Python金融大数据分析——第6章 金融时间序列 笔记
- 第6章 金融时间序列
- 6.1 pandas基础
- 6.1.1 使用DataFrame类的第一步
- 6.1.2 使用DataFrame类的第二步
- 6.1.3 基本分析
- 6.1.4 Series类
- 6.1.5 GroupBy操作
- 6.2 金融数据
- 6.3 回归分析
- 6.4 高频数据
- 6.1 pandas基础
第6章 金融时间序列
6.1 pandas基础
6.1.1 使用DataFrame类的第一步
import pandas as pd
import numpy as np
df = pd.DataFrame([10, 20, 30, 40], columns=['numbers'], index=['a', 'b', 'c', 'd'])
df
# numbers
# a 10
# b 20
# c 30
# d 40
df.index
# Index(['a', 'b', 'c', 'd'], dtype='object')
df.columns
# Index(['numbers'], dtype='object')
df.loc['c']
# numbers 30
# Name: c, dtype: int64
df.loc[['a', 'b']]
# numbers
# a 10
# b 20
df.loc[df.index[1:3]]
# numbers
# b 20
# c 30
df.sum()
# numbers 100
# dtype: int64
df.apply(lambda x: x ** 2)
# numbers
# a 100
# b 400
# c 900
# d 1600
df ** 2
# numbers
# a 100
# b 400
# c 900
# d 1600
df['floats'] = (1.5, 2.5, 3.5, 4.5)
df
# numbers floats
# a 10 1.5
# b 20 2.5
# c 30 3.5
# d 40 4.5
df['floats']
# a 1.5
# b 2.5
# c 3.5
# d 4.5
# Name: floats, dtype: float64
df.floats
# a 1.5
# b 2.5
# c 3.5
# d 4.5
# Name: floats, dtype: float64
df['names'] = pd.DataFrame(['Yves', 'Guido', 'Felix', 'Francesc'], index=['d', 'a', 'b', 'c'])
df
# numbers floats names
# a 10 1.5 Guido
# b 20 2.5 Felix
# c 30 3.5 Francesc
# d 40 4.5 Yves
df.append({'numbers': 100, 'floats': 5.75, 'names': 'Henry'}, ignore_index=True)
# numbers floats names
# 0 10 1.50 Guido
# 1 20 2.50 Felix
# 2 30 3.50 Francesc
# 3 40 4.50 Yves
# 4 100 5.75 Henry
df = df.append(pd.DataFrame({'numbers': 100, 'floats': 5.75, 'names': 'Henry'}, index=['z', ]))
df
# floats names numbers
# a 1.50 Guido 10
# b 2.50 Felix 20
# c 3.50 Francesc 30
# d 4.50 Yves 40
# z 5.75 Henry 100
df.join(pd.DataFrame([1, 4, 9, 16, 25], index=['a', 'b', 'c', 'd', 'y'], columns=['squares', ]))
# floats names numbers squares
# a 1.50 Guido 10 1.0
# b 2.50 Felix 20 4.0
# c 3.50 Francesc 30 9.0
# d 4.50 Yves 40 16.0
# z 5.75 Henry 100 NaN
df = df.join(pd.DataFrame([1, 4, 9, 16, 25],
index=['a', 'b', 'c', 'd', 'y'],
columns=['squares', ]),
how='outer')
df
