DGL官方教程二——使用DGL进行批量图分类
enumerate的用法:https://blog.csdn.net/liu_xzhen/article/details/79564455
map函数 zip() zip(*):https://blog.csdn.net/qq_42707449/article/details/81122741
.pop(): https://www.cnblogs.com/foremostxl/p/9365482.html
3 Batched Graph Classification with DGL
图表分类是许多领域应用的重要问题 -——生物信息学,化学信息学,社交网络分析,城市计算和网络安全。将图神经网络应用于该问题最近是一种流行的方法(Ying等,2018,Cangea等,2018,Knyazev等,2018,Bianchi等,2019,Liao等,2019,Gao等人,2019年)。
本次教程演示:
使用DGL批处理多个可变大小和形状的图形
为简单的图分类任务训练图神经网络
3.1 Simple Graph Classification Task 简单图表分类任务
在本教程中,我们将学习如何使用dgl通过分类8种常规图形的小示例执行批量图形分类,如下所示:
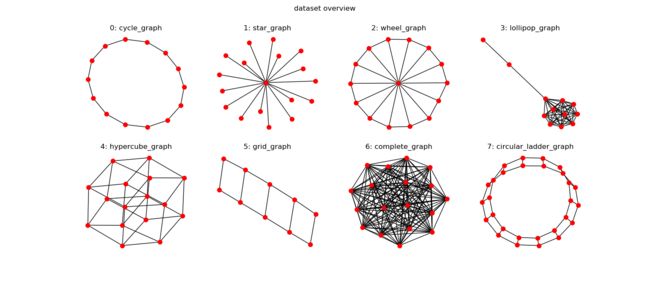
我们在DGL中实现了一个合成数据集data.MiniGCDataset。数据集有8种不同类型的图形,每个类具有相同数量的图形样本。(如何创建自己的数据集??)pickle dump
'图的可视化'
label_names = ['cycle_graph','star_graph','wheel_graph','lollipop_graph','hypercube_graph','grid_graph','complete_graph','circular_ladder_graph']
plt.figure(figsize=(25, 10))
for i, index in enumerate(list(range(0, 80, 10))): #[0,10,20,30,40,50,60,70]#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据索引和数据
plt.subplot(2, 4, i+1) #子图2行4列,8个子图
graph, label = dataset[index] # 每个类别graph的第一个图
nx.draw(graph.to_networkx())
plt.title('Class : %d,%s'%(label,label_names[i]))
plt.show() 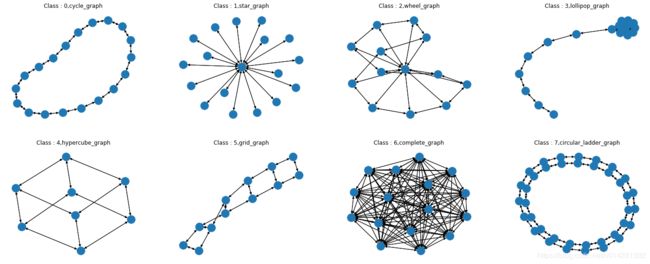
3.2 Form a graph mini-batch
为了更有效地训练神经网络,通常的做法是将多个样本一起批处理。批量固定形状的张量输入非常容易(例如,批量处理两个28×28的图像,张量的形状2×28×28)。
相比之下,批处理图输入有两个挑战:
- 图很稀疏
- 图的形状不固定(节点和边的数量)
为了解决这个问题,DGL提供了一个dgl.batch(),生成batch_graphs.。将 n 张小图打包在一起的操作可以看成是生成一张含 n 个不相连小图的大图。。下面是一个可视化,提供了一般的想法:(这个例子中dgl.batch()中输入的是所有的样本? 8类构成一张大图???还是两类结合??)
