知识疫图背后的故事之地区风险预测与基于搜索日志疫情预测技术实践
AI TIME欢迎每一位AI爱好者的加入!
在AI TIME知识疫图专题的开篇,张鹏博士为大家介绍了清华大学AMiner团队联合多个研究团队和机构研发上线的“知识疫图”系统,一个集冠状病毒各种数据整合、大数据智能预测、知识图谱构建于一体的新冠综合服务平台。以成为全球新冠疫情智能驾驶舱为使命,知识疫图旨在打造一个基于知识的全球新冠疫情风险评估和复工辅助决策系统。在张鹏老师的报告中,我们了解了知识疫图的目标,领略了知识疫图的丰富内容,也为其强大的功能和智能化的服务所折服。
一颗种子的发芽,离不开阳光的照耀、雨露的浇灌。而一个系统的诞生,需要精心的设计,需要众多技术、模型的支撑,知识疫图亦是如此。“工欲善其事,必先利其器”,知识疫图的“利器”在于其背后强大的科研团队,以及对知识、AI技术、大数据多年的挖掘、探索。本次疫情知识智能服务技术实践系列第2期我们有幸邀请到了来自清华大学计算机系的曾奥涵和叶子逸,为大家解密知识疫图中新冠肺炎地区风险预测和基于搜索日志疫情预测两大模块背后的技术实践。

基于多维度信息的新冠肺炎地区风险预测
疫情期间,为了能够运用所学知识贡献自己的微薄之力,曾奥涵开始了疫情可视化的探索之旅。在前期调研中,研究人员发现虽然国内外已有很多疫情可视化项目(如图一),但是它们大多存在一些问题。比如只有疫情数据,数据种类单一,或者只呈现数据,缺乏数据分析。研究人员克服以上缺点推出了知识疫图综合型平台,该平台能够让用户直观且全面的了解疫情。作者曾奥涵在本次分享中主要介绍了知识疫图的疫情风险指数评估工作,内容包括风险指数的由来和模型的实现等。
图一 国内外疫情可视化项目
风险指数指的是一个国家或地区在某一时刻疫情的严重程度,通过将原始的疫情数据转化为直观的风险指数,让用户能直接地感知到疫情的严重程度。如图二的例子所示,将不同国家的确诊数量映射为不同地区的颜色块。用户通过视觉方式直观感受各地区的疫情状况。在风险指数评估地图项目中,知识疫图还结合疫情发展时间线,提供了如视频一展示的动态播放功能,通过动态的风险指数播放用户可以实时地捕捉世界整体疫情变化。
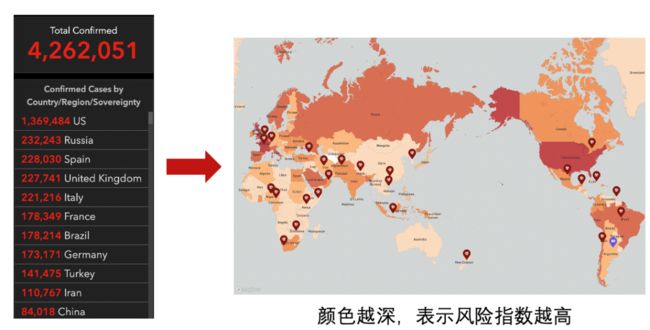
图二 风险指数示例
视频一 知识疫图风险指数动态播放
