车道线检测
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
CNN:RCNN、SPPNet、Fast RCNN、Faster RCNN、YOLO V1 V2 V3、SSD、FCN、SegNet、U-Net、DeepLab V1 V2 V3、Mask RCNN
车道线检测
相机校正、张氏标定法、极大似然估计/极大似然参数估计、牛顿法、高斯牛顿法、LM算法、sin/cos/tan/cot
相机校正和图像校正:图像去畸变
车道线提取:Sobel边缘提取算法
透视变换
车道线定位及拟合:直方图确定车道线位置
车道曲率和中心点偏离距离计算
在视频中检测车道线
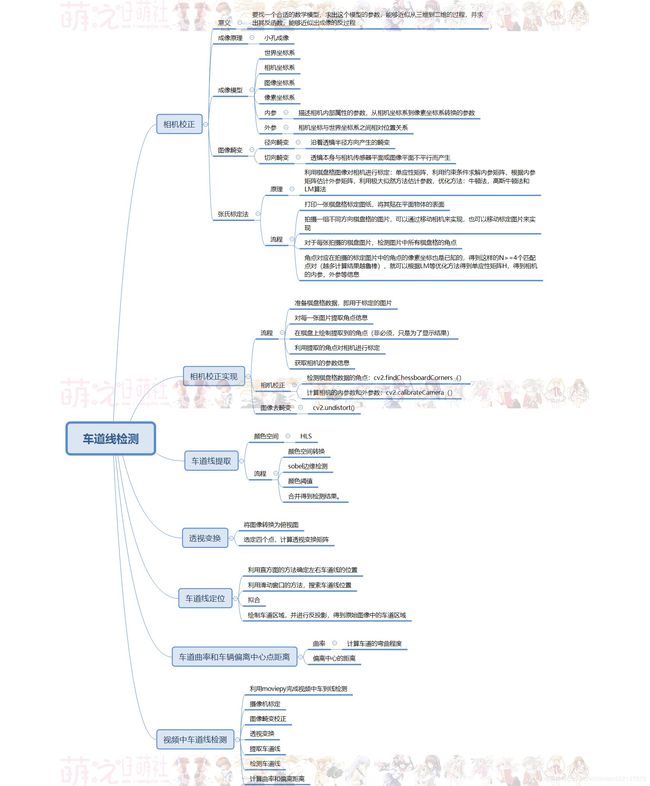
5.车道线检测实现
项目简介
汽车的日益普及在给人们带来极大便利的同时,也导致了拥堵的交通路况,以及更为频发的交通事故。而自动驾驶技术的出现可以有效的缓解了此类问题,减少交通事故,提升出行效率。
自动驾驶的首要任务就是准确的识别出车道线并根据车道线的指示进行行驶。在人为因素导致的交通事故中,因汽车偏离正常轨道致使的交通事故占总事故的发生的50%,据美国联邦公路局统计,如果能在事故前一秒能够以报警的方式提醒驾驶员,那么将避免90%的交通事故,如此惊人的数据足以证明车道线在自动驾驶的安全行驶中具有重要的意义。
国内外检测车道线的方法主要有两类:一类是基于模型的检测方法,还有一类是基于特征的检测方法。
基于模型的检测方法是将车道赋予一种合适的数学模型,并基于该模型对车道线进行拟合,原理就是在结构化的道路上根据车道线的几何特征为车道线匹配合适的曲线模型,在采用最小二乘法,Hough变换等方法对车道线进行拟合。常用的数学模型有直线型、抛物线模型以及样条曲线模型。这种方法对噪声抗干扰能力强。但也存在弊端,即一种车道线模型不能同时适应多种道路场景。
基于特征的检测方法是根据车道线自身的特征信息,通过边缘检测或者阈值分割将车道线的特征信息从路面区域中提取出来。该方法对车道线的边缘特征要求较高,在边缘特征明显的情况下可获得较好的结果,但对噪声很敏感,鲁棒性较差。
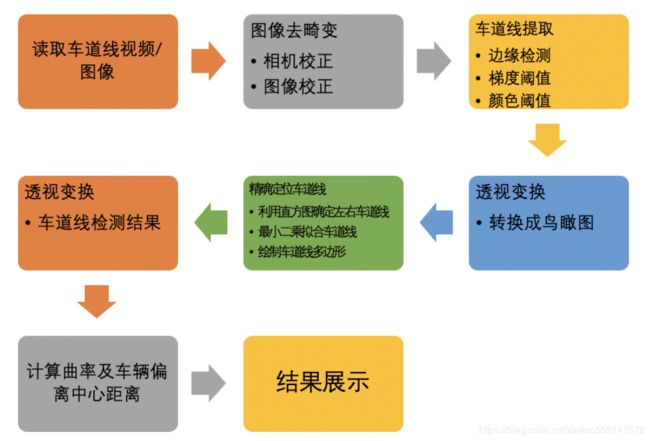
本项目针对车载相机获得的道路图像进行提取,主要是对图像进行校正,利用边缘提取和颜色阈值的方法提取车道线,利用透视变换将图像转换为鸟瞰图,利用直方图统计的方法确定左右车道位置,并利用最小二乘法拟合车道线,并利用透视变换将检测结果绘制在图像上,最后计算车道线的曲率及车辆偏离车道中央的距离,流程如下图所示:
该项目效果展示如下:
在视频中检测车道线

import cv2
import numpy as np
import matplotlib.pyplot as plt
import glob
from moviepy.editor import VideoFileClip
"参数设置"
nx = 9
ny = 6
file_paths = glob.glob("./camera_cal/calibration*.jpg")
# 绘制对比图
def plot_contrast_image(origin_img, converted_img, origin_img_title="origin_img", converted_img_title="converted_img",
converted_img_gray=False):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 20))
ax1.set_title = origin_img_title
ax1.imshow(origin_img)
ax2.set_title = converted_img_title
if converted_img_gray == True:
ax2.imshow(converted_img, cmap="gray")
else:
ax2.imshow(converted_img)
plt.show()
# 相机校正:外参,内参,畸变系数
def cal_calibrate_params(file_paths):
# 存储角点数据的坐标
object_points = [] # 角点在三维空间的位置
image_points = [] # 角点在图像空间中的位置
# 生成角点在真实世界中的位置
objp = np.zeros((nx * ny, 3), np.float32)
objp[:, :2] = np.mgrid[0:nx, 0:ny].T.reshape(-1, 2)
# 角点检测
for file_path in file_paths:
img = cv2.imread(file_path)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 角点检测
rect, coners = cv2.findChessboardCorners(gray, (nx, ny), None)
# imgcopy = img.copy()
# cv2.drawChessboardCorners(imgcopy,(nx,ny),coners,rect)
# plot_contrast_image(img,imgcopy)
if rect == True:
object_points.append(objp)
image_points.append(coners)
# 相机校正
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(object_points, image_points, gray.shape[::-1], None, None)
return ret, mtx, dist, rvecs, tvecs
# 图像去畸变:利用相机校正的内参,畸变系数
def img_undistort(img, mtx, dist):
dis = cv2.undistort(img, mtx, dist, None, mtx)
return dis
# 车道线提取
# 颜色空间转换——》边缘检测——》颜色阈值-》合并并且使用L通道进行白的区域的抑制
def pipeline(img, s_thresh=(170, 255), sx_thresh=(40, 200)):
# 复制原图像
img = np.copy(img)
# 颜色空间转换
hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS).astype(np.float)
l_chanel = hls[:, :, 1]
s_chanel = hls[:, :, 2]
# sobel边缘检测
sobelx = cv2.Sobel(l_chanel, cv2.CV_64F, 1, 0)
# 求绝对值
abs_sobelx = np.absolute(sobelx)
# 将其装换为8bit的整数
scaled_sobel = np.uint8(255 * abs_sobelx / np.max(abs_sobelx))
# 对边缘提取结果进行二值化
sxbinary = np.zeros_like(scaled_sobel)
sxbinary[(scaled_sobel >= sx_thresh[0]) & (scaled_sobel <= sx_thresh[1])] = 1
# plt.figure()
# plt.imshow(sxbinary, cmap='gray')
# plt.title("sobel")
# plt.show()
# s通道阈值处理
s_binary = np.zeros_like(s_chanel)
s_binary[(s_chanel >= s_thresh[0]) & (s_chanel <= s_thresh[1])] = 1
# plt.figure()
# plt.imshow(s_binary, cmap='gray')
# plt.title("schanel")
# plt.show()
# 结合边缘提取结果和颜色的结果,
color_binary = np.zeros_like(sxbinary)
color_binary[((sxbinary == 1) | (s_binary == 1)) & (l_chanel > 100)] = 1
return color_binary
# 透视变换
# 获取透视变换的参数矩阵
def cal_perspective_params(img, points):
offset_x = 330
offset_y = 0
img_size = (img.shape[1], img.shape[0])
src = np.float32(points)
# 设置俯视图中的对应的四个点
dst = np.float32([[offset_x, offset_y], [img_size[0] - offset_x, offset_y],
[offset_x, img_size[1] - offset_y], [img_size[0] - offset_x, img_size[1] - offset_y]])
# 原图像转换到俯视图
M = cv2.getPerspectiveTransform(src, dst)
# 俯视图到原图像
M_inverse = cv2.getPerspectiveTransform(dst, src)
return M, M_inverse
# 根据参数矩阵完成透视变换
def img_perspect_transform(img, M):
img_size = (img.shape[1], img.shape[0])
return cv2.warpPerspective(img, M, img_size)
# 精确定位车道线
def cal_line_param(binary_warped):
# 1.确定左右车道线的位置
# 统计直方图
histogram = np.sum(binary_warped[:, :], axis=0)
# 在统计结果中找到左右最大的点的位置,作为左右车道检测的开始点
# 将统计结果一分为二,划分为左右两个部分,分别定位峰值位置,即为两条车道的搜索位置
midpoint = np.int(histogram.shape[0] / 2)
leftx_base = np.argmax(histogram[:midpoint])
rightx_base = np.argmax(histogram[midpoint:]) + midpoint
# 2.滑动窗口检测车道线
# 设置滑动窗口的数量,计算每一个窗口的高度
nwindows = 9
window_height = np.int(binary_warped.shape[0] / nwindows)
# 获取图像中不为0的点
nonzero = binary_warped.nonzero()
nonzeroy = np.array(nonzero[0])
nonzerox = np.array(nonzero[1])
# 车道检测的当前位置
leftx_current = leftx_base
rightx_current = rightx_base
# 设置x的检测范围,滑动窗口的宽度的一半,手动指定
margin = 100
# 设置最小像素点,阈值用于统计滑动窗口区域内的非零像素个数,小于50的窗口不对x的中心值进行更新
minpix = 50
# 用来记录搜索窗口中非零点在nonzeroy和nonzerox中的索引
left_lane_inds = []
right_lane_inds = []
# 遍历该副图像中的每一个窗口
for window in range(nwindows):
# 设置窗口的y的检测范围,因为图像是(行列),shape[0]表示y方向的结果,上面是0
win_y_low = binary_warped.shape[0] - (window + 1) * window_height
win_y_high = binary_warped.shape[0] - window * window_height
# 左车道x的范围
win_xleft_low = leftx_current - margin
win_xleft_high = leftx_current + margin
# 右车道x的范围
win_xright_low = rightx_current - margin
win_xright_high = rightx_current + margin
