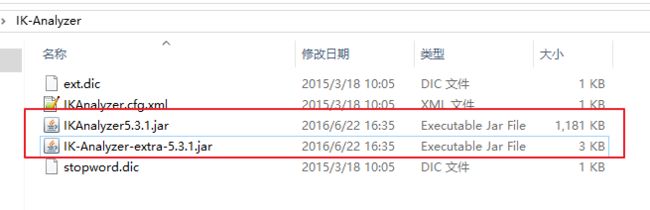
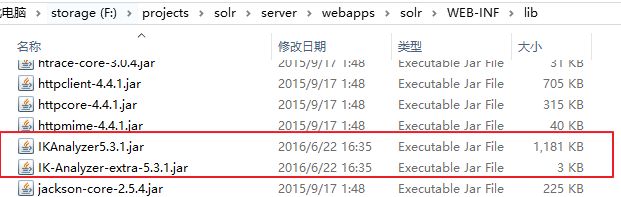
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- 探索OpenAI和LangChain的适配器集成:轻松切换模型提供商
nseejrukjhad
langchaineasyui前端python
#探索OpenAI和LangChain的适配器集成:轻松切换模型提供商##引言在人工智能和自然语言处理的世界中,OpenAI的模型提供了强大的能力。然而,随着技术的发展,许多人开始探索其他模型以满足特定需求。LangChain作为一个强大的工具,集成了多种模型提供商,通过提供适配器,简化了不同模型之间的转换。本篇文章将介绍如何使用LangChain的适配器与OpenAI集成,以便轻松切换模型提供商
- 利用LangChain的StackExchange组件实现智能问答系统
nseejrukjhad
langchainmicrosoft数据库python
利用LangChain的StackExchange组件实现智能问答系统引言在当今的软件开发世界中,StackOverflow已经成为程序员解决问题的首选平台之一。而LangChain作为一个强大的AI应用开发框架,提供了StackExchange组件,使我们能够轻松地将StackOverflow的海量知识库集成到我们的应用中。本文将详细介绍如何使用LangChain的StackExchange组件
- MongoDB Oplog 窗口
喝醉酒的小白
MongoDB运维
在MongoDB中,oplog(操作日志)是一个特殊的日志系统,用于记录对数据库的所有写操作。oplog允许副本集成员(通常是从节点)应用主节点上已经执行的操作,从而保持数据的一致性。它是MongoDB副本集实现数据复制的基础。MongoDBOplog窗口oplog窗口是指在MongoDB副本集中,从节点可以用来同步数据的时间范围。这个窗口通常由以下因素决定:Oplog大小:oplog的大小是有限
- CX8903:Ebike自行车仪表电源方案开发,Ebike智能仪表电源芯片
诚芯微科技
社交电子
CX8903:电动Ebike自行车仪表电源方案开发,Ebike智能仪表电源芯片推荐。电动助力自行车EBIKE凭借其环保、健康、低噪、和便捷等特点,成为了越来越受欢迎的骑行便利交通工具。提供电动Ebike自行车仪表电源方案开发、E-BIKE电动助力自行车仪表供电电源解决方案。CX8903采用100V高压制造工艺(芯片最高耐压可到100V以上),SOP-8L贴片封装,CX8903内置100V/90mΩ
- 数据仓库——维度表一致性
墨染丶eye
背诵数据仓库
数据仓库基础笔记思维导图已经整理完毕,完整连接为:数据仓库基础知识笔记思维导图维度一致性问题从逻辑层面来看,当一系列星型模型共享一组公共维度时,所涉及的维度称为一致性维度。当维度表存在不一致时,短期的成功难以弥补长期的错误。维度时确保不同过程中信息集成起来实现横向钻取货活动的关键。造成横向钻取失败的原因维度结构的差别,因为维度的差别,分析工作涉及的领域从简单到复杂,但是都是通过复杂的报表来弥补设计
- Low Power概念介绍-Voltage Area
飞奔的大虎
随着智能手机,以及物联网的普及,芯片功耗的问题最近几年得到了越来越多的重视。为了实现集成电路的低功耗设计目标,我们需要在系统设计阶段就采用低功耗设计的方案。而且,随着设计流程的逐步推进,到了芯片后端设计阶段,降低芯片功耗的方法已经很少了,节省的功耗百分比也不断下降。芯片的功耗主要由静态功耗(staticleakagepower)和动态功耗(dynamicpower)构成。静态功耗主要是指电路处于等
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- (179)时序收敛--->(29)时序收敛二九
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛二九(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)
- (180)时序收敛--->(30)时序收敛三十
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛三十(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)
- (158)时序收敛--->(08)时序收敛八
