2019独角兽企业重金招聘Python工程师标准>>> 
一:简介
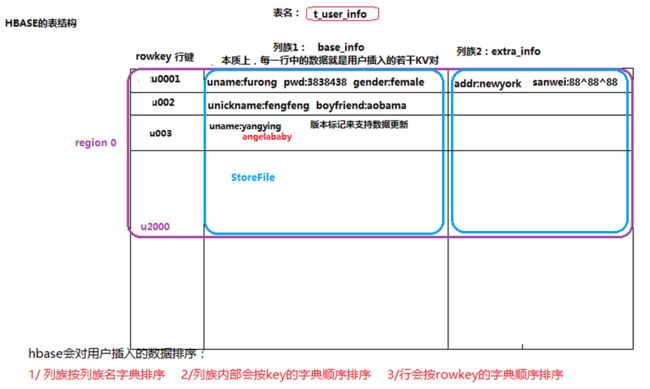
1、hbase是一个“列式存储”的nosql数据库,有如下特点
-
支持单表上百亿行,数百万列的存储以及实时查询
-
它支持表中某行数据的字段可以动态增加和减少,也就是不需要所有行数据字段个数一致,也不需要像关系型数据库那样事先定义表的schame信息。
-
经常用于字段动态改变的一些场景。
2、hbase表的几个概念
-
行键rowkey
用于唯一表示一条数据,所以表中的rowkey必须保证唯一,通过rowKey查询非常快,一般使用数据中的某几个关键查询字段拼接而成。这样就可以使用rowKey进行条件组合查询。
-
列族Family
hbase将每条数据的字段归属于不同的列族以方便管理,比如:userName、passwd、age字段归属于base_info列族,interests归属于extra_info列族。每个列族在内存中体现为一个store来管理。
-
单元格cell
数据的每个字段叫做cell,它是归属于列族的,所以插入和查询的时候都需要带上列族来组合。所以会发现单元格可以随意增加,只需要指定列族即可。
-
版本号version
因为cell值需要被经常修改,而hbase又不想直接把原来的值给替换掉,所以形成了版本号。版本号是针对列族而言的,表示此列族下的每个cell要保存多少个版本。版本号一般用时间戳timestamp来表示
二:Hbase shell操作
DDL
-
1、查看表 --> list
-
2、 创建表 --> 指定列族,列族版本数
create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2} -
3、删除表 --> 先disable再删除
disable 't1' drop 't1' -
4、查看表的结构
describe 't1' -
5、修改表结构
disable 'test1' alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'} enable 'test1'
DML
-
1、插入数据 --> put
put 't1','rowkey001','f1:col1','value01' -
2、查询数据 --> get
get 't1', 'rowkey001' get 't1', 'rowkey001', 'f1:coll' -
3、扫描表 --> scan 't1'
-
4、删除数据
deleteall 't1','rowkey001' --> 删除一条数据 deleteall 't1' --> 删除整表数据
三:Hbase Java api
package com.bigdata.storage.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.regionserver.BloomType;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
/**
* hbase ddl、dml、filter等操作
*
* [@Author](https://my.oschina.net/arthor) liufu
*/
public class HbaseClientTest {
private static final Logger logger = LoggerFactory.getLogger(HbaseClientTest.class);
private Connection conn;
[@Before](https://my.oschina.net/u/3870904)
public void init() throws Exception {
/**
* HBaseConfiguration.create()
* 会调用Hadoop的Configuration加载core-site.xml、hdfs-site.xml
* 然后在加载hbase-site.xml
* 这三个文件在jar包中有默认的值,但是没法和集群对应上,有两中方法:
* 1、所以需要将集群中的这三个文件copy下来放到本工程的resources目录下被加载即可
* 2、创建好conf之后,设置zookeeper地址,因为只要知道了zookeeper就可以连接hbase
* 注意:client只和zookeeper以及regainServer交互,不和Hmaster交互
*/
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "rzx168:2181");
try {
conn = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
logger.error("创建hbase连接失败", e);
}
}
/**
* DDL:建表
*
* [@throws](https://my.oschina.net/throws) Exception
*/
[@Test](https://my.oschina.net/azibug)
public void testCreate() throws Exception {
// 获取一个表管理器
Admin admin = conn.getAdmin();
// 构造一个表描述器,并指定表名
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf("t_user_info"));
// 构造一个列族描述器,并指定列族名
HColumnDescriptor hcd1 = new HColumnDescriptor("base_info");
// 为该列族设定一个布隆过滤器类型参数/版本数量
hcd1.setBloomFilterType(BloomType.ROW).setVersions(1, 3);
// 构造第二个列族描述器,并指定列族名
HColumnDescriptor hcd2 = new HColumnDescriptor("extra_info");
hcd2.setBloomFilterType(BloomType.ROW).setVersions(1, 3);
// 将列族描述器添加到表描述器中
htd.addFamily(hcd1).addFamily(hcd2);
admin.createTable(htd);
admin.close();
conn.close();
}
/**
* 删除表
*
* [@throws](https://my.oschina.net/throws) Exception
*/
@Test
public void testDrop() throws Exception {
Admin admin = conn.getAdmin();
//先disable才能进行delete
admin.disableTable(TableName.valueOf("t_user_info"));
admin.deleteTable(TableName.valueOf("t_user_info"));
admin.close();
conn.close();
}
/**
* 修改表定义(schema)
*
* @throws Exception
*/
@Test
public void testModify() throws Exception {
Admin admin = conn.getAdmin();
// 修改已有的ColumnFamily
HTableDescriptor table = admin.getTableDescriptor(TableName.valueOf("t_user_info"));
HColumnDescriptor f2 = table.getFamily("extra_info".getBytes());
f2.setBloomFilterType(BloomType.ROWCOL);
// 添加新的ColumnFamily
table.addFamily(new HColumnDescriptor("other_info"));
admin.modifyTable(TableName.valueOf("t_user_info"), table);
admin.close();
conn.close();
}
/**
* 插入、修改 数据 DML
* 如果插入的行对应的字段已经存在,则会修改,以版本来记录以前的值
*
* @throws Exception
*/
@Test
public void testPut() throws Exception {
Table table = conn.getTable(TableName.valueOf("t_user_info"));
ArrayList puts = new ArrayList();
// 构建一个put对象(kv),指定其行键
Put put01 = new Put(Bytes.toBytes("user001"));
put01.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhangsan"));
Put put02 = new Put("user001".getBytes());