# 确定非零点的位置x,y是否在搜索窗口中,将在搜索窗口内的x,y的索引存入left_lane_inds和right_lane_inds中
good_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]
good_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]
left_lane_inds.append(good_left_inds)
right_lane_inds.append(good_right_inds)
# 如果获取的点的个数大于最小个数,则利用其更新滑动窗口在x轴的位置
if len(good_left_inds) > minpix:
leftx_current = np.int(np.mean(nonzerox[good_left_inds]))
if len(good_right_inds) > minpix:
rightx_current = np.int(np.mean(nonzerox[good_right_inds]))
# 将检测出的左右车道点转换为array
left_lane_inds = np.concatenate(left_lane_inds)
right_lane_inds = np.concatenate(right_lane_inds)
# 获取检测出的左右车道点在图像中的位置
leftx = nonzerox[left_lane_inds]
lefty = nonzeroy[left_lane_inds]
rightx = nonzerox[right_lane_inds]
righty = nonzeroy[right_lane_inds]
# 3.用曲线拟合检测出的点,二次多项式拟合,返回的结果是系数
left_fit = np.polyfit(lefty, leftx, 2)
right_fit = np.polyfit(righty, rightx, 2)
return left_fit, right_fit
# 填充车道线之间的多边形
def fill_lane_poly(img, left_fit, right_fit):
# 获取图像的行数
y_max = img.shape[0]
# 设置输出图像的大小,并将白色位置设为255
out_img = np.dstack((img, img, img)) * 255
# 在拟合曲线中获取左右车道线的像素位置
left_points = [[left_fit[0] * y ** 2 + left_fit[1] * y + left_fit[2], y] for y in range(y_max)]
right_points = [[right_fit[0] * y ** 2 + right_fit[1] * y + right_fit[2], y] for y in range(y_max - 1, -1, -1)]
# 将左右车道的像素点进行合并
line_points = np.vstack((left_points, right_points))
# 根据左右车道线的像素位置绘制多边形
cv2.fillPoly(out_img, np.int_([line_points]), (0, 255, 0))
return out_img
# 计算车道线曲率
def cal_radius(img,left_fit,right_fit):
# 比例
ym_per_pix = 30/720
xm_per_pix = 3.7/700
# 得到车道线上的每个点
left_y_axis = np.linspace(0,img.shape[0],img.shape[0]-1)
left_x_axis = left_fit[0]*left_y_axis**2+left_fit[1]*left_y_axis+left_fit[0]
right_y_axis = np.linspace(0,img.shape[0],img.shape[0]-1)
right_x_axis = right_fit[0]*right_y_axis**2+right_fit[1]*right_y_axis+right_fit[2]
# 把曲线中的点映射真实世界,在计算曲率
left_fit_cr = np.polyfit(left_y_axis*ym_per_pix,left_x_axis*xm_per_pix,2)
right_fit_cr = np.polyfit(right_y_axis*ym_per_pix,right_x_axis*xm_per_pix,2)
# 计算曲率半径
left_curverad = ((1+(2*left_fit_cr[0]*left_y_axis*ym_per_pix+left_fit_cr[1])**2)**1.5)/np.absolute(2*left_fit_cr[0])
right_curverad = ((1+(2*right_fit_cr[0]*right_y_axis*ym_per_pix *right_fit_cr[1])**2)**1.5)/np.absolute((2*right_fit_cr[0]))
# 将曲率半径渲染在图像上
cv2.putText(img,'Radius of Curvature = {}(m)'.format(np.mean(left_curverad)),(20,50),cv2.FONT_ITALIC,1,(255,255,255),5)
return img
# 计算车道线中心
def cal_line_center(img):
undistort_img = img_undistort(img,mtx,dist)
rigin_pipeline_img = pipeline(undistort_img)
trasform_img = img_perspect_transform(rigin_pipeline_img,M)
left_fit,right_fit = cal_line_param(trasform_img)
y_max = img.shape[0]
left_x = left_fit[0]*y_max**2+left_fit[1]*y_max+left_fit[2]
right_x = right_fit[0]*y_max**2+right_fit[1]*y_max+right_fit[2]
return (left_x+right_x)/2
def cal_center_departure(img,left_fit,right_fit):
# 计算中心点
y_max = img.shape[0]
left_x = left_fit[0]*y_max**2 + left_fit[1]*y_max +left_fit[2]
right_x = right_fit[0]*y_max**2 +right_fit[1]*y_max +right_fit[2]
xm_per_pix = 3.7/700
center_depart = ((left_x+right_x)/2-lane_center)*xm_per_pix
# 渲染
if center_depart>0:
cv2.putText(img,'Vehicle is {}m right of center'.format(center_depart), (20, 100), cv2.FONT_ITALIC, 1,
(255, 255, 255), 5)
elif center_depart<0:
cv2.putText(img, 'Vehicle is {}m left of center'.format(-center_depart), (20, 100), cv2.FONT_ITALIC, 1,
(255, 255, 255), 5)
else:
cv2.putText(img, 'Vehicle is in the center', (20, 100), cv2.FONT_ITALIC, 1, (255, 255, 255), 5)
return img
if __name__ == "__main__":
ret, mtx, dist, rvecs, tvecs = cal_calibrate_params(file_paths)
# if np.all(mtx != None):
# img = cv2.imread("./test/test1.jpg")
# undistort_img = img_undistort(img, mtx, dist)
# plot_contrast_image(img, undistort_img)
# print("done")
# else:
# print("failed")
# 测试车道线提取
# img = cv2.imread('./test/frame45.jpg')
# result = pipeline(img)
# plot_contrast_image(img, result, converted_img_gray=True)
# 测试透视变换
img = cv2.imread('./test/straight_lines2.jpg')
points = [[601, 448], [683, 448], [230, 717], [1097, 717]]
img = cv2.line(img, (601, 448), (683, 448), (0, 0, 255), 3)
img = cv2.line(img, (683, 448), (1097, 717), (0, 0, 255), 3)
img = cv2.line(img, (1097, 717), (230, 717), (0, 0, 255), 3)
img = cv2.line(img, (230, 717), (601, 448), (0, 0, 255), 3)
# plt.figure()
# plt.imshow(img[:, :, ::-1])
# plt.title("原图")
# plt.show()
M, M_inverse = cal_perspective_params(img, points)
# if np.all(M != None):
# trasform_img = img_perspect_transform(img, M)
# plt.figure()
# plt.imshow(trasform_img[:, :, ::-1])
# plt.title("俯视图")
# plt.show()
# else:
# print("failed")
img = cv2.imread('./test/straight_lines2.jpg')
# undistort_img = img_undistort(img,mtx,dist)
# pipeline_img = pipeline(undistort_img)
# trasform_img = img_perspect_transform(pipeline_img,M)
# left_fit,right_fit = cal_line_param(trasform_img)
# result = fill_lane_poly(trasform_img,left_fit,right_fit)
# plt.figure()
# plt.imshow(result[:,:,::-1])
# plt.title("俯视图:填充结果")
# plt.show()
# trasform_img_inv = img_perspect_transform(result,M_inverse)
# plt.figure()
# plt.imshow(trasform_img_inv[:, :, ::-1])
# plt.title("填充结果")
# plt.show()
# res = cv2.addWeighted(img,1,trasform_img_inv,0.5,0)
# plt.figure()
# plt.imshow(res[:, :, ::-1])
# plt.title("安全区域")
# plt.show()
lane_center = cal_line_center(img)
print("中心点位置:{}".format(lane_center))
def process_image(img):
# 图像去畸变
undistort_img = img_undistort(img,mtx,dist)
# 车道线检测
rigin_pipline_img = pipeline(undistort_img)
# 透视变换
transform_img = img_perspect_transform(rigin_pipline_img,M)