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛八(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)F
- (159)时序收敛--->(09)时序收敛九
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛九(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)F
- (160)时序收敛--->(10)时序收敛十
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛十(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)F
- (153)时序收敛--->(03)时序收敛三
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛三(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)F
- (121)DAC接口--->(006)基于FPGA实现DAC8811接口
FPGA系统设计指南针
FPGA接口开发(项目实战)fpga开发FPGAIC
1目录(a)FPGA简介(b)IC简介(c)Verilog简介(d)基于FPGA实现DAC8811接口(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电
- FPGA复位专题---(3)上电复位?
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发
(3)上电复位?1目录(a)FPGA简介(b)Verilog简介(c)复位简介(d)上电复位?(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限
- (182)时序收敛--->(32)时序收敛三二
FPGA系统设计指南针
FPGA系统设计(内训)fpga开发时序收敛
1目录(a)FPGA简介(b)Verilog简介(c)时钟简介(d)时序收敛三二(e)结束1FPGA简介(a)FPGA(FieldProgrammableGateArray)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。(b)
- Python神器!WEB自动化测试集成工具 DrissionPage
亚丁号
python开发语言
一、前言用requests做数据采集面对要登录的网站时,要分析数据包、JS源码,构造复杂的请求,往往还要应付验证码、JS混淆、签名参数等反爬手段,门槛较高。若数据是由JS计算生成的,还须重现计算过程,体验不好,开发效率不高。使用浏览器,可以很大程度上绕过这些坑,但浏览器运行效率不高。因此,这个库设计初衷,是将它们合而为一,能够在不同须要时切换相应模式,并提供一种人性化的使用方法,提高开发和运行效率
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- 光盘文件系统 (iso9660) 格式解析
穷人小水滴
光盘文件系统iso9660denoGNU/Linuxjavascript
越简单的系统,越可靠,越不容易出问题.光盘文件系统(iso9660)十分简单,只需不到200行代码,即可实现定位读取其中的文件.参考资料:https://wiki.osdev.org/ISO_9660相关文章:《光盘防水嘛?DVD+R刻录光盘泡水实验》https://blog.csdn.net/secext2022/article/details/140583910《光驱的内部结构及日常使用》ht
- 基于STM32的汽车仪表显示系统:集成CAN、UART与I2C总线设计流程
极客小张
stm32汽车嵌入式硬件物联网单片机c语言
一、项目概述项目目标与用途本项目旨在设计和实现一个基于STM32微控制器的汽车仪表显示系统。该系统能够实时显示汽车的速度、转速、油量等关键信息,并通过CAN总线与其他汽车控制单元进行通信。这种仪表显示系统不仅提高了驾驶的安全性和便捷性,还能为汽车提供更智能的用户体验。技术栈关键词微控制器:STM32显示技术:TFTLCD/OLED传感器:速度传感器、温度传感器、油量传感器通信协议:CAN总线、UA
- 02-Cesium聚合分析EntityCluster完整代码
fxshy
htmlcssjavascript
