姿态估计&目标检测论文整理(1)
一、姿态估计
1. 现阶段人体姿态识别主流的通常有2个思路:
- Top-Down(自上而下)方法:将人体检测和关键点检测分离,在图像上首先进行人体检测,找到所有的人体框,对每个人体框图再使用关键点检测,这类方法往往比较慢,但姿态估计准确度较高。目前的主流是CPN,Hourglass,CPM,Alpha Pose等。
- Bottom-Up(自下而上)方法:先检测图像中人体部件,然后将图像中多人人体的部件分别组合成人体,因此这类方法在测试推断的时候往往更快速,准确度稍低。典型就是COCO2016年人体关键点检测冠军Open Pose。
六种人体姿态估计的深度学习模型和代码总结
2. 姿态估计标注方法
数据的基本结构是:
[{“image_id”:[],
“category_id”:[],
“keypoints”:[],
“score”:[] }]
“keypoints”是长度为3K的数组([x,y,v]),K是对某类定义的关键点总数,这里人体的keypoint就是17个.位置为[x,y],关键点可见性v. 如果关键点没有标注信息,则关键点位置[x=y=0],v=0;如果关键点有标注信息,但不可见,则可见性v=1;如果关键点在物体segment内,则认为可见v=2。

(a)17关键点
(b)18关键点
人体姿态估计数据集整理(Pose Estimation/Keypoint):
3. 评价标准
主要评价标准包括以下两种,PCK的评价标准多出现在单人的姿态估计上,多人的姿态估计评价标准基本上为mAP,比赛和学术论文中mAP成为衡量结果的必须指标。
3.1 PCK
Percentage of Correct Keypoints (PCK),reports the percentage of keypoint detection falling within a normalized distance of the ground truth.
3.2 mAP
人体骨骼关键点的评价指标类比通用的物体检测评价方式,将最终的mAP(mean Average Precision)值作为评价依据。物体检测任务中使用IoU(Intersection over Union)来评价预测与真实标注之间的差异,在人体骨骼关键点检测任务中,我们使用OKS(Object Keypoint Similarity)代替IoU,对选手预测的人体骨骼关键点位置与真实标注之间的相似性进行打分。
3.3 OKS
![]()
其中 d i d_i di是检测到的关键点与标签关键点之间的欧式距离, v i v_i vi是标签的可见性标签,s是目标尺度, k i k_i ki是每类关键点的相关控制衰减常数。每个关节点的相似度都会在 [0,1]之间,完美的预测将会得到OKS~1,预测值与真实值差距太大将会得到OKS~0
OKS指标详解
4. DeepPose:通过深度神经网络进行人体姿态估计
与同时期(2014)的其他深度学习方法一样,DeepPose在领域内带来的影响是颠覆性的:它将2D人体姿态估计问题由原本的图像处理和模板匹配问题转化为CNN图像特征提取和关键点坐标回归问题,并使用了一些回归准则来估计被遮挡/未出现的人体关节节点。
模型包括7层Alexnet和额外的回归全连接层,输出为2*关节点坐标数目,表示在二维图像中的坐标。

作者在这个CNN网络的基础上使用了一个Trick:级联回归器(Cascaded Regressors)。其思路就是针对当时浅层CNN学习到的特征尺度固定、回归性能差的问题,将网络得到的粗分回归(x, y)坐标保存,增加一个阶段:在原图中以(x, y)为中心,剪切一个区域图像,将区域图像传入CNN网络学习更高分辨率的特征,进行较高精度的坐标值回归。
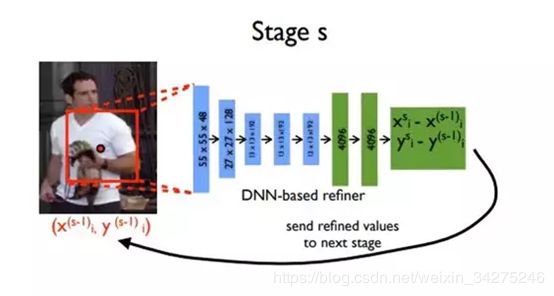
