线程A在串行队列dq中执行串行任务task1的过程中,如果再向dq中投递串行任务task2,同时还要求必须阻塞当前线程,来等待task2结束(调用dispatch_sync投递task2),那么这时候会发生死锁。
因为这时候task1还没有结束,串行队列不会取执行task2,而我们又要在当前线程等待task2的结束才肯继续执行task1,即task1在等task2,而task2也在等task1,循环等待,形成死锁。
总结一下,GCD会发生死锁的情况必须同时满足3个条件,才会形成task1和task2相互等待的情况:
- 串行队列正在执行task1
- 在task1中又向串行队列投递了task2
- task2是以
dispatch_sync方式投递的,会阻塞当前线程
其实在GCD的死锁检测中,并没有完全覆盖以上3个条件。因为GCD对于条件2,附加加了条件限制,即task2是在task1的执行线程中提交的。而条件2其实是没有这个限制的,task2可以在和task1不同的线程中提交,同样可以造成死锁。因此,在这种情况下的死锁,GCD是检测不出来的,也就不会crash,仅仅是死锁。
以下是GCD会检测出的死锁以及不会检测出的死锁,可以自己体会一下:
// 串行队列死锁crash的例子(在同个线程的串行队列任务执行过程中,再次发送dispatch_sync 任务到串行队列,会crash)
//==============================
dispatch_queue_t sQ = dispatch_queue_create("st0", 0);
dispatch_async(sQ, ^{
NSLog(@"Enter");
dispatch_sync(sQ, ^{ // 这里会crash
NSLog(@"sync task");
});
});
// 串行死锁的例子(这里不会crash,在线程A执行串行任务task1的过程中,又在线程B中投递了一个task2到串行队列同时使用dispatch_sync等待,死锁,但GCD不会测出)
//==============================
dispatch_queue_t sQ1 = dispatch_queue_create("st01", 0);
dispatch_async(sQ1, ^{
NSLog(@"Enter");
dispatch_sync(dispatch_get_main_queue(), ^{
dispatch_sync(sQ1, ^{
NSArray *a = [NSArray new];
NSLog(@"Enter again %@", a);
});
});
NSLog(@"Done");
});
在逻辑结构良好的情况下,串行队列不会发生死锁,而只是task1,task2依次执行:
// 串行队列等待的例子1
//==============================
dispatch_queue_t sQ1 = dispatch_queue_create("st01", 0);
dispatch_async(sQ1, ^{
NSLog(@"Enter");
sleep(5);
NSLog(@"Done");
});
dispatch_sync(sQ1, ^{
NSLog(@"It is my turn");
});
再来看并行队列会走的分支:
DISPATCH_NOINLINE
static void
_dispatch_sync_invoke_and_complete(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func); // call clinet function
_dispatch_queue_non_barrier_complete(dq); // 结束
}
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_sync_function_invoke_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq); // 保护现场
_dispatch_client_callout(ctxt, func); // 回调到client
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
可见,并行队列不会创建线程取执行dispatch_sync命令。
dispatch_async
自定义串行队列的async派发
dispatch_queue_t sq1 = dispatch_queue_create("sq1", NULL);
dispatch_async(sq1, ^{
NSLog(@"Serial aysnc task");
});
他的调用堆栈是:
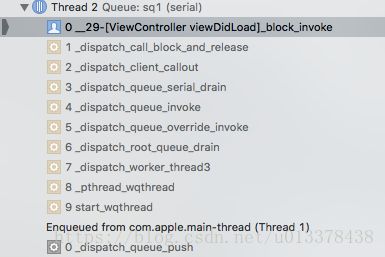
我们来看一下源码:
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
// 设置标志位
uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT;
// 将work打包成dispatch_continuation_t
_dispatch_continuation_init(dc, dq, work, 0, 0, dc_flags);
_dispatch_continuation_async(dq, dc);
}
无论dq是什么类型的queue,GCD首先会将work打包成dispatch_continuation_t 类型,然后调用方法_dispatch_continuation_async。
在继续深入之前,先来看一下work是如何打包的:
static inline void
_dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
pthread_priority_t pp, dispatch_block_flags_t flags, uintptr_t dc_flags)
{
dc->dc_flags = dc_flags | DISPATCH_OBJ_BLOCK_BIT;
// 将work封装到dispatch_continuation_t中
dc->dc_ctxt = _dispatch_Block_copy(work);
_dispatch_continuation_priority_set(dc, pp, flags);
if (unlikely(_dispatch_block_has_private_data(work))) {
// always sets dc_func & dc_voucher
// may update dc_priority & do_vtable
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
if (dc_flags & DISPATCH_OBJ_CONSUME_BIT) { // 之前的flag 被设置为DISPATCH_OBJ_CONSUME_BIT,因此会走这里
dc->dc_func = _dispatch_call_block_and_release; // 这里是设置dc的功能函数:1. 执行block 2. release block对象
} else {
dc->dc_func = _dispatch_Block_invoke(work);
}
_dispatch_continuation_voucher_set(dc, dqu, flags);
}
我们重点关注dc->dc_func = _dispatch_call_block_and_release方法,它会在dispatch_continuation_t dc被执行时调用:
void
_dispatch_call_block_and_release(void *block)
{
void (^b)(void) = block;
b();
Block_release(b);
}
dc_func的逻辑也很简单:执行block,释放block。
看完了work是如何打包成dispatch_continuation_t的,我们回过头来继续看_dispatch_continuation_async,它接受两个参数:work queue以及dispatch_continuation_t 形式的work:
void
_dispatch_continuation_async(dispatch_queue_t dq, dispatch_continuation_t dc)
{
_dispatch_continuation_async2(dq, dc,
dc->dc_flags & DISPATCH_OBJ_BARRIER_BIT);
}
static inline void
_dispatch_continuation_async2(dispatch_queue_t dq, dispatch_continuation_t dc,
bool barrier)
{
// 如果是用barrier插进来的任务或者是串行队列,直接将任务加入到队列
// #define DISPATCH_QUEUE_USES_REDIRECTION(width) \
// ({ uint16_t _width = (width); \
// _width > 1 && _width < DISPATCH_QUEUE_WIDTH_POOL; })
if (fastpath(barrier || !DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width)))
return _dispatch_continuation_push(dq, dc); // 入队
}
return _dispatch_async_f2(dq, dc); // 并行队列走这里
}
执行到_dispatch_continuation_async2时,就出现了分支:(1)串行(barrier)执行_dispatch_continuation_push (2)并行执行_dispatch_async_f2
我们这里关注的是自定义串行队列的分支,因此继续看_dispatch_continuation_push这一支。
static void
_dispatch_continuation_push(dispatch_queue_t dq, dispatch_continuation_t dc)