1.完整代码Document-->-->Cesium.Ion.defaultAccessToken='eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJhZjZkZDAwZC1mNTFhLTRhOTEtOGExNi00MzRhNGIzMDdlNDQiLCJpZCI6MTA1MTUzLCJpYXQiOjE2NjA4MDg0Njd9.qajeJtc4-kp
- 03-Cesium自定义着色器完整代码以及注释
fxshy
着色器javascript
1.效果展示2.完整代码自定义着色器完整代码#map{position:absolute;width:100%;height:100%;top:0;left:0;right:0;bottom:0;}Cesium.Ion.defaultAccessToken='eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJhZjZkZDAwZC1mNTFhLTRhO
- 【算法练习】IDEA集成leetcode插件实现快速刷
2401_84102892
2024年程序员学习算法intellij-idealeetcode
============点击右侧边leetcode->设置->配置地址、用户名、密码、存放目录、文件模板用户名要登录后在账号信息里看模板代码1.codefilename!velocityTool.camelC
- 信息系统安全相关概念(上)
YuanDaima2048
课程笔记基础概念安全信息安全笔记
文章总览:YuanDaiMa2048博客文章总览下篇:信息系统安全相关概念(下)信息系统安全相关概念[上]信息系统概述信息系统信息系统架构信息系统发展趋势:信息系统日趋大型化、复杂化信息系统面临的安全威胁信息系统安全架构设计--以云计算为例信息系统安全需求及安全策略自主访问控制策略DAC强制访问控制策略MAC信息系统概述信息系统用于收集、存储和处理数据以及传递信息、知识和数字产品的一组集成组件。几
- 《Veronika decides to die》
Ooutstanding
Whatismadness?——Madnessistheinabilitytocommunicate.Betweennormalityandmadness,whicharebasicallythesamething,thereexistsanintermediarystage:itiscalled"beingdifferent."Andpeoplewerebecomingmoreandmoreaf
- ansible的安装、使用
ytym00
简介高度模块化,调用特定的模块,完成特定的任务,基于Yaml,来完成批量任务的模板化,来支持playbook。基于Python语言实现,主要使用Paramiko、PyYAML和JinJa2三个关键模块,部署简单(agentless),主从模式,支持自定义模块,支持playbook,幂等性:允许重复执行N次,没有变化时,只会执行第一次。特点:1、Configuration(cfengine,chef
- 大牛:新型电动汽车电池技术问世! 可将电池能量密度提高2倍成本降一半
38cc8b780dc0
据外媒报道,当地时间6月10日,电动汽车电池技术领导者OneDBatterySciences宣布推出一项可为下一代电动汽车电池提供动力的突破性技术——SINANODE。对于电动汽车行业而言,打造含有更多硅的电池一直是一个挑战,而SINANODE无缝集成至现有的生产工艺中,让硅纳米线与商用石墨粉末融合,将电池阳极的能量密度提高了两倍,但是将每kWh的成本降低了一半。能量密度更高可以让电池的续航更长,
- 一部手机就能操作的10种赚钱方式,看看哪种适合你?
氧惠全网优惠
手机已经成为了我们生活中不可或缺的一部分,拿着手机刷分享赚钱已经成为了不少人的日常。今天,我想和大家分享一下手机赚钱的10种好方法。京东密令红包:最爱领红包828红包多多148今天给大家分享我长期在做的副业,也在这里赚到人生第3桶金!氧惠APP佣金高,资质靠谱,各大应用市场均可搜索使用。【氧惠】氧惠app是杭州长孚科技有限公司旗下一款新开发电商导购应用,为用户打造一个集成电商购物优惠佣金平台,公司
- 2018-08-16【Swift 4.1】 关于Swift4.0以后调用MJExtension无法模型转换问题
码农happy
1、本人使用swift4.1,弄了一晚上才弄好,结果还是一个小问题真是尴尬,要在model中每个属性前面加上@objcimportUIKitclassUserModel:NSObject{@objcvardix=String()}letdic=["dix":"ffffff"]asNSDictionaryletmodel=UserModel.mj_object(withKeyValues:dic)!