总体来说这个方法是很具有启发性的,它不仅仅首次将CNN应用于人体姿态估计,而且使用的级联回归器计算了高低分辨率的不同特征,证明人体姿态估计任务与人脸定位、瞳孔定位等普通的坐标回归任务而言更细致,需要不同图像尺度下特征的融合计算,这种思路至今仍然非常具有价值。
其主要局限性在于:1. Alexnet网络的学习能力有限;2. 直接回归2D坐标点太困难;3. 泛化能力差。
5. Stacked Hourglass:通过堆叠沙漏网络进行人体姿态估计
堆叠沙漏网络同样在2D人体姿态识别领域有着颠覆性的地位,一经提出(2016)就横扫各大比赛数据集,并且凭借简单灵活的结构获取了很多的关注和后续改进。
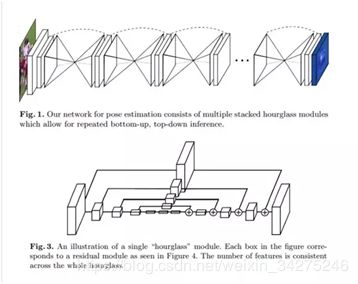
其本质上是一种加入了残差的编码器-解码器-网络,其中编码器-解码器用于提取特征、恢复尺度,而残差则用来将不同尺度的特征通融合起来,并经由上采样过程逐步进入恢复到原始特征尺寸。残差在保留原始特征的同时也解决了深层网络的梯度消失问题,使得更深的网络结构中更加抽象的特征得以被提取和计算。
这里的 “hourglass” 结构很像 FCN,结构最大的不同点就是更加对称的容量分布(包括特征从高分辨率到低分辨率,从低分辨率到高分辨率),可能其他工作,FCN 或者 holistically-nested 结构都是高分辨率到低分辨率(down-top)容量比较大(结构较复杂),低分辨率到高分辨率(top-down)就结构简单。
这里的结构也与一些做分割,样本生成,去噪自编码器,监督/半监督特征学习等的结构很像,但是操作的本质不同, “hourglass” 没有使用 unpooling 操作或者是解卷积层,而是使用了最简单的最近邻上采样和跨层连接来做 top-down(上采样)。还有一个不一样的点是,本文工作堆叠了多个 “hourglass” 的结构来构建整个网络。
2D姿态估计整理:从DeepPose到HRNet
6. DensePose
DensePose 是 Facebook开发(2018.2)的一个令人惊叹的人体实时姿势识别系统,它在 2D 图像和人体3D 模型之间建立映射,最终实现密集人群的实时姿态识别。
具体来说,DensePose 利用深度学习将 2D RPG 图像坐标映射到 3D人体表面,把一个人分割成许多 UV 贴图(UV 坐标),然后处理密集坐标,实现动态人物的精确定位和姿态估计。
Facebook公布了这一框架的代码、模型和数据集,同时发布了DensePose-COCO,这是一个为了估计人类姿态的大型真实数据集,其中包括了对5万张COCO图像手动标注的由图像到表面的对应。这对深度学习研究者来说是非常详细的资源,它对姿态估计、身体部位分割等任务提供了良好的数据源。
6.1 UV纹理贴图坐标
对于三维模型,有两个最重要的坐标系统,一是顶点的位置(X,Y,Z)坐标,另一个就是UV坐标。U和V分别是图片在显示器水平、垂直方向上的坐标,取值一般都是0~1,也 就是(水平方向的第U个像素/图片宽度,垂直方向的第V个像素/图片高度。纹理映射是把图片(或者说是纹理)映射到3D模型的一个或者多个面上。纹理可以是任何图片,使用纹理映射可以增加3D物体的真实感。每个片元(像素)都有一个对应的纹理坐标。由于三维物体表面有大有小是变化的,这意味着我们要不断更新纹理坐标。但是这在现实中很难做到。于是设定了纹理坐标空间,每维的纹理坐标范围都在[0,1]中,利用纹理坐标乘以纹理的高度或宽度就可以得到顶点在纹理上对应的纹理单元位置。纹理空间又叫UV空间。对于顶点来说,纹理坐标相对位置不变。
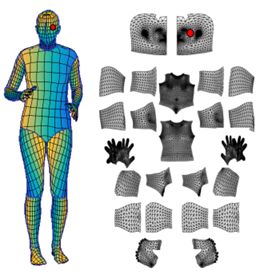
6.2 密集姿态估计
密集姿态估计的核心任务是,训练一个深度网络,用于预测 2D 图片像素 (image pixels)与 3D 表面模型点 (surface points) 之间的密集联系 (dense correspondences)。这个任务最近已经通过基于全卷积网络的 Dense Regression (DenseReg) 系统得到了解决。
