检测与姿态估计的评价标准
1. 通用目标检测中AP, mAP指标的定义和计算
转载自 点击打开链接 点击打开链接
多标签图像分类(Multi-label Image Classification)任务中图片的标签不止一个,因此评价不能用普通单标签图像分类的标准,即mean accuracy,该任务采用的是和信息检索中类似的方法—mAP(mean Average Precision)。mAP虽然字面意思和mean accuracy看起来差不多,但是计算方法要繁琐得多,以下是mAP的计算方法:
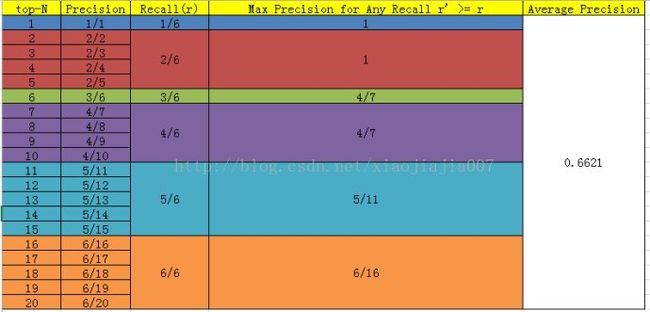
首先用训练好的模型得到所有测试样本的confidence score,每一类(如car)的confidence score保存到一个文件中(如comp1_cls_test_car.txt)。假设共有20个测试样本,每个的id,confidence score和ground truth label如下:
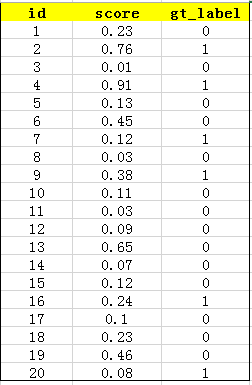
接下来对confidence score排序,得到:

这张表很重要,接下来的precision和recall都是依照这个表计算的
然后计算precision和recall,这两个标准的定义如下:
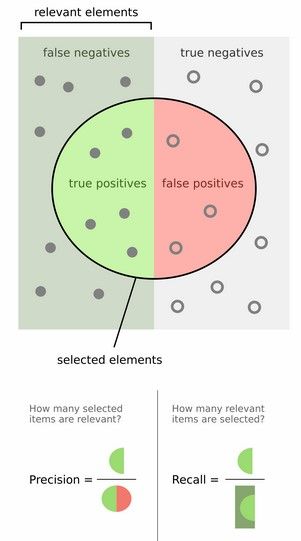
上图比较直观,圆圈内(true positives+ false positives)是我们选出的元素,它对应于分类任务中我们取出的结果,比如对测试样本在训练好的car模型上分类,我们想得到top-5的结果,即:
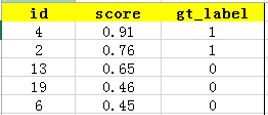
在这个例子中,true positives就是指第4和第2张图片,false positives就是指第13,19,6张图片。方框内圆圈外的元素(false negatives和true negatives)是相对于方框内的元素而言,在这个例子中,是指confidence score排在top-5之外的元素,即:
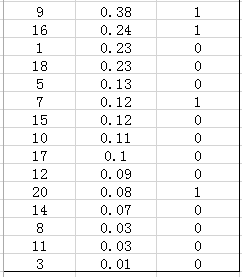
其中,false negatives是指第9,16,7,20张图片,true negatives是指第1,18,5,15,10,17,12,14,8,11,3张图片。
那么,这个例子中Precision=2/5=40%,意思是对于car这一类别,我们选定了5个样本,其中正确的有2个,即准确率为40%;Recall=2/6=30%,意思是在所有测试样本中,共有6个car,但是因为我们只召回了2个,所以召回率为30%。