put02.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("password"), Bytes.toBytes("123456"));
Put put03 = new Put("user002".getBytes());
put03.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("lisi"));
put03.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put04 = new Put("zhang_sh_01".getBytes());
put04.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang01"));
put04.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put05 = new Put("zhang_sh_02".getBytes());
put05.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang02"));
put05.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put06 = new Put("liu_sh_01".getBytes());
put06.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("liu01"));
put06.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put07 = new Put("zhang_bj_01".getBytes());
put07.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang03"));
put07.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put08 = new Put("zhang_bj_01".getBytes());
put08.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang04"));
put08.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
puts.add(put01);
puts.add(put02);
puts.add(put03);
puts.add(put04);
puts.add(put05);
puts.add(put06);
puts.add(put07);
puts.add(put08);
table.put(puts);
table.close();
conn.close();
}
/**
* 读取数据 ---get,指定rowkey
* 可以一次读一行,也可以一次读取一批
* 一般结合ES存储索引字段,以及对应的rowKey
* 通过ES查询得到的rowKey,然后一次性从hbase中查询
*
* @throws Exception
*/
@Test
public void testGet() throws Exception {
Table table = conn.getTable(TableName.valueOf("t_user_info"));
// 构造一个get查询参数对象,指定要get的是哪一行
Get get = new Get("user001".getBytes());
Result result = table.get(get);
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell current = cellScanner.current();
byte[] familyArray = current.getFamilyArray();
byte[] qualifierArray = current.getQualifierArray();
byte[] valueArray = current.getValueArray();
System.out.print(new String(familyArray, current.getFamilyOffset(), current.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, current.getQualifierOffset(), current.getQualifierLength()));
System.out.println(" " + new String(valueArray, current.getValueOffset(), current.getValueLength()));
}
table.close();
conn.close();
}
/**
* 删除某rowkey的某列
*
* @throws Exception
*/
@Test
public void testDel() throws Exception {
Table table = conn.getTable(TableName.valueOf("t_user_info"));
Delete delete = new Delete("user001".getBytes());
delete.addColumn("base_info".getBytes(), "password".getBytes());
table.delete(delete);
table.close();
conn.close();
}
/**
* scan 批量查询数据(全表扫描)
*
* @throws Exception
*/
@Test
public void testScan() throws Exception {
Table t_user_info = conn.getTable(TableName.valueOf("t_user_info"));
Scan scan = new Scan();
ResultScanner scanner = t_user_info.getScanner(scan);
Iterator iter = scanner.iterator();
while (iter.hasNext()) {
Result result = iter.next();
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell current = cellScanner.current();
byte[] familyArray = current.getFamilyArray();
byte[] valueArray = current.getValueArray();
byte[] qualifierArray = current.getQualifierArray();
byte[] rowArray = current.getRowArray();
System.out.println(new String(rowArray, current.getRowOffset(), current.getRowLength()));
System.out.print(new String(familyArray, current.getFamilyOffset(), current.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, current.getQualifierOffset(), current.getQualifierLength()));
System.out.println(" " + new String(valueArray, current.getValueOffset(), current.getValueLength()));
}
System.out.println("-----------------------");
}
}
/**
* 上面的scan操作是全表扫描,数据量很大,可以再加上一些filter功能
* 包括针对:rowkey、family(用得少)、字段名(用得少),字段值
*
* 虽然可以进行过滤,但是要全表扫描,性能较差
* 一般配合ES来存储,ES存储索引字段,以及对应rowKey字段
* 查询ES得到符合的rowKey,最后一次性在hbase中按照rowKey进行查找
*
* @throws Exception
*/
@Test
public void testFilter() throws Exception {
// ================关于行键过滤器(用的多)
// 行键前缀过滤器:针对行键的前缀过滤器
Filter pf = new PrefixFilter(Bytes.toBytes("liu"));
testScan(pf);
/**
* 行键过滤器:针对行键的更灵活的过滤器
* 参数1: CompareOp.LESS 过滤的运算(大于/小于/等于/不等于.....)