在第一步中,我们将一个像素归类为属于背景或者几个区域部分中的一个,它们提供表面坐标的粗略估计,这相当于使用标准交叉熵损失进行训练的标签任务。
第二步,回归系统指出该像素在区域中的确切坐标。由于人体结构的复杂性,我们将其分解为多个独立的部分,并使用局部二维坐标系对每个部分进行参数化,以识别该表面区域上任何关键点的位置。
7. Fast Human Pose Estimation
在本研究中(2018.11),我们考虑了在不降低模型性能的情况下提高姿态估计效率的问题,但保留了可比较的精度结果。我们观察到,用于最先进的人体姿态网络(如Hourglass [19])的基本CNN构建模块在建立小型网络方面并不具有成本效益,因为每层的通道数量很多,而且难以训练。为了克服这些障碍,我们设计了一种轻量级的沙漏网络,并以知识蒸馏方式提出了一种更有效的小姿态网络训练方法[13]。我们称之为快速姿态蒸馏(Fast Pose Distillation,FPD)。与表现最佳的替代姿势方法[32,10]相比,所提出的FPD方法能够以更小的模型尺寸实现更快且更具成本效益的模型推断,同时达到人类姿势预测性能的相同水平。
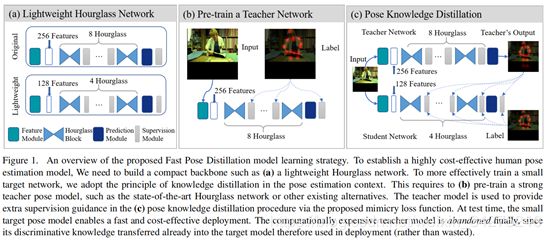
值得一提的是此处“姿态知识蒸馏”的损失函数。

通过Teacher网络的监督信息的加入,弥补了每一步训练“局部数据集”上标签错误、部分遮挡等问题,也有利于学习到Teacher网络已经从大量样本学到的关于人体姿态的先验信息。
代码:Official pytorch Code for CVPR2019 paper “Fast Human Pose Estimation”
二、目标检测
1. YOLO V1,V2,V3对比
1.1 YOLOV1
YOLO网络结构主要分为两个部分,第一部分是特征提取网络,主要是为了提取物体的通用特征,一般在ImageNet上进行预训练;第二部分是后处理网络,目的是回归出待检测物体的坐标和类别。
输入:一张图片;
输出:把每张图片分成SxS个方格,对每个方格,输出一个B5+C维的数组。其中B是该方格预测方框的数目,包含(x,y,w,h,s),s表示方框的置信度,C表示需要预测的类别数。在YOLO中,S=7, B=2,PASCAL VOC有20类,所以C=20,B5+C=30。
缺点:每个方格只能预测一类物体,对于小目标检测很难。在损失函数中,对小物体变化的置信度和大物体变化的置信度惩罚相同,实际小物体变化应该加大惩罚。
1.2 YOLOV2
添加了BN层,map提高了2%。用448x448的输入分辨率在ImageNet上进行参数微调,map提高了4%。把全连接层取消,使用anchor boxes来预测目标方框;用k-means来选择好的方框先验。对于每个方格,预测5个方框。把26x26x512的feature-map,相邻特征分到不同的channel中,因此得到13x13x2048的feature-map,与后面层进行concat,使得map提高了1%。多scale的训练,因为网络为全卷积层,所以同样的网络可以预测不同分辨率的输入,每10个batch随机选择一个新的image size。
1.3 YOLOV3
YOLO-v3在YOLO-v2的基础上进行了一些改进。
用逻辑回归对矩形框置信度进行回归,对先验与实际方框IOU大于0.5的作为正例,与SSD不同的是,若有多个先验满足目标,只取一个IOU最大的先验。
对每个类别独立地使用logistic regression,用二分类交叉熵损失作为类别损失,可以很好地处理多标签任务。
利用多个scale进行预测,实际使用3个不同的scale。将前两层的feature-map进行上采样,与开始的feature-map进行concat起来,加一些卷积层,然后进行预测。
2. YOLO V3与SSD对比

YOLOv3 为什么速度比ssd快?