# floats names numbers squares
# a 1.50 Guido 10.0 1.0
# b 2.50 Felix 20.0 4.0
# c 3.50 Francesc 30.0 9.0
# d 4.50 Yves 40.0 16.0
# y NaN NaN NaN 25.0
# z 5.75 Henry 100.0 NaN
df[['numbers', 'squares']].mean()
# numbers 40.0
# squares 11.0
# dtype: float64
df[['numbers', 'squares']].std()
# numbers 35.355339
# squares 9.669540
# dtype: float646.1.2 使用DataFrame类的第二步
a = np.random.standard_normal((9, 4))
a.round(6)
# array([[ 0.109076, -1.05275 , 1.253471, 0.39846 ],
# [-1.561175, -1.997425, 1.158739, -2.030734],
# [ 0.764723, 0.760368, 0.864103, -0.174079],
# [ 2.429043, 0.281962, -0.496606, 0.009445],
# [-1.679758, -1.02374 , -1.135922, 0.077649],
# [-0.247692, 0.301198, 2.156474, 1.537902],
# [ 1.162934, 2.102327, -0.4501 , 0.812529],
# [-0.374749, -0.818229, -1.013962, -0.476855],
# [ 0.626347, 2.294829, -1.29531 , -0.031501]])
df = pd.DataFrame(a)
df
# 0 1 2 3
# 0 0.109076 -1.052750 1.253471 0.398460
# 1 -1.561175 -1.997425 1.158739 -2.030734
# 2 0.764723 0.760368 0.864103 -0.174079
# 3 2.429043 0.281962 -0.496606 0.009445
# 4 -1.679758 -1.023740 -1.135922 0.077649
# 5 -0.247692 0.301198 2.156474 1.537902
# 6 1.162934 2.102327 -0.450100 0.812529
# 7 -0.374749 -0.818229 -1.013962 -0.476855
# 8 0.626347 2.294829 -1.295310 -0.031501
df.columns = [['No1', 'No2', 'No3', 'No4']]
df
# No1 No2 No3 No4
# 0 0.109076 -1.052750 1.253471 0.398460
# 1 -1.561175 -1.997425 1.158739 -2.030734
# 2 0.764723 0.760368 0.864103 -0.174079
# 3 2.429043 0.281962 -0.496606 0.009445
# 4 -1.679758 -1.023740 -1.135922 0.077649
# 5 -0.247692 0.301198 2.156474 1.537902
# 6 1.162934 2.102327 -0.450100 0.812529
# 7 -0.374749 -0.818229 -1.013962 -0.476855
# 8 0.626347 2.294829 -1.295310 -0.031501
df['No2'][3]
# 0.2819621128403918
dates = pd.date_range('2018-01-01', periods=9, freq='M')
dates
# DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
# '2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31',
# '2018-09-30'],
# dtype='datetime64[ns]', freq='M')data_range函数参数
| 参数 | 格式 | 描述 |
|---|---|---|
| start | 字符串/日期时间 | 生成日期的左界 |
| end | 字符串/日期时间 | 生成日期的右界 |
| periods | 整数/None | 期数(如果start或者end空缺) |
| freq | 字符串/日期偏移 | 频率字符串,例如5D (5天) |