- jsonp 常用util方法
hw1287789687
jsonpjsonp常用方法jsonp callback
jsonp 常用java方法
(1)以jsonp的形式返回:函数名(json字符串)
/***
* 用于jsonp调用
* @param map : 用于构造json数据
* @param callback : 回调的javascript方法名
* @param filters : <code>SimpleBeanPropertyFilter theFilt
- 多线程场景
alafqq
多线程
0
能不能简单描述一下你在java web开发中需要用到多线程编程的场景?0
对多线程有些了解,但是不太清楚具体的应用场景,能简单说一下你遇到的多线程编程的场景吗?
Java多线程
2012年11月23日 15:41 Young9007 Young9007
4
0 0 4
Comment添加评论关注(2)
3个答案 按时间排序 按投票排序
0
0
最典型的如:
1、
- Maven学习——修改Maven的本地仓库路径
Kai_Ge
maven
安装Maven后我们会在用户目录下发现.m2 文件夹。默认情况下,该文件夹下放置了Maven本地仓库.m2/repository。所有的Maven构件(artifact)都被存储到该仓库中,以方便重用。但是windows用户的操作系统都安装在C盘,把Maven仓库放到C盘是很危险的,为此我们需要修改Maven的本地仓库路径。
- placeholder的浏览器兼容
120153216
placeholder
【前言】
自从html5引入placeholder后,问题就来了,
不支持html5的浏览器也先有这样的效果,
各种兼容,之前考虑,今天测试人员逮住不放,
想了个解决办法,看样子还行,记录一下。
【原理】
不使用placeholder,而是模拟placeholder的效果,
大概就是用focus和focusout效果。
【代码】
<scrip
- debian_用iso文件创建本地apt源
2002wmj
Debian
1.将N个debian-506-amd64-DVD-N.iso存放于本地或其他媒介内,本例是放在本机/iso/目录下
2.创建N个挂载点目录
如下:
debian:~#mkdir –r /media/dvd1
debian:~#mkdir –r /media/dvd2
debian:~#mkdir –r /media/dvd3
….
debian:~#mkdir –r /media
- SQLSERVER耗时最长的SQL
357029540
SQL Server
对于DBA来说,经常要知道存储过程的某些信息:
1. 执行了多少次
2. 执行的执行计划如何
3. 执行的平均读写如何
4. 执行平均需要多少时间
列名 &
- com/genuitec/eclipse/j2eedt/core/J2EEProjectUtil
7454103
eclipse
今天eclipse突然报了com/genuitec/eclipse/j2eedt/core/J2EEProjectUtil 错误,并且工程文件打不开了,在网上找了一下资料,然后按照方法操作了一遍,好了,解决方法如下:
错误提示信息:
An error has occurred.See error log for more details.
