Python正则表达式学习
1、re模块
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为re。
实例
#coding=utf-8
# 导入re模块
import re
# 使用match方法进行匹配操作
# result = re.match(正则表达式,要匹配的字符串)
result = re.match("itcast","itcast.cn sex") #匹配成功,返回匹配对象,否则返回None,不是""
# 如果上一步匹配到数据的话,可以使用group方法来提取数据,必须是itcast开头
print(result.group()) 运行结果:
itcast2、单字符匹配
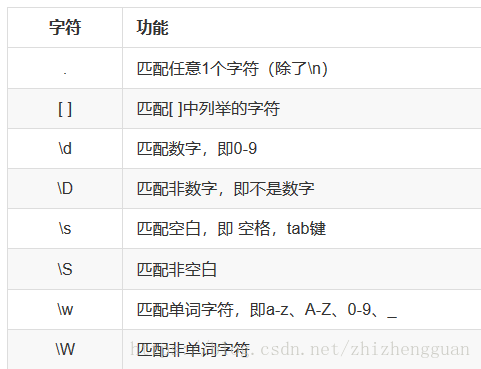
#coding=utf-8
import re
ret = re.match(".S","ASa") #AS
print(ret.group())
ret = re.match("[0123456789]\w","7Hello Python") #7H
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥2号发射成功") #嫦娥2号
print(ret.group())
ret = re.match("\D\D\S","嫦娥2号发射成功") #嫦娥2
print(ret.group())
3、原生字符串
Python中字符串前面加上 r 表示原生字符串
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原始字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
#coding=utf-8
import re
mm = "c:\\a\\b\\c"
print(mm) #c:\a\b\c
print(re.match("c:\\\\",mm).group()) #c:\
print(re.match("c:\\\\a",mm).group())
print(re.match(r"c:\\a",mm).group()) #c:\a
print(re.match(r"c:\a",mm).group())
#Traceback (most recent call last):
# File "", line 1, in
# AttributeError: 'NoneType' object has no attribute 'group' 4、表示数量

import re
print(re.match("[A-Z][a-z]*", "Mcewf").group())
print(re.match("[a-zA-Z_]+[\w]*", "_name1_").group()) #匹配出,变量名是否有效
print(re.match("[1-9]?[0-9]*", "0").group())#匹配出,0到99之间的数字
print(re.match("[a-zA-Z0-9_]{6}", "1ad12f23s34455ff66").group()) #匹配前一个字符出现m次
print(re.match("[a-zA-Z0-9_]{9,20}", "1ad12f23s34455ff66").group()) #匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
5、表示边界

import re
print(re.match("[\w]{4,20}@163\.com$", "[email protected]").group()) #匹配163.com的邮箱地址
print(re.match(r".*\bver\b", "ho ver abc").group())
print(re.match(r".*\Bver\B", "hocverabc").group())6、匹配分组
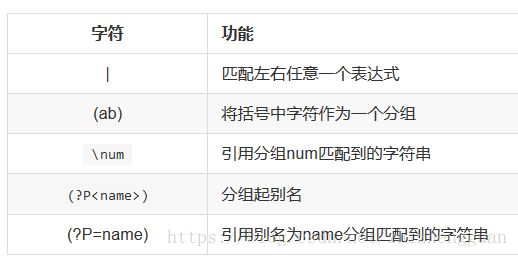
import re
print(re.match("[1-9]?\d$|100", "100").group()) #匹配出0-100之间的数字
print(re.match("\w{4,20}@(163|126|qq)\.com$", "[email protected]").group()) #[email protected]
ret = re.match("([^-]*)-(\d+)","11000-12345678")
print(ret.group(1)) #11000
print(ret.group(2)) #12345678 +表示前1个字符至少出现1次
print(re.match(r"<([a-zA-Z]*)>\w*", "hh ").group()) #匹配出hh
#如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
print(re.match(r"<(\w*)><(\w*)>.*", "www.itcast.cn
").group()) #匹配出www.itcast.cn
print(re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn
").group())#匹配出www.itcast.cn
7、其他
import re
print(re.search(r"\d+", "阅读次数为 9999").group()) #9999 匹配出文章阅读的次数
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345") #统计出python、c、c++相应文章阅读的次数\
print(ret) #['9999', '7890', '12345']
print(re.sub(r"\d+", '265898', "python = 997")) #python = 265898 sub将匹配到的数据进行替换
print(re.split(r":| ", "“info:xiaoZhang 33 shandong”")) #['“info', 'xiaoZhang', '33', 'shandong”'] split 根据匹配进行切割字符串,并返回一个列表
8、python贪婪和非贪婪
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串。非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
print(re.match(r"aa(\d+)","aa2343ddd").group(1)) #2343
print(re.match(r"aa(\d+?)","aa2343ddd").group(1)) #2
print(re.match(r"aa(\d+)ddd","aa2343ddd").group(1) ) #2343
print(re.match(r"aa(\d+?)ddd","aa2343ddd").group(1)) #2343