| tz | 字符串/None | 本地化索引的时区名称 |
| nonnalize | 布尔值,默认None | 将star和end规范化为午夜 |
| name | 字符串,默认None | 结果索引名称 |
df.index = dates
df
# No1 No2 No3 No4
# 2018-01-31 0.109076 -1.052750 1.253471 0.398460
# 2018-02-28 -1.561175 -1.997425 1.158739 -2.030734
# 2018-03-31 0.764723 0.760368 0.864103 -0.174079
# 2018-04-30 2.429043 0.281962 -0.496606 0.009445
# 2018-05-31 -1.679758 -1.023740 -1.135922 0.077649
# 2018-06-30 -0.247692 0.301198 2.156474 1.537902
# 2018-07-31 1.162934 2.102327 -0.450100 0.812529
# 2018-08-31 -0.374749 -0.818229 -1.013962 -0.476855
# 2018-09-30 0.626347 2.294829 -1.295310 -0.031501data_range函数频率参数值
| 别名 | 描述 |
|---|---|
| B | 交易日 |
| C | 自定义交易日(试验性) |
| D | 日历日 |
| W | 每周 |
| M | 每月底 |
| BM | 每月最后一个交易日 |
| MS | 月初 |
| BMS | 每月第一个交易日 |
| Q | 季度末 |
| BQ | 每季度最后一个交易日 |
| QS | 季度初 |
| BQS | 每季度第一个交易日 |
| A | 每年底 |
| BA | 每年最后一个交易日 |
| AS | 每年初 |
| BAS | 每年第一个交易日 |
| H | 每小时 |
| T | 每分钟 |
| S | 每秒 |
| L | 毫秒 |
| U | 微秒 |
通常可以从一个 ndarray 对象生成 DataFrame 对象。 但是也可以简单地使用NumPy的array函数从DataFrame 生成一个 ndarray。
np.array(df).round(6)
# array([[ 0.109076, -1.05275 , 1.253471, 0.39846 ],
# [-1.561175, -1.997425, 1.158739, -2.030734],
# [ 0.764723, 0.760368, 0.864103, -0.174079],
# [ 2.429043, 0.281962, -0.496606, 0.009445],
# [-1.679758, -1.02374 , -1.135922, 0.077649],
# [-0.247692, 0.301198, 2.156474, 1.537902],
# [ 1.162934, 2.102327, -0.4501 , 0.812529],
# [-0.374749, -0.818229, -1.013962, -0.476855],
# [ 0.626347, 2.294829, -1.29531 , -0.031501]])6.1.3 基本分析
df.sum()
# No1 1.228750
# No2 0.848540
# No3 1.040888
# No4 0.122816
# dtype: float64
df.mean()
# No1 0.136528
# No2 0.094282
# No3 0.115654
# No4 0.013646
# dtype: float64
df.cumsum()
# No1 No2 No3 No4
# 2018-01-31 0.109076 -1.052750 1.253471 0.398460
# 2018-02-28 -1.452099 -3.050176 2.412210 -1.632274
# 2018-03-31 -0.687376 -2.289807 3.276313 -1.806353
# 2018-04-30 1.741667 -2.007845 2.779707 -1.796908
# 2018-05-31 0.061909 -3.031585 1.643786 -1.719259
# 2018-06-30 -0.185783 -2.730387 3.800259 -0.181357
# 2018-07-31 0.977152 -0.628061 3.350160 0.631172
# 2018-08-31 0.602403 -1.446289 2.336198 0.154317
# 2018-09-30 1.228750 0.848540 1.040888 0.122816
df.describe()