实际多类别分类任务中,我们通常不满足只通过top-5来衡量一个模型的好坏,而是需要知道从top-1到top-N(N是所有测试样本个数,本文中为20)对应的precision和recall。显然随着我们选定的样本越来也多,recall一定会越来越高,而precision整体上会呈下降趋势。把recall当成横坐标,precision当成纵坐标,即可得到常用的precision-recall曲线。这个例子的precision-recall曲线如下:
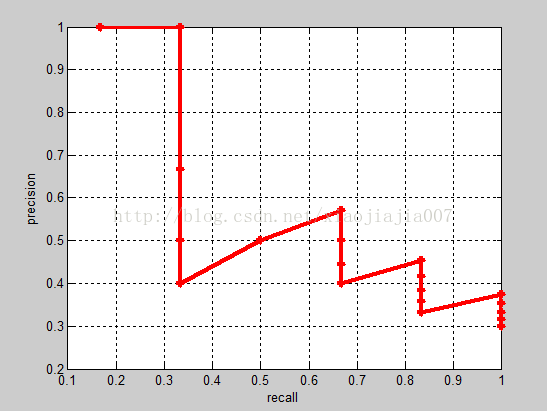
接下来说说AP的计算,此处参考的是PASCAL VOC CHALLENGE的计算方法。首先设定一组阈值,[0, 0.1, 0.2, …,1]。然后对于recall大于每一个阈值(比如recall>0.3),我们都会得到一个对应的最大precision。这样,我们就计算出了11个precision。AP即为这11个precision的平均值。这种方法英文叫做11-pointinterpolated average precision。
当然PASCAL VOCCHALLENGE自2010年后就换了另一种计算方法。新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M,2/M, ..., M/M),对于每个recall值r,我们可以计算出对应(r' >r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。计算方法如下:
相应的Precision-Recall曲线(这条曲线是单调递减的)如下:
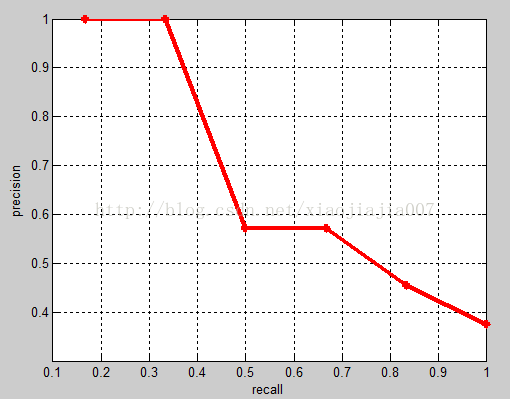
注: 这种标准比前面那个AP更加科学,比如当前面所有的 True Positive都被检测出来,此时 top-N 变成 top-N+1时,recall保持不变,precision也能够保持不变,而前一种的prcision却会变小,但这并不意味着应该认为检测效果差了
AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
两种不同AP计算方式的区别 见 点击打开链接
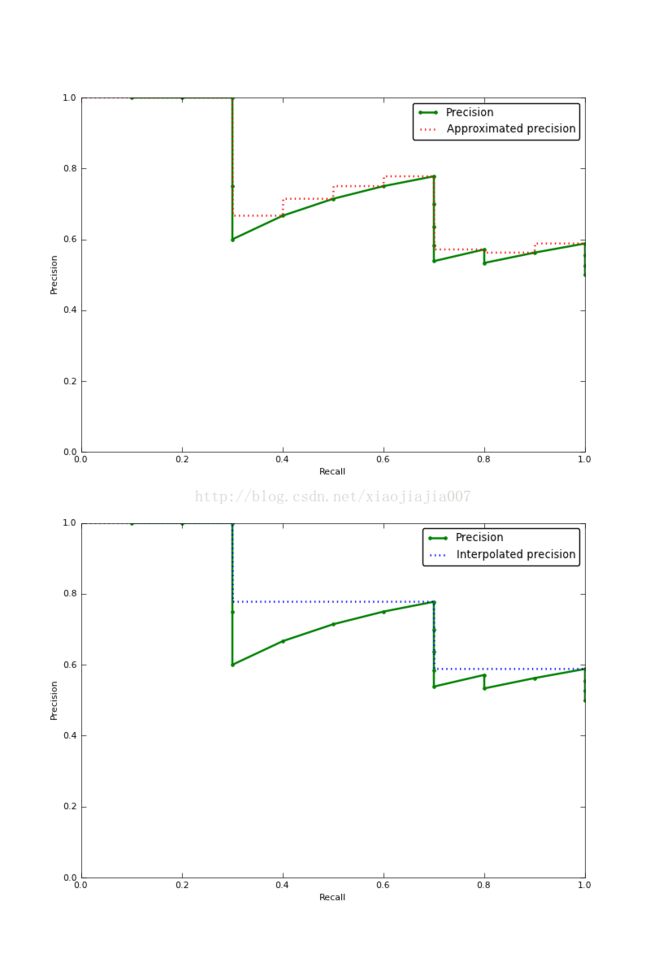
2. COCO数据集中的姿态估计评测指标AP定义:
详情可以参阅COCO官网说明:http://cocodataset.org/#keypoints-eval
需要特别注意的地方就是COCO对于人体姿态估计的AP定义 综合考虑了对于不同关键点类型(sigma)和人物大小尺寸s( each ground truth object also has a scale s which we define as the square root of the object segment area)的归一化,这样评估更加科学。比如相同的绝对定位误差,对于大的人物和范围大的关键点(如膝盖),对于小的人物和范围小的关键点(如眼睛),相同偏差值带来的误差百分比是完全不同的。