# 拟合车道线
left_fit,right_fit = cal_line_param(transform_img)
# 绘制安全区域
result = fill_lane_poly(transform_img,left_fit,right_fit)
transform_img_inv = img_perspect_transform(result,M_inverse)
# 曲率和偏离距离
transform_img_inv = cal_radius(transform_img_inv,left_fit,right_fit)
transform_img_inv = cal_center_departure(transform_img_inv,left_fit,right_fit)
transform_img_inv = cv2.addWeighted(undistort_img,1,transform_img_inv,0.5,0)
return transform_img_inv
# 视频处理
clip1 = VideoFileClip("project_video.mp4")
white_clip = clip1.fl_image(process_image)
# white_clip.ipython_display()
white_clip.write_videofile("output.mp4",audio=False)
import cv2
import numpy as np
import matplotlib.pyplot as plt
import glob
from moviepy.editor import VideoFileClip
"""
车道线检测流程
1.棋盘格数据对车载相机进行校正
2.图像去畸变
3.车道线提取
4.透视变换
5.车道线精确定位
6.反投影
7.车道曲率
8.车道偏离距离
"""
"""
1.相机标定:
根据张正友校正算法,利用棋盘格数据校正对车载相机进行校正,计算其内参矩阵,外参矩阵和畸变系数。
相机内参:
图像坐标系变 换到 像素坐标系的参数矩阵 + 相机坐标系 变换到 图像坐标系的转换的参数矩阵。
确定相机从三维空间到二维图像的投影关系,畸变系数也属于内参。
相机外参:
世界坐标系 变换到 相机坐标系的参数矩阵。
决定相机坐标与世界坐标系之间相对位置关系,主要包括旋转和平移两部分。
2.标定的流程是:
准备棋盘格数据,即用于标定的图片
对每一张图片提取角点信息
在棋盘上绘制提取到的角点(非必须,只是为了显示结果)
利用提取的角点对相机进行标定
获取相机的参数信息
3.标定的图片
标定的图片需要使用棋盘格数据在不同位置、不同角度、不同姿态下拍摄的图片,最少需要3张,当然多多益善,通常是10-20张。
该项目中我们使用了20张图片。把这些图片存放在项目路径中的camera_cal文件夹中。
4.相机校正
下面我们对相机进行校正,OPenCV中提供了对相机进行校正的代码,在本项目中直接使用opencv中的API进行相机的校正。
"""
#参数设定:定义棋盘横向和纵向的角点个数并指定校正图像的位置
nx = 9 #棋盘 横向的角点个数
ny = 6 #棋盘 纵向的角点个数
#读取所有的棋盘格图片数据
file_paths = glob.glob("./camera_cal/calibration*.jpg")
# 绘制对比图
def plot_contrast_image(origin_img, converted_img, origin_img_title="origin_img", converted_img_title="converted_img", converted_img_gray=False):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 20))
ax1.set_title = origin_img_title
ax1.imshow(origin_img)
ax2.set_title = converted_img_title
if converted_img_gray == True:
ax2.imshow(converted_img, cmap="gray")
else:
ax2.imshow(converted_img)
plt.show()
"""
相机内参:
图像坐标系变 换到 像素坐标系的参数矩阵 + 相机坐标系 变换到 图像坐标系的转换的参数矩阵。
确定相机从三维空间到二维图像的投影关系,畸变系数也属于内参。
相机外参:
世界坐标系 变换到 相机坐标系的参数矩阵。
决定相机坐标与世界坐标系之间相对位置关系,主要包括旋转和平移两部分。
1.寻找棋盘图中的棋盘角点
rect, corners = cv2.findChessboardCorners(image, pattern_size, flags)
参数:
Image: 输入的棋盘图,必须是8位的灰度或者彩色图像
Pattern_size: 棋盘图中每行每列的角点个数(内角点)。
flags: 用来定义额外的滤波步骤以有助于寻找棋盘角点。所有的变量都可以单独或者以逻辑或的方式组合使用。
取值主要有:
CV_CALIB_CB_ADAPTIVE_THRESH :使用自适应阈值(通过平均图像亮度计算得到)将图像转换为黑白图,而不是一个固定的阈值。
CV_CALIB_CB_NORMALIZE_IMAGE :在利用固定阈值或者自适应的阈值进行二值化之前,先使用cvNormalizeHist来均衡化图像亮度。
CV_CALIB_CB_FILTER_QUADS :使用其他的准则(如轮廓面积,周长,方形形状)来去除在轮廓检测阶段检测到的错误方块。
返回:
Corners: 检测到的二维图像中的角点
rect: 输出是否找到角点,找到角点返回1,否则返回0
2.检测完角点之后我们可以将将测到的角点绘制在图像上,使用的API是:
cv2.drawChessboardCorners(img, pattern_size, corners, rect)
参数:
Img: 预绘制检测角点的图像
pattern_size: 预绘制的角点的形状
corners: 角点矩阵
rect:表示是否所有的棋盘角点被找到,可以设置为findChessboardCorners的返回值
注意:如果发现了所有的角点,那么角点将用不同颜色绘制(每行使用单独的颜色绘制),并且把角点以一定顺序用线连接起来
3.利用定标的结果计算内外参数
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(object_points, image_points, image_size, None, None)
参数:
Object_points: 角点在三维空间的位置(角点在真实世界中的位置)
世界坐标系中的点,在使用棋盘的场合,我们令z的坐标值为0,而x,y坐标用里面来度量,选用英寸单位,
那么所有参数计算的结果也是用英寸表示。最简单的方式是我们定义棋盘的每一个方块为一个单位。
image_points:角点在二维图像空间中的位置。在图像中寻找到的角点的坐标,包含object_points所提供的所有点
image_size: 图像的大小,以像素为衡量单位
返回:
ret: 返回值
mtx: 相机的内参矩阵,大小为3*3的矩阵
dist: 畸变系数,为5*1大小的矢量
rvecs: 旋转变量
tvecs: 平移变量
"""
# 相机校正:计算相机的 外参、内参、畸变系数
def cal_calibrate_params(file_paths):
# 存储角点数据的坐标
object_points = [] # 角点在三维空间的位置(角点在真实世界中的位置)
image_points = [] # 角点在二维图像空间中的位置
# 生成角点在真实世界中的位置(生成角点在三维空间的位置):np.zeros((9 * 6, 3)) 即(54, 3)
#(棋盘横向的角点个数,棋盘纵向的角点个数):棋盘图中每行每列的角点个数(内角点)
objp = np.zeros((nx * ny, 3), np.float32) #生成角点在真实世界中的位置:(54, 3)
objp[:, :2] = np.mgrid[0:nx, 0:ny].T.reshape(-1, 2)
"""
mgrid处理后的 objp:
array([[0., 0., 0.], [1., 0., 0.], [2., 0., 0.], [3., 0., 0.], [4., 0., 0.], [5., 0., 0.], [6., 0., 0.], [7., 0., 0.], [8., 0., 0.],
[0., 1., 0.], [1., 1., 0.], [2., 1., 0.], [3., 1., 0.], 。。。。。。
。。。。。。
], dtype=float32)
"""
# 角点检测
# 遍历每个棋盘图片数据
for file_path in file_paths:
# 读取棋盘图片
img = cv2.imread(file_path)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 角点检测
"""
寻找棋盘图中的棋盘角点
rect, coners = cv2.findChessboardCorners(gray, (nx, ny), None)
参数:
gray: 输入的棋盘图,必须是8位的灰度或者彩色图像
(nx,ny): (9,6) 即 (棋盘横向的角点个数,棋盘纵向的角点个数),棋盘图中每行每列的角点个数(内角点)
flags:
用来定义额外的滤波步骤以有助于寻找棋盘角点。所有的变量都可以单独或者以逻辑或的方式组合使用。
取值主要有:
CV_CALIB_CB_ADAPTIVE_THRESH :使用自适应阈值(通过平均图像亮度计算得到)将图像转换为黑白图,而不是一个固定的阈值。
CV_CALIB_CB_NORMALIZE_IMAGE :在利用固定阈值或者自适应的阈值进行二值化之前,先使用cvNormalizeHist来均衡化图像亮度。
CV_CALIB_CB_FILTER_QUADS :使用其他的准则(如轮廓面积,周长,方形形状)来去除在轮廓检测阶段检测到的错误方块。
返回:
rect: 输出是否找到角点,找到角点返回1,否则返回0
coners: 检测到的二维图像中的角点
"""
rect, coners = cv2.findChessboardCorners(gray, (nx, ny), None)
# imgcopy = img.copy()
# cv2.drawChessboardCorners(imgcopy,(nx,ny),coners,rect)
# plot_contrast_image(img,imgcopy)
if rect == True:
# 角点在三维空间的位置(角点在真实世界中的位置)
object_points.append(objp)
# 角点在二维图像空间中的位置
image_points.append(coners)
"""
利用定标的结果计算内外参数
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(object_points, image_points, image_size, None, None)
参数:
object_points: 角点在三维空间的位置(角点在真实世界中的位置)
世界坐标系中的点,在使用棋盘的场合,我们令z的坐标值为0,而x,y坐标用里面来度量,选用英寸单位,
那么所有参数计算的结果也是用英寸表示。最简单的方式是我们定义棋盘的每一个方块为一个单位。
image_points:角点在二维图像空间中的位置。在图像中寻找到的角点的坐标,包含object_points所提供的所有点
image_size: 棋盘图片的shape[::-1]作为传入的image_size。图像的大小,以像素为衡量单位
返回:
ret: 返回值
mtx: 相机的内参矩阵,大小为3*3的矩阵
dist: 畸变系数,为5*1大小的矢量
rvecs: 旋转变量
tvecs: 平移变量
"""
# 相机校正
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(object_points, image_points, gray.shape[::-1], None, None)
return ret, mtx, dist, rvecs, tvecs
"""
1.图像去畸变
上一步中我们已经得到相机的内参及畸变系数,我们利用其进行图像的去畸变,最直接的方法就是调用opencv中的函数得到去畸变的图像.