{
dx_push(dq, dc, _dispatch_continuation_override_qos(dq, dc));
}
// dx_push是一个宏定义:
#define dx_push(x, y, z) dx_vtable(x)->do_push(x, y, z)
#define dx_vtable(x) (&(x)->do_vtable->_os_obj_vtable)
会调用dq的do_push方法,可以在init.c中查看到do_push的定义:
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_serial, queue,
.do_type = DISPATCH_QUEUE_SERIAL_TYPE,
.do_kind = "serial-queue",
.do_dispose = _dispatch_queue_dispose,
.do_suspend = _dispatch_queue_suspend,
.do_resume = _dispatch_queue_resume,
.do_finalize_activation = _dispatch_queue_finalize_activation,
.do_push = _dispatch_queue_push,
.do_invoke = _dispatch_queue_invoke,
.do_wakeup = _dispatch_queue_wakeup,
.do_debug = dispatch_queue_debug,
.do_set_targetq = _dispatch_queue_set_target_queue,
);
查看_dispatch_queue_push的定义:
void
_dispatch_queue_push(dispatch_queue_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
_dispatch_queue_push_inline(dq, dou, qos);
}
#define _dispatch_queue_push_inline _dispatch_trace_queue_push_inline
static inline void
_dispatch_trace_queue_push_inline(dispatch_queue_t dq, dispatch_object_t _tail,
dispatch_qos_t qos)
{
if (slowpath(DISPATCH_QUEUE_PUSH_ENABLED())) {
struct dispatch_object_s *dou = _tail._do;
_dispatch_trace_continuation(dq, dou, DISPATCH_QUEUE_PUSH);
}
_dispatch_introspection_queue_push(dq, _tail); // 第一个push似乎是为了监听dq入队(enqueue)的消息
_dispatch_queue_push_inline(dq, _tail, qos); // 第二个push才是将dq入队, 这里的_tail,实质是_dispatch_continuation_t 类型
}
static inline void
_dispatch_queue_push_inline(dispatch_queue_t dq, dispatch_object_t _tail,
dispatch_qos_t qos)
{
struct dispatch_object_s *tail = _tail._do;
dispatch_wakeup_flags_t flags = 0;
bool overriding = _dispatch_queue_need_override_retain(dq, qos);
if (unlikely(_dispatch_queue_push_update_tail(dq, tail))) { // 将tail放入到dq中
if (!overriding) _dispatch_retain_2(dq->_as_os_obj);
_dispatch_queue_push_update_head(dq, tail);
flags = DISPATCH_WAKEUP_CONSUME_2 | DISPATCH_WAKEUP_MAKE_DIRTY;
} else if (overriding) {
flags = DISPATCH_WAKEUP_CONSUME_2;
} else {
return;
}
return dx_wakeup(dq, qos, flags);
}
这里,会将我们提交的任务,放到dq的队尾。将任务入队后,则调用dx_wakeup方法唤醒dq:
#define dx_wakeup(x, y, z) dx_vtable(x)->do_wakeup(x, y, z)
同样,查看init.c文件,do_wakeup定义:
void
_dispatch_queue_wakeup(dispatch_queue_t dq, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE;
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
return _dispatch_queue_barrier_complete(dq, qos, flags);
}
if (_dispatch_queue_class_probe(dq)) { // 如果dq中有任务,则target = DISPATCH_QUEUE_WAKEUP_TARGET. 当我们第一次进入_dispatch_queue_wakeup时,dq是我们自定义的dq,会进入这里
target = DISPATCH_QUEUE_WAKEUP_TARGET;
}
return _dispatch_queue_class_wakeup(dq, qos, flags, target);
}
当dq是我们自定义时,因为之前我们已经将任务入队,因此dq中肯定有任务,因此target 被设置为了 DISPATCH_QUEUE_WAKEUP_TARGET 。
由于第一次进入时target != NULL, 因此我们删除无关代码:
void
_dispatch_queue_class_wakeup(dispatch_queue_t dq, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
dispatch_assert(target != DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT);
if (target && !(flags & DISPATCH_WAKEUP_CONSUME_2)) {
_dispatch_retain_2(dq);
flags |= DISPATCH_WAKEUP_CONSUME_2;
}
// 这里target 如果dq是root queue大概率为null,否则,target == DISPATCH_QUEUE_WAKEUP_TARGET, 调用_dispatch_queue_push_queue,将自定义dq入队,然后会在调用一遍wake up,最终在root queue中执行方法
if (target) {
uint64_t old_state, new_state, enqueue = DISPATCH_QUEUE_ENQUEUED;
qos = _dispatch_queue_override_qos(dq, qos);
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = _dq_state_merge_qos(old_state, qos);
if (likely(!_dq_state_is_suspended(old_state) &&
!_dq_state_is_enqueued(old_state) &&
(!_dq_state_drain_locked(old_state) ||
(enqueue != DISPATCH_QUEUE_ENQUEUED_ON_MGR &&
_dq_state_is_base_wlh(old_state))))) {
new_state |= enqueue;
}
if (flags & DISPATCH_WAKEUP_MAKE_DIRTY) {
new_state |= DISPATCH_QUEUE_DIRTY;
} else if (new_state == old_state) {
os_atomic_rmw_loop_give_up(goto done);
}
});
if (likely((old_state ^ new_state) & enqueue)) {
dispatch_queue_t tq;
if (target == DISPATCH_QUEUE_WAKEUP_TARGET) {
os_atomic_thread_fence(dependency);
tq = os_atomic_load_with_dependency_on2o(dq, do_targetq,
(long)new_state);
}
dispatch_assert(_dq_state_is_enqueued(new_state));
return _dispatch_queue_push_queue(tq, dq, new_state); // 将dq push到target queue中,并再次调用wake up 方法,tq作为dq传入
}
}
第一次进入wake up方法时,GCD会调用_dispatch_queue_push_queue 方法将自定义dq入队到target queue中,即root queue中:
static inline void
_dispatch_queue_push_queue(dispatch_queue_t tq, dispatch_queue_t dq,
uint64_t dq_state)
{
return dx_push(tq, dq, _dq_state_max_qos(dq_state));
}
这里又调用了dx_push方法,会将我们自定义的dq加入到target queue中。
那么,我们的work,会在root queue中什么时候被执行呢?