COCO中的关键点相似性度量指标OKS定义如下:
![]()
在这里首先补充一下COCO数据集中关于visible标签v的说明:
# -------------------------------原始coco关于visible标签的定义--------------------------------# # 第三个元素是个标志位v,v为0时表示这个关键点没有标注(这种情况下x = y = v = 0), # v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。 # ------------------------------------ ---------------------------- ---------------------#
对于每个关键点,COCO数据集制造者收集了一个包含5000张重复标注的图片,然后统计每一类关键点的相对于目标人物尺寸的标注方差,即:![]() . 为了使得认为定义的关键点相似性度量指标能够有一个直观上的合理性,接着在OKS指标中又人为做了一个新的定义:
. 为了使得认为定义的关键点相似性度量指标能够有一个直观上的合理性,接着在OKS指标中又人为做了一个新的定义:![]() (
(我理解这里面的2sigma是实验出来的,因为真正的σi是无法计算出来的,这里使用5000个样本所得的只是一个估计值,因此作者通过增加比例参数调整发现当参数为2时,实验所得的结果符合68–95–99.7规则 摘自). 如此一来呢,对于关键点“3 原则”处,也就是在
原则”处,也就是在![]() 将会有OKS相似度量值
将会有OKS相似度量值![]() 。正如所料,人类注释的关键点是正态分布的(忽略偶尔的异常值), 而3对应的概率值分别为 68–95–99.7%。 也就是说当我们设
。正如所料,人类注释的关键点是正态分布的(忽略偶尔的异常值), 而3对应的概率值分别为 68–95–99.7%。 也就是说当我们设![]() 时,68%, 95%, and 99.7% of human annotated keypoints should have a keypoint similarity of .88, .61, or .32 or higher, respectively (实际的统计数据结果为:in practice the percentages are 75%, 95% and 98.7%,大致符合68-95-99.7).
时,68%, 95%, and 99.7% of human annotated keypoints should have a keypoint similarity of .88, .61, or .32 or higher, respectively (实际的统计数据结果为:in practice the percentages are 75%, 95% and 98.7%,大致符合68-95-99.7).