2.图像去畸变的API:
dst = cv2.undistort(img, mtx, dist, None, mtx)
参数:
Img: 要进行校正的图像
mtx: 相机的内参
dist: 相机的畸变系数
返回:
dst: 图像校正后的结果
"""
# 图像去畸变:利用相机校正的内参,畸变系数
def img_undistort(img, mtx, dist):
"""
图像去畸变的API:cv2.undistort(img, mtx, dist, None, mtx)
:param img: 要进行校正的图像
:param mtx: 相机的内参
:param dist: 相机的畸变系数
:return: 图像校正后的结果
"""
dis = cv2.undistort(img, mtx, dist, None, mtx)
return dis
"""
车道线提取
1.我们基于图像的梯度和颜色特征,定位车道线的位置。
在这里选用Sobel边缘提取算法,Sobel相比于Canny的优秀之处在于,它可以选择横向或纵向的边缘进行提取。
从车道的拍摄图像可以看出,我们关心的正是车道线在横向上的边缘突变。
2.OpenCV提供的cv2.Sobel()函数,将进行边缘提取后的图像做二进制图的转化,即提取到边缘的像素点显示为白色(值为1),
未提取到边缘的像素点显示为黑色(值为0)。由于只使用边缘检测,在有树木阴影覆盖的区域时,虽然能提取出车道线的大致轮廓,
但会同时引入的噪声,给后续处理带来麻烦。所以在这里我们引入颜色阈值来解决这个问题。
3.颜色空间
1.在车道线检测中,我们使用的是HSL颜色空间,其中H表示色相,即颜色,S表示饱和度,即颜色的纯度,L表示颜色的明亮程度。
2.HSL的H(hue)分量,代表的是人眼所能感知的颜色范围,这些颜色分布在一个平面的色相环上,取值范围是0°到360°的圆心角,
每个角度可以代表一种颜色。色相值的意义在于,我们可以在不改变光感的情况下,通过旋转色相环来改变颜色。在实际应用中,
我们需要记住色相环上的六大主色,用作基本参照:360°/0°红、60°黄、120°绿、180°青、240°蓝、300°洋红,
它们在色相环上按照60°圆心角的间隔排列.
3.HSL的S(saturation)分量,指的是色彩的饱和度,描述了相同色相、明度下色彩纯度的变化。
数值越大,颜色中的灰色越少,颜色越鲜艳,呈现一种从灰度到纯色的变化。因为车道线是黄色或白色,所以利用s通道阈值来检测车道线。
4.HSL的L(lightness)分量,指的是色彩的明度,作用是控制色彩的明暗变化。数值越小,色彩越暗,越接近于黑色;
数值越大,色彩越亮,越接近于白色。
"""
# 车道线提取
# 颜色空间转换 —> 边缘检测 —> 颜色阈值 —> 合并并且使用L通道进行白的区域的抑制
def pipeline(img, s_thresh=(170, 255), sx_thresh=(40, 200)):
"""
:param img: 校正(去畸变)后的图像
:param s_thresh: 颜色通道的阈值
:param sx_thresh: 边缘提取的阈值
:return: 把S通道([:, :, 2])所构建的二值化图和L通道([:, :, 1])所构建的二值化图进行合并作为最终车道线提取的二值图结果。
最终车道线提取的二值图中车道线为白色。
"""
"""
1.首先我们是把图像转换为HLS颜色空间,然后利用边缘检测和阈值的方法检测车道线
2.利用sobel边缘检测的结果
3.利用S通道的阈值检测结果
4.将边缘检测结果与颜色检测结果合并,并利用L通道抑制非白色的信息
"""
# 复制原图像:把校正(去畸变)后的图像 深拷贝 一份
img = np.copy(img)
"""
把校正(去畸变)后的图像转换为HLS色彩空间,然后获取HSL色彩图像的L通道([:, :, 1])和S通道([:, :, 2])
"""
# 颜色空间转换:将图像转换为HLS色彩空间,并分离各个通道
hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS).astype(np.float)
# HSL的L通道:
# 指的是色彩的饱和度,描述了相同色相、明度下色彩纯度的变化。
# 数值越大,颜色中的灰色越少,颜色越鲜艳,呈现一种从灰度到纯色的变化。
# 因为车道线是黄色或白色,所以利用s通道阈值来检测车道线。
l_chanel = hls[:, :, 1]
# HSL的S通道:
# 指的是色彩的明度,作用是控制色彩的明暗变化。数值越小,色彩越暗,越接近于黑色;
# 数值越大,色彩越亮,越接近于白色。
s_chanel = hls[:, :, 2]
"""
使用Sobel边缘提取算法对HSL色彩图像的L通道([:, :, 1])进行边缘提取。
然后根据边缘提取的阈值sx_thresh对边缘提取后的图像(即L通道的边缘检测值)做二进制图(二值化图)的转化(只有0和1的值)。
"""
# sobel对L通道进行边缘检测,利用sobel计算x方向的梯度。L通道边缘检测输出的图像中道路和车道线仍然为一片黑色,只有些许的树叶边缘的白色。
# 在这里选用Sobel边缘提取算法,Sobel相比于Canny的优秀之处在于,它可以选择横向或纵向的边缘进行提取。
# 从车道的拍摄图像可以看出,我们关心的正是车道线在横向上的边缘突变。
sobelx = cv2.Sobel(l_chanel, cv2.CV_64F, 1, 0)
# 对L通道的边缘检测值 进行求绝对值
abs_sobelx = np.absolute(sobelx)
# 将其L通道的边缘检测值 转换为8bit的整数。将导数转换为8bit整数。
scaled_sobel = np.uint8(255 * abs_sobelx / np.max(abs_sobelx))
# 目的为对边缘提取结果(即L通道的边缘检测值)进行二值化:只有0和1的值
sxbinary = np.zeros_like(scaled_sobel)
# 将进行边缘提取后的图像(即L通道的边缘检测值)做二进制图的转化,即提取到边缘的像素点显示为白色(值为1),未提取到边缘的像素点显示为黑色(值为0)。
# 使用 边缘提取的阈值sx_thresh
sxbinary[(scaled_sobel >= sx_thresh[0]) & (scaled_sobel <= sx_thresh[1])] = 1
# plt.figure()
# plt.imshow(sxbinary, cmap='gray')
# plt.title("sobel")
# plt.show()
"""
根据颜色通道的阈值s_thresh 对 HSL色彩图像的S通道([:, :, 2]) 构建二进制图(二值化图)的转化(只有0和1的值)。
"""
# s通道阈值处理。对s通道进行阈值处理。
s_binary = np.zeros_like(s_chanel)
# 由于只使用边缘检测,在有树木阴影覆盖的区域时,虽然能提取出车道线的大致轮廓,
# 但会同时引入的噪声,给后续处理带来麻烦。所以在这里我们引入颜色阈值s_thresh来解决这个问题。
s_binary[(s_chanel >= s_thresh[0]) & (s_chanel <= s_thresh[1])] = 1
# plt.figure()
# plt.imshow(s_binary, cmap='gray')
# plt.title("schanel")
# plt.show()
"""
把S通道([:, :, 2])所构建的二值化图和L通道([:, :, 1])所构建的二值化图进行合并作为最终车道线提取的二值图结果。
二值图中提取的车道线为白色。
"""
# 结合边缘提取结果和颜色的结果。将边缘检测的结果和颜色空间阈值的结果合并,并结合l通道的取值,确定车道提取的二值图结果。
color_binary = np.zeros_like(sxbinary)
color_binary[((sxbinary == 1) | (s_binary == 1)) & (l_chanel > 100)] = 1
return color_binary
# 透视变换
# 获取透视变换的参数矩阵
def cal_perspective_params(img, points):
"""
原图像转换到俯视图的参数矩阵 M:cv2.getPerspectiveTransform(src, dst)
俯视图转换到原图像的参数矩阵 M_inverse:cv2.getPerspectiveTransform(dst, src)
:param img: 原图
:param points: 原图上的车道线所构建的矩形的四个顶点的xy坐标位置
:return: 原图像转换到俯视图的参数矩阵 M、俯视图转换到原图像的参数矩阵 M_inverse
"""
#原图中根据左右两边的车道线使用4条红色线画出的一个红色矩形的四个顶点的坐标位置
# points = [[矩形前面的边的左点的xy坐标], [矩形前面的边的右点的xy坐标], [矩形后面的边的左点的xy坐标], [矩形后面的边的右点的xy坐标]]
src = np.float32(points)
#获取原图的宽和高:(1280, 720) 即(宽, 高)
img_size = (img.shape[1], img.shape[0])
offset_x = 330
offset_y = 0
"""
dst = [[330. 0.] [950. 0.] [330. 720.] [950. 720.]]
dst 即 [[左边竖线车道线在俯视图中顶边的点的xy坐标] [右边竖线车道线在俯视图中顶边的点的xy坐标]
[左边竖线车道线在俯视图中底边的点的xy坐标] [右边竖线车道线在俯视图中底边的点的xy坐标]]
"""
# 设置俯视图中的对应的四个点
dst = np.float32([[offset_x, offset_y], #[330. 0.]
