我们知道计算机的五大组成部件:输入设备、输出设备、储存器、运算器、控制器,其中输入输出设备我们称之为I/O设备,运算器和控制器称之为CPU,存储器如内存、硬盘等。计算机只要有CPU和内存其实就已经可以独立完成计算任务了,只是其输入输出都在内存中实现,但是内存属于随机存储单元,断电就会导致数据的丢失,因此我们就通过其他的辅助存储设备来弥补内存的这个不足,这些辅助的存储设备称之为外存,如:磁盘、光驱等。
对于linux而言,一切皆文件,因此linux之上所有的设备的操作都是通过文件接口实现的,也就是所的在访问设备的时候就像访问一个文件一样,因此他们使用的都是文件接口.
每一个设备都有一个文件作为它的访问接口,此文件我们称之为设备文件;该文件关联至一个设备驱动程序,进而能够跟与之对应的硬件设备进行通讯.
假如同一个设备有两个,那请问该设备是应该关联一个设备文件还是关联两个设备文件?假如有两个两块硬盘,那他肯定要关联到两个设备文件上,那这两个设备文件可能会关联到一个驱动程序上,因为这两块硬盘都是统一的型号,但是这两个设备文件作为了两个不同的设备入口;需要知道的是文件只是用户视图中所看到的访问入口,但是对于硬件和系统级别,他们更容易识别的是数字而不是字符串,那么每个设备在内核集中都是靠一个设备号来进行标识的。
设备号码:用来标识设备,不同类别的设备有不同的设备号,同一个类别设备有不同的设备或多个设备,因此就有主设备号和次设备号。
主设备号:major number, 标识设备类型
次设备号:minor number, 标识同一类型下的不同设
磁盘设备的设备文件命名
硬盘接口类型:通常我们通过硬盘接口的不同来区分不同硬盘,而不同的驱动程序是靠自己的硬盘内部的工作电气特性来实现的;因此不管你的硬盘是那个厂商生产的,你的sata接口肯定是要接入到主板上的sata控制器上。


机械硬盘和固态硬盘
机械硬盘(HDD):Hard Disk Drive,即是传统普通硬盘,主要由:盘 片,磁头,盘片转轴及控制电机,磁头控制器,数据转换器,接口,缓存 等几个部分组成。机械硬盘中所有的盘片都装在一个旋转轴上,每张盘片 之间是平行的,在每个盘片的存储面上有一个磁头,磁头与盘片之间的距 离比头发丝的直径还小,所有的磁头联在一个磁头控制器上,由磁头控制 器负责各个磁头的运动。磁头可沿盘片的半径方向运动,加上盘片每分钟 几千转的高速旋转,磁头就可以定位在盘片的指定位置上进行数据的读写 操作。数据通过磁头由电磁流来改变极性方式被电磁流写到磁盘上,也可 以通过相反方式读取。硬盘为精密设备,进入硬盘的空气必须过滤
固态硬盘(SSD):Solid State Drive,用固态电子存储芯片阵列而制 成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。固 态硬盘在接口的规范和定义、功能及使用方法上与普通硬盘的完全相同, 在产品外形和尺寸上也与普通硬盘一致
磁盘的寻址方式:CHS和LBA
CHS 有以下特点:
1.采用24bit位寻址方式
2.其中前10位表示cylinde(柱面) ,中间8位表示head(磁头) ,后边6位表示aector(扇区)
3.最空间大寻址8GB
LBA
LBA有以下特点
1.LBA是一个整数,通过转换成CHS格式完成磁盘具体寻址
2.LBA采用48个bit为寻址
3.最大寻址空间128PB
LBA有以下特点
1.LBA是一个整数,通过转换成CHS格式完成磁盘具体寻址
2.LBA采用48个bit为寻址
3.最大寻址空间128PB
*由于CHS寻址方式的寻址空间大概在8GB以内,所以在磁盘容量小于8GB时可以使用CHS寻址方式或是LBA寻址方式,在磁盘容量大于8GB时,只能使用LBA寻址方式。
磁盘分区方式:MBA和GPT
MBA
1.使用32位表示扇区数,分区不超过2T
2.根据柱面数来分区
3.MBR的0磁道0扇区的前512字节中446字节用来存boot loader(系统启动项)64字节用来表示分区表(16字节一个)最后2字节用来存结束位(55AA)
4.因为前512字节中,只有64个字节是用来存分区表信息的,所以只能分4个主分区,一般会分三个主分区,一个扩展分区,扩展分区可以在分N个逻辑分区
GPT
1.支持128个分区没知识64位,支持8Z(512byte/block)64Z(4096byte/block)
2.使用128位UUID表示磁盘和分区GPT分区表自动备份在头和尾两位,并有CRC校验位
3.UEFI(统一扩展固件接口)硬件支持GPT,是操作系统启动,
