Go语言的分词器(sego)
今天,主要来介绍一个Go语言的中文分词器,即sego。本分词器是由陈辉写的,他的微博在这里,github详
见此处。由于之前他在Google,所以对Go语言特别熟悉。sego的介绍如下
sego是Go语言的中文分词器,词典用前缀树实现, 分词器算法为基于词频的最短路径加动态规划。
支持普通和搜索引擎两种分词模式,支持用户词典、词性标注,可运行JSON RPC服务。
分词速度单线程2.7MB/s,goroutines并发13MB/s, 处理器Core i7-3615QM 2.30GHz 8核。
接下来,以如下几个方面来介绍sego
1. sego的安装
2. sego的原理
3. sego的使用
1. sego的安装
首先,在Go语言中,有很多第三方包,可以帮助我们实现某些特定的功能。比如这里。而sego的项目在这里。
先把工程根目录加入GOPATH,然后执行如下命令
![]()
然后在sego项目根目录下就得到了src和pkg,这是一个Go语言项目,可以在src中创建文件进行使用。
sego的源文件如下
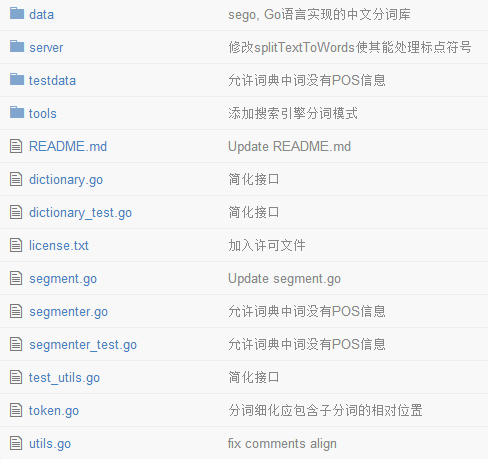
其中词库在data目录下,至此,sego就可以直接使用了。接下来会介绍sego的原理。
2. sego的原理
之前,我用过中科院的分词器ICTCLAS2014,它是一个非常优秀的分词器,支持C++,Java,C#,Hadoop等
等,使用起来非常方便,分词效果也不错,但是它不是开源的。今天介绍的sego分词器是开源Go语言分词器,
它的原理是:词典用前缀树实现,而分词器算法为基于词频的最短路径加动态规划。具体参考这两部分的代码
词典:dictionary.go
package sego
import (
"bytes"
)
// Dictionary结构体实现了一个字串前缀树,一个分词可能出现在叶子节点也有可能出现在非叶节点
type Dictionary struct {
root node // 根节点
maxTokenLength int // 词典中最长的分词
numTokens int // 词典中分词数目
tokens []*Token // 词典中所有的分词,方便遍历
totalFrequency int64 // 词典中所有分词的频率之和
}
// 前缀树节点
type node struct {
word Text // 该节点对应的字元
token *Token // 当此节点没有对应的分词时值为nil
children []*node // 该字元后继的所有可能字元,当为叶子节点时为空
}
// 词典中最长的分词
func (dict *Dictionary) MaxTokenLength() int {
return dict.maxTokenLength
}
// 词典中分词数目
func (dict *Dictionary) NumTokens() int {
return dict.numTokens
}
// 词典中所有分词的频率之和
func (dict *Dictionary) TotalFrequency() int64 {
return dict.totalFrequency
}
// 向词典中加入一个分词
func (dict *Dictionary) addToken(token *Token) {
current := &dict.root
for _, word := range token.text {
// 一边向深处移动一边添加节点(如果需要的话)
current = upsert(¤t.children, word)
}
// 当这个分词不存在词典中时添加此分词,否则忽略
if current.token == nil {
current.token = token
if len(token.text) > dict.maxTokenLength {
dict.maxTokenLength = len(token.text)
}
dict.numTokens++
dict.tokens = append(dict.tokens, token)
dict.totalFrequency += int64(token.frequency)
}
}
// 在词典中查找和字元组words可以前缀匹配的所有分词
// 返回值为找到的分词数
func (dict *Dictionary) lookupTokens(words []Text, tokens []*Token) int {
// 特殊情况
if len(words) == 0 {
return 0
}
current := &dict.root
numTokens := 0
for _, word := range words {
// 如果已经抵达叶子节点则不再继续寻找
if len(current.children) == 0 {
break
}
// 否则在该节点子节点中进行下个字元的匹配
index, found := binarySearch(current.children, word)
if !found {
break
}
// 匹配成功,则跳入匹配的子节点中
current = current.children[index]
if current.token != nil {
tokens[numTokens] = current.token
numTokens++
}
}
return numTokens
}
// 二分法查找字元在子节点中的位置
// 如果查找成功,第一个返回参数为找到的位置,第二个返回参数为true
// 如果查找失败,第一个返回参数为应当插入的位置,第二个返回参数false
func binarySearch(nodes []*node, word Text) (int, bool) {
start := 0
end := len(nodes) - 1
// 特例:
if len(nodes) == 0 {
// 当slice为空时,插入第一位置
return 0, false
}
compareWithFirstWord := bytes.Compare(word, nodes[0].word)
if compareWithFirstWord < 0 {
// 当要查找的元素小于首元素时,插入第一位置
return 0, false
} else if compareWithFirstWord == 0 {
// 当首元素等于node时