[img_size[0] - offset_x, offset_y],#[950. 0.],宽1280-330=950
[offset_x, img_size[1] - offset_y], #[330. 720.],高720-0=720
[img_size[0] - offset_x, img_size[1] - offset_y]]) #[950. 720.],宽1280-330=950,高720-0=720
"""
1.原图像points中矩形的四个顶点的坐标位置 和 俯视图dst中矩形的四个顶点的坐标位置 是一一对应的。
原图像points中矩形的四个顶点的坐标位置
[[矩形前面的边的左点的xy坐标], [矩形前面的边的右点的xy坐标], [矩形后面的边的左点的xy坐标], [矩形后面的边的右点的xy坐标]]
俯视图dst中矩形的四个顶点的坐标位置
[[左边竖线车道线在俯视图中顶边的点的xy坐标] [右边竖线车道线在俯视图中顶边的点的xy坐标]
[左边竖线车道线在俯视图中底边的点的xy坐标] [右边竖线车道线在俯视图中底边的点的xy坐标]]
2.原图像转换到俯视图的参数矩阵:cv2.getPerspectiveTransform(src, dst)
俯视图转换到原图像的参数矩阵:cv2.getPerspectiveTransform(dst, src)
"""
# 原图像转换到俯视图
M = cv2.getPerspectiveTransform(src, dst)
# 俯视图到原图像
M_inverse = cv2.getPerspectiveTransform(dst, src)
return M, M_inverse
"""
1.根据“原图像转换到俯视图的”参数矩阵 把 原图 转换为 俯视图
2.根据“俯视图转换到原图像的”参数矩阵 把 俯视图 转换为 原图
"""
# 根据参数矩阵完成透视变换
def img_perspect_transform(img, M):
"""
1.根据“原图像转换到俯视图的”参数矩阵 把 原图 转换为 俯视图
2.根据“俯视图转换到原图像的”参数矩阵 把 俯视图 转换为 原图
:param img: 原图 / 俯视图
:param M: “原图像转换到俯视图的”参数矩阵 / “俯视图转换到原图像的”参数矩阵
:return: 俯视图 / 原图
"""
# 获取图像的宽和高
img_size = (img.shape[1], img.shape[0])
return cv2.warpPerspective(img, M, img_size)
"""
车道线定位及拟合
1.根据前面检测出的车道线信息,利用直方图和滑动窗口的方法,精确定位车道线,并进行拟合。
2.定位思想
沿x轴方向统计每一列中白色像素点的个数,横坐标是图像的列数,纵坐标表示每列中白色点的数量,那么这幅图就是“直方图”。
3.对比上述“直方图”,可以发现直方图左半边最大值对应的列数,即为左车道线所在的位置,直方图右半边最大值对应的列数,是右车道线所在的位置。
确定左右车道线的大致位置后,使用”滑动窗口“的方法,在图中对左右车道线的点进行搜索。
4.滑动窗口的搜索过程:
设置搜索窗口大小(width和height):一般情况下width为手工设定,height为图片大小除以设置搜索窗口数目计算得到。
以搜寻起始点作为当前搜索的基点,并以当前基点为中心,做一个网格化搜索。
对每个搜索窗口分别做水平和垂直方向直方图统计,统计在搜索框区域内非零像素个数,并过滤掉非零像素数目小于50的框。
计算非零像素坐标的均值作为当前搜索框的中心,并对这些中心点做一个二阶的多项式拟合,得到当前搜寻对应的车道线曲线参数。
"""
# 精确定位车道线
def cal_line_param(binary_warped):
"""
利用直方图和滑动窗口的方法 对“俯视图中提取出来的”车道线 进行精确定位 车道检测线,并进行拟合出匹配左右车道检测线的线段
:param binary_warped: “校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图
:return: 匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
"""
# 根据“车道线提取后的二值图的”俯视图统计直方图:
# 沿x轴方向统计每一列中白色像素点的个数,横坐标是图像的列数,纵坐标表示每列中白色点的数量,那么这幅图就是“直方图”
histogram = np.sum(binary_warped[:, :], axis=0)
# 在统计直方图中找到左右最大的点的位置,作为左右车道检测的开始点。确定左右车道线的位置。
# 将统计直方图一分为二,划分为左右两个部分,分别定位峰值位置,即为两条车道的搜索位置。
# 可以发现统计直方图左半边最大值对应的列数,即为左车道线所在的位置,统计直方图右半边最大值对应的列数,是右车道线所在的位置。
midpoint = np.int(histogram.shape[0] / 2) #直方图的宽 / 2 = 宽的中间点,可用于分割左右两半的图
leftx_base = np.argmax(histogram[:midpoint]) #左车道线所在列(x轴)上的位置:直方图的中间点的左半边 搜寻y最大值的列的索引值位置
rightx_base = np.argmax(histogram[midpoint:]) + midpoint #右车道线所在列(x轴)上的位置:直方图的中间点的右半边 搜寻y最大值的列的索引值位置
# 2.滑动窗口检测车道线
# 设置滑动窗口的数量,计算每一个窗口的高度
nwindows = 9
#binary_warped.shape[0]:进行车道线提取后的二值图的俯视图的高 720
#binary_warped.shape[1]:进行车道线提取后的二值图的俯视图的宽 1280
window_height = np.int(binary_warped.shape[0] / nwindows) #高720 / 滑动窗口的数量 = 每一个窗口的高度
# 获取“车道线提取后的二值图的”俯视图中不为0的点,包括每个不为0的点的xy坐标
nonzero = binary_warped.nonzero()
# nonzeroy:记录了“车道线提取后的二值图的”俯视图中所有非0点的y坐标组成的数组。
nonzeroy = np.array(nonzero[0]) #获取“车道线提取后的二值图的”俯视图中不为0的每个点的y坐标
# nonzerox:记录了“车道线提取后的二值图的”俯视图中所有非0点的x坐标组成的数组。
nonzerox = np.array(nonzero[1]) #获取“车道线提取后的二值图的”俯视图中不为0的每个点的x坐标
# 左车道/右车道 检测线的位置,也即 左车道/右车道 上滑动窗口的中心点在x轴上的位置
leftx_current = leftx_base #左车道检测线所在列的位置,即 左车道上滑动窗口的中心点 在x轴上的位置
rightx_current = rightx_base #右车道线所在列的位置,即 右车道上滑动窗口的中心点 在x轴上的位置
# 设置滑动窗口在x轴方向上的检测范围:手动指定margin为滑动窗口的宽度的一半,那么整个滑动窗口在x轴方向上的检测范围即margin*2
margin = 100
# 设置滑动窗口中允许存在最少像素点数量的阈值
# 该阈值用于统计滑动窗口区域内的非零像素个数,小于该阈值的滑动窗口区域则不对车道线的中心值进行更新
minpix = 50
# 用来记录左车道线上所有的滑动窗口中的非零点在nonzeroy和nonzerox中的索引
left_lane_inds = []
# 用来记录右车道线上所有的滑动窗口中的非零点在nonzeroy和nonzerox中的索引
right_lane_inds = []
# 遍历该“车道线提取后的二值图的”俯视图中的每一个窗口
for window in range(nwindows):
# 设置每个窗口在y方向的检测范围。注意:y方向从上到下才是从0开始的正数方向
# binary_warped.shape[0]:进行车道线提取后的二值图的俯视图的高720。
# 每个窗口是从y轴的最大值到y轴的0点方向进行叠加滑动,即每个窗口是从“车道线提取后的二值图的”俯视图的底边开始往上叠加滑动窗口的。
win_y_low = binary_warped.shape[0] - (window + 1) * window_height #高720 - (当前窗口数+1) * 窗口的高度 = 当前窗口的顶边在y轴小值方向的y坐标位置
win_y_high = binary_warped.shape[0] - window * window_height #高720 - (当前窗口数) * 窗口的高度 = 当前窗口的底边在y轴大值方向的的y坐标位置
# 左车道线上的滑动窗口在x轴方向上的检测范围 即margin*2
win_xleft_low = leftx_current - margin #左车道检测线所在列的位置 - 100 = 左车道线上的滑动窗口中的左边在x轴上的值
win_xleft_high = leftx_current + margin #左车道检测线所在列的位置 + 100 = 左车道线上的滑动窗口中的右边在x轴上的值
# 右车道线上的滑动窗口在x轴方向上的检测范围 即margin*2
win_xright_low = rightx_current - margin #右车道检测线所在列的位置 - 100 = 右车道线上的滑动窗口中的左边在x轴上的值
win_xright_high = rightx_current + margin #右车道检测线所在列的位置 + 100 = 右车道线上的滑动窗口中的右边在x轴上的值
# 确定非零点的x/y坐标是否在滑动窗口中,将所有滑动窗口内的非零点的x/y坐标的索引分别存入到left_lane_inds/right_lane_inds中
# good_left_inds:位于左车道线上的当前滑动窗口之内的非零点在nonzerox/nonzeroy数组中的索引值。
# nonzerox[good_left_inds] 和 nonzeroy[good_left_inds]:
# 该good_left_inds索引值对应到nonzerox/nonzeroy数组中元素值 指的分别是同一个非零点的x坐标位置和y坐标位置
"""