MAR分区结构
GRT分区结构
磁盘阵列
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意。
磁盘阵列是由很多价格较便宜的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。
分类
磁盘阵列其样式有三种,一是外接式磁盘阵列柜、二是内接式磁盘阵列卡,三是利用软件来仿真。
外接式磁盘阵列柜最常被使用大型服务器上,具可热交换(Hot Swap)的特性,不过这类产品的价格都很贵。
内接式磁盘阵列卡,因为价格便宜,但需要较高的安装技术,适合技术人员使用操作。硬件阵列能够提供在线扩容、动态修改阵列级别、自动数据恢复、驱动器漫游、超高速缓冲等功能。它能×××能、数据保护、可靠性、可用性和可管理性的解决方案。阵列卡专用的处理单元来进行操作。
利用软件仿真的方式,是指通过网络操作系统自身提供的磁盘管理功能将连接的普通SCSI卡上的多块硬盘配置成逻辑盘,组成阵列。软件阵列可以提供数据冗余功能,但是磁盘子系统的性能会有所降低,有的降低幅度还比较大,达30%左右。因此会拖累机器的速度,不适合×××量的服务器。
RAID优缺点
优点
提高传输速率。RAID通过在多个磁盘上同时存储和读取数据来大幅提高存储系统的数据吞吐量(Throughput)。在RAID中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用RAID可以达到单个磁盘驱动器几倍、几十倍甚至上百倍的速率。这也是RAID最初想要解决的问题。因为当时CPU的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种方案解决二者之间的矛盾。RAID最后成功了。
通过数据校验提供容错功能。普通磁盘驱动器无法提供容错功能,如果不包括写在磁盘上的CRC(循环冗余校验)码的话。RAID容错是建立在每个磁盘驱动器的硬件容错功能之上的,所以它提供更高的安全性。在很多RAID模式中都有较为完备的相互校验/恢复的措施,甚至是直接相互的镜像备份,从而大大提高了RAID系统的容错度,提高了系统的稳定冗余性。
缺点
RAID0没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都无法使用。
RAID1磁盘的利用率最高只能达到50%(使用两块盘的情况下),是所有RAID级别中最低的。
RAID0+1以理解为是RAID 0和RAID 1的折中方案。RAID 0+1可以为系统提供数据安全保障,但保障程度要比 Mirror低而磁盘空间利用率要比Mirror高。
RAID级别
RAID 0: RAID 0连续以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余,因此并不能算是真正的RAID结构。RAID 0只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0不能应用于数据安全性要求高的场合。
RAID 1: 它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能。RAID 1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。

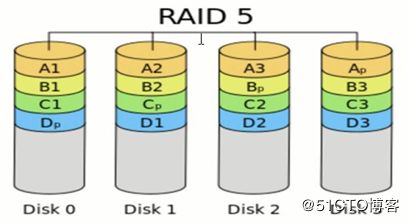
RAID 5: RAID 5不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息。在RAID 5上,读/写指针可同时对阵列设备进行操作,提供了更高的数据流量。RAID 5更适合于小数据块和随机读写的数据。RAID 3与RAID 5相比,最主要的区别在于RAID 3每进行一次数据传输就需涉及到所有的阵列盘;而对于RAID 5来说,大部分数据传输只对一块磁盘操作,并可进行并行操作。在RAID 5中有“写损失”,即每一次写操作将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
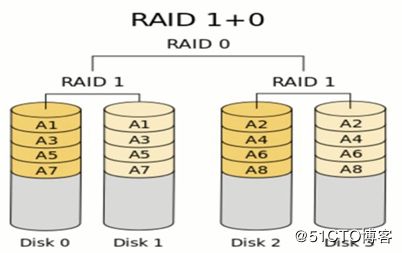
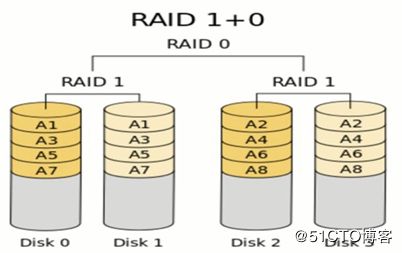