要想做到风险指数的有效可视化展示,前提是能够有效量评估风险指数。有效评估各国家和地区的疫情风险指数, 除了能够帮助用户更好的了解疫情的发展态势, 同时也能对个人、企业、政府的复产复工决策提供指标参考。然而影响一个地区的风险指数的因素很多,如疫情数据、人口密度、医疗条件等,需要综合考虑多维度信息,使得各个方面的因素均有所体现。同时要合理对信息进行聚合,使得评估方法具有泛化性,适应不同规模的国家与地区。在地区风险指数的评估上,知识疫图结合了疫情数据以及预测模型,地区的人口,面积等客观因素,同时参考了约翰霍普金斯大学的全球卫生安全数据,提出独特的风险指数评估模型。
在形式上,假设给定的疫情数据集为????,则时间????的风险指数由评估模型 ????:D´t®R的输出定义。对于某个地区的疫情数据集 ????Î????,????(????,????)描述了在时间 ???? 由 ????评估该区域的风险。令 ????????(????)=????(????,????),风险指数????????(????) 越大,则地区的疫情越严重。
计算时,将某一地区风险指数 RI(t) 分成两个部分考虑:(1)先验风险指数 RI_prior (地区的人口密度、医疗条件等客观因素,与时间无关);(2)后验风险指数 RI_posterior (t),根据 t 时刻之前的疫情时序数据评估得到。RI(t) 的计算方式如下:

先验风险指数计算中,density 表示地区人口密度,地区医疗条件参考 Johns Hopkins 发布的全球卫生指数(Global Health Index),用 ghi 表示,对于没有评级的地区,采用所有地区的平均值替代。后验风险指数使用时间 t 之前疫情的时序数据计算,直观上,有几个对风险指数比较重要的指标,如疫情的拐点、增长率、感染率、死亡率等。将这些指标拼接为一个向量 v(t)∈R^n,其中每个维度都是之前提到的一个疫情指标。w 是参数,σ(⋅)=max(0,⋅)。
通过构建的风险指数计算模型,得到各个国家不同时刻下随着疫情发展的风险指数曲线。风险指数曲线直观地展现了不同地区风险指数的变化趋势,通过与地区疫情曲线的对比可以检验模型的有效性。从图三的疫情曲线与风险指数曲线对比中,我们可以看出风险指数大体上与疫情实际情况相符,存在其合理性。此外,风险指数还具有疫情处于上升势头且尚未达到拐点时达到最高,可以放大数据突变,国家大小不敏感等特点。将得到的风险指数集成进知识疫图全球新冠疫情智能驾驶舱,随着国家和地区疫情数据实时更新,可以为用户提供及时、全面的指数参考。
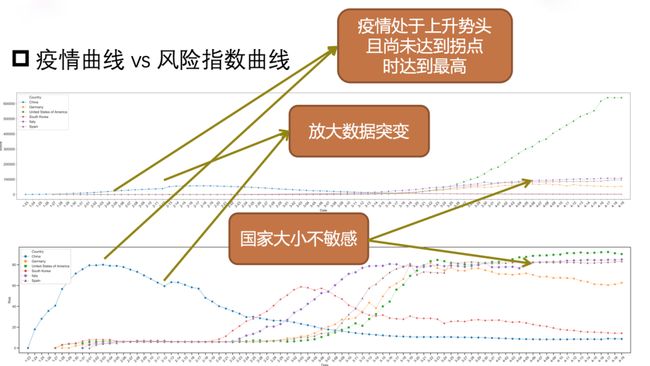
图三 疫情曲线(上)VS风险指数曲线(下)