我们会看一下调用堆栈:
其实,root queue中维护了一个线程池,当线程执行方法时,会调用_dispatch_worker_thread3方法。为什么会调用thread3方法?线程池是如何创建的?这些问题我们稍后再提,现在,我们先看_dispatch_worker_thread3的实现:
static void
_dispatch_worker_thread3(pthread_priority_t pp)
{
bool overcommit = pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG;
dispatch_queue_t dq;
pp &= _PTHREAD_PRIORITY_OVERCOMMIT_FLAG | ~_PTHREAD_PRIORITY_FLAGS_MASK;
_dispatch_thread_setspecific(dispatch_priority_key, (void *)(uintptr_t)pp);
dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), overcommit); // 根据thread pripority和是否overcommit,取出root queue数组中对应的root queue
return _dispatch_worker_thread4(dq); // 最终会调用它
}
static void
_dispatch_worker_thread4(void *context)
{
dispatch_queue_t dq = context;
dispatch_root_queue_context_t qc = dq->do_ctxt;
_dispatch_introspection_thread_add();
int pending = os_atomic_dec2o(qc, dgq_pending, relaxed);
dispatch_assert(pending >= 0);
_dispatch_root_queue_drain(dq, _dispatch_get_priority()); // 将root queue的所有任务都drain(倾倒),并执行
_dispatch_voucher_debug("root queue clear", NULL);
_dispatch_reset_voucher(NULL, DISPATCH_THREAD_PARK);
}
我们来看root queue是如何被‘倾倒’的:
static void
_dispatch_root_queue_drain(dispatch_queue_t dq, pthread_priority_t pp)
{
#if DISPATCH_DEBUG
dispatch_queue_t cq;
if (slowpath(cq = _dispatch_queue_get_current())) {
DISPATCH_INTERNAL_CRASH(cq, "Premature thread recycling");
}
#endif
_dispatch_queue_set_current(dq); // 设置dispatch thread的当前queue是dq
dispatch_priority_t pri = dq->dq_priority;
if (!pri) pri = _dispatch_priority_from_pp(pp);
dispatch_priority_t old_dbp = _dispatch_set_basepri(pri);
_dispatch_adopt_wlh_anon();
struct dispatch_object_s *item;
bool reset = false;
dispatch_invoke_context_s dic = { };
#if DISPATCH_COCOA_COMPAT
_dispatch_last_resort_autorelease_pool_push(&dic);
#endif // DISPATCH_COCOA_COMPAT
dispatch_invoke_flags_t flags = DISPATCH_INVOKE_WORKER_DRAIN |
DISPATCH_INVOKE_REDIRECTING_DRAIN;
_dispatch_queue_drain_init_narrowing_check_deadline(&dic, pri);
_dispatch_perfmon_start();
while ((item = fastpath(_dispatch_root_queue_drain_one(dq)))) { // 拿出queue中的一个item
if (reset) _dispatch_wqthread_override_reset();
_dispatch_continuation_pop_inline(item, &dic, flags, dq); // 执行这个item
reset = _dispatch_reset_basepri_override();
if (unlikely(_dispatch_queue_drain_should_narrow(&dic))) {
break;
}
}
// overcommit or not. worker thread
if (pri & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG) {
_dispatch_perfmon_end(perfmon_thread_worker_oc);
} else {
_dispatch_perfmon_end(perfmon_thread_worker_non_oc);
}
#if DISPATCH_COCOA_COMPAT
_dispatch_last_resort_autorelease_pool_pop(&dic);
#endif // DISPATCH_COCOA_COMPAT
_dispatch_reset_wlh();
_dispatch_reset_basepri(old_dbp);
_dispatch_reset_basepri_override();
_dispatch_queue_set_current(NULL); // 设置dispatch thread的当前queue是NULL
}
代码很多,核心是中间的while循环:
while ((item = fastpath(_dispatch_root_queue_drain_one(dq)))) { // 拿出queue中的一个item
if (reset) _dispatch_wqthread_override_reset();
_dispatch_continuation_pop_inline(item, &dic, flags, dq); // 执行这个item
reset = _dispatch_reset_basepri_override();
if (unlikely(_dispatch_queue_drain_should_narrow(&dic))) {
break;
}
}
通过while循环,GCD每次从root queue中取出一个queue item,并调用_dispatch_continuation_pop_inline 执行它,直到root queue中的item全部清空为止。
我们来看一下queue item是如何被执行的,这里的queue item,应该是一个dispatch queue:
static inline void
_dispatch_continuation_pop_inline(dispatch_object_t dou,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
dispatch_queue_t dq)
{
dispatch_pthread_root_queue_observer_hooks_t observer_hooks =
_dispatch_get_pthread_root_queue_observer_hooks();
if (observer_hooks) observer_hooks->queue_will_execute(dq);
_dispatch_trace_continuation_pop(dq, dou);
flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;
if (_dispatch_object_has_vtable(dou)) { // 到这里,我们提交的任务,才被queue执行。简直是百转千回啊!!!!
dx_invoke(dou._do, dic, flags);
} else {
_dispatch_continuation_invoke_inline(dou, DISPATCH_NO_VOUCHER, flags);
}
if (observer_hooks) observer_hooks->queue_did_execute(dq);
}
这里dx_invoke是一个宏,它会调用_dispatch_queue_invoke 方法, 结合调用堆栈,其最后会调用
_dispatch_queue_serial_drain。
OK,上面就是dispatch async串行队列的执行步骤,总结一下就是:
将work打包成dispatch_continuation_t, 然后将dq入队到响应的root queue中,root queue中的线程池中的线程会被唤醒,执行线程函数_dispatch_worker_thread3,root queue会被倾倒,执行queue中的任务。
让我们再看一下 dispatch_async 到并行队列的情况:

回到上面串行队列和并行队列分支的地方:
static inline void
_dispatch_continuation_async2(dispatch_queue_t dq, dispatch_continuation_t dc,
bool barrier)
{
// 如果是用barrier插进来的任务或者是串行队列,直接将任务加入到队列
// #define DISPATCH_QUEUE_USES_REDIRECTION(width) \
// ({ uint16_t _width = (width); \
// _width > 1 && _width < DISPATCH_QUEUE_WIDTH_POOL; })
if (fastpath(barrier || !DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width)))
return _dispatch_continuation_push(dq, dc); // 入队
}
return _dispatch_async_f2(dq, dc); // 并行队列走这里
}
并行队列会走_dispatch_async_f2 :
static void
_dispatch_async_f2(dispatch_queue_t dq, dispatch_continuation_t dc)
{
// reserving non barrier width
// doesn't fail if only the ENQUEUED bit is set (unlike its barrier width
// equivalent), so we have to check that this thread hasn't enqueued
// anything ahead of this call or we can break ordering
if (slowpath(dq->dq_items_tail)) {
return _dispatch_continuation_push(dq, dc);
}
if (slowpath(!_dispatch_queue_try_acquire_async(dq))) {
return _dispatch_continuation_push(dq, dc);
}
// async 重定向,任务的执行由自动定义queue转入root queue
return _dispatch_async_f_redirect(dq, dc,
_dispatch_continuation_override_qos(dq, dc));
}
这里,会调用_dispatch_async_f_redirect,同样的,会将dq重定向到root queue中。
static void
_dispatch_async_f_redirect(dispatch_queue_t dq,
dispatch_object_t dou, dispatch_qos_t qos)
{
if (!slowpath(_dispatch_object_is_redirection(dou))) {
dou._dc = _dispatch_async_redirect_wrap(dq, dou);
}
// 将dq替换为root queue
dq = dq->do_targetq;
// 这里一般不会进入,主要是将dq替换为最终的targetq
while (slowpath(DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width))) {
if (!fastpath(_dispatch_queue_try_acquire_async(dq))) {
break;
}
if (!dou._dc->dc_ctxt) {
// find first queue in descending target queue order that has
// an autorelease frequency set, and use that as the frequency for
// this continuation.