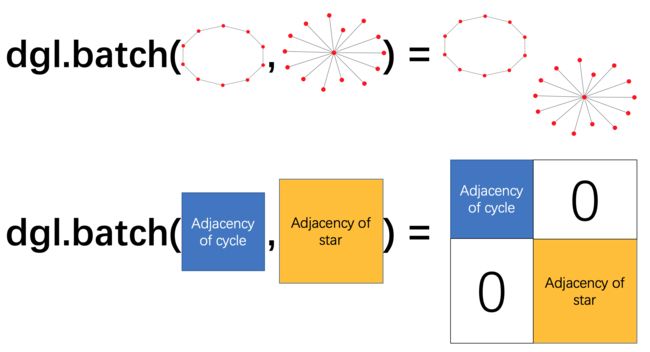
可以看到通过 dgl.batch 操作,我们生成了一张大图,其中包含了一个环状和一个星状的连通分量。其邻接矩阵表示则对应为在对角线上把两张小图的邻接矩阵拼接在一起(其余部分都为 0)。
我们定义以下collate函数,以从给定的图和标签对列表中形成一个小批量。
def collate(samples):
#输入`samples`是一个列表# 每个元素都是一个二元组 (图, 标签)
#生成graoh,labels两个列表
graphs, labels = map(list, zip(*samples)) #map函数将第二个参数(一般是数组)中的每一个项,处理为第一个参数的类型。
#DGL提供了一个dgl.batch()方法,生成batch_graphs.
batched_graph = dgl.batch(graphs)
return batched_graph, torch.tensor(labels)batch(graph_list[, node_attrs, edge_attrs]) 批处理DGLGraph的集合并返回BatchedDGLGraph
正如打包 N 个张量得到的还是张量,dgl.batch 返回的也是一张图。这样的设计有两点好处。首先,任何用于操作一张小图的代码可以被直接使用在一个图批量上。其次,由于 DGL 能够并行处理图中节点和边上的计算,因此同一批量内的图样本都可以被并行计算。
2.3 Graph Classifier 图分类器
这里使用的图分类器和应用在图像或者语音上的分类器类似——先通过多层神经网络计算每个样本的表示(representation),再通过表示计算出每个类别的概率,最后通过向后传播计算梯度。一个常见的图分类器由以下几个步骤构成:
- 1. 通过图卷积(Graph Convolution)层获得图中每个节点的表示。
- 2. 使用「读出」操作(Readout)获得每张图的表示。
- 3. 使用 Softmax 计算每个类别的概率,使用向后传播更新参数。
下图展示了整个流程:
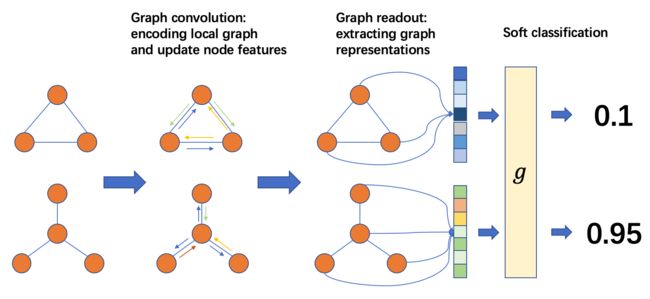
batch graph中每个图的每个节点通过message passing/graph convolution的方式与其他节点进行“通信”,然后更新node’s feature.之后,我们用节点(和边)属性计算图的提取张量.该步骤可以互换地称为“读出/聚合”。图的提取张量输入分类器g 预测图的标签。
- 图卷积:编码局部子图并更新节点特征最后,
- 图读出:提取图表示 最后提取图的表示为取图所有节点特征的平均值然后输入分类器。
- soft 分类:将图的表示输入分类器。分类器对图表示先做了一个线性变换然后得到每一类在 softmax 之前的 logits。
2.4 Graph Convolution

 :第层
:第层 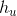 :节点u的特征
:节点u的特征 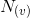 : v的所有邻居节点的集合 取绝对值为v的所有邻居节点的个数
: v的所有邻居节点的集合 取绝对值为v的所有邻居节点的个数
torch.nn.Linear(in_features, out_features, bias=True)
 :形状为(out_features x in_features)的模块中可学习的权值
:形状为(out_features x in_features)的模块中可学习的权值  :形状为(out_features)的模块中可学习的偏置
:形状为(out_features)的模块中可学习的偏置
我们将求和替换成求平均可用来平衡度数不同的节点,在实验中这也带来了模型表现的提升。
此外,在构建数据集时,我们给每个图里所有的节点都加上了和自己的边(自环)。这保证节点在收集邻居节点表示进行更新时也能考虑到自己原有的表示(允许我们在获取平均值时包括原始节点特征![]() 。)。以下是定义图卷积模型的代码。这里我们使用 PyTorch 作为 DGL 的后端引擎(DGL 也支持 MXNet 作为后端)。
。)。以下是定义图卷积模型的代码。这里我们使用 PyTorch 作为 DGL 的后端引擎(DGL 也支持 MXNet 作为后端)。
'图卷积'
import dgl.function as fn #使用内置函数并行更新API
import torch
import torch.nn as nn
'传递节点特征h的message'
msg = fn.copy_src(src='h', out='m') #将节点表示h作为信息发出
'对所有邻居节点特征hu进行平均,并使用它来覆盖原始节点特征。'
def reduce(nodes): #定义消息累和函数。对收到的消息进行平均。
accum = torch.mean(nodes.mailbox['m'], 1)
return {'h': accum}
'使用ReLU(Whv + b)更新节点特征hv.'