return 0, true
}
compareWithLastWord := bytes.Compare(word, nodes[end].word)
if compareWithLastWord == 0 {
// 当尾元素等于node时
return end, true
} else if compareWithLastWord > 0 {
// 当尾元素小于node时
return end + 1, false
}
// 二分
current := end / 2
for end-start > 1 {
compareWithCurrentWord := bytes.Compare(word, nodes[current].word)
if compareWithCurrentWord == 0 {
return current, true
} else if compareWithCurrentWord < 0 {
end = current
current = (start + current) / 2
} else {
start = current
current = (current + end) / 2
}
}
return end, false
}
// 将字元加入节点数组中,并返回插入的节点指针
// 如果字元已经存在则返回存在的节点指针
func upsert(nodes *[]*node, word Text) *node {
index, found := binarySearch(*nodes, word)
if found {
return (*nodes)[index]
}
*nodes = append(*nodes, nil)
copy((*nodes)[index+1:], (*nodes)[index:])
(*nodes)[index] = &node{word: word}
return (*nodes)[index]
}
分词器算法:segmenter.go
//Go中文分词
package sego
import (
"bufio"
"fmt"
"log"
"math"
"os"
"strconv"
"strings"
"unicode"
"unicode/utf8"
)
const (
minTokenFrequency = 2 // 仅从字典文件中读取大于等于此频率的分词
)
// 分词器结构体
type Segmenter struct {
dict *Dictionary
}
// 该结构体用于记录Viterbi算法中某字元处的向前分词跳转信息
type jumper struct {
minDistance float32
token *Token
}
// 返回分词器使用的词典
func (seg *Segmenter) Dictionary() *Dictionary {
return seg.dict
}
// 从文件中载入词典
//
// 可以载入多个词典文件,文件名用","分隔,排在前面的词典优先载入分词,比如
// "用户词典.txt,通用词典.txt"
// 当一个分词既出现在用户词典也出现在通用词典中,则优先使用用户词典。
//
// 词典的格式为(每个分词一行):
// 分词文本 频率 词性
func (seg *Segmenter) LoadDictionary(files string) {
seg.dict = new(Dictionary)
for _, file := range strings.Split(files, ",") {
log.Printf("载入sego词典 %s", file)
dictFile, err := os.Open(file)
defer dictFile.Close()
if err != nil {
log.Fatalf("无法载入字典文件 \"%s\" \n", file)
}
reader := bufio.NewReader(dictFile)
var text string
var freqText string
var frequency int
var pos string
// 逐行读入分词
for {
size, _ := fmt.Fscanln(reader, &text, &freqText, &pos)
if size == 0 {
// 文件结束
break
} else if size < 2 {
// 无效行
continue
} else if size == 2 {
// 没有词性标注时设为空字符串
pos = ""
}
// 解析词频
var err error
frequency, err = strconv.Atoi(freqText)
if err != nil {
continue
}
// 过滤频率太小的词
if frequency < minTokenFrequency {
continue
}
// 将分词添加到字典中
words := splitTextToWords([]byte(text))
token := Token{text: words, frequency: frequency, pos: pos}
seg.dict.addToken(&token)
}
}
// 计算每个分词的路径值,路径值含义见Token结构体的注释
logTotalFrequency := float32(math.Log2(float64(seg.dict.totalFrequency)))
for _, token := range seg.dict.tokens {
token.distance = logTotalFrequency - float32(math.Log2(float64(token.frequency)))
}
// 对每个分词进行细致划分,用于搜索引擎模式,该模式用法见Token结构体的注释。
for _, token := range seg.dict.tokens {
segments := seg.segmentWords(token.text, true)
// 计算需要添加的子分词数目
numTokensToAdd := 0
for iToken := 0; iToken < len(segments); iToken++ {
if len(segments[iToken].token.text) > 1 {
// 略去字元长度为一的分词
// TODO: 这值得进一步推敲,特别是当字典中有英文复合词的时候