4个“&”条件判断表达式仅输出一个True或False:
该True或False的索引值 即等于 非零点的x坐标在nonzerox数组中的索引值 和 非零点的y坐标在nonzeroy数组中的索引值
"""
good_left_inds = ((nonzeroy >= win_y_low) #所有非0点的y坐标组成的数组 >= 当前窗口的顶边在y轴小值方向的y坐标位置
& (nonzeroy < win_y_high) #所有非0点的y坐标组成的数组 < 当前窗口的底边在y轴大值方向的的y坐标位置
& (nonzerox >= win_xleft_low) #所有非0点的x坐标组成的数组 >= 左车道线上的滑动窗口中的左边在x轴上的值
& (nonzerox < win_xleft_high) #所有非0点的x坐标组成的数组 < 左车道线上的滑动窗口中的右边在x轴上的值
).nonzero()[0]
# good_right_inds:位于右车道线上的当前滑动窗口之内的非零点在nonzerox/nonzeroy数组中的索引值
# nonzerox[good_right_inds] 和 nonzeroy[good_right_inds]:
# 该good_right_inds索引值对应到nonzerox/nonzeroy数组中元素值 指的分别是同一个非零点的x坐标位置和y坐标位置
"""
4个“&”条件判断表达式仅输出一个True或False:
该True或False的索引值 即等于 非零点的x坐标在nonzerox数组中的索引值 和 非零点的y坐标在nonzeroy数组中的索引值
"""
good_right_inds = ((nonzeroy >= win_y_low) #所有非0点的y坐标组成的数组 >= 当前窗口的顶边在y轴小值方向的y坐标位置
& (nonzeroy < win_y_high)#所有非0点的y坐标组成的数组 < 当前窗口的底边在y轴大值方向的的y坐标位置
& (nonzerox >= win_xright_low) #所有非0点的x坐标组成的数组 >= 右车道线上的滑动窗口中的左边在x轴上的值
& (nonzerox < win_xright_high) #所有非0点的x坐标组成的数组 < 右车道线上的滑动窗口中的右边在x轴上的值
).nonzero()[0]
#left_lane_inds:存储“位于左车道线上所有的滑动窗口之内的非零点在nonzerox/nonzeroy数组中的”索引值
left_lane_inds.append(good_left_inds)
#right_lane_inds:存储“位于右车道线上所有的滑动窗口之内的非零点在nonzerox/nonzeroy数组中的”索引值
right_lane_inds.append(good_right_inds)
# 如果 左车道线上的当前滑动窗口中的非0点的索引值数量 > minpix(滑动窗口中允许存在最少像素点数量的阈值)
if len(good_left_inds) > minpix:
#利用左车道线上的当前滑动窗口中的所有非0点的x坐标的平均值来更新左车道检测线所在的位置,也即更新左车道线上的滑动窗口的中心点在x轴上的位置
leftx_current = np.int(np.mean(nonzerox[good_left_inds]))
# 如果 右车道线上的当前滑动窗口中的非0点的索引值数量 > minpix(滑动窗口中允许存在最少像素点数量的阈值)
if len(good_right_inds) > minpix:
#利用右车道线上的当前滑动窗口中的所有非0点的x坐标的平均值来更新右车道检测线所在的位置,也即更新右车道线上的滑动窗口的中心点在x轴上的位置
rightx_current = np.int(np.mean(nonzerox[good_right_inds]))
# 将“存储了左车道线上所有滑动窗口之内的非零点的索引值的”二维数组 合并为 一维的数组
left_lane_inds = np.concatenate(left_lane_inds)
# 将“存储了右车道线上所有滑动窗口之内的非零点的索引值的”二维数组 合并为 一维的数组
right_lane_inds = np.concatenate(right_lane_inds)
# 获取 左车道线上的所有滑动窗口中的非0点的 x坐标值集合leftx 和 y坐标值集合lefty:
# 根据的是 同一个非0点的 “x坐标值在nonzerox数组中的”索引值left_lane_inds 和 “y坐标值在nonzeroy数组中的”索引值left_lane_inds 是相同的。
leftx = nonzerox[left_lane_inds]
lefty = nonzeroy[left_lane_inds]
# 获取 右车道线上的所有滑动窗口中的非0点的 x坐标值集合leftx 和 y坐标值集合lefty:
# 根据的是 同一个非0点的 “x坐标值在nonzerox数组中的”索引值right_lane_inds 和 “y坐标值在nonzeroy数组中的”索引值right_lane_inds 是相同的。
rightx = nonzerox[right_lane_inds]
righty = nonzeroy[right_lane_inds]
""" np.polyfit(同一个非0点的y坐标, 同一个非0点的x坐标, 2):根据所有滑动窗口中的非0点 拟合出 一条匹配车道检测线位置的线段 """
# 3.用曲线拟合检测出的点,二次多项式拟合,返回的结果是系数
left_fit = np.polyfit(lefty, leftx, 2) #根据 左车道上所有滑动窗口中的非0点 拟合出 一条匹配左车道上的车道检测线位置的线段
right_fit = np.polyfit(righty, rightx, 2) #根据 右车道上所有滑动窗口中的非0点 拟合出 一条匹配右车道上的车道检测线位置的线段
return left_fit, right_fit
"""
在 左车道检测线的拟合线段 和 右车道检测线的拟合线段 的两列线段之间 绘制出“整个面积为绿色填充的四边形的”车道区域,
该四边形填充在左右车道检测线之间。
传入参数:“校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图、匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
返回值:“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的俯视图
"""
# 填充车道线之间的多边形
def fill_lane_poly(img, left_fit, right_fit):
"""
在 左车道检测线的拟合线段 和 右车道检测线的拟合线段 的两列线段之间 绘制出“整个面积为绿色填充的四边形的”车道区域,
该四边形填充在左右车道检测线之间。
:param img: “校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图
:param left_fit: 匹配左车道检测线的拟合线段
:param right_fit: 匹配右车道检测线的拟合线段
:return: “左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的俯视图
"""
# 获取图像的行数:“进行车道线提取后的二值图的”俯视图的高720
y_max = img.shape[0]
# 设置输出图像的大小,并将白色位置设为255
#把输出图像设置为img(二值图的俯视图)大小组成的3通道的图像,因为是二值图所以再乘以255得到0到255的图
#np.dstack:按水平方向(列顺序)堆叠数组构成一个新的数组
out_img = np.dstack((img, img, img)) * 255
# 在拟合曲线中获取左右车道线中每个像素的xy坐标位置
#y:每一行的行值,即俯视图的高的每一行y值
#x:左车道线上的拟合曲线中的每个像素点的x坐标位置,即 left_fit[0] * y ** 2 + left_fit[1] * y + left_fit[2]
left_points = [[left_fit[0] * y ** 2 + left_fit[1] * y + left_fit[2], y] for y in range(y_max)]
# x:右车道线上的拟合曲线中的每个像素点的x坐标位置,即 right_fit[0] * y ** 2 + right_fit[1] * y + right_fit[2]
right_points = [[right_fit[0] * y ** 2 + right_fit[1] * y + right_fit[2], y] for y in range(y_max - 1, -1, -1)]
# 将左右车道的像素点进行合并
#np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组
line_points = np.vstack((left_points, right_points))
# 根据左右车道线的像素位置绘制多边形
cv2.fillPoly(out_img, np.int_([line_points]), (0, 255, 0))
#“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的俯视图
return out_img
"""
1.曲线的曲率就是针对曲线上某个点的切线方向角对弧长的转动率,通过微分来定义,表明曲线偏离直线的程度。
数学上表明曲线在某一点的弯曲程度的数值。曲率越大,表示曲线的弯曲程度越大。曲率的倒数就是曲率半径。
2.圆的曲率
下面有三个球体,网球、篮球、地球,半径越小的越容易看出是圆的,所以随着半径的增加,圆的程度就越来越弱了。
定义球体或者圆的“圆”的程度,就是 曲率。
其中r为球体或者圆的半径,这样半径越小的圆曲率越大,直线可以看作半径为无穷大的圆。
3.曲线的曲率
1.不同的曲线有不同的弯曲程度。
2.怎么来表示某一条曲线的弯曲程度呢?