* 参数2: ByteArrayComparable 过滤的比较方式(按字节比,按字符串比,按前缀比,按正则表达式比.....)
*/
RowFilter rf1 = new RowFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("user002")));
RowFilter rf2 = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("00"));
testScan(rf1);
System.out.println("**********");
testScan(rf2);
// ================关于列族名过滤器(这个用得少)
// 列族名过滤器:针对列族名的过滤器 返回结果中只会包含满足条件的列族中的数据
FamilyFilter ff1 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("inf")));
FamilyFilter ff2 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base")));
testScan(ff2);
// ================关于列名过滤
// 列名过滤器:针对列名的过滤器 返回结果中只会包含满足条件的列的数据
QualifierFilter qf = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("password")));
QualifierFilter qf2 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("us")));
testScan(qf2);
// 跟QualifierFilter使用BinaryPrefixComparator这种比较器时,效果是一样的
ColumnPrefixFilter cf = new ColumnPrefixFilter("passw".getBytes());
testScan(cf);
// ================关于列值过滤器
// 列值过滤器:针对指定列的value来过滤
SingleColumnValueFilter scvf = new SingleColumnValueFilter("base_info".getBytes(), "password".getBytes(), CompareFilter.CompareOp.GREATER, "123456".getBytes());
scvf.setFilterIfMissing(true); // 如果指定的列缺失,则也过滤掉
testScan(scvf);
ByteArrayComparable comparator1 = new RegexStringComparator("^zhang");
ByteArrayComparable comparator2 = new SubstringComparator("ang");
SingleColumnValueFilter scvf1 = new SingleColumnValueFilter("base_info".getBytes(), "username".getBytes(), CompareFilter.CompareOp.EQUAL, comparator1);
testScan(scvf1);
//MultipleColumnPrefixFilter 跟ColumnPrefixFilter功能是相似的,区别在于可以指定多个前缀值,满足任意一个即可
byte[][] prefixes = new byte[][]{Bytes.toBytes("username"), Bytes.toBytes("password")};
MultipleColumnPrefixFilter mcf = new MultipleColumnPrefixFilter(prefixes);
testScan(mcf);
// 过滤器链表:FilterList 可以用“与”/“或”的方式组合多个过滤器
FamilyFilter ff3 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base")));
ColumnPrefixFilter cf1 = new ColumnPrefixFilter("passw".getBytes());
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
filterList.addFilter(ff3);
filterList.addFilter(cf1);
testScan(filterList);
}
public void testScan(Filter filter) throws Exception {
Table t_user_info = conn.getTable(TableName.valueOf("t_user_info"));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = t_user_info.getScanner(scan);
Iterator iter = scanner.iterator();
while (iter.hasNext()) {
Result result = iter.next();
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell current = cellScanner.current();
byte[] familyArray = current.getFamilyArray();
byte[] valueArray = current.getValueArray();
byte[] qualifierArray = current.getQualifierArray();
byte[] rowArray = current.getRowArray();
System.out.println(new String(rowArray, current.getRowOffset(), current.getRowLength()));
System.out.print(new String(familyArray, current.getFamilyOffset(), current.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, current.getQualifierOffset(), current.getQualifierLength()));
System.out.println(" " + new String(valueArray, current.getValueOffset(), current.getValueLength()));
}
System.out.println("-----------------------");
}
}
/**
* 分页查询
* 核心思想:
* 用一个pageFilter来定义一页返回最多的条数
* 自己去记录每一页中的最后一条的(行键+\000)作为下一页查询时的起始行键
*
* @throws Exception
*/
@Test
public void pageScan() throws Exception {
final byte[] POSTFIX = new byte[]{0x00};
Table table = conn.getTable(TableName.valueOf("t_user_info"));
Filter filter = new PageFilter(3); // 一次需要获取一页的条数
byte[] lastRow = null;
int totalRows = 0;
while (true) {
Scan scan = new Scan();
scan.setFilter(filter);
if (lastRow != null) {
byte[] startRow = Bytes.add(lastRow, POSTFIX); // 设置本次查询的起始行键
scan.setStartRow(startRow);
}
// 由于scan中已经设置了PageFilter(3),所以scanner将返回<=3条数据
ResultScanner scanner = table.getScanner(scan);
int localRows = 0;
Result result;
while ((result = scanner.next()) != null) {
System.out.println(++localRows + ":" + result);
totalRows++;
lastRow = result.getRow();
}
scanner.close();
if (localRows == 0)
break;
Thread.sleep(2000);
}
System.out.println("total rows:" + totalRows);
}
}