dou._dc->dc_ctxt = (void *)
(uintptr_t)_dispatch_queue_autorelease_frequency(dq);
}
dq = dq->do_targetq;
}
// 任务入队,展开宏定义:
// #define dx_push(x, y, z) dx_vtable(x)->do_push(x, y, z)
// #define dx_vtable(x) (&(x)->do_vtable->_os_obj_vtable)
// 由于此时的x实质上是root queue,可以查看init.c 中的
// do_push 实质会调用 _dispatch_root_queue_push
dx_push(dq, dou, qos);
}
这里又出现了dx_push,查看init.c,实质会调用_dispatch_root_queue_push :
void
_dispatch_root_queue_push(dispatch_queue_t rq, dispatch_object_t dou,
dispatch_qos_t qos)
{
#if DISPATCH_USE_KEVENT_WORKQUEUE
dispatch_deferred_items_t ddi = _dispatch_deferred_items_get();
if (unlikely(ddi && ddi->ddi_can_stash)) {
dispatch_object_t old_dou = ddi->ddi_stashed_dou;
dispatch_priority_t rq_overcommit;
rq_overcommit = rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;
if (likely(!old_dou._do || rq_overcommit)) {
dispatch_queue_t old_rq = ddi->ddi_stashed_rq;
dispatch_qos_t old_qos = ddi->ddi_stashed_qos;
ddi->ddi_stashed_rq = rq;
ddi->ddi_stashed_dou = dou;
ddi->ddi_stashed_qos = qos;
_dispatch_debug("deferring item %p, rq %p, qos %d",
dou._do, rq, qos);
if (rq_overcommit) {
ddi->ddi_can_stash = false;
}
if (likely(!old_dou._do)) {
return;
}
// push the previously stashed item
qos = old_qos;
rq = old_rq;
dou = old_dou;
}
}
#endif
#if HAVE_PTHREAD_WORKQUEUE_QOS
if (_dispatch_root_queue_push_needs_override(rq, qos)) { // 判断root queue的优先级和 自定义优先级是否相等,不相等,进入if(一般不相等)
return _dispatch_root_queue_push_override(rq, dou, qos);
}
#else
(void)qos;
#endif
_dispatch_root_queue_push_inline(rq, dou, dou, 1);
}
会调用_dispatch_root_queue_push_override :
static void
_dispatch_root_queue_push_override(dispatch_queue_t orig_rq,
dispatch_object_t dou, dispatch_qos_t qos)
{
bool overcommit = orig_rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;
dispatch_queue_t rq = _dispatch_get_root_queue(qos, overcommit); // 根据优先级,获取root queue
dispatch_continuation_t dc = dou._dc;
if (_dispatch_object_is_redirection(dc)) {
// no double-wrap is needed, _dispatch_async_redirect_invoke will do
// the right thing
dc->dc_func = (void *)orig_rq;
} else {
dc = _dispatch_continuation_alloc();
dc->do_vtable = DC_VTABLE(OVERRIDE_OWNING);
// fake that we queued `dou` on `orig_rq` for introspection purposes
_dispatch_trace_continuation_push(orig_rq, dou);
dc->dc_ctxt = dc;
dc->dc_other = orig_rq;
dc->dc_data = dou._do;
dc->dc_priority = DISPATCH_NO_PRIORITY;
dc->dc_voucher = DISPATCH_NO_VOUCHER;
}
_dispatch_root_queue_push_inline(rq, dc, dc, 1); // 又会调用这里
}
static inline void
_dispatch_root_queue_push_inline(dispatch_queue_t dq, dispatch_object_t _head,
dispatch_object_t _tail, int n)
{
struct dispatch_object_s *head = _head._do, *tail = _tail._do;
// 当queue为空,且需要设置header时,会进入到这里。这里应该是第一次使用root queue的时候会进入一次
if (unlikely(_dispatch_queue_push_update_tail_list(dq, head, tail))) { // 尝试更新dq的list,如果是第一次,list 为空,返回false
_dispatch_queue_push_update_head(dq, head); // 设置queue 头
return _dispatch_global_queue_poke(dq, n, 0); // 这里激活root queue,这里的n是入队dq个数,是1
}
}
上面的判断很重要:
if (unlikely(_dispatch_queue_push_update_tail_list(dq, head, tail))) { // 尝试更新dq的list,如果是第一次,list 为空,返回false
_dispatch_queue_push_update_head(dq, head); // 设置queue 头
return _dispatch_global_queue_poke(dq, n, 0); // 这里激活root queue,这里的n是入队dq个数,是1
}
在执行新的任务时,GCD会尝试更新root queue的任务列表。如果是第一次向root queue投递任务,则此时的任务列表是空,更新任务列表失败,则会进入_dispatch_global_queue_poke 来激活root queue:
void
_dispatch_global_queue_poke(dispatch_queue_t dq, int n, int floor)
{
if (!_dispatch_queue_class_probe(dq)) { // 如果还有要执行的,直接返回
return;
}
#if DISPATCH_USE_WORKQUEUES
dispatch_root_queue_context_t qc = dq->do_ctxt;
if (
#if DISPATCH_USE_PTHREAD_POOL
(qc->dgq_kworkqueue != (void*)(~0ul)) &&
#endif
!os_atomic_cmpxchg2o(qc, dgq_pending, 0, n, relaxed)) {
_dispatch_root_queue_debug("worker thread request still pending for "
"global queue: %p", dq);
return;
}
#endif // DISPATCH_USE_WORKQUEUES
return _dispatch_global_queue_poke_slow(dq, n, floor);
}
poke 会进入第二阶段 _dispatch_global_queue_poke_slow :
static void
_dispatch_global_queue_poke_slow(dispatch_queue_t dq, int n, int floor)
{
dispatch_root_queue_context_t qc = dq->do_ctxt;
int remaining = n; // remaining 表示要执行的任务数量 1
int r = ENOSYS;
// step1. 先初始化root queues 包括初始化XUN 的workqueue
_dispatch_root_queues_init();
_dispatch_debug_root_queue(dq, __func__);
#if DISPATCH_USE_WORKQUEUES
#if DISPATCH_USE_PTHREAD_POOL
if (qc->dgq_kworkqueue != (void*)(~0ul))
#endif
{
_dispatch_root_queue_debug("requesting new worker thread for global "
"queue: %p", dq);
#if DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
if (qc->dgq_kworkqueue) {
pthread_workitem_handle_t wh;
unsigned int gen_cnt;
do {
// 调用XUN内核的workqueue函数,来维护GCD层的 pthread pool
r = pthread_workqueue_additem_np(qc->dgq_kworkqueue,
_dispatch_worker_thread4, dq, &wh, &gen_cnt);
(void)dispatch_assume_zero(r);
} while (--remaining);
return;
}
#endif // DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
#if HAVE_PTHREAD_WORKQUEUE_QOS
r = _pthread_workqueue_addthreads(remaining,