我们知道三点确定一个圆:
当δ趋近于0时,我们可以得到曲线在x0处的密切圆,也就是曲线在该点的圆近似。
另外我们也可以观察到,在曲线比较平坦的位置,密切圆较大,在曲线比较弯曲的地方,密切圆较小。
因此,我们通过密切圆的曲率来定义曲线的曲率。
曲线的 曲率 也就是 密切圆的 曲率。
所以密切圆也称为曲线的 曲率圆 ,半径r 称为 曲率半径 。
"""
# 计算车道线的曲率半径r(曲率的倒数就是曲率半径r)
def cal_radius(img, left_fit, right_fit):
"""
计算车道线的曲率半径r(曲率的倒数就是曲率半径r)
曲率是表示曲线的弯曲程度,代表了车道线的弯曲程度。
曲率越大,表示曲线的弯曲程度越大。
曲率的倒数就是曲率半径r。
:param img: “左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的原图像
:param left_fit: 匹配左车道检测线的拟合线段
:param right_fit: 匹配右车道检测线的拟合线段
:return: 返回“带有左车道线/右车道线上拟合的现实曲线的曲率半径r的”二值图的原图像
"""
# 图像中像素个数与实际中距离的比率
# 沿车行进的方向长度大概覆盖了30米,按照美国高速公路的标准,宽度为3.7米(经验值)
ym_per_pix = 30 / 720 # y方向像素个数与距离的比例:前进30米 / 720像素个数
xm_per_pix = 3.7 / 700 # x方向像素个数与距离的比例:一条车道的宽3.7米 / 700像素个数
# 原图像的宽和高:(1280, 720) 即(宽, 高)。shape[0]为高720。
left_y_axis = np.linspace(0, img.shape[0], img.shape[0]-1) #left_y_axis.shape:(719,)
right_y_axis = np.linspace(0, img.shape[0], img.shape[0]-1)#right_y_axis.shape:(719,)
# 获取 左车道线上的拟合曲线中每个像素点 的x坐标位置
left_x_axis = left_fit[0] * left_y_axis **2 + left_fit[1] * left_y_axis + left_fit[2]
# 获取 右车道线上的拟合曲线中每个像素点 的x坐标位置
right_x_axis = right_fit[0] * right_y_axis**2 + right_fit[1] * right_y_axis + right_fit[2]
# 获取真实环境中的曲线:把图像中的拟合曲线上的每个点 通过二次多项式拟合 映射到真实世界中 相应的拟合曲线
# np.polyfit(左车道线的拟合曲线上每个像素的y坐标 * (30 / 720)), (左车道线的拟合曲线上每个像素的x坐标 * (3.7 / 700)), 2)
# 在真实环境中 绘制出一条“能关联映射到图像中左车道上的拟合曲线的”相应的现实环境中左车道的拟合曲线
left_fit_cr = np.polyfit(left_y_axis*ym_per_pix, left_x_axis*xm_per_pix, 2)
# np.polyfit(右车道线的拟合曲线上每个像素的y坐标 * (30 / 720)), (右车道线的拟合曲线上每个像素的x坐标 * (3.7 / 700)), 2)
# 在真实环境中 绘制出一条“能关联映射到图像中右车道上的拟合曲线的”相应的现实环境中右车道的拟合曲线
right_fit_cr = np.polyfit(right_y_axis*ym_per_pix, right_x_axis*xm_per_pix, 2)
# 获取“所映射到真实环境中相应拟合曲线的”曲率半径r,即对“所映射到真实环境中相应的”拟合曲线 来进行计算 曲率半径r。
# 曲率越大,表示曲线的弯曲程度越大。曲率的倒数就是曲率半径。
# left_curverad:求出真实环境中左车道线相应的拟合曲线的曲率半径r
left_curverad = ((1+(2*left_fit_cr[0]*left_y_axis*ym_per_pix + left_fit_cr[1])**2)**1.5) / np.absolute(2*left_fit_cr[0])
# right_curverad:求出真实环境中右车道线相应的拟合曲线的曲率半径r
right_curverad = ((1+(2*right_fit_cr[0]*right_y_axis*ym_per_pix + right_fit_cr[1])**2)**1.5) / np.absolute((2*right_fit_cr[0]))
# 在二值图的原图像上显示曲率半径r:将曲率半径r渲染在二值图的原图像上
# 只使用 left_curverad/right_curverad 其中一个均即可,返回带有 左车道线/右车道线上 拟合的现实曲线的曲率半径r 即可。
cv2.putText(img,'Radius of Curvature = {}(m)'.format(np.mean(left_curverad)), (20,50), cv2.FONT_ITALIC, 1, (255,255,255), 5)
return img
#计算图像中左车道和右车道之间的中心点位置:即车的中心线/左右车道线的中心线在图像中的像素坐标位置
def cal_line_center(img):
"""
1.获取车的中心线的两个方案:
1.第一个方案:
假如车载摄像头在出厂时就预先安置于车身上的固定位置,那么车出厂时工程师就可以根据摄像头位于车身上的位置上所拍摄的画面中就能得知,
车的中心线位于画面中的哪个固定位置,那么工程师就可以预先设定车的中心线位于画面中的像素坐标位置。
2.第二个方案:
假如车载摄像头是额外装配的,并且可以把车载摄像头挂载于车内的任何拍摄位置的话,
那么假如摄像头所搭配的屏幕上显示有“用于给用户可以手动标定车的中心线位于屏幕画面中的哪个位置的”颜色线,
那么在可以把摄像头安置于车内的任何位置的情况下,只需要事先在屏幕上手动设定把画面中的颜色线移动到
“车的中心线出现在画面中的”位置,即可达到手动设定车的中心线位于画面中的像素坐标位置。
2.下面的函数实现中,假设输入图片中的车的中心线即位于左右车道线的中心位置,即左右车道线的中心线和车的中心线重合,
那么便可以通过获取左右车道线的中心线(车的中心线)在图像中的像素坐标位置。
:param img: 车的中心线/左右车道线的中心线重合的图像
:return: 左右车道线的中心线(车的中心线)在图像中的像素坐标位置
"""
# 图像去畸变:利用相机校正的内参,畸变系数,返回校正(去畸变)后的图像
undistort_img = img_undistort(img,mtx,dist)
#车道线提取:校正(去畸变)后的图像进行车道线提取后的二值图结果,最终车道线提取的二值图中车道线为白色。
rigin_pipeline_img = pipeline(undistort_img)
#透视变换:根据 原图像转换到俯视图的参数矩阵M 把“校正(去畸变)后的图像进行车道线提取后的”二值图 转换到 俯视图
trasform_img = img_perspect_transform(rigin_pipeline_img, M)
#利用直方图和滑动窗口的方法 对“俯视图中提取出来的”车道线 进行精确定位 车道检测线,并进行拟合出匹配左右车道检测线的线段
left_fit, right_fit = cal_line_param(trasform_img)
#获取原图的高shape[0]:高720
y_max = img.shape[0]
# left_x:左车道线上的拟合曲线中的每个像素点的x坐标位置
left_x = left_fit[0]*y_max**2 + left_fit[1]*y_max + left_fit[2]
# print("left_x",left_x) #324.370274632789
# right_x:右车道线上的拟合曲线中的每个像素点的x坐标位置
right_x = right_fit[0]*y_max**2 + right_fit[1]*y_max + right_fit[2]
# print("right_x",right_x) #950.473764339667
#中心点位置:637.422019486228
return (left_x + right_x) / 2
def cal_center_departure(img, left_fit, right_fit):
"""
计算视频中每一帧中的“左车道检测线和右车道检测线之间的”中心线 和 车的中心线 之间的 偏移距离,即能知道车的中心线偏离车道中心的距离。
:param img: “带有左车道线/右车道线上拟合的现实曲线的曲率半径r的”二值图的原图像
:param left_fit: 匹配左车道检测线的拟合线段
:param right_fit: 匹配右车道检测线的拟合线段
:return:“带有 左车道线/右车道线上拟合的现实曲线的曲率半径r 和 偏移车道中心距离信息 的”二值图的原图像
"""
#获取原图的高shape[0]:高720
y_max = img.shape[0]
# left_x:左车道线上的拟合曲线中的每个像素点的x坐标位置
left_x = left_fit[0]*y_max**2 + left_fit[1]*y_max + left_fit[2]
# right_x:右车道线上的拟合曲线中的每个像素点的x坐标位置
right_x = right_fit[0]*y_max**2 + right_fit[1]*y_max + right_fit[2]
# x方向像素个数与距离的比例:一条车道的宽3.7米 / 700像素个数
xm_per_pix = 3.7 / 700
"""
(left_x+right_x)/2:当前帧中左车道线和右车道线之间的中心点的像素坐标位置
lane_center:车的中心线在图像中的像素坐标位置
center_depart:在现实环境中,车的中心线偏移车道中心的大概距离
"""
#根据 “当前帧中左右车道之间的中心线的”像素坐标 偏离 车的中心线的像素坐标位置 的距离 转换为 在现实环境中的大概距离
center_depart = ((left_x+right_x)/2 - lane_center) * xm_per_pix
# 在二值图的原图像上渲染显示 现实环境中车的中心线 与 车道中心之间偏移的大概距离
if center_depart>0:
cv2.putText(img,'Vehicle is {}m right of center'.format(center_depart), (20, 100), cv2.FONT_ITALIC, 1, (255, 255, 255), 5)
elif center_depart<0:
cv2.putText(img, 'Vehicle is {}m left of center'.format(-center_depart), (20, 100), cv2.FONT_ITALIC, 1, (255, 255, 255), 5)
else:
cv2.putText(img, 'Vehicle is in the center', (20, 100), cv2.FONT_ITALIC, 1, (255, 255, 255), 5)
return img
"""
车道线检测流程
1.棋盘格数据对车载相机进行校正
2.图像去畸变
3.车道线提取
4.透视变换
5.车道线精确定位
6.反投影
7.车道曲率
8.车道偏离距离
相机内参:
图像坐标系变 换到 像素坐标系的参数矩阵 + 相机坐标系 变换到 图像坐标系的转换的参数矩阵。
确定相机从三维空间到二维图像的投影关系,畸变系数也属于内参。
相机外参:
世界坐标系 变换到 相机坐标系的参数矩阵。
决定相机坐标与世界坐标系之间相对位置关系,主要包括旋转和平移两部分。
"""
if __name__ == "__main__":
"""
1.相机校正:计算相机的 外参、内参、畸变系数
2.传入:所读取全部的棋盘格图片数据。
3.返回:
ret: 返回值
mtx: 相机的内参矩阵,大小为3*3的矩阵
dist: 畸变系数,为5*1大小的矢量
rvecs: 旋转变量
tvecs: 平移变量
"""
ret, mtx, dist, rvecs, tvecs = cal_calibrate_params(file_paths)
# if np.all(mtx != None):
# img = cv2.imread("./test/test1.jpg")
# undistort_img = img_undistort(img, mtx, dist)
# plot_contrast_image(img, undistort_img)
# print("done")
# else:
# print("failed")
# 测试车道线提取
# img = cv2.imread('./test/frame45.jpg')
# result = pipeline(img)
# plot_contrast_image(img, result, converted_img_gray=True)
# 测试透视变换
img = cv2.imread('./test/straight_lines2.jpg')