1)分类器不同,ssd采用了softmax分类器。而yolov3则使用了多logistic分类器分别针对每个类进行二分类,只用设置阈值,便可以大批量筛选;
2)yolov3的默认框选取采用了聚类的方式;
3)在ssd预测时,每次预测的bbox都是在defalut bbox上基础上,预测出其偏移量。
3. SNIPER
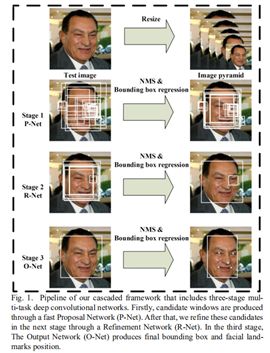
为了实现对图片上不同大小目标的检测,需要针对multi-scale提出有效方法。现在很多先进的目标检测算法,比如Faster R-CNN/Mask R-CNN,它们实现multi-scale的思路除了使用anchor的思想之外,一般还都包括一种常用的手段,那就是 image pyramid,这方法在早期的目标检测算法中是经常使用的方法。但是我们知道的,这种方法肯定会严重影响速度,不管是训练还是inference,不过但凡是用了这种方法的一般都是为了追求高精度,而暂时不注重速度。
image pyramid 影响速度的原因也很明了,每一个scale的图片的所有像素都参与了后续的计算。比如一个3scale的image pyramid(分别是原图的1倍,2倍,3倍),它要处理相当于原图14倍的像素.
在CVPR2018上有这样一篇文章,An Analysis of Scale Invariance in Object Detection。这篇文章分析了小尺度与预训练模型尺度之间的关系, 并且提出了一个和 Cascade R-CNN 有异曲同工之妙的中心思想: 要让输入分布接近模型预训练的分布(本文主要探讨尺度的分布不一致带来的问题). 之后利用分析的结论, 提出了一个多尺度训练(MST)的升级版:Scale Normalization for Image Pyramids (SNIP)
SNIP借鉴了Multi-Scale Training(MST)的思想,在MST方法中,由于训练数据中尺寸极大或极小的目标会影响实验结果,因此SNIP的做法就是只对尺寸在指定范围内的目标回传损失(该范围需接近预训练模型的训练数据尺寸),也就是说训练过程实际上只是针对这些目标进行的,这样就能减少domain-shift带来的影响。又因为训练过程采用了类似MST的做法,所以每个目标在训练时都会有几个不同的尺寸,那么总有一个尺寸在指定的尺寸范围内。

代码:SNIPER
4. CornerNet
这篇发表在ECCV2018上的目标检测文章给人一种眼前一亮的感觉,
1、将目标检测问题当作关键点检测问题来解决,也就是通过检测目标框的左上角和右下角两个关键点得到预测框,因此CornerNet算法中没有anchor的概念,这种做法在目标检测领域是比较创新的而且能够取得不错效果是很难的。
2、整个检测网络的训练是从头开始的,并不基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。

4.1 anchor机制的缺点
目前大部分常用的目标检测算法都是基于anchor的,比如Faster RCNN系列,SSD,YOLO(v2、v3)等,引入anchor后检测效果提升确实比较明显(比如YOLO v1和YOLO v2),但是引入anchor的缺点在于:
1、正负样本不均衡。大部分检测算法的anchor数量都成千上万,但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及focal loss等算法来解决这个问题。
2、引入更多的超参数,比如anchor的数量、大小和宽高比等。
4.2 创新点
论文的第一个创新是讲目标检测上升到方法论,基于多人姿态估计的Bottom-Up思想,首先同时预测定位框的顶点对(左上角和右下角)热点图和embedding vector,根据embedding vector对顶点进行分组。
论文第二个创新是提出了corner pooling用于定位顶点。自然界的大部分目标是没有边界框也不会有矩形的顶点,依top-left corner pooling 为例,对每个channel,分别提取特征图的水平和垂直方向的最大值,然后求和。
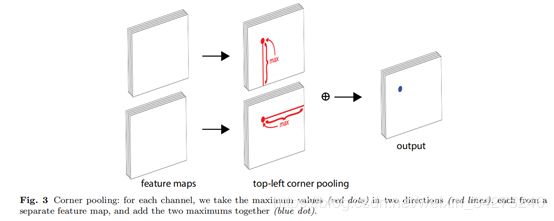
论文的第三个创新是模型基于hourglass架构,使用focal loss[5]的变体训练神经网络。

代码:CornerNet
5. TridentNet
图像金字塔和特征金字塔本质上都是希望不同尺度的目标有不同的感受野,这样提取到的特征才比较全面,因此TridentNet算法(2019.6)从感受野入手,通过引入空洞卷积增加网络的感受野,从而实现不同尺度目标的检测。
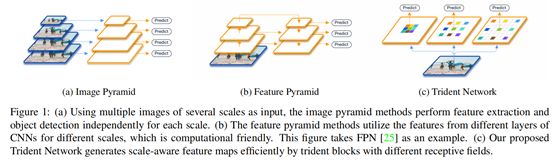
5.1 感受野和检测效果之间到底存在什么关系?