# No1 No2 No3 No4
# count 9.000000 9.000000 9.000000 9.000000
# mean 0.136528 0.094282 0.115654 0.013646
# std 1.300700 1.465006 1.256782 0.972826
# min -1.679758 -1.997425 -1.295310 -2.030734
# 25% -0.374749 -1.023740 -1.013962 -0.174079
# 50% 0.109076 0.281962 -0.450100 0.009445
# 75% 0.764723 0.760368 1.158739 0.398460
# max 2.429043 2.294829 2.156474 1.537902
np.sqrt(df)
# No1 No2 No3 No4
# 2018-01-31 0.330266 NaN 1.119585 0.631236
# 2018-02-28 NaN NaN 1.076447 NaN
# 2018-03-31 0.874484 0.871991 0.929571 NaN
# 2018-04-30 1.558539 0.531001 NaN 0.097184
# 2018-05-31 NaN NaN NaN 0.278656
# 2018-06-30 NaN 0.548815 1.468494 1.240122
# 2018-07-31 1.078394 1.449940 NaN 0.901404
# 2018-08-31 NaN NaN NaN NaN
# 2018-09-30 0.791421 1.514869 NaN NaN
np.sqrt(df).sum()
# No1 4.633104
# No2 4.916616
# No3 4.594098
# No4 3.148602
# dtype: float64df.cumsum().plot(lw=2.0)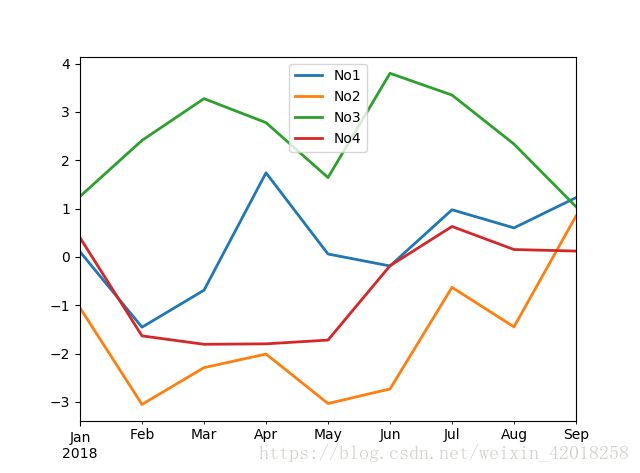
plot方法参数
| 参数 | 格式 | 描述 |
|---|---|---|
| x | 标签/位置,默认None | 只在列值为x刻度时使用 |
| y | 标签/位置,默认None | 只在列值为x刻度时使用 |
| subplots | 布尔值,默认False | 子图中的绘图列 |
| sharex | 布尔值,默认True | 共用x轴 |
| sharey | 布尔值,默认False | 共用y轴 |
| use_index | 布尔值,默认True | 使用DataFrame.index作为x轴刻度 |
| stacked | 布尔值,默认False | 堆叠(只用于柱状图) |
| sort_columns | 布尔值,默认False | 在绘图之前将列按字母顺序排列 |
| title | 字符串,默认None | 图表标题 |
| grid | 布尔值,默认False | 水平和垂直网格线 |
| legend | 布尔值,默认True | 标签图例 |
| ax | matplotlib轴对象 | 绘图使用的matplotlib轴对象 |
| style | 字符串或者列表/字典 | 绘图线形(每列) |
| kind | ‘line’ : line plot (default) ‘bar’ : vertical bar plot ‘barh’ : horizontal bar plot ‘hist’ : histogram ‘box’ : boxplot ‘kde’ : Kernel Density Estimation plot ‘density’ : same as ‘kde’ ‘area’ : area plot ‘pie’ : pie plot ‘scatter’ : scatter plot ‘hexbin’ : hexbin plot |
图表类型 |
| logx | 布尔值,默认False | x轴的对数刻度 |
| logy | 布尔值,默认False | y轴的对数刻度 |
| xticks | 序列,默认index | x轴刻度 |
| yticks | 序列,默认Values | y轴刻度 |
| xlim | 二元组,列表 | x轴界限 |
| ylim | 二元组,列表 | y轴界限 |
| rot | 整数,默认为None | 旋转x刻度 |
| secondary_y | 布尔值/序列,默认False | 第二个y轴 |
| mark_right | 布尔值,默认True | 第二个y轴自动设置标签 |