numTokensToAdd++
}
}
token.segments = make([]*Segment, numTokensToAdd)
// 添加子分词
iSegmentsToAdd := 0
for iToken := 0; iToken < len(segments); iToken++ {
if len(segments[iToken].token.text) > 1 {
token.segments[iSegmentsToAdd] = &segments[iSegmentsToAdd]
iSegmentsToAdd++
}
}
}
log.Println("sego词典载入完毕")
}
// 对文本分词
//
// 输入参数:
// bytes UTF8文本的字节数组
//
// 输出:
// []Segment 划分的分词
func (seg *Segmenter) Segment(bytes []byte) []Segment {
return seg.internalSegment(bytes, false)
}
func (seg *Segmenter) internalSegment(bytes []byte, searchMode bool) []Segment {
// 处理特殊情况
if len(bytes) == 0 {
return []Segment{}
}
// 划分字元
text := splitTextToWords(bytes)
return seg.segmentWords(text, searchMode)
}
func (seg *Segmenter) segmentWords(text []Text, searchMode bool) []Segment {
// 搜索模式下该分词已无继续划分可能的情况
if searchMode && len(text) == 1 {
return []Segment{}
}
// jumpers定义了每个字元处的向前跳转信息,包括这个跳转对应的分词,
// 以及从文本段开始到该字元的最短路径值
jumpers := make([]jumper, len(text))
tokens := make([]*Token, seg.dict.maxTokenLength)
for current := 0; current < len(text); current++ {
// 找到前一个字元处的最短路径,以便计算后续路径值
var baseDistance float32
if current == 0 {
// 当本字元在文本首部时,基础距离应该是零
baseDistance = 0
} else {
baseDistance = jumpers[current-1].minDistance
}
// 寻找所有以当前字元开头的分词
numTokens := seg.dict.lookupTokens(
text[current:minInt(current+seg.dict.maxTokenLength, len(text))], tokens)
// 对所有可能的分词,更新分词结束字元处的跳转信息
for iToken := 0; iToken < numTokens; iToken++ {
location := current + len(tokens[iToken].text) - 1
if !searchMode || current != 0 || location != len(text)-1 {
updateJumper(&jumpers[location], baseDistance, tokens[iToken])
}
}
// 当前字元没有对应分词时补加一个伪分词
if numTokens == 0 || len(tokens[0].text) > 1 {
updateJumper(&jumpers[current], baseDistance,
&Token{text: []Text{text[current]}, frequency: 1, distance: 32, pos: "x"})
}
}
// 从后向前扫描第一遍得到需要添加的分词数目
numSeg := 0
for index := len(text) - 1; index >= 0; {
location := index - len(jumpers[index].token.text) + 1
numSeg++
index = location - 1
}
// 从后向前扫描第二遍添加分词到最终结果
outputSegments := make([]Segment, numSeg)
for index := len(text) - 1; index >= 0; {
location := index - len(jumpers[index].token.text) + 1
numSeg--
outputSegments[numSeg].token = jumpers[index].token
index = location - 1
}
// 计算各个分词的字节位置
bytePosition := 0
for iSeg := 0; iSeg < len(outputSegments); iSeg++ {
outputSegments[iSeg].start = bytePosition
bytePosition += textSliceByteLength(outputSegments[iSeg].token.text)
outputSegments[iSeg].end = bytePosition
}
return outputSegments
}
// 更新跳转信息:
// 1. 当该位置从未被访问过时(jumper.minDistance为零的情况),或者
// 2. 当该位置的当前最短路径大于新的最短路径时
// 将当前位置的最短路径值更新为baseDistance加上新分词的概率
func updateJumper(jumper *jumper, baseDistance float32, token *Token) {
newDistance := baseDistance + token.distance
if jumper.minDistance == 0 || jumper.minDistance > newDistance {
jumper.minDistance = newDistance