Reason:
com/genuitec/
- 用正则删除文本中的html标签
adminjun
javahtml正则表达式去掉html标签
使用文本编辑器录入文章存入数据中的文本是HTML标签格式,由于业务需要对HTML标签进行去除只保留纯净的文本内容,于是乎Java实现自动过滤。
如下:
public static String Html2Text(String inputString) {
String htmlStr = inputString; // 含html标签的字符串
String textSt
- 嵌入式系统设计中常用总线和接口
aijuans
linux 基础
嵌入式系统设计中常用总线和接口
任何一个微处理器都要与一定数量的部件和外围设备连接,但如果将各部件和每一种外围设备都分别用一组线路与CPU直接连接,那么连线
- Java函数调用方式——按值传递
ayaoxinchao
java按值传递对象基础数据类型
Java使用按值传递的函数调用方式,这往往使我感到迷惑。因为在基础数据类型和对象的传递上,我就会纠结于到底是按值传递,还是按引用传递。其实经过学习,Java在任何地方,都一直发挥着按值传递的本色。
首先,让我们看一看基础数据类型是如何按值传递的。
public static void main(String[] args) {
int a = 2;
- ios音量线性下降
bewithme
ios音量
直接上代码吧
//second 几秒内下降为0
- (void)reduceVolume:(int)second {
KGVoicePlayer *player = [KGVoicePlayer defaultPlayer];
if (!_flag) {
_tempVolume = player.volume;
- 与其怨它不如爱它
bijian1013
选择理想职业规划
抱怨工作是年轻人的常态,但爱工作才是积极的心态,与其怨它不如爱它。
一般来说,在公司干了一两年后,不少年轻人容易产生怨言,除了具体的埋怨公司“扭门”,埋怨上司无能以外,也有许多人是因为根本不爱自已的那份工作,工作完全成了谋生的手段,跟自已的性格、专业、爱好都相差甚远。
- 一边时间不够用一边浪费时间
bingyingao
工作时间浪费
一方面感觉时间严重不够用,另一方面又在不停的浪费时间。
每一个周末,晚上熬夜看电影到凌晨一点,早上起不来一直睡到10点钟,10点钟起床,吃饭后玩手机到下午一点。
精神还是很差,下午像一直野鬼在城市里晃荡。
为何不尝试晚上10点钟就睡,早上7点就起,时间完全是一样的,把看电影的时间换到早上,精神好,气色好,一天好状态。
控制让自己周末早睡早起,你就成功了一半。
有多少个工作
- 【Scala八】Scala核心二:隐式转换
bit1129
scala
Implicits work like this: if you call a method on a Scala object, and the Scala compiler does not see a definition for that method in the class definition for that object, the compiler will try to con
- sudoku slover in Haskell (2)
bookjovi
haskellsudoku
继续精简haskell版的sudoku程序,稍微改了一下,这次用了8行,同时性能也提高了很多,对每个空格的所有解不是通过尝试算出来的,而是直接得出。
board = [0,3,4,1,7,0,5,0,0,
0,6,0,0,0,8,3,0,1,
7,0,0,3,0,0,0,0,6,
5,0,0,6,4,0,8,0,7,
- Java-Collections Framework学习与总结-HashSet和LinkedHashSet
BrokenDreams
linkedhashset
本篇总结一下两个常用的集合类HashSet和LinkedHashSet。
它们都实现了相同接口java.util.Set。Set表示一种元素无序且不可重复的集合;之前总结过的java.util.List表示一种元素可重复且有序
- 读《研磨设计模式》-代码笔记-备忘录模式-Memento
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
/*
* 备忘录模式的功能是,在不破坏封装性的前提下,捕获一个对象的内部状态,并在对象之外保存这个状态,为以后的状态恢复作“备忘”
- 《RAW格式照片处理专业技法》笔记
cherishLC
PS
注意,这不是教程!仅记录楼主之前不太了解的
一、色彩(空间)管理
作者建议采用ProRGB(色域最广),但camera raw中设为ProRGB,而PS中则在ProRGB的基础上,将gamma值设为了1.8(更符合人眼)
注意:bridge、camera raw怎么设置显示、输出的颜色都是正确的(会读取文件内的颜色配置文件),但用PS输出jpg文件时,必须先用Edit->conv
- 使用 Git 下载 Spring 源码 编译 for Eclipse
crabdave
eclipse
使用 Git 下载 Spring 源码 编译 for Eclipse
1、安装gradle,下载 http://www.gradle.org/downloads
配置环境变量GRADLE_HOME,配置PATH %GRADLE_HOME%/bin,cmd,gradle -v
2、spring4 用jdk8 下载 https://jdk8.java.