| colormap | 字符串/颜色映射对象,默认None | 用于绘图的颜色映射 |
| kwds | 关键字 | 传递給matplotlib选项 |
6.1.4 Series类
type(df)
# pandas.core.frame.DataFrame
df['No1']
# 2018-01-31 0.109076
# 2018-02-28 -1.561175
# 2018-03-31 0.764723
# 2018-04-30 2.429043
# 2018-05-31 -1.679758
# 2018-06-30 -0.247692
# 2018-07-31 1.162934
# 2018-08-31 -0.374749
# 2018-09-30 0.626347
# Freq: M, Name: No1, dtype: float64
type(df['No1'])
# pandas.core.series.Series
# DataFrame的主要方法也可用于Series对象
# 6-2 Series对象的线图
import matplotlib.pyplot as plt
df['No1'].cumsum().plot(style='r', lw=2)
plt.xlabel('date')
plt.ylabel('value')DataFrame的主要方法也可用于Series对象
Series对象的线图
import matplotlib.pyplot as plt
df['No1'].cumsum().plot(style='r', lw=2)
plt.xlabel('date')
plt.ylabel('value')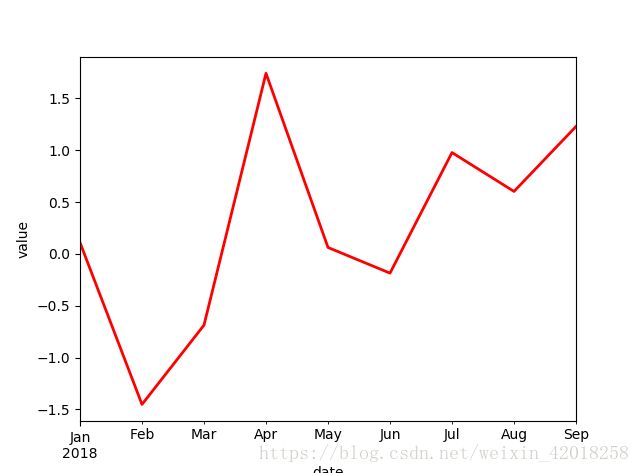
6.1.5 GroupBy操作
df['Quarter'] = ['Q1', 'Q1', 'Q1', 'Q2', 'Q2', 'Q2', 'Q3', 'Q3', 'Q3']
df
# No1 No2 No3 No4 Quarter
# 2018-01-31 0.109076 -1.052750 1.253471 0.398460 Q1
# 2018-02-28 -1.561175 -1.997425 1.158739 -2.030734 Q1
# 2018-03-31 0.764723 0.760368 0.864103 -0.174079 Q1
# 2018-04-30 2.429043 0.281962 -0.496606 0.009445 Q2
# 2018-05-31 -1.679758 -1.023740 -1.135922 0.077649 Q2
# 2018-06-30 -0.247692 0.301198 2.156474 1.537902 Q2
# 2018-07-31 1.162934 2.102327 -0.450100 0.812529 Q3
# 2018-08-31 -0.374749 -0.818229 -1.013962 -0.476855 Q3
# 2018-09-30 0.626347 2.294829 -1.295310 -0.031501 Q3
groups = df.groupby('Quarter')
groups.mean()
# No1 No2 No3 No4
# Quarter
# Q1 -0.229125 -0.763269 1.092104 -0.602118
# Q2 0.167198 -0.146860 0.174649 0.541665
# Q3 0.471511 1.192976 -0.919790 0.101391
groups.max()
# No1 No2 No3 No4
# Quarter
# Q1 0.764723 0.760368 1.253471 0.398460
# Q2 2.429043 0.301198 2.156474 1.537902
# Q3 1.162934 2.294829 -0.450100 0.812529
groups.size()
# Quarter
# Q1 3
# Q2 3
# Q3 3
# dtype: int64
df['Odd_Even'] = ['Odd', 'Even', 'Odd', 'Even', 'Odd', 'Even', 'Odd', 'Even', 'Odd']
groups = df.groupby(['Quarter', 'Odd_Even'])
groups.size()
# Quarter Odd_Even
# Q1 Even 1
# Odd 2
# Q2 Even 2
# Odd 1
# Q3 Even 1
# Odd 2
# dtype: int64
groups.mean()
