学Python好还是学R好?

“R诚可贵,Python价更高?”
本文约1200字,阅读需要4分钟
关键词:Python R 爬虫
本文讲述了使用pyt hon和R写爬虫,并进行对比的过程
p.s. 文末有福利大家自取~
最近一直有人问我,R和Python哪个比较简单,我应该学习哪一个好。对于这种@#¥%&@#&*的问题,我一般是这样回答的:都挺简单的,两个一起学吧,技多不压身!(内心:学不会,哪个都不好!)
当然,以上都是玩笑。为了认真,客观,精准地回答这个问题,我开始了R语言的学习之路,我要用我的亲身经历来告诉大家,“真的很简单!”
在我学习了一小时基本语法,
a <- 1b <- 1c <- a+bprint(c)
之后!我似有所悟~
我决定用R语言来写一个爬虫!并且决定用Python同样写一个爬虫!然后,形象生动地对比两者之间的区别。
任务准备
爬取的网站,是被誉为爬虫教科书级的网站——链家网。数千万爬虫工程师起步的地方。内容:爬取上海二手房前100页所有房源的标题,基本信息,价格和每平米单价。
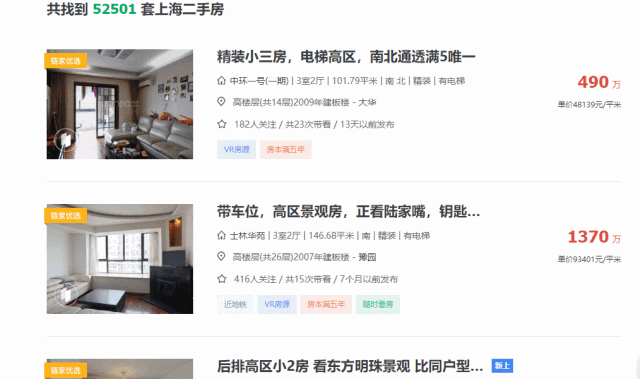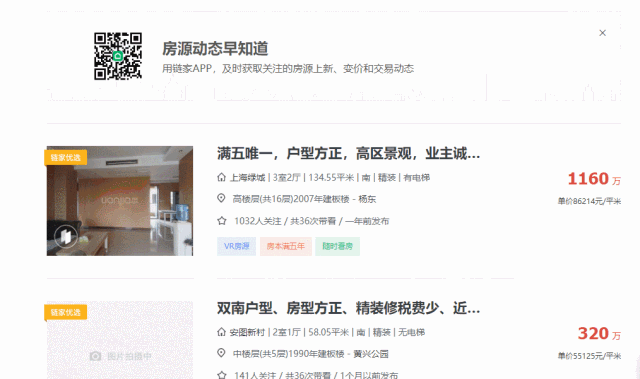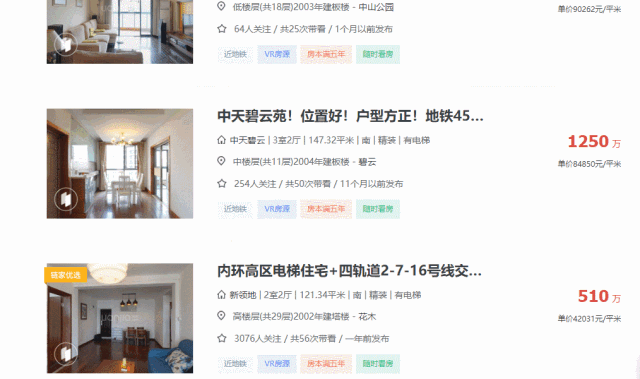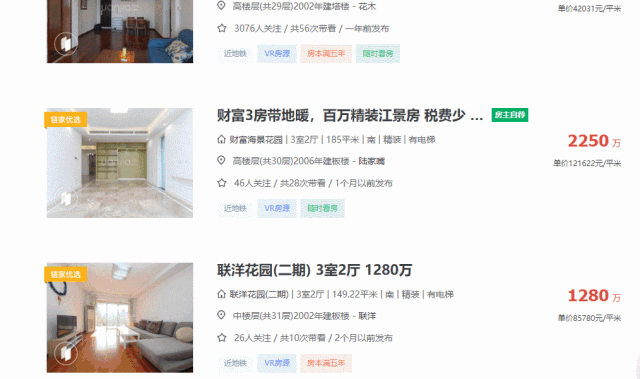
接下来,我们进入代码编辑环节。
关于爬虫逻辑,分析地址,通过选择器提取信息,数据存储等,这里就不赘述了。如果大家有点忘记了,可以往前翻阅公众号,有许多内容呢~
代码编辑
第一步:导入工具包
R:
#导入工具包library(dplyr)library(rvest)library(stringr)
R语言用library导入R包,这里有三个包,dplyr是做数据处理的,相当于python中的pandas,rvest用于网络爬虫解析,stringr用于字符串处理。
Python:
#导入工具包import pandas as pdimport requestsfrom bs4 import BeautifulSoup
Python用import导入工具包,这些大家都很熟悉了,pandas数据处理神器,requests用于访问网页,beautifulsoup,当然是用于爬虫解析。
第二步:创建存储数据的数据表和链接地址
R:
#创建数据表和链接地址house_data <- data.frame()urls <- 'https://sh.lianjia.com/ershoufang/pg'
R中的赋值符号是“<-”,而不是“=”,切记!,这里创建DataFrame数据结构和网址的统一路径。
Python:
#创建数据表和链接地址house_data = pd.DataFrame(columns=['title','inf','price','price_per'])urls = 'https://sh.lianjia.com/ershoufang/pg'
因为python数据分析的一些逻辑和结构很大程度上借鉴了R,比如,DataFrame数据结构。所以,这里写法几乎完全一致。
第三步:编写循环,遍历网页
R:
#循环爬取前100页for (i in 1:100){
R的控制结构和传统的编程语言一样, for后面用小括号定义循环范围,花括号里是循环主体逻辑。
Python:
#循环爬取前100页for i in range(1,101):
而相比较而言,python就简单的多,它是用严格的四格缩进,来区分代码结构的。
第四步:生成URL,并读取网页
R:
#遍历页码,生成URL url <- str_c(urls,i) web <- read_html(url)
R中,字符串合并,我们用到了str_c()函数,合并URL前半段和最后的页码。
Pyhton:
#遍历页码,生成URL url = urls + str(i) web = BeautifulSoup(requests.get(url).text,'lxml')
Python中字符串合并,直接相加就行。
第五步:使用选择器提取信息
R:
#使用选择器提取信息 title <- web %>% html_nodes('body > div.content > div.leftContent > ul > li> div.info.clear > div.title > a') %>% html_text() inf <- web %>% html_nodes('body > div.content > div.leftContent > ul > li > div.info.clear > div.address > div') %>% html_text() price <- web %>% html_nodes('body > div.content > div.leftContent > ul > li > div.info.clear > div.priceInfo > div.totalPrice > span') %>% html_text() price_per <- web %>% html_nodes('body > div.content > div.leftContent > ul > li > div.info.clear > div.priceInfo > div.unitPrice > span') %>% html_text() print(paste('正在爬取第',i,'页数据'))
用selector选择器提取信息,谷歌浏览器,查一查,直接粘就OK。值得一说的是“%>%”这个符号,这是R语言中的连接符,类似于python中连接方法的”.”,具体用法如下图:
#下面两行是等效的filter(data,a==1)data %>% filter(a==1)
大家理解一下……
Python:
#使用选择器提取信息 titles = web.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.title > a') infs = web.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.address > div') prices = web.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.priceInfo > div.totalPrice > span') price_pers = web.select('body > div.content > div.leftContent > ul > li > div.info.clear > div.priceInfo > div.unitPrice > span') print('正在爬取第' + str(i) + '页数据')
其实就是函数或方法的名字换了一换,本质上并没有区别。
第六步:整理数据
R:
#整合数据 house_information <- data_frame(title,inf,price,price_per) house_data <- rbind(house_data,house_information)}
总感觉R语言对数据结构的认知比Python要高,所以这里的操作非常简单,直接把爬取的信息往dataframe中写入就行。
Python:
#整合数据 for title,inf,price,price_per in zip(titles,infs,prices,price_pers): house_information = [title.get_text(),inf.get_text(),price.get_text(),price_per.get_text()] house_data = pd.concat([house_data,pd.DataFrame([house_information],columns=['title','inf','price','price_per'])])
而Python略显麻烦,需要通过列表转换一下,再写入dataframe,但从另一个角度,Python的拓展性,也是R无可比拟的。其次,理解Python更显得容易一点,因为其结构更基础。
第七步:写入数据
R:
#写入CSVsetwd("H:/R语言爬虫/")write.csv(house_data,file = './R_data.csv',row.names = FALSE)
R语言需要先规定工作目录才能使用相对路径。
Python:
#写入CSVhouse_data.to_csv('./Python_data.csv',index=0)
Python这一步可以省略,默认脚本所在之处为工作目录。当然你也可以使用os.getcwd()设置。
完成数据爬取,查看结果:
方便查看,左边是Python爬虫的结果,右边是R的结果~
从整个过程来看,其实R与Python两者数据工作方面操作逻辑并没有很大不同,除了语法结构上。
所以,
R和Python哪个比较简单,我应该学习哪一个好?
我的答案是:当然是Python!
![]()
关注“大鹏教你玩数据”,更多python教程等你拿~
本文作者:聚聚
编辑:木木
扫码关注我们
关注送狗子表情包一张&精选python资料一份

用数据改变未来