作者做了一个关于感受野和检测效果之间的联系的对比实验,实验结果如Table1所示。这个实验通过修改Faster RCNN算法的特征提取网络中卷积层的dilation参数控制感受野大小,当dilation参数为1时等效于常规卷积层。可以看出不同尺度目标的最高AP值对应的dilation参数(也就是不同感受野)是不同的,而且存在明显的规律,这说明针对目标尺度大小设计对应的感受野可以使检测模型的整体效果达到最佳,这也是TridentNet算法的主要思想。
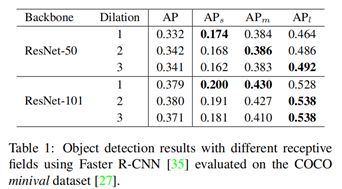
5.2 改进点
- 第1个改进点是将原本特征提取网络(backbone)的单支路卷积层替换成3个支路且dilated参数不同的dilated卷积层,这就是论文中提到的多分枝(multi-branch)思想。以特征提取网络ResNet为例,就是将residual block中的3×3卷积层替换成Figure2中的3支路3×3卷积层,dilated参数分别为1、2、3。
- 第2个改进点是权重共享(weight sharing among branches),是指3个支路的卷积层参数是共享的(差别仅在于dilated参数),这么做的原因是一方面可以减少网络前向计算的时间,另一方面网络学到的参数有更好的泛化能力。还有一个好处在于inference,文中提到了一种快速inference做法:选择一个分支的输出作为最终结果,假如没有权重共享,那么单分支的结果很难近似多分支结果。
- 第3个改进点是指定尺度过滤训练(scale-aware training scheme),是指不同dilated参数的3个支路分别检测不同尺度的目标。还记得Table1的实验结果吗?不同尺度的目标所对应的网络最佳感受野是不同的,因此可以为这3条支路分配不同尺度的目标(和SNIP的思想有点类似),比如对于dalated参数为3的支路而言,感受野更大,大尺度目标的检测效果好,因此就分配尺度较大的目标,实现上可以通过判断RoI的尺寸后将尺度符合定义的目标输入该支路进行训练。这种方法减少了每条支路所训练的目标尺寸差异,虽然训练样本也少了,但由于权重是共享的,所以效果不会下降。
5.3 空洞卷积
空洞卷积(atrous convolutions)又名扩张卷积(dilated convolutions),向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。
该结构的目的是在不用pooling(pooling层会导致信息损失)且计算量相当的情况下,提供更大的感受野。
空洞卷积(Dilated convolutions)在卷积的时候,会在卷积核元素之间塞入空格。
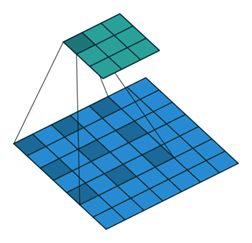
普通卷积主要问题
- Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)内部数据结构丢失;
- 空间层级化信息丢失;
- 小物体信息无法重建 (假设有四个pooling layer则任何小于 2^4 = 16 pixel的物体信息将理论上无法重建。)在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度,而dilated convolution 的设计就良好的避免了这些问题。
而空洞卷积就有内部数据结构的保留和避免使用 down-sampling 这样的特性,优点明显。
代码: simpledet
三、人脸识别
绝大多数人脸识别都包含如下几个流程:人脸检测(Face Detection)、人脸对齐(Face Alignment)、人脸表示(Face Representation)和人脸匹配(Face Matching)。
![]()
3.1 人脸检测
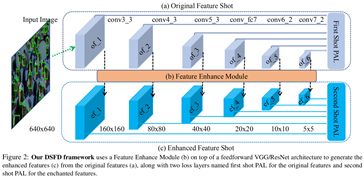
3.1.1 DSFD: Dual Shot Face Detector
3.1.2 Joint Face Detection and Facial Motion Retargeting for Multiple Faces