# No1 No2 No3 No4
# Quarter Odd_Even
# Q1 Even -1.561175 -1.997425 1.158739 -2.030734
# Odd 0.436899 -0.146191 1.058787 0.112190
# Q2 Even 1.090676 0.291580 0.829934 0.773673
# Odd -1.679758 -1.023740 -1.135922 0.077649
# Q3 Even -0.374749 -0.818229 -1.013962 -0.476855
# Odd 0.894640 2.198578 -0.872705 0.3905146.2 金融数据
import datetime
import pandas_datareader.data as web
start = datetime.datetime(2016, 1, 1) # or start = '1/1/2016' or '2016-1-1'
end = datetime.date.today()
prices = web.DataReader('AAPL', 'yahoo', start, end)
# 从雅虎财经拉取的苹果股价
prices.head()| Open | High | Low | Close | Adj | Close | Volume | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2015-12-31 | 107.010002 | 107.029999 | 104.820000 | 105.260002 | 100.540207 | 40635300 | |
| 2016-01-04 | 102.610001 | 105.370003 | 102.000000 | 105.349998 | 100.626175 | 67649400 | |
| 2016-01-05 | 105.750000 | 105.849998 | 102.410004 | 102.709999 | 98.104546 | 55791000 | |
| 2016-01-06 | 100.559998 | 102.370003 | 99.870003 | 100.699997 | 96.184654 | 68457400 | |
| 2016-01-07 | 98.680000 | 100.129997 | 96.430000 | 96.449997 | 92.125244 | 81094400 |
DataReader函数参数(源代码的参数说明已经很详细了)
| 参数 | 格式 | 描述 |
|---|---|---|
| name | 字符串 | 数据集名称——通常是股票代码 |
| data_source | 如“yahoo” | “yahoo”:Yahoo! Finance, ”google”:Google Finance, ”fred”:St. Louis FED (FRED), ”famafrench”:Kenneth French’s data library, ”edgar-index”:the SEC’s EDGAR Index |
| start | 字符串/日期时间/None | 范围左界(默认”2010/1/1”) |
| end | 字符串/日期时间/None | 范围右界(默认当天) |
指数历史水平
prices['Close'].plot(figsize=(8, 5))
指数和每日指数收益
prices[['Close', 'Return']].plot(subplots=True, style='b', figsize=(8, 5))
指数及移动平均线
prices[['Close', '42d', '252d']].plot(figsize=(8, 5))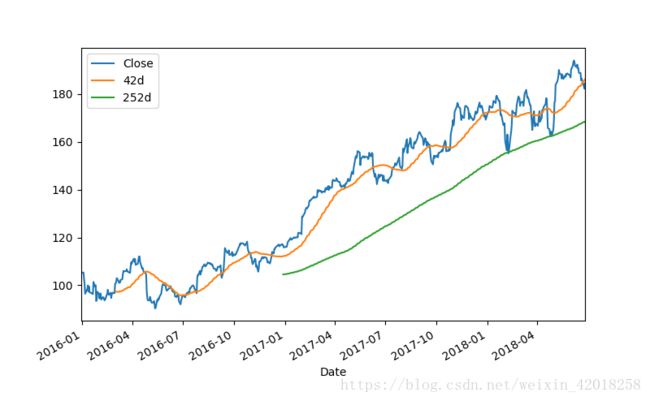
指数和移动年化波动率
import math
prices['Mov_Vol'] = pd.rolling_std(prices['Return'], window=252) * math.sqrt(252)
prices[['Close', 'Mov_Vol', 'Return']].plot(subplots=True, style='b', figsize=(8, 7))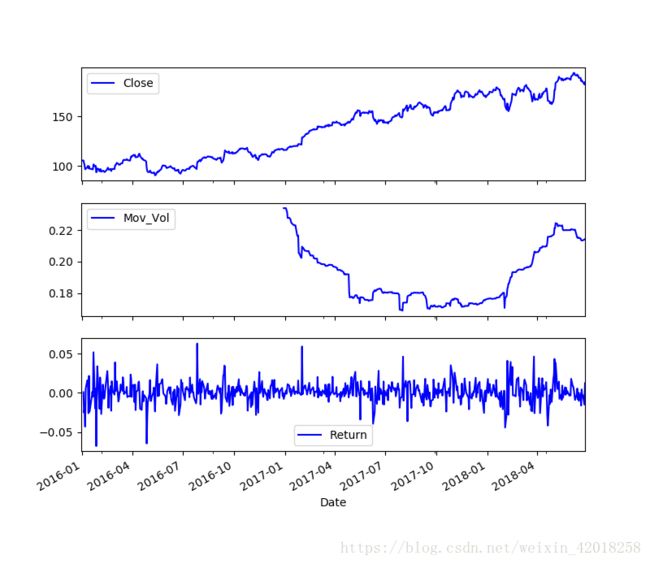
6.3 回归分析
import pandas as pd
import urllib.request
es_url = 'https://www.stoxx.com/document/Indices/Current/HistoricalData/hbrbcpe.txt'