总结来说,知识疫图提出了一种综合多维度信息的地区风险指数评估方法。不需要大量的人工干预,能够基于疫情数据和地区本身的客观情况计算,可以做到与疫情数据同样细粒度的风险评估。从结果上来看,计算得到风险指数能够比较好的反映地区风险情况。下一步的研究目标是希望将新闻事件也考虑进地区风险指数的计算,并将风险指数进一步细化,如出行风险指数,复工风险指数等,同时基于风险指数上线一系列惠及用户的实用功能。
基于搜索日志的新冠肺炎预测
在医疗卫生领域,传染病的监测主要依赖医生和有关医学机构的临床报告。但在这个过程中,从患者出现传染病的相关症状到前往医院确诊并最终上报数据存在延迟。如果能够提前预测传染病的发展趋势就能够更好地协助国家、有关医疗机构采取必要的防控手段,从而有效制止传染病的进一步传播。因此,设计一个高效准确的传染病传播预测模型至关重要。
随着现代信息技术特别是互联网的快速发展,搜索引擎成为人们获取医疗相关讯息的重要工具,这些大量的讯息数据涉及人们对疾病的关注、对自身症状的描述等。在新冠病毒疫情预测的研究中,研究人员发现搜索引擎用户行为和新型冠状病毒发展趋势息息相关。以图四的新冠肺炎为例,在潜在患者确诊的过程中,他们可能会和搜索引擎产生一系列交互,而在交互过程中生成的搜索日志可以作为监测新冠肺炎有效的间接信号。利用以搜索日志为基础的用户行为数据,生成额外的特征信息,可以有效协助新冠肺炎传播的预测,以便政府有关部门可以及时采取措施。在知识疫图项目中,叶子逸对基于搜索日志的新冠肺炎预测进行了深入研究。
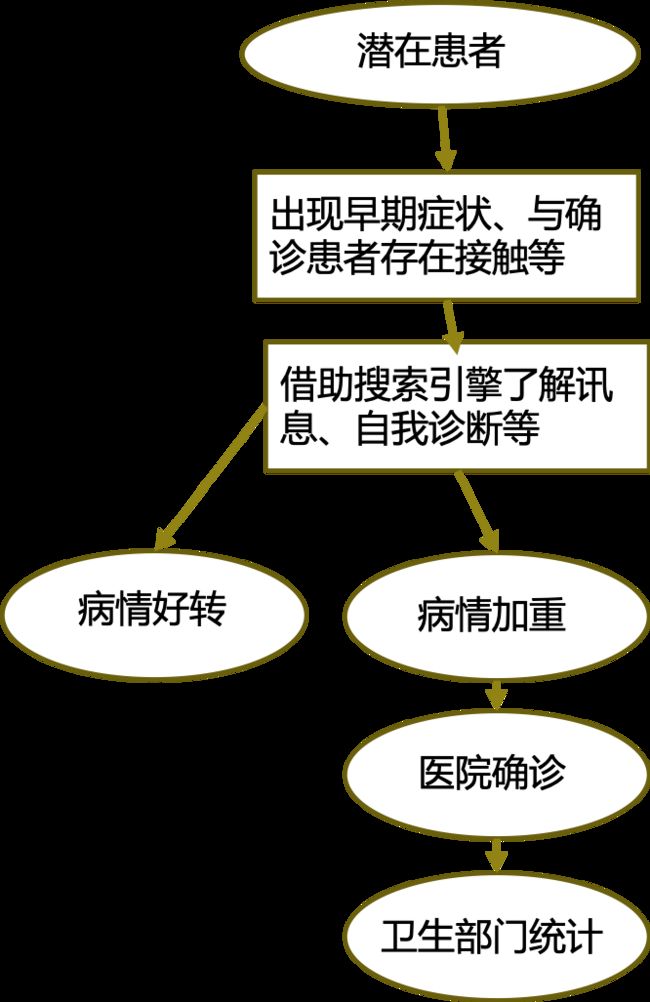
图四 潜在患者确诊过程
对于新冠病毒疫情预测,主要有传播动力学和时间序列两种思路。为了结合搜索日志这种用户行为信号进行新冠肺炎的预测,叶子逸主要采用了基于时间序列的回归模型和神经网络模型。
虽然在以往的学术研究中,有类似的研究范式,比如基于Google Trends的流行性感冒和登革热预测、基于传染病相关查询和相关网页集合进行流感预测、基于Twitter数据的H1N1预测等。但是此项任务面临着很多不同的挑战和困难。首先新型冠状肺炎的发展趋势与其他突发性传染病存在差异,比如影响更大、爆发性更强等。其次预测任务在时间粒度上与之前的研究存在差异,需要从周、月细化到每天。最后是要避免使用大数据进行研究带来的弊端,即避免过于依赖大数据进行特征抽取从而造成的噪声积累和伪相关性等输入特征问题。
基于搜索日志的新冠肺炎预测任务主要包含了三个步骤:(a)数据筛选(b)数据统计分析(c)模型应用,下面将逐一介绍。
a)
数据筛选
数据是预测基础,任务的第一步进行数据筛选。从某通用搜索引擎公司2020年1月1日到3月5日的搜索日志中过滤出包含病情相关查询(ERQ)的搜索记录,平均每天有100余万条,每条搜索日志包含ERQ、时间戳、点击信息、URL、空间信息等。在获取了原始数据之后,需要对这些大量的数据进行筛选,提取出有效信息。对此作者设计了如图五所示的基于点击二部图的图传播算法,图六是算法中部分的ERQ集合和得分情况。