_dispatch_priority_to_pp(dq->dq_priority));
#elif DISPATCH_USE_PTHREAD_WORKQUEUE_SETDISPATCH_NP
r = pthread_workqueue_addthreads_np(qc->dgq_wq_priority,
qc->dgq_wq_options, remaining);
#endif
(void)dispatch_assume_zero(r);
return;
}
#endif // DISPATCH_USE_WORKQUEUES
#if DISPATCH_USE_PTHREAD_POOL
dispatch_pthread_root_queue_context_t pqc = qc->dgq_ctxt;
if (fastpath(pqc->dpq_thread_mediator.do_vtable)) {
while (dispatch_semaphore_signal(&pqc->dpq_thread_mediator)) { // step2. 唤醒线程,来做事情
_dispatch_root_queue_debug("signaled sleeping worker for "
"global queue: %p", dq);
if (!--remaining) { // 如果没有要处理的dq了,返回
return;
}
}
}
}
说实话,这里看的不是很清楚,重点是step1, 初始化root queue的方法:_dispatch_root_queues_init :
void
_dispatch_root_queues_init(void)
{
// 这里用了dispatch_once_f, 仅会执行一次
static dispatch_once_t _dispatch_root_queues_pred;
dispatch_once_f(&_dispatch_root_queues_pred, NULL,
_dispatch_root_queues_init_once);
}
static void
_dispatch_root_queues_init_once(void *context DISPATCH_UNUSED)
{
int wq_supported;
_dispatch_fork_becomes_unsafe();
if (!_dispatch_root_queues_init_workq(&wq_supported)) {
#if DISPATCH_ENABLE_THREAD_POOL
size_t i;
for (i = 0; i < DISPATCH_ROOT_QUEUE_COUNT; i++) {
bool overcommit = true;
#if TARGET_OS_EMBEDDED || (DISPATCH_USE_INTERNAL_WORKQUEUE && HAVE_DISPATCH_WORKQ_MONITORING)
// some software hangs if the non-overcommitting queues do not
// overcommit when threads block. Someday, this behavior should
// apply to all platforms
if (!(i & 1)) {
overcommit = false;
}
#endif
_dispatch_root_queue_init_pthread_pool(
&_dispatch_root_queue_contexts[i], 0, overcommit);
}
#else
DISPATCH_INTERNAL_CRASH((errno << 16) | wq_supported,
"Root queue initialization failed");
#endif // DISPATCH_ENABLE_THREAD_POOL
}
}
这个初始化函数有两个分支,GCD首先会调用_dispatch_root_queues_init_workq 来初始化root queues,如果不成功,才使用_dispatch_root_queue_init_pthread_pool 。 这里可以看出,GCD是优先使用XUN内核提供的workqueue,而非使用用户层的线程池。 我们这里重点关注GCD使用workqueue的情况:
static inline bool
_dispatch_root_queues_init_workq(int *wq_supported)
{
int r; (void)r;
bool result = false;
*wq_supported = 0;
#if DISPATCH_USE_WORKQUEUES
bool disable_wq = false; (void)disable_wq;
#if DISPATCH_ENABLE_THREAD_POOL && DISPATCH_DEBUG
disable_wq = slowpath(getenv("LIBDISPATCH_DISABLE_KWQ"));
#endif
#if DISPATCH_USE_KEVENT_WORKQUEUE || HAVE_PTHREAD_WORKQUEUE_QOS
bool disable_qos = false;
#if DISPATCH_DEBUG
disable_qos = slowpath(getenv("LIBDISPATCH_DISABLE_QOS"));
#endif
#if DISPATCH_USE_KEVENT_WORKQUEUE
bool disable_kevent_wq = false;
#if DISPATCH_DEBUG || DISPATCH_PROFILE
disable_kevent_wq = slowpath(getenv("LIBDISPATCH_DISABLE_KEVENT_WQ"));
#endif
#endif
if (!disable_wq && !disable_qos) {
*wq_supported = _pthread_workqueue_supported();
#if DISPATCH_USE_KEVENT_WORKQUEUE
if (!disable_kevent_wq && (*wq_supported & WORKQ_FEATURE_KEVENT)) {
r = _pthread_workqueue_init_with_kevent(_dispatch_worker_thread3,
(pthread_workqueue_function_kevent_t)
_dispatch_kevent_worker_thread,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
#if DISPATCH_USE_MGR_THREAD
_dispatch_kevent_workqueue_enabled = !r;
#endif
result = !r;
} else
#endif // DISPATCH_USE_KEVENT_WORKQUEUE
if (*wq_supported & WORKQ_FEATURE_FINEPRIO) {
#if DISPATCH_USE_MGR_THREAD
r = _pthread_workqueue_init(_dispatch_worker_thread3,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
result = !r;
#endif
}
if (!(*wq_supported & WORKQ_FEATURE_MAINTENANCE)) {
DISPATCH_INTERNAL_CRASH(*wq_supported,
"QoS Maintenance support required");
}
}
#endif // DISPATCH_USE_KEVENT_WORKQUEUE || HAVE_PTHREAD_WORKQUEUE_QOS
#if DISPATCH_USE_PTHREAD_WORKQUEUE_SETDISPATCH_NP
if (!result && !disable_wq) {
pthread_workqueue_setdispatchoffset_np(
offsetof(struct dispatch_queue_s, dq_serialnum));
r = pthread_workqueue_setdispatch_np(_dispatch_worker_thread2);
#if !DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
(void)dispatch_assume_zero(r);
#endif
result = !r;
}
#endif // DISPATCH_USE_PTHREAD_WORKQUEUE_SETDISPATCH_NP
#if DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK || DISPATCH_USE_PTHREAD_POOL
if (!result) {
#if DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
pthread_workqueue_attr_t pwq_attr;
if (!disable_wq) {
r = pthread_workqueue_attr_init_np(&pwq_attr);
(void)dispatch_assume_zero(r);
}
#endif
size_t i;
for (i = 0; i < DISPATCH_ROOT_QUEUE_COUNT; i++) {
pthread_workqueue_t pwq = NULL;
dispatch_root_queue_context_t qc;
qc = &_dispatch_root_queue_contexts[i];
#if DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
if (!disable_wq && qc->dgq_wq_priority != WORKQ_PRIO_INVALID) {
r = pthread_workqueue_attr_setqueuepriority_np(&pwq_attr,
qc->dgq_wq_priority);
(void)dispatch_assume_zero(r);
r = pthread_workqueue_attr_setovercommit_np(&pwq_attr,
qc->dgq_wq_options &
WORKQ_ADDTHREADS_OPTION_OVERCOMMIT);
(void)dispatch_assume_zero(r);
r = pthread_workqueue_create_np(&pwq, &pwq_attr);
(void)dispatch_assume_zero(r);
result = result || dispatch_assume(pwq);
}
#endif // DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
if (pwq) {