RAID 01/10: 根据组合分为RAID 10和RAID 01,实际是将RAID 0和RAID 1标准结合的产物,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘作磁盘镜像进行冗余。它的优点是同时拥有RAID 0的超凡速度和RAID 1的数据高可靠性,但是CPU占用率同样也更高,而且磁盘的利用率比较低。RAID 1+0是先镜射再分区数据,再将所有硬盘分为两组,视为是RAID 0的最低组合,然后将这两组各自视为RAID 1运作。RAID 0+1则是跟RAID 1+0的程序相反,是先分区再将数据镜射到两组硬盘。它将所有的硬盘分为两组,变成RAID 1的最低组合,而将两组硬盘各自视为RAD 0运作。性能上,RAID 0+1比RAID 1+0有着更快的读写速度。可靠性上,当RAID 1+0有一个硬盘受损,其余三个硬盘会继续运作。RAID 0+1 只要有一个硬盘受损,同组RAID 0的另一只硬盘亦会停止运作,只剩下两个硬盘运作,可靠性较低。因此,RAID 10远较RAID 01常用,零售主板绝大部份支持RAID 0/1/5/10,但不支持RAID 01
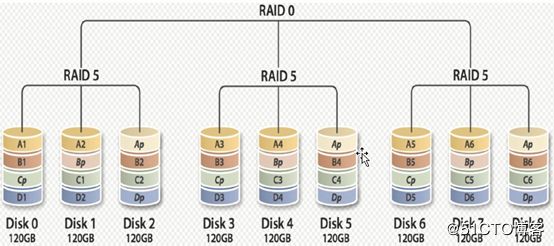
RAID 50: RAID50是RAID5与RAID0的结合。此配置在RAID5的子磁盘组的每个磁盘上进行包括奇偶信息在内的数据的剥离。每个RAID5子磁盘组要求三个硬盘。RAID50具备更高的容错能力,因为它允许某个组内有一个磁盘出现故障,而不会造成数据丢失。而且因为奇偶位分部于RAID5子磁盘组上,故重建速度有很大提高。优势:更高的容错能力,具备更快数据读取速率的潜力。需要注意的是:磁盘故障会影响吞吐量。故障后重建信息的时间比镜像配置情况下要长。(不常用的)
两道Linux运维面试题
简述raid0 raid1 raid5 三种工作模式的工作原理及特点
RAID,可以把硬盘整合成一个大磁盘,还可以在大磁盘上再分区,放数据
还有一个大功能,多块盘放在一起可以有冗余(备份)
RAID整合方式有很多,常用的:0 1 5 10
RAID 0,可以是一块盘和N个盘组合
其优点读写快,是RAID中最好的
缺点:没有冗余,一块坏了数据就全没有了
RAID 1,只能2块盘,盘的大小可以不一样,以小的为准
10G+10G只有10G,另一个做备份。它有100%的冗余,缺点:浪费资源,成本高
RAID 5 ,3块盘,容量计算10*(n-1),损失一块盘
特点,读写性能一般,读还好一点,写不好
冗余从好到坏:RAID1 RAID10 RAID 5 RAID0
性能从好到坏:RAID0 RAID10 RAID5 RAID1
成本从低到高:RAID0 RAID5 RAID1 RAID10
单台服务器:很重要盘不多,系统盘,RAID1
数据库服务器:主库:RAID10 从库 RAID5\RAID0(为了维护成本,RAID10)
WEB服务器,如果没有太多的数据的话,RAID5,RAID0(单盘)
有多台,监控、应用服务器,RAID0 RAID5
我们会根据数据的存储和访问的需求,去匹配对应的RAID级别
简述raid0 raid1 raid5 三种工作模式的工作原理及特点
RAID 0:带区卷,连续以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率
但它没有数据冗余,RAID 0 只是单纯地提高性能,并没有为数据的可靠性提供保证
而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0 不能应用于数据安全性要求高的场合
RAID 1:镜像卷,它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据
不能提升写数据效率。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID1 可以提高读取性能
RAID 1 是磁盘阵列中单位成本最高的,镜像卷可用容量为总容量的1/2,但提供了很高的数据安全性和可用性
当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据
RAID5:至少由3块硬盘组成,分布式奇偶校验的独立磁盘结构,它的奇偶校验码存在于所有磁盘上
任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据(最多允许1块硬盘损坏)
所以raid5可以实现数据冗余,确保数据的安全性,同时raid5也可以提升数据的读写性能