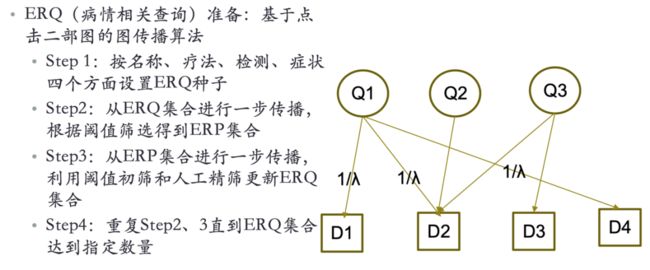
图五 基于点击二部图的图传播算法
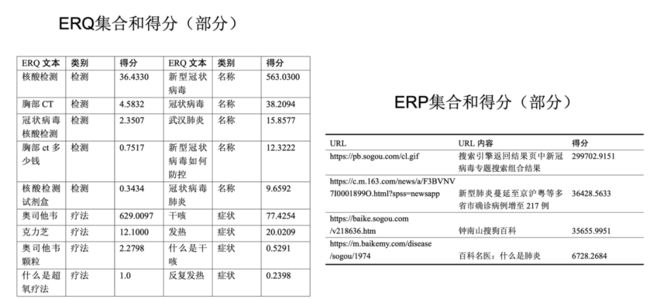
图六 部分ERQ集合和得分
b)
数据分布统计
第二步是对ERQ数据粗略的数据分布统计,从图七中可以直观地看出不同随机种子产生的ERQ集合频率分布不同,并将随着疫情的发展呈现出不同的变化。将ERQ集合频率与新冠疫情发展趋势进行比较(图八),从斜率来看,两者之间存在一定的相关性。
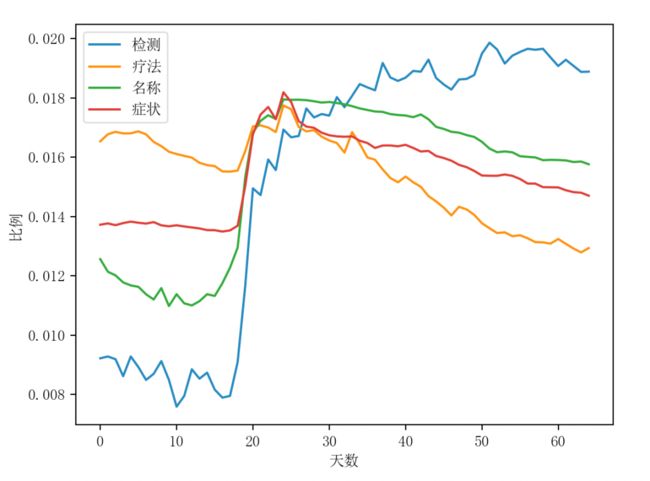
图七 ERQ种子频率分别
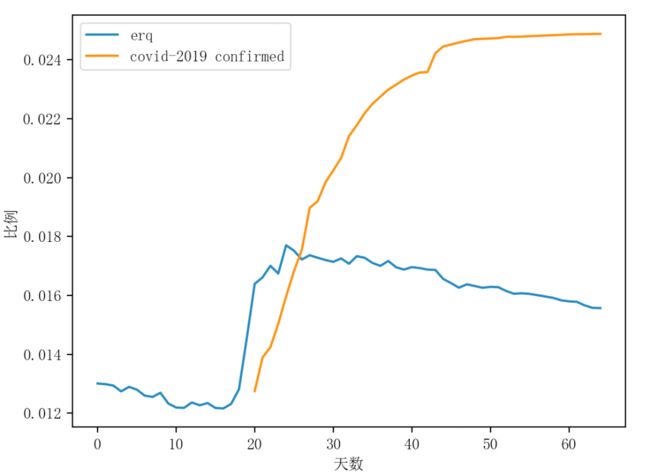
图八 ERQ集合频率与新冠疫情的趋势对比
c)
模型应用
结合对实验数据的观察,叶子逸主要考虑了自回归模型(AR,baseline)、长短期记忆网络模型(LSTM,不考虑ERQ,baseline)、自回归分布滞后模型(ADL,考虑ERQ)、使用词袋模型和k-means聚类融合各类ERQ特征的特征聚类的自回归分布滞后模型(ADL,考虑ERQ)、长短期记忆网络模型(LSTM,考虑ERQ)等几种不同模型。
为了验证模型的有效性,他将不同模型应用到了预测累计确诊数据(基于历史确诊数据,预测k天后的确诊人数)和预测新增与治愈人数(基于疑似数据与新增数据)两项实验任务中,不同模型在两项实验中的结果如图九、图十所示。

图九 预测累计确诊数据实验结果
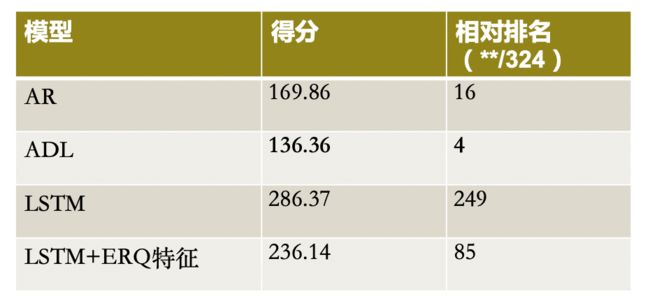
图十 预测新增与治愈人数实验结果
d)
总结
研究发现,引入ERQ数据在绝大多数任务中都能够提升病情趋势的预测性能。但引入ERQ数据作为传染病预测模型特征时,需要考虑病情趋势相对ERQ趋势的滞后效应,滞后天数在3-5天,对ERQ特征进行聚类后叠加为多个特征比直接叠加效果更好。未来叶子逸将探索分析不同搜索意图下的搜索引擎用户行为,更好地将疫情发展与用户意图、用户行为关联起来。
答疑互动
最后和大家分享直播后微信群里大家与两位嘉宾的部分互动,希望也可以对你认识知识疫图有所帮助。

用基于搜索日志的这种方法预测的时候,不同时期的效果是否会不同呢?