qc->dgq_kworkqueue = pwq;
} else {
qc->dgq_kworkqueue = (void*)(~0ul);
// because the fastpath of _dispatch_global_queue_poke didn't
// know yet that we're using the internal pool implementation
// we have to undo its setting of dgq_pending
qc->dgq_pending = 0;
}
}
#if DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK
if (!disable_wq) {
r = pthread_workqueue_attr_destroy_np(&pwq_attr);
(void)dispatch_assume_zero(r);
}
#endif
}
#endif // DISPATCH_USE_LEGACY_WORKQUEUE_FALLBACK || DISPATCH_ENABLE_THREAD_POOL
#endif // DISPATCH_USE_WORKQUEUES
return result;
}
又是一堆代码,网上对于workqueue的资料比较少,笔者也没有深入的研究。但可以关注下上面代码中workqueue的初始化函数:
_pthread_workqueue_init_with_kevent(_dispatch_worker_thread3,
(pthread_workqueue_function_kevent_t)
_dispatch_kevent_worker_thread,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
workqueue指定了_dispatch_worker_thread3 作为root quue的工作方法:
static void
_dispatch_worker_thread3(pthread_priority_t pp)
{
bool overcommit = pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG;
dispatch_queue_t dq;
pp &= _PTHREAD_PRIORITY_OVERCOMMIT_FLAG | ~_PTHREAD_PRIORITY_FLAGS_MASK;
_dispatch_thread_setspecific(dispatch_priority_key, (void *)(uintptr_t)pp);
dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), overcommit); // 根据thread pripority和是否overcommit,取出root queue数组中对应的root queue
return _dispatch_worker_thread4(dq); // 最终会调用它
}
static void
_dispatch_worker_thread4(void *context)
{
dispatch_queue_t dq = context;
dispatch_root_queue_context_t qc = dq->do_ctxt;
_dispatch_introspection_thread_add();
int pending = os_atomic_dec2o(qc, dgq_pending, relaxed);
dispatch_assert(pending >= 0);
_dispatch_root_queue_drain(dq, _dispatch_get_priority()); // 将root queue的所有任务都drain(倾倒),并执行
_dispatch_voucher_debug("root queue clear", NULL);
_dispatch_reset_voucher(NULL, DISPATCH_THREAD_PARK);
}
上面就是GCD dispatch_async并行队列的实现方法。说实话,理解并不是很清楚,只能从大体上感受一下:
并行队列首先会被替换为对应的root queue,将自定义dq入队。如果是第一次入队,则会去激活所有的root queue。所谓激活,主要是创建XUN 内核支持的workqueue(升级版线程池,会自动判断是否需要创建新的线程),同时,将workqueue的工作函数设置为_dispatch_worker_thread3。_dispatch_worker_thread3 的注意方法是会调用_dispatch_root_queue_drain,将root queue进行清空,它会清空所有提交到当前root queue中的dq,并执行它们的dq任务。
dispatch_once
我们平常在写单例模式的时候,总会用到GCD的dispatch_once 函数。那么,它是怎么实现的呢?
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
NSLog(@"This will only run once");
});
dispatch_once_t onceToken是一个typedef,实际上是一个long值:
typedef long dispatch_once_t;
dispatch_once是一个宏定义:
#define dispatch_once _dispatch_once
我们查看_dispatch_once 方法的定义:
void
_dispatch_once(dispatch_once_t *predicate,
DISPATCH_NOESCAPE dispatch_block_t block)
{
if (DISPATCH_EXPECT(*predicate, ~0l) != ~0l) { // 如果是第一次进入,走这里。或者在设置*predicate = ~0l之前,其他线程再调用_dispatch_once,还会走这里
dispatch_once(predicate, block); // 这里执行完毕之前,如果_dispatch_once再次由其他线程调用,仍会进入这里
}
DISPATCH_COMPILER_CAN_ASSUME(*predicate == ~0l); // 设置*predicate == ~0l,防止在进入
}
这里可以发现,当单例方法执行完毕,GCD会将onceToken置为~0。如果再次调用单例方法,GCD会发现onceToken已经使用过,就直接返回了。但是仍有一种可能,就是在onceToken被设置为~0之前,其他线程再次进入了_dispatch_once方法,这就会导致dispatch_once 被多次调用。
我们就来接着看一下,在dispatch_once中,是如何防止这种情况发生的:
void
dispatch_once(dispatch_once_t *val, dispatch_block_t block)
{
dispatch_once_f(val, block, _dispatch_Block_invoke(block));
}
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
#if !DISPATCH_ONCE_INLINE_FASTPATH
if (likely(os_atomic_load(val, acquire) == DLOCK_ONCE_DONE)) { // 这里来判断是否已经执行了一次(用原子操作load val的值,如果执行过了 val == ~0)
return;
}
#endif // !DISPATCH_ONCE_INLINE_FASTPATH
return dispatch_once_f_slow(val, ctxt, func);
}
static void
dispatch_once_f_slow(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
_dispatch_once_waiter_t volatile *vval = (_dispatch_once_waiter_t*)val; // 明明是一个long指针,硬被转换为了_dispatch_once_waiter_t *,无所谓,都是地址而已
struct _dispatch_once_waiter_s dow = { };
_dispatch_once_waiter_t tail = &dow, next, tmp;
dispatch_thread_event_t event;
if (os_atomic_cmpxchg(vval, NULL, tail, acquire)) { // *vval 是否等于NULL? 是,则返回true,并将*vval置为tail。如果不是,返回false(第一次进入,*vval == NULL, 之后又其他线程进入,则进入else分支) 如果之后在没有其他线程进入,则val的值一直会保持tail
dow.dow_thread = _dispatch_tid_self();// 当前线程的 thread port
_dispatch_client_callout(ctxt, func); // 执行client 代码,也就是我们单例初始化方法。 注意,如果在client 代码中嵌套调用同一个once token的dispatch once方法时,再次会进入else分支,导致当前的thread被_dispatch_thread_event_wait阻塞,而无法执行下面的_dispatch_thread_event_signal,导致死锁
next = (_dispatch_once_waiter_t)_dispatch_once_xchg_done(val); // 调用原子操作 atomic_exchange_explicit(val, DLOCK_ONCE_DONE, memory_order_release); 将val置为DLOCK_ONCE_DONE,同时返回val的之前值赋值给next
while (next != tail) { // 如果next 不为tail, 说明val的值被别的线程修改了。也就是说同一时间,有其他线程试图执行单例方法,这会导致其他线程做信号量等待,所以下面要signal其他线程
tmp = (_dispatch_once_waiter_t)_dispatch_wait_until(next->dow_next);
event = &next->dow_event;
next = tmp;
_dispatch_thread_event_signal(event);
}
} else { // 其他后进入的线程会走这里(会被阻塞住,直到第一个线程执行完毕,才会被唤醒)
_dispatch_thread_event_init(&dow.dow_event);
next = *vval; // 保留之前的值
for (;;) {
if (next == DISPATCH_ONCE_DONE) {
break;
}
if (os_atomic_cmpxchgv(vval, next, tail, &next, release)) { // *vval 是否等于next?相等,返回true,同时设置*vval = tail。不相等,返回false,同时设置*vval = next. 所有线程第一次进入这里,应该是相等的