- mysql连接拒绝问题
daizj
mysql登录权限
mysql中在其它机器连接mysql服务器时报错问题汇总
一、[running]
[email protected]:~$mysql -uroot -h 192.168.9.108 -p //带-p参数,在下一步进行密码输入
Enter password: //无字符串输入
ERROR 1045 (28000): Access
- Google Chrome 为何打压 H.264
dsjt
applehtml5chromeGoogle
Google 今天在 Chromium 官方博客宣布由于 H.264 编解码器并非开放标准,Chrome 将在几个月后正式停止对 H.264 视频解码的支持,全面采用开放的 WebM 和 Theora 格式。
Google 在博客上表示,自从 WebM 视频编解码器推出以后,在性能、厂商支持以及独立性方面已经取得了很大的进步,为了与 Chromium 现有支持的編解码器保持一致,Chrome
- yii 获取控制器名 和方法名
dcj3sjt126com
yiiframework
1. 获取控制器名
在控制器中获取控制器名: $name = $this->getId();
在视图中获取控制器名: $name = Yii::app()->controller->id;
2. 获取动作名
在控制器beforeAction()回调函数中获取动作名: $name =
- Android知识总结(二)
come_for_dream
android
明天要考试了,速速总结如下
1、Activity的启动模式
standard:每次调用Activity的时候都创建一个(可以有多个相同的实例,也允许多个相同Activity叠加。)
singleTop:可以有多个实例,但是不允许多个相同Activity叠加。即,如果Ac
- 高洛峰收徒第二期:寻找未来的“技术大牛” ——折腾一年,奖励20万元
gcq511120594
工作项目管理
高洛峰,兄弟连IT教育合伙人、猿代码创始人、PHP培训第一人、《细说PHP》作者、软件开发工程师、《IT峰播》主创人、PHP讲师的鼻祖!
首期现在的进程刚刚过半,徒弟们真的很棒,人品都没的说,团结互助,学习刻苦,工作认真积极,灵活上进。我几乎会把他们全部留下来,现在已有一多半安排了实际的工作,并取得了很好的成绩。等他们出徒之日,凭他们的能力一定能够拿到高薪,而且我还承诺过一个徒弟,当他拿到大学毕
- linux expect
heipark
expect
1. 创建、编辑文件go.sh
#!/usr/bin/expect
spawn sudo su admin
expect "*password*" { send "13456\r\n" }
interact
2. 设置权限
chmod u+x go.sh 3.
- Spring4.1新特性——静态资源处理增强
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- idea ubuntuxia 乱码
liyonghui160com
1.首先需要在windows字体目录下或者其它地方找到simsun.ttf 这个 字体文件。
2.在ubuntu 下可以执行下面操作安装该字体:
sudo mkdir /usr/share/fonts/truetype/simsun
sudo cp simsun.ttf /usr/share/fonts/truetype/simsun
fc-cache -f -v
- 改良程序的11技巧
pda158
技巧
有很多理由都能说明为什么我们应该写出清晰、可读性好的程序。最重要的一点,程序你只写一次,但以后会无数次的阅读。当你第二天回头来看你的代码 时,你就要开始阅读它了。当你把代码拿给其他人看时,他必须阅读你的代码。因此,在编写时多花一点时间,你会在阅读它时节省大量的时间。
让我们看一些基本的编程技巧:
尽量保持方法简短
永远永远不要把同一个变量用于多个不同的
- 300个涵盖IT各方面的免费资源(下)——工作与学习篇
shoothao
创业免费资源学习课程远程工作
工作与生产效率:
A. 背景声音
Noisli:背景噪音与颜色生成器。
Noizio:环境声均衡器。
Defonic:世界上任何的声响都可混合成美丽的旋律。
Designers.mx:设计者为设计者所准备的播放列表。
Coffitivity:这里的声音就像咖啡馆里放的一样。
B. 避免注意力分散
Self Co
- 深入浅出RPC
uule
rpc
深入浅出RPC-浅出篇
深入浅出RPC-深入篇
RPC
Remote Procedure Call Protocol
远程过程调用协议
它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发