利用python分析:2018年北京积分落户数据
‘’’
本次分析的数据是2018年北京积分落户数据分析
这个数据是从官网上下载下来的,因此此数据不存在数据缺失,不需要做数据清洗
本文是使用numpy、pandas和matplotlib来分析此数据
可以分析的数据
1.关于公司:
1)哪些公司落户北京的人多
2.关于积分
1)哪个积分区间人最多
3.关于生日
1)落户北京的年龄范围
‘’’
#导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#将csv导入到jupyter,并将id设置为行索引
luohu_data = pd.read_csv(’./bj_luohu.csv’,index_col= ‘id’)
#查看数据前五行,看看数据是什么,有哪些信息
luohu_data.head()
#涉及名字这个敏感信息,将姓名列删除
luohu_data =luohu_data.drop(columns=[‘name’])
luohu_data.head()
‘’’
1.分析公司相关的数据
1)哪些公司落户北京的人多
‘’’
#按照公司进行分组,不重新设置索引,并查看每个公司被重复的次数
company_data = luohu_data.groupby(‘company’,as_index=False).count()[[‘company’,‘score’]]
company_data

#优化下结果
#将列索引的‘score’更换为‘people_count’
#将所有以‘people_count’列从大到小排序
company_data.rename(columns={‘score’:‘people_count’},inplace=True)
company_sorted_data = company_data.sort_values(‘people_count’,ascending=False)
company_sorted_data
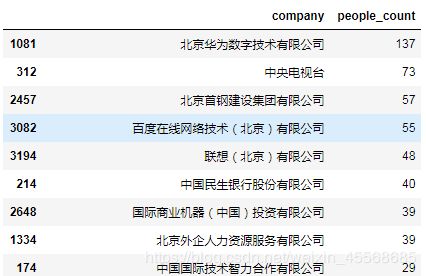
#查看排名前20的公司和人数
company_sorted_data.head(20)

‘’’
北京华为数字技术有限公司
中央电视台
北京首钢建设集团有限公司
百度在线网络技术(北京)有限公司
联想(北京)有限公司
中国民生银行股份有限公司
国际商业机器(中国)投资有限公司
北京外企人力资源服务有限公司
174 中国国际技术智力合作有限公司
华为技术有限公司北京研究所
爱立信(中国)通信有限公司
腾讯科技(北京)有限公司
北京阿里巴巴云计算技术有限公司
中国石油天然气股份有限公司管道北京输油气分公司
用友软件股份有限公司
暂时无法统计到这些公司的总申请数(因此这里忽略)
这些公司落户人数在20人以上
单从现有数据说明如果进这些公司,在北京落户的概率会高些
题外:BAT,华为都有哦,还是去大厂吧
看到了用友软件有些意外,之前做财务时用到过这个软件,在转行做it这段时间虽然经常看互联网的新闻,但是很少看到用友,唯一一次看到是在这篇文章:2018科技赋能B端新趋势白皮书,有兴趣的朋友可以去看看:原文地址
‘’’
‘’’
2.关于积分
1)哪个积分区间人最多
‘’’
#describe下这个数据
luohu_data.describe()
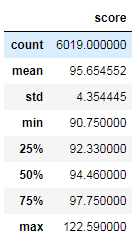
‘’’
落户分数
最高分122.59
最低分90.75
平均分95.65
第一四分位数 92.33
第二四分位数94.56
第三四分位数97.75
平均分>第二四分位数,说明大部分人在平均分以下
‘’’
#从describe后的数据来看,最低分90.75,最高分122.59,创建一个区间(90,130,5)
score_section = np.arange(90,130,5)
#每个分数落在哪个区间
score_data = pd.cut(luohu_data[‘score’],score_section )
score_data

#查看每个区间总共有多少人
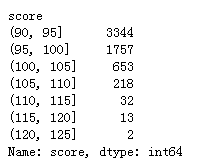
score_data_count = luohu_data[‘score’].groupby(score_data).count()
score_data_count
#把左‘(’和右‘]’去掉,‘,’加上‘~’作为区分
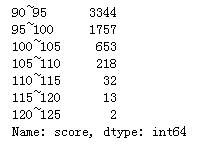
score_data_count.index = [str(x.left) + ‘~’ + str(x.right) for x in score_data_count.index]
score_data_count
‘’’
绘制饼状图,查看每个区间所占的比例
‘’’
import matplotlib
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname=‘C:\Windows\Fonts\simfang.ttf’,size=18)
#设置画布大小
plt.figure(figsize=(8,8),dpi=100)
#设置饼状图相关信息
#各部分标签
label_list = [‘90到95’,‘95到100’,‘100到105’,‘105到110’,‘110到115’,‘115到120’,‘120到125’]
#各部分大小
size = [value for value in score_data_count]
#各部分颜色
color = [‘red’,‘green’,‘blue’,‘yellow’,‘orange’,‘gray’,‘black’]
#各部分突出值
explode = [0,0,0,0,0,0,0]
patches, l_text, p_text = plt.pie(size,
explode=explode,
colors=color,
labels=label_list,
labeldistance=1.1,
autopct="%1.1f%%",
shadow=False,
startangle=90,
pctdistance=0.6)
for t in l_text:
dir((t))
t.set_fontproperties(my_font)
for t in l_text:
print(t.get_alpha())
t.set_fontproperties(my_font)
plt.show()
‘’’
描述重叠的问题暂时在网上没有找到解决方法,如果哪位大神有方法欢迎留言
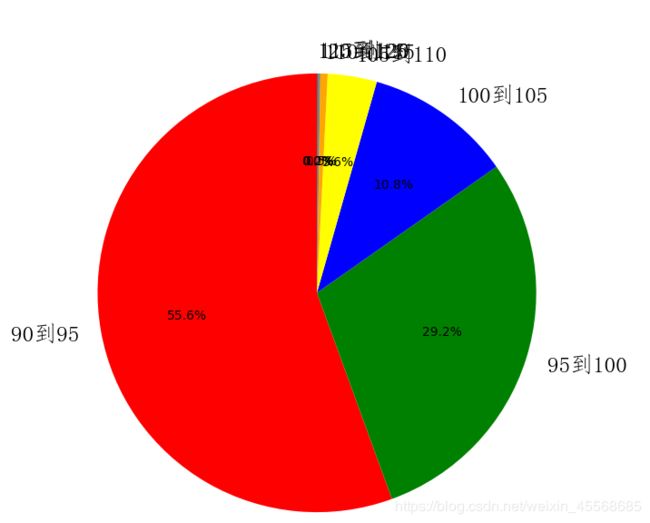
从饼状图的数据来看,90到95的比例最高达到了55.6%
加上前面的数据
平均分95.65
第一四分位数 92.33
第二四分位数94.56
第三四分位数97.75
平均分95.65>95>第二四分位数94.56
说明大部分人的分数是在90到95这个区间,这个区间竞争非常激烈
如果你的分数在这个区间,可以考虑去前面推荐的那些公司,对于你落户北京会有帮助
‘’’
‘’’
3.关于生日
1)落户北京的年龄范围
‘’’
#此数据现在是生日,需要先转化为年龄再做分析
#新增年龄列,并将得出的结果插入在此列
luohu_data[‘age’] = (pd.to_datetime(‘2018-12’) - pd.to_datetime(luohu_data[‘birthday’])) / pd.Timedelta(‘365 days’)
#查看下插入后的数据
luohu_data.head()