// 这里的dow = *tail = *vval
// 因此下面两行代码可以理解为:
// (*vval)->dow_thread = next->dow_thread
// (*vval)->dow_next = next;
dow.dow_thread = next->dow_thread; // 这里的dow = *tail = **vval
dow.dow_next = next;
if (dow.dow_thread) {
pthread_priority_t pp = _dispatch_get_priority();
_dispatch_thread_override_start(dow.dow_thread, pp, val);
}
_dispatch_thread_event_wait(&dow.dow_event); // 线程在这里休眠,直到单例方法执行完毕后,被唤醒
if (dow.dow_thread) {
_dispatch_thread_override_end(dow.dow_thread, val);
}
break;
}
}
_dispatch_thread_event_destroy(&dow.dow_event);
}
}
上面的代码注释应该说明了在dispatch_once_f_slow中是如何保证代码仅执行一次,同时防止在其他线程多次进入的情况。可以看到,其避免多线程的方法主要是用了C++11中的原子操作。这说一下dispatch_once_f_slow 实现的大致思路:
- 如果是线程第一次进入
dispatch_once_f_slow方法,此时*vval == NULL, 进入if分支,执行单例方法。同时,通过原子操作os_atomic_cmpxchg, *vval 被设置为tail,也就是_dispatch_once_waiter_t,指向一个空的_dispatch_once_waiter_s结构体。 - 如果其他线程再次进入
dispatch_once_f_slow方法,此时*vval != NULL,走 else 分支。在else分支里面主要是将与当前线程相关的_dispatch_once_waiter_t头插入vval列表中。然后,调用_dispatch_thread_event_wait(&dow.dow_event)阻塞当前线程。也就是说,在单例方法调用完毕前,其他要访问单例方法的线程都会被阻塞。 - 回到第一个线程的if分支中,当调用完单例方法后(
_dispatch_client_callout(ctxt, func)),会将onceToken val设置为DLOCK_ONCE_DONE,表明已经执行过一次单例方法。同时,会将val之前的值赋值给next。如果之前有其他线程进来过,根据步骤2中val的赋值,则val肯定不等于初始的tail值,而在val的链表中,保存了所有代表其他线程的_dispatch_once_waiter_t,这时候就会遍历这个链表,一次唤醒其他线程,直到next等于初始的tail为止。
dispatch_once的死锁问题
阅读了上面的源码后,会发现,dispatch_once将后进入的线程阻塞。这本是为了防止多线程并发的问题,但是也留下了一个死锁的隐患。如果在dispatch_once仍在执行时,同一线程再次调用dispatch_once方法,则会死锁。其实这本是一个递归循环调用的问题,但是由于线程阻塞的存在,就不会递归,而成了死锁:
- (void)viewDidLoad {
[super viewDidLoad];
[self once];
}
- (void)once {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
[self otherOnce];
});
NSLog(@"遇到第一只熊猫宝宝...");
}
- (void)otherOnce {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
[self once];
});
NSLog(@"遇到第二只熊猫宝宝...");
}
但是,在最新的XCode中会crash:也就是说GCD的内部实现已经更改了。

dispatch_group
当我们需要等待一批任务执行完毕时,我们可以用dispatch_group:
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t myQueue = dispatch_queue_create("com.example.MyQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t finishQueue = dispatch_queue_create("com.example.finishQueue", NULL);
dispatch_group_async(group, myQueue, ^{NSLog(@"Task 1");});
dispatch_group_async(group, myQueue, ^{NSLog(@"Task 2");});
dispatch_group_async(group, myQueue, ^{NSLog(@"Task 3");});
dispatch_group_notify(group, finishQueue, ^{
NSLog(@"All Done!");
}
我们依次来看一下调用函数的源码:
dispatch_group_create
dispatch_group_t group = dispatch_group_create();
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
static inline dispatch_group_t
_dispatch_group_create_with_count(long count)
{
// 创建一个dg
dispatch_group_t dg = (dispatch_group_t)_dispatch_object_alloc(
DISPATCH_VTABLE(group), sizeof(struct dispatch_group_s));
_dispatch_semaphore_class_init(count, dg); // 初始化dg。这里count 默认是0
if (count) {
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // dg 引用计数加一
}
return dg;
}
创建dg的时候,会创建一个dispatch_group_t 类型实例并返回,这就是我们使用的group类型,我们看一下他的定义:
struct dispatch_group_s {
DISPATCH_SEMAPHORE_HEADER(group, dg);
int volatile dg_waiters;
struct dispatch_continuation_s *volatile dg_notify_head;
struct dispatch_continuation_s *volatile dg_notify_tail;
};
DISPATCH_SEMAPHORE_HEADER是一个宏定义,表明dispatch_group_s也可以看做是一个信号量对象。
#define DISPATCH_SEMAPHORE_HEADER(cls, ns) \
DISPATCH_OBJECT_HEADER(cls); \
long volatile ns##_value; \
_dispatch_sema4_t ns##_sema
展开dispatch_group_s :
struct dispatch_group_s {
DISPATCH_OBJECT_HEADER(group);
long volatile dg_value; // 这里来记录有几个group任务
_dispatch_sema4_t dg_sema;
int volatile dg_waiters;
struct dispatch_continuation_s *volatile dg_notify_head;
struct dispatch_continuation_s *volatile dg_notify_tail;
};
dispatch_group_async
创建了group后,就可以将任务提交到group了:
dispatch_group_async(group, myQueue, ^{NSLog(@"Task 1");});
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
// 将db封装为dispatch_continuation_t,这里和dispatch_async一样的
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT | DISPATCH_OBJ_GROUP_BIT; // 相比普通的async,这里dc_flags置位了DISPATCH_OBJ_GROUP_BIT
_dispatch_continuation_init(dc, dq, db, 0, 0, dc_flags);
// 会调用这里
_dispatch_continuation_group_async(dg, dq, dc);
}
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc)
{
dispatch_group_enter(dg); // 这里将dg->dg_value +1
dc->dc_data = dg; // 将dg 存储到dc中
_dispatch_continuation_async(dq, dc); // 这里和dispatch_async是一样的调用
}
可以看到,dispatch_group_async和dispatch_async,最终都会调用到_dispatch_continuation_async。这里和dispatch_async 都是一样的逻辑,直到dc被invoke时:
static inline void
_dispatch_continuation_invoke_inline(dispatch_object_t dou, voucher_t ov,
dispatch_invoke_flags_t flags)
{
dispatch_continuation_t dc = dou._dc, dc1;
dispatch_invoke_with_autoreleasepool(flags, {
uintptr_t dc_flags = dc->dc_flags;
// Add the item back to the cache before calling the function. This
// allows the 'hot' continuation to be used for a quick callback.
//
// The ccache version is per-thread.
// Therefore, the object has not been reused yet.
// This generates better assembly.