因为舆情的影响,不同时期的效果会有所差别,实验中疫情前中期效果比较好,但到后期新增病例变化不大的时候,效果有一定的下降,这是因为更多的搜索内容是舆情引起的。还有1月21日附近舆情爆发也有一定的影响,需要调整模型。

直播中提到咱们的预测模型中考虑到了疫情数据滞后的问题,那咱们是如何进行补偿和优化的呢?
因为从疑似用户产生搜索行为到确诊存在延迟,所以有一定的滞后现像。需要根据历史的经验和实际疫情与搜索记录的趋势分析来进行确定滞后的时间。其中利用典型症状相关的检索趋势是最为有效的。
请问有将传染病学模型预测结果作为衡量的参考吗?预测结果与传染病学模型的比较结果又怎么样?
这个问题很好,因为传染病学的模型需要的经验参数太多且专业性比较强。即使是网上一些相关基于传染病学模型的预测工作由于参数选取的原因效果差异也比较大,所以我没有实际实现传染病学的模型来进行比较。我觉得设计一个合适的传染病学模型,并尝试引入ERQ特征来进行模型比较是未来可以做的。
请问能不能实现实时或准实时的风险指数预测?
在我们的方法中,风险指数分为与时间无关的先验风险指数和与当前疫情数据有关的后验风险指数两个部分。所以我们的风险指数是随着疫情数据更新的,如果疫情数据是实时的,那么风险指数也是实时的。目前的疫情数据更新是一小时一次,风险指数也是。

那我们是用什么方法来评估风险指数预测结果的可靠性呢?
对于风险指数来说,的确没有一个客观的量化指标来评估可靠性。然而我们认为风险指数更重要的意义是提供在同一标准下一个不同国家和地区的风险状况的对比参考用以指导复产复工。此外,在风险指数的开发过程中,我们也与清华大学医学院、清华大学公共健康研究中心和清华大学社会学系的教授进行了合作,融入了一系列的专家知识,我们认为得到的结果应该是有一定的参考意义的。
风险指数预测的地理尺度最小能到什么程度呢?
理论上与疫情数据的粒度(中国到县/市,美国到 Country,意大利到大区)相同,但是由于地区客观数据(如面积、人口密度)不一定能完全匹配疫情数据的粒度,所以会有所减小,我们也会逐步也会完善这些客观数据的收集。
科学技术的发展为这个时代带来了各方面的进步,无论是我们的日常生活还是面临突发灾难时应对的举措,而在这发展的背后离不开无数科研人员坚持不懈的辛勤探索和研究。在此,除了感谢两位嘉宾带来的精彩分享以外,也感谢他们利用自己的专业知识为疫情做出的贡献,希望大家都可以学有所成、学有所用。之后的AI TIME技术专题将继续解密知识疫图智能服务背后的技术实践,学习路漫,下期分享我们不见不散!
整理:何文莉
审稿:叶子逸、曾奥涵
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://b23.tv/kQNGvj)