#再describe下
luohu_data.describe()
‘’’
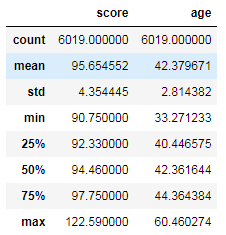
最小年纪:33.2
最大年纪:60.4
平均分42.3
第一四分位数 40.4
第二四分位数42.3
第三四分位数44.3
最小年纪是33.2岁,也就是说如果你现在的年龄小于33.2岁就不要想落户北京了
‘’’
#从describe后的数据来看,最小年纪:33.2,最大年纪:60.4,创建一个区间(30,70,5)
age_section = np.arange(30,70,5)
#每个年龄落在哪个区间
age_data = pd.cut(luohu_data[‘age’],age_section )
age_data

#查看每个区间有多少人
age_data_count = luohu_data[‘age’].groupby(age_data).count()
age_data_count

#把左‘(’和‘]’去掉,加上‘~’作为区分
age_data_count.index = [str(x.left) + ‘~’ + str(x.right) for x in age_data_count.index]
age_data_count

‘’’
绘制饼状图,查看每个区间所占的比例
‘’’
#设置画布大小
plt.figure(figsize=(8,8),dpi=100)
#设置饼状图相关信息
#各部分标签
label_list = [‘30到35’,‘35到40’,‘40到45’,‘45到50’,‘50到55’,‘55到60’,‘60到65’]
#各部分大小
size = [value for value in age_data_count]
#各部分颜色
color = [‘red’,‘green’,‘blue’,‘yellow’,‘orange’,‘gray’,‘black’]
#各部分突出值
explode = [0,0,0,0,0,0,0]
patches, l_text, p_text = plt.pie(size,
explode=explode,
colors=color,
labels=label_list,
labeldistance=1.1,
autopct="%1.1f%%",
shadow=False,
startangle=90,
pctdistance=0.6)
for t in l_text:
dir((t))
t.set_fontproperties(my_font)
for t in l_text:
print(t.get_alpha())
t.set_fontproperties(my_font)
plt.show()
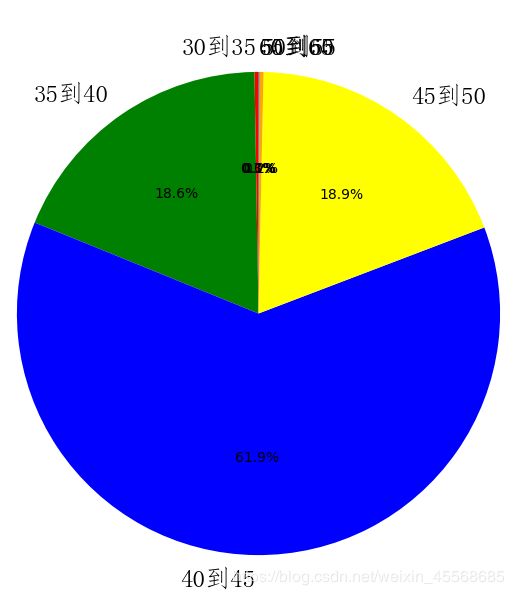
‘’’
跪求大神帮忙
因为不知道这些人是什么时候来北京工作的这个数据,我们在这里只分析这些人落户北京的年龄
从饼状图来看,大部分的人是在40到45岁之间落户北京
35岁到50岁占了99.4%,也就是说,超过了50岁基本就不用想落户北京的事儿了
但是60多岁的人还在拼命落户北京,你还有什么脸不拼命???
哈哈,开个玩笑
‘’’
以上是利用python分析:2018年北京积分落户数据
还可以分析
公司、年龄、分数的细化
公司和年龄两者之间的关系
公司和分数两者之间的关系
年龄和分数两者之间的关系
公司、年龄和分数三者之间的关系
欢迎互动交流,不足之处请指正
谢谢您的时间