vs_url = 'https://www.stoxx.com/document/Indices/Current/HistoricalData/h_vstoxx.txt'
es_txt = 'E:/data/es.txt'
vs_txt = 'E:/data/vs.txt'
urllib.request.urlretrieve(es_url, es_txt)
urllib.request.urlretrieve(vs_url, vs_txt)
# 数据处理
lines = open(es_txt, 'r').readlines()
lines = [line.replace(' ', '') for line in lines]
# 生成一个新的文本文件
es50_txt = 'E:/data/es50.txt'
new_file = open(es50_txt, 'w')
new_file.writelines('date' + lines[3][:-1] + ';DEL' + lines[3][-1]) # DEL用来占位
new_file.writelines(lines[4:])
new_file.close()
new_lines = open(es50_txt, 'r').readlines()
new_lines[:5]
# ['date;SX5P;SX5E;SXXP;SXXE;SXXF;SXXA;DK5F;DKXF;DEL\n',
# '31.12.1986;775.00;900.82;82.76;98.58;98.06;69.06;645.26;65.56\n',
# '01.01.1987;775.00;900.82;82.76;98.58;98.06;69.06;645.26;65.56\n',
# '02.01.1987;770.89;891.78;82.57;97.80;97.43;69.37;647.62;65.81\n',
# '05.01.1987;771.89;898.33;82.82;98.60;98.19;69.16;649.94;65.82\n']
es = pd.read_csv(es50_txt, index_col=0, parse_dates=True, sep=';', dayfirst=True)
es.head()
# SX5P SX5E SXXP SXXE SXXF SXXA DK5F DKXF DEL
# date
# 1986-12-31 775.00 900.82 82.76 98.58 98.06 69.06 645.26 65.56 NaN
# 1987-01-01 775.00 900.82 82.76 98.58 98.06 69.06 645.26 65.56 NaN
# 1987-01-02 770.89 891.78 82.57 97.80 97.43 69.37 647.62 65.81 NaN
# 1987-01-05 771.89 898.33 82.82 98.60 98.19 69.16 649.94 65.82 NaN
# 1987-01-06 775.92 902.32 83.28 99.19 98.83 69.50 652.49 66.06 NaN
# 辅助列已经完成了使命,可以删除
del es['DEL']
es.info()
# pd.read_csv参数
pd.read_csv(filepath_or_buffer, sep=’,’, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar=’”’, quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
import datetime as dt
data = pd.DataFrame({'EUROSTOXX': es['SX5E'][es.index > dt.datetime(1999, 1, 1)]})
data = data.join(pd.DataFrame({'VSTOXX': vs['V2TX'][vs.index > dt.datetime(1999, 1, 1)]}))
data = data.fillna(method='ffill')
data.info()
# 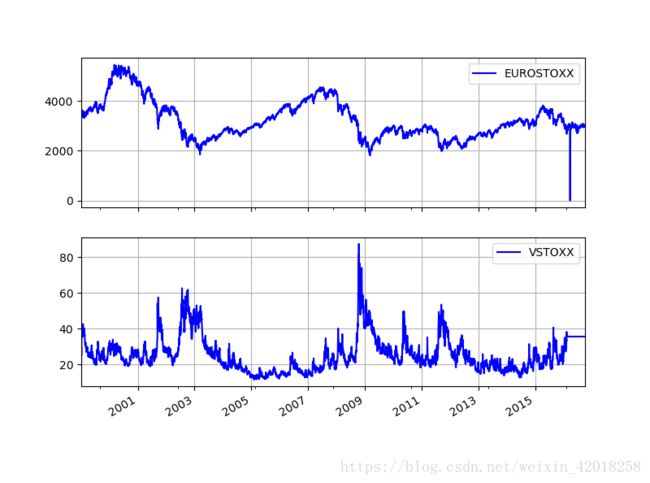
EURO STOXX 50和VSTOXX对数收益率
rets=np.log(data/data.shift(1))
rets.head()
# EUROSTOXX VSTOXX
# 1999-01-04 NaN NaN
# 1999-01-05 0.017228 0.489248
# 1999-01-06 0.022138 -0.165317
# 1999-01-07 -0.015723 0.256337
# 1999-01-08 -0.003120 0.021570
# EURO STOXX 50和VSTOXX对数收益率
rets.plot(subplots=True,grid=True,style='b',figsize=(8,6))