class NodeApplyModule(nn.Module): #对收到的消息应用线性变换和激活函数,将节点特征 hv 更新为 ReLU(Whv+b).
def __init__(self, in_feats, out_feats, activation):
super(NodeApplyModule, self).__init__()
self.linear = nn.Linear(in_feats, out_feats)
#class torch.nn.Linear(in_features, out_features, bias=True) 对输入数据作线性变换 y=Wx+b
self.activation = activation #还没指定是什么激活函数
def forward(self, node):
h = self.linear(node.data['h'])
h = self.activation(h)
return {'h' : h} #返回更新后的节点的特征 h(l+1)
'定义GCN'
#我们把所有的小模块串联起来成为 GCNLayer。
#GCN实际上是对所有节点进行 消息传递/聚合/更新
class GCN(nn.Module):
def __init__(self, in_feats, out_feats, activation):
super(GCN, self).__init__()
self.apply_mod = NodeApplyModule(in_feats, out_feats, activation)
def forward(self, g, feature):
g.ndata['h'] = feature #使用 h 初始化节点特征。
g.update_all(msg, reduce) #使用 update_all接口和自定义的消息传递及累和函数更新节点表示。
#DGLGraph.update_all([message_func, …]) 通过所有边发送消息并更新所有节点。
g.apply_nodes(func=self.apply_mod) #更新节点特征
#DGLGraph.apply_nodes([func, v, inplace]) 在节点上应用该函数以更新它们的特征。
return g.ndata.pop('h')
#pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。2.5 Readout and Classification
读出(Readout)操作的输入是图中所有节点的表示,输出则是整张图的表示。在 Google 的 Neural Message Passing for Quantum Chemistry(Gilmer et al. 2017) 论文中总结过许多不同种类的读出函数。在这个示例里,我们对图中所有节点表示取平均以作为图的表示:

DGL 提供了许多读出函数接口,以上公式可以很方便地用dgl.mean_nodes完成。最后我们将图的表示输入分类器。分类器对图表示先做了一个线性变换然后得到每一类在 softmax 之前的 logits。具体代码如下:
- func:
dgl.mean_nodes:处理不同形状的图卷积后的输出
'读出和分类'
import torch.nn.functional as F
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
super(Classifier, self).__init__()
#两层GCN(图卷积) 一层线性分类
self.layers = nn.ModuleList([
GCN(in_dim, hidden_dim, F.relu),
GCN(hidden_dim, hidden_dim, F.relu)])
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g):
# 对于无向图 入度=出度
h = g.in_degrees().view(-1, 1).float() #使用节点度数作为初始节点表示
for conv in self.layers: #图卷积层
h = conv(g, h)
g.ndata['h'] = h
hg = dgl.mean_nodes(g, 'h') #读出函数 #每个图的所有节点的输出特征的均值作为图的表示
return self.classify(hg) #分类层 #将图的表示输入分类器2.6 Setup and Training 准备和训练
之后的训练过程和其他经典的图像,语音分类问题基本一致。首先我们创建了一个包含 400 张节点数量为 10~20 的合成数据集。其中 320 张图作为训练数据集,80 张图作为测试集。