"""
下面的4行cv2.line中每行的cv2.line用于在原图中根据线段AB两点的坐标画出一段红色的线段AB。
线段AB两点的坐标:cv2.line(原图, (线段A点的x坐标,线段A点的y坐标), (线段B点的x坐标,线段B点的y坐标), ...)。
下面的4行cv2.line的目的为用于在原图中根据左右两边的车道线使用4条红色线画出一个红色的矩形。
"""
#原图中根据左右两边的车道线使用4条红色线画出的一个红色矩形的四个顶点的坐标位置
#points = [[矩形前面的边的左点的xy坐标], [矩形前面的边的右点的xy坐标], [矩形后面的边的左点的xy坐标], [矩形后面的边的右点的xy坐标]]
points = [[601, 448], [683, 448], [230, 717], [1097, 717]]
img = cv2.line(img, (601, 448), (683, 448), (0, 0, 255), 3)
img = cv2.line(img, (683, 448), (1097, 717), (0, 0, 255), 3)
img = cv2.line(img, (1097, 717), (230, 717), (0, 0, 255), 3)
img = cv2.line(img, (230, 717), (601, 448), (0, 0, 255), 3)
# plt.figure()
# plt.imshow(img[:, :, ::-1])
# plt.title("原图")
# plt.show()
"""
为了方便后续的直方图滑窗对车道线进行准确的定位,我们在这里利用透视变换将图像转换成俯视图,
也可将俯视图恢复成原有的图像。
计算透视变换所需的参数矩阵:原图像转换到俯视图的参数矩阵、俯视图转换到原图像的参数矩阵。
传入参数:原图、原图上的车道线所构建的矩形的四个顶点的xy坐标位置
返回值:
原图像转换到俯视图的参数矩阵 M:cv2.getPerspectiveTransform(src, dst)
俯视图转换到原图像的参数矩阵 M_inverse:cv2.getPerspectiveTransform(dst, src)
"""
M, M_inverse = cal_perspective_params(img, points)
# if np.all(M != None):
# trasform_img = img_perspect_transform(img, M)
# plt.figure()
# plt.imshow(trasform_img[:, :, ::-1])
# plt.title("俯视图")
# plt.show()
# else:
# print("failed")
img = cv2.imread('./test/straight_lines2.jpg')
# undistort_img = img_undistort(img,mtx,dist)
# pipeline_img = pipeline(undistort_img)
# trasform_img = img_perspect_transform(pipeline_img,M)
# left_fit,right_fit = cal_line_param(trasform_img)
# result = fill_lane_poly(trasform_img,left_fit,right_fit)
# plt.figure()
# plt.imshow(result[:,:,::-1])
# plt.title("俯视图:填充结果")
# plt.show()
# trasform_img_inv = img_perspect_transform(result,M_inverse)
# plt.figure()
# plt.imshow(trasform_img_inv[:, :, ::-1])
# plt.title("填充结果")
# plt.show()
# res = cv2.addWeighted(img,1,trasform_img_inv,0.5,0)
# plt.figure()
# plt.imshow(res[:, :, ::-1])
# plt.title("安全区域")
# plt.show()
"""
1.获取车的中心线的两个方案:
1.第一个方案:
假如车载摄像头在出厂时就预先安置于车身上的固定位置,那么车出厂时工程师就可以根据摄像头位于车身上的位置上所拍摄的画面中就能得知,
车的中心线位于画面中的哪个固定位置,那么工程师就可以预先设定车的中心线位于画面中的像素坐标位置。
2.第二个方案:
假如车载摄像头是额外装配的,并且可以把车载摄像头挂载于车内的任何拍摄位置的话,
那么假如摄像头所搭配的屏幕上显示有“用于给用户可以手动标定车的中心线位于屏幕画面中的哪个位置的”颜色线,
那么在可以把摄像头安置于车内的任何位置的情况下,只需要事先在屏幕上手动设定把画面中的颜色线移动到
“车的中心线出现在画面中的”位置,即可达到手动设定车的中心线位于画面中的像素坐标位置。
2.下面的函数实现中,假设输入图片中的车的中心线即位于左右车道线的中心位置,即左右车道线的中心线和车的中心线重合,
那么便可以通过获取左右车道线的中心线(车的中心线)在图像中的像素坐标位置。
传入参数:车的中心线/左右车道线的中心线重合的图像
返回值:左右车道线的中心线(车的中心线)在图像中的像素坐标位置
"""
#计算图像中左车道和右车道之间的中心点位置:即车的中心线/左右车道线的中心线在图像中的像素坐标位置
lane_center = cal_line_center(img)
#标准中心点位置:637.422019486228
print("中心点位置:{}".format(lane_center))
#process_image函数:处理视频中每帧
def process_image(img):
"""
1.图像去畸变
上一步中我们已经得到相机的内参及畸变系数,我们利用其进行图像的去畸变,最直接的方法就是调用opencv中的函数得到去畸变的图像.
2.图像去畸变的API:
dst = cv2.undistort(img, mtx, dist, None, mtx)
参数:
Img: 要进行校正的视频中每帧
mtx: 相机的内参矩阵,大小为3*3的矩阵
相机内参:
图像坐标系变 换到 像素坐标系的参数矩阵 + 相机坐标系 变换到 图像坐标系的转换的参数矩阵。
确定相机从三维空间到二维图像的投影关系,畸变系数也属于内参。
dist: 相机的畸变系数,为5*1大小的矢量
返回:
dst: 图像校正后的结果
"""
# 图像去畸变,返回校正(去畸变)后的图像
undistort_img = img_undistort(img, mtx, dist)
# plt.imshow(undistort_img)
# plt.show()
"""
对校正(去畸变)后的图像进行车道线提取。校正(去畸变)后的图像先转换为HSL色彩的图像,
把HSL色彩的图像中的S通道([:, :, 2])所构建的二值化图 和 L通道([:, :, 1])所构建的二值化图进行合并作为最终车道线提取的二值图结果。
最终车道线提取的二值图中车道线为白色。
传入参数:
undistort_img:校正(去畸变)后的图像
默认形参:s_thresh: 颜色通道的阈值
sx_thresh: 边缘提取的阈值
返回值:校正(去畸变)后的图像进行车道线提取后的二值图结果,最终车道线提取的二值图中车道线为白色。
"""
# 车道线检测
rigin_pipline_img = pipeline(undistort_img)
# plt.imshow(rigin_pipline_img)
# plt.show()
"""
透视变换:根据 原图像转换到俯视图的参数矩阵M 把“校正(去畸变)后的图像进行车道线提取后的”二值图 转换到 俯视图
传入参数:“校正(去畸变)后的图像进行车道线提取后的”二值图、“原图像转换到俯视图的”参数矩阵M
返回值:“校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图
"""
# 透视变换
transform_img = img_perspect_transform(rigin_pipline_img, M)
# plt.imshow(transform_img)
# plt.show()
"""
利用直方图和滑动窗口的方法 对“俯视图中提取出来的”车道线 进行精确定位 车道检测线,并进行拟合出匹配左右车道检测线的线段
传入参数:“校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图
返回值:匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
"""
# 拟合车道线
left_fit, right_fit = cal_line_param(transform_img)
"""
在 左车道检测线的拟合线段 和 右车道检测线的拟合线段 的两列线段之间 绘制出“整个面积为绿色填充的四边形的”车道区域,
该四边形填充在左右车道检测线之间。
传入参数:“校正(去畸变)后的图像进行车道线提取后的二值图”的俯视图、匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
返回值:“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的俯视图
"""
# 绘制安全区域
result = fill_lane_poly(transform_img, left_fit, right_fit)
# plt.imshow(result[:,:,::-1])
# plt.show()
"""
透视变换:调用透视变换的方法把二值图的俯视图 转换为 原图像,即根据“俯视图转换到原图像的”参数矩阵 把 二值图的俯视图 转换为 原图像。
传入参数:“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的俯视图、俯视图转换到原图像的参数矩阵
返回值:“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的原图像
"""
transform_img_inv = img_perspect_transform(result, M_inverse)
# plt.imshow(transform_img_inv[:,:,::-1])
# plt.show()
"""
左车道线/右车道线上 拟合的现实曲线的曲率半径r(曲率的倒数就是曲率半径r)
曲率是表示曲线的弯曲程度,代表了车道线的弯曲程度。
曲率越大,表示曲线的弯曲程度越大。
曲率的倒数就是曲率半径r。
传入参数:“左右车道检测线之间绘制有整个面积为绿色填充的四边形的”二值图的原图像、匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
返回值:返回“带有左车道线/右车道线上拟合的现实曲线的曲率半径r的”二值图的原图像
"""
# 曲率和偏离距离
transform_img_inv = cal_radius(transform_img_inv, left_fit, right_fit)
# plt.imshow(transform_img_inv[:,:,::-1])
# plt.show()
"""
计算视频中每一帧中的“左车道检测线和右车道检测线之间的”中心线 和 车的中心线 之间的 偏移距离,即能知道车的中心线偏离车道中心的距离。
传入参数:“带有左车道线/右车道线上拟合的现实曲线的曲率半径r的”二值图的原图像、匹配左车道检测线的拟合线段、匹配右车道检测线的拟合线段
返回值:“带有 左车道线/右车道线上拟合的现实曲线的曲率半径r 和 偏移车道中心距离信息 的”二值图的原图像
"""
transform_img_inv = cal_center_departure(transform_img_inv, left_fit, right_fit)
# plt.imshow(transform_img_inv[:,:,::-1])
# plt.show()
#反投影:把 “带有 左车道线/右车道线上拟合的现实曲线的曲率半径r 和 偏移车道中心距离信息 的”二值图 叠加到 校正(去畸变)后的图像
transform_img_inv = cv2.addWeighted(undistort_img, 1, transform_img_inv, 0.5, 0)
#“带有 左车道线/右车道线上拟合的现实曲线的曲率半径r 和 偏移车道中心距离信息 的”校正(去畸变)后的图像
return transform_img_inv
# 视频处理
clip1 = VideoFileClip("project_video.mp4")
#视频中每帧处理调用process_image函数
white_clip = clip1.fl_image(process_image)
# white_clip.ipython_display()
#处理后的视频保存
white_clip.write_videofile("output.mp4",audio=False)