_dispatch_continuation_voucher_adopt(dc, ov, dc_flags);
if (dc_flags & DISPATCH_OBJ_CONSUME_BIT) {
dc1 = _dispatch_continuation_free_cacheonly(dc);
} else {
dc1 = NULL;
}
if (unlikely(dc_flags & DISPATCH_OBJ_GROUP_BIT)) { // group会走这里
_dispatch_continuation_with_group_invoke(dc);
} else {
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);
_dispatch_introspection_queue_item_complete(dou);
}
if (unlikely(dc1)) {
_dispatch_continuation_free_to_cache_limit(dc1);
}
});
_dispatch_perfmon_workitem_inc();
}
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data; // 这里的dou是dispatch_group_s类型
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) {
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func); // 调用client回调
_dispatch_introspection_queue_item_complete(dou);
dispatch_group_leave((dispatch_group_t)dou); // group 任务执行完,leave group
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
}
void
dispatch_group_leave(dispatch_group_t dg)
{
long value = os_atomic_dec2o(dg, dg_value, release); // 这里将dg->dg_value -1,对应dispatch_group_enter的+1 并将新值返回给value
if (slowpath(value == 0)) { // 如果group中所有的任务都已经完成,则调用_dispatch_group_wake
return (void)_dispatch_group_wake(dg, true);
}
if (slowpath(value < 0)) { // 这里说明dispatch_group_enter / dispatch_group_leave 必须成对调用, 否则会crash
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_group_leave()");
}
}
我们看到,当group中所有的任务都已经完成时,会调用_dispatch_group_wake :
static long
_dispatch_group_wake(dispatch_group_t dg, bool needs_release)
{
dispatch_continuation_t next, head, tail = NULL;
long rval;
// cannot use os_mpsc_capture_snapshot() because we can have concurrent
// _dispatch_group_wake() calls
head = os_atomic_xchg2o(dg, dg_notify_head, NULL, relaxed);
if (head) {
// snapshot before anything is notified/woken
tail = os_atomic_xchg2o(dg, dg_notify_tail, NULL, release);
}
rval = (long)os_atomic_xchg2o(dg, dg_waiters, 0, relaxed);
if (rval) { // 如果有group等待,则唤醒线程
// wake group waiters
_dispatch_sema4_create(&dg->dg_sema, _DSEMA4_POLICY_FIFO);
_dispatch_sema4_signal(&dg->dg_sema, rval);
}
uint16_t refs = needs_release ? 1 : 0; //
if (head) {
// async group notify blocks
do { // 依次执行group 执行完毕时的回调block
next = os_mpsc_pop_snapshot_head(head, tail, do_next);
dispatch_queue_t dsn_queue = (dispatch_queue_t)head->dc_data;
_dispatch_continuation_async(dsn_queue, head);
_dispatch_release(dsn_queue);
} while ((head = next));
refs++;
}
if (refs) _dispatch_release_n(dg, refs); // 释放group
return 0;
}
上面的代码,当group中的任务全部执行完毕时,会调用_dispatch_group_wake,里面又会调用_dispatch_continuation_async(dsn_queue, head), 将group finish 时的block再次入队调用。
我们等待group结束有两种方法:
异步方法:dispatch_group_notify , 同步方法:dispatch_group_wait
我们分别来看一下他们的实现:
void
dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
// 打包db
dispatch_continuation_t dsn = _dispatch_continuation_alloc();
_dispatch_continuation_init(dsn, dq, db, 0, 0, DISPATCH_OBJ_CONSUME_BIT);
// 内部会调用私有函数 _dispatch_group_notify
_dispatch_group_notify(dg, dq, dsn);
}
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
dsn->dc_data = dq; // 将notifiy的queue放入dsn的dc_data中,用于group任务all finish时,在指定的queue中调用group finish block
dsn->do_next = NULL;
_dispatch_retain(dq);
if (os_mpsc_push_update_tail(dg, dg_notify, dsn, do_next)) { // 将当前的notify 存入到dg_notify_tail队列中,用于finish时回调group
_dispatch_retain(dg);
os_atomic_store2o(dg, dg_notify_head, dsn, ordered);
// seq_cst with atomic store to notify_head
if (os_atomic_load2o(dg, dg_value, ordered) == 0) {
_dispatch_group_wake(dg, false);
}
}
}
以上代码很简单,由于是异步执行,不需要等待,因此只需要将finish block入队到dispatch group中,等待group任务全部执行完毕在依次调用finish block即可。
下面再看一下同步group的实现:
long
dispatch_group_wait(dispatch_group_t dg, dispatch_time_t timeout)
{
if (dg->dg_value == 0) { // 如果当前group没有任何任务,直接返回
return 0;
}
if (timeout == 0) { // 如果timeout == 0, 直接返回
return _DSEMA4_TIMEOUT();
}
return _dispatch_group_wait_slow(dg, timeout);
}
static long
_dispatch_group_wait_slow(dispatch_group_t dg, dispatch_time_t timeout)
{
long value;
int orig_waiters;
// check before we cause another signal to be sent by incrementing
// dg->dg_waiters
// 在wait前,先看有没有任务在,没有,直接wake dg
value = os_atomic_load2o(dg, dg_value, ordered); // 19296565
if (value == 0) {
return _dispatch_group_wake(dg, false);
}
// 在group的dg_waiters中添加一个waiter计数
(void)os_atomic_inc2o(dg, dg_waiters, relaxed);
// check the values again in case we need to wake any threads
value = os_atomic_load2o(dg, dg_value, ordered); // 19296565
if (value == 0) {
_dispatch_group_wake(dg, false);
// Fall through to consume the extra signal, forcing timeout to avoid
// useless setups as it won't block
timeout = DISPATCH_TIME_FOREVER;
}
// 创建信号量,准备等待
_dispatch_sema4_create(&dg->dg_sema, _DSEMA4_POLICY_FIFO);
// 根据time out的值,有不同的等待策略
switch (timeout) {
default:
if (!_dispatch_sema4_timedwait(&dg->dg_sema, timeout)) { // 默认指定等待到timeout
break;
}
// Fall through and try to undo the earlier change to
// dg->dg_waiters
case DISPATCH_TIME_NOW: // 如果timeout ==0, 即不等待
orig_waiters = dg->dg_waiters;
while (orig_waiters) { // waiter 数量-1, 返回等待超时
if (os_atomic_cmpxchgvw2o(dg, dg_waiters, orig_waiters,
orig_waiters - 1, &orig_waiters, relaxed)) {
return _DSEMA4_TIMEOUT();
}
}
// Another thread is running _dispatch_group_wake()
// Fall through and drain the wakeup.
case DISPATCH_TIME_FOREVER: // 一直等
_dispatch_sema4_wait(&dg->dg_sema);
break;
}
return 0;
}
dispatch_group_wait的实现也很简单,在底层用到了信号量,同时,会在group的dg_waiters中计数加一。
参考资料
浅谈iOS多线程(源码)
源码
源代码