那官网中介绍评测指标的剩余部分也就不难理解了:
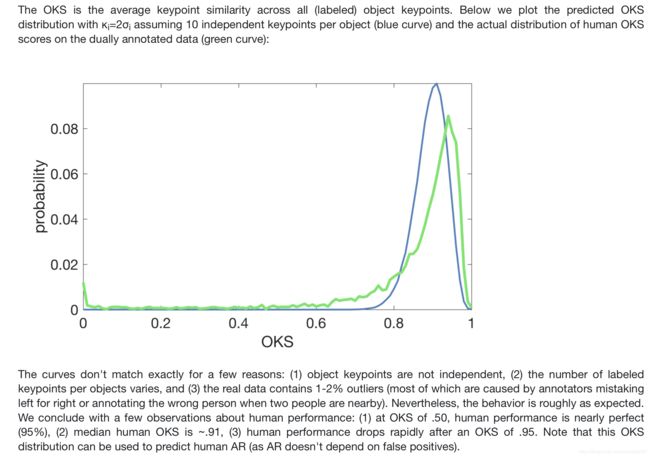
可以看出实际统计值和理论值基本相符。

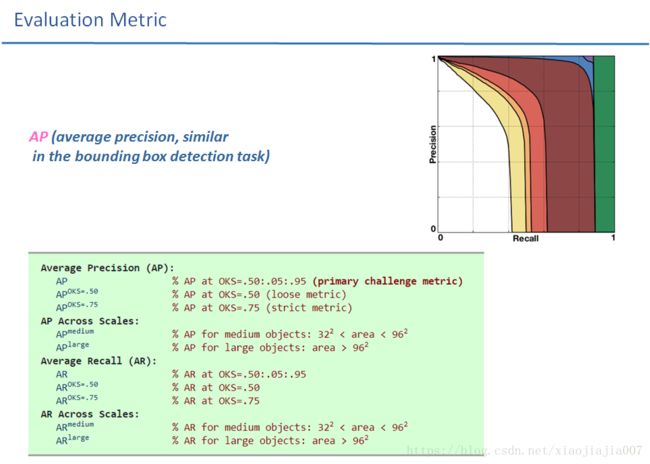
介绍完了相似性度量指标OKS,就可以类比于目标检测中的IoU相似性度量指标,对人体姿态估计AP做一个定义了,如下所述:

3. Detailed breakdown of the errors at a OKS threshold的PR曲线的意义
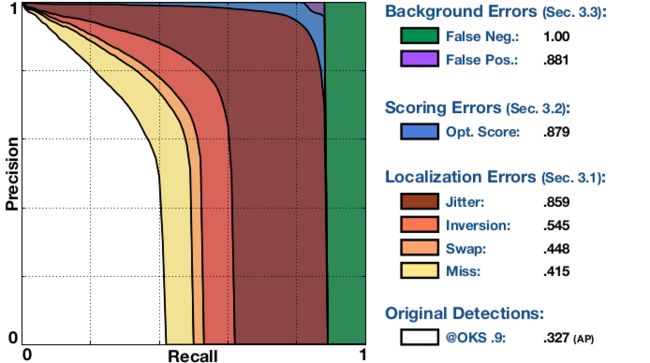
The plot summarizes the impact of all types of error on the performance of a multi-instance pose estimation algorithm. It is composed of a series of Precision Recall (PR) curves where each curve is guaranteed to be strictly higher than the previous as the algorithm's detections are progressively corrected at an (arbitrary) OKS threshold of .9. The legend shows the Area Under the Curve (AUC). The curves are as follows (check project page for a full description):
- Original Dts.: PR obtained with the original detections at OKS=.9 (AP at strict OKS), area under curve corresponds to APOKS=.9 metric.
- Miss: PR at OKS=.9 (AP at strict OKS), after all miss errors have been corrected. A miss is a large localization error: the detected keypoint is not within the proximity of the correct body part.
- Swap: PR at OKS=.9 (AP at stric OKS), after all swap errors have been corrected. A swap is due to the confusion between the same body part of different people in an image (i.e. right elbow).
- Inversion: PR at OKS=.9 (AP at stric OKS), after all inversion errors have been corrected. An inversion is due to the confusion of body parts within the same person (i.e. left and right elbow).
- Jitter: PR at OKS=.9 (AP at strict OKS), after all jitter errors have been corrected. A jitter is a small localization error: the detected keypoint is within the proximity of the correct body part.
- Opt. Score: PR at OKS=.9 (AP at strict OKS), after all the algorithm's detections have been rescored using an oracle function computed at evaluation time. As a result of the rescoring the number of matches between detections and ground-truth instances is maximized.
- FP: PR after all background fps are removed. FP is a step function that is 1 until max recall is reached then drops to 0 (the curve is smoother after averaging across categories).
- FN: PR after all remaining errors are removed (trivially AP=1).
FP: PR after all background fps are removed. FP is a step function that is 1 until max recall is reached then drops to 0 (the curve is smoother after averaging across categories).
为什么一直保持1然后突然变成0呢?
答:一旦去除了FP,则只剩正样本,精度肯定恒为1了。之后那一部分的AP improvement全部都是由没有检测到的正样本FN贡献的,不存在FP了,所以移除FP也不会带来AP improvement,因此FP那条曲线立刻降到零。