jumper.token = token
}
}
// 取两整数较小值
func minInt(a, b int) int {
if a > b {
return b
}
return a
}
// 取两整数较大值
func maxInt(a, b int) int {
if a > b {
return a
}
return b
}
// 将文本划分成字元
func splitTextToWords(text Text) []Text {
output := make([]Text, len(text))
current := 0
currentWord := 0
inAlphanumeric := true
alphanumericStart := 0
for current < len(text) {
r, size := utf8.DecodeRune(text[current:])
if size <= 2 && (unicode.IsLetter(r) || unicode.IsNumber(r)) {
// 当前是拉丁字母或数字(非中日韩文字)
if !inAlphanumeric {
alphanumericStart = current
inAlphanumeric = true
}
} else {
if inAlphanumeric {
inAlphanumeric = false
if current != 0 {
output[currentWord] = toLower(text[alphanumericStart:current])
currentWord++
}
}
output[currentWord] = text[current : current+size]
currentWord++
}
current += size
}
// 处理最后一个字元是英文的情况
if inAlphanumeric {
if current != 0 {
output[currentWord] = toLower(text[alphanumericStart:current])
currentWord++
}
}
return output[:currentWord]
}
// 将英文词转化为小写
func toLower(text []byte) []byte {
output := make([]byte, len(text))
for i, t := range text {
if t >= 'A' && t <= 'Z' {
output[i] = t - 'A' + 'a'
} else {
output[i] = t
}
}
return output
}
3. sego的使用
接下来介绍sego的使用。首先介绍网页版的分词器,在源文件的server目录下面,运行server.go,如下

server.go是一个轻量级的web服务器,端口为8080,在浏览器打开后如下图

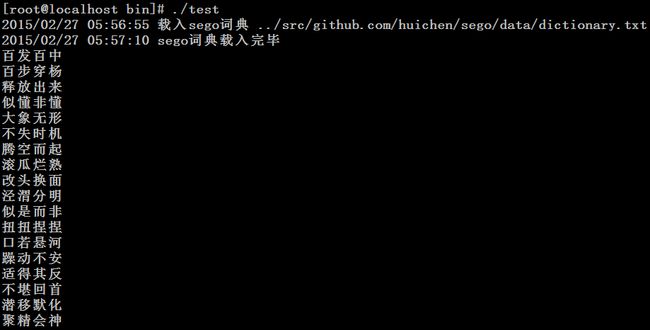
接下来,对如下文章进行分词
近年结识了一位警察朋友,好枪法。不单单在射击场上百发百中,更在解救人质的现场,次次百步穿杨。当然了,这个“杨”不是杨树的杨,而是匪徒的代称。
我向他请教射击的要领。他说,很简单,就是极端的平静。我说这个要领所有打枪的人都知道,可是做不到。他说,记住,你要像烟灰一样松散。只有放松,全部潜在的能量才会释放出来,协同你达到完美。
他的话我似懂非懂,但从此我开始注意以前忽略了的烟灰。烟灰,尤其是那些优质香烟燃烧后的烟灰,非常松散,几乎没有重量和形状,真一个大象无形。它们懒洋洋地趴在那里,好像在冬眠。其实,在烟灰的内部,栖息着高度警觉和机敏的鸟群,任何一阵微风掠过,哪怕只是极轻微的叹息,它们都会不失时机地腾空而起驭风而行。它们的力量来自放松,来自一种飘扬的本能。
松散的反面是紧张。几乎每个人都有过由于紧张而惨败的经历。比如,考试的时候,全身肌肉僵直,心跳得好像无数个小炸弹在身体的深浅部位依次爆破。手指发抖头冒虚汗,原本记得滚瓜烂熟的知识,改头换面潜藏起来,原本泾渭分明的答案变得似是而非,泥鳅一样滑走……面试的时候,要么扭扭捏捏不够大方,无法表现自己的真实实力,要么口若悬河躁动不安,拿捏不准问题的实质,只得用不停的述说掩饰自己的紧张,适得其反……相信每个人都储存了一大堆这类不堪回首的往事。在最危急的时刻能保持极端的放松,不是一种技术,而是一种修养,是一种长期潜移默化修炼提升的结果。我们常说,某人胜就胜在心理上,或是说某人败就败在心理上。这其中的差池不是指在理性上,而是这种心灵张弛的韧性上。
没事的时候看看烟灰吧。他们曾经是火焰,燃烧过,沸腾过,但它们此刻安静了。它们毫不张扬地聚精会神地等待着下一次的乘风而起,携带着全部的能量,抵达阳光能到的任何地方。
那么代码如下
package main
import (
"os"
"fmt"
"github.com/huichen/sego"
)
func main() {
// 载入词典
var segmenter sego.Segmenter
segmenter.LoadDictionary("../src/github.com/huichen/sego/data/dictionary.txt")
//读取文件内容到buf中
filename := "../src/test/Text"
fp, err := os.Open(filename)
defer fp.Close()
if err != nil {
fmt.Println(filename, err)
return
}
buf := make([]byte, 4096)
n, _ := fp.Read(buf)
if n == 0 {
return
}
// 分词
segments := segmenter.Segment(buf)
// 处理分词结果
// 支持普通模式和搜索模式两种分词,见utils.go代码中SegmentsToString函数的注释。
// 如果需要词性标注,用SegmentsToString(segments, false),更多参考utils.go文件
output := sego.SegmentsToSlice(segments, false)
//输出分词后的成语
for _, v := range output {
if len(v) == 12 {
fmt.Println(v)
}
}
}
运行结果如下
整个工程的结构如下