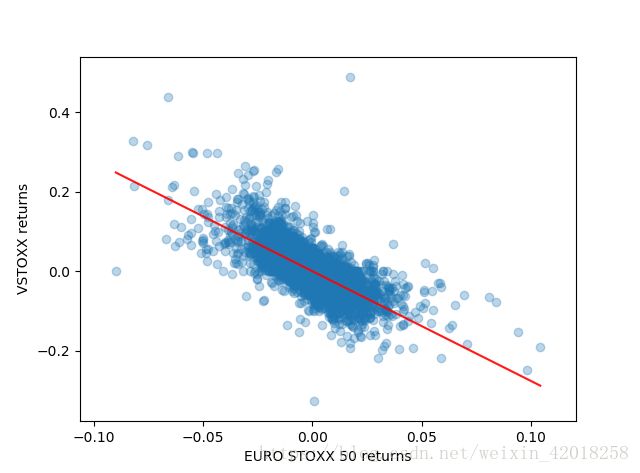
对数收益率散点图和回归线
# 对数收益率散点图和回归线
y = rets.VSTOXX # 结果变量
X = rets.EUROSTOXX # 预测变量
p_inf=float("inf") # 正无穷
n_inf=float("-inf") # 负无穷
y = y.map(lambda x: y.median() if x == p_inf or x == n_inf or np.isnan(x) else x)
X = X.map(lambda x: y.median() if x == p_inf or x == n_inf or np.isnan(x) else x)
import matplotlib.pyplot as plt
import statsmodels.api as sm
model = sm.OLS(y, X)
model = model.fit()
model.summary()
# 
EURO STOXX 50和VSTOXX之间的滚动相关
rets.corr()
# EUROSTOXX VSTOXX
# EUROSTOXX 1.000000 -0.724945
# VSTOXX -0.724945 1.000000
pd.rolling_corr(rets.EUROSTOXX,rets.VSTOXX,window=252).plot(grid=True,style='b')
6.4 高频数据
一个交易日的股价分时数据和交易量
import numpy as np
import datetime as dt
import tushare as ts
import datetime
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 这里用tushare获取了600118中国卫星一周的5分钟分时数据
k_5 = ts.get_k_data(code="600118", start="2018-06-18", end="2018-06-22", ktype='5')
k_5.head()
# 这个接口返回的数据和查询条件有些对不上,当测试数据还是可以的
# date open close high low volume code
# 0 2018-06-12 14:55 20.57 20.57 20.58 20.54 489.0 600118
# 1 2018-06-12 15:00 20.56 20.56 20.57 20.54 1163.0 600118
# 2 2018-06-13 09:35 20.48 20.30 20.48 20.26 2895.0 600118
# 3 2018-06-13 09:40 20.30 20.34 20.39 20.30 1258.0 600118
# 4 2018-06-13 09:45 20.35 20.40 20.45 20.35 535.0 600118
k_5['date'] = k_5['date'].map(lambda x: datetime.datetime.strptime(x, '%Y-%m-%d %H:%M'))
# 筛选出一天的数据
plot_data = k_5[['date','close', 'volume']][(k_5['date'] > dt.datetime(2018, 6, 20)) & (k_5['date'] < dt.datetime(2018, 6, 21))]
# 横坐标
l = plot_data.index
lx = plot_data['date'].map(lambda x: datetime.datetime.strftime(x,'%m-%d %H:%M'))
# 画图
fig, (ax1, ax2) = plt.subplots(2, sharex=True, figsize=(8, 6))
# 折线图
ax1.plot(l, plot_data['close'].values)
ax1.set_title('中国卫星')
ax1.set_ylabel('index level')
# 柱状图
ax2.bar(l, plot_data['volume'].values.astype('int'), width=0.5)
ax2.set_ylabel('volume')
plt.xticks(l, lx, rotation=270)
fig.subplots_adjust(bottom=0.3)
plt.show()
