机器学习 leetcode总结
机器学习 leetcode总结
- 机器学习 leetcode总结
- 什么是机器学习?
- 机器学习模型
- 有监督 VS. 无监督
- 有监督学习
- 无监督学习
- 半监督学习
- 分类 VS. 回归
- 分类模型
- 回归模型
- 问题转换
- 机器学习怎么做?
- 机器学习工作流
- 以数据为中心的工作流
- 数据,数据,数据!
- 欠拟合 VS. 过拟合
- 欠拟合
- 过拟合
- 为什么存在?
- 为什么要机器学习
- 机器学习是万能的吗?
机器学习 leetcode总结
什么是机器学习?
机器学习模型
**机器学习(Machine Learning)**这个术语常常掩盖了它的计算机科学性质,因为它的名字可能暗示机器正在像人类一样学习,甚至做得更好。
机器学习算法是揭示数据中潜在关系的过程。
机器学习的任务,就是从广阔的映射空间中学习函数。
尽管我们希望有一天机器能够像人类一样思考和学习,但如今机器学习并不能超越执行预定义过程的计算机程序。机器学习算法与非机器学习算法(如控制交通灯的程序)的不同之处在于,它能够使自身的行为适应新的输入。而这种似乎没有人为干预的适应,偶尔会给人一种机器真的是在学习的错觉。然而,在机器学习模型的背后,这种行为上的适应和人类编写的每一条机器指令一样严格。
那么什么是机器学习模型?
机器学习模型(machine learning model)是机器学习算法产出的结果,可以将其看作是在给定输入情况下、输出一定结果的函数。
机器学习模型不是预先定义好的固定函数,而是从历史数据中推导出来的。因此,当输入不同的数据时,机器学习算法的输出会发生变化,即机器学习模型发生改变。
有监督 VS. 无监督
有监督学习

无监督学习

半监督学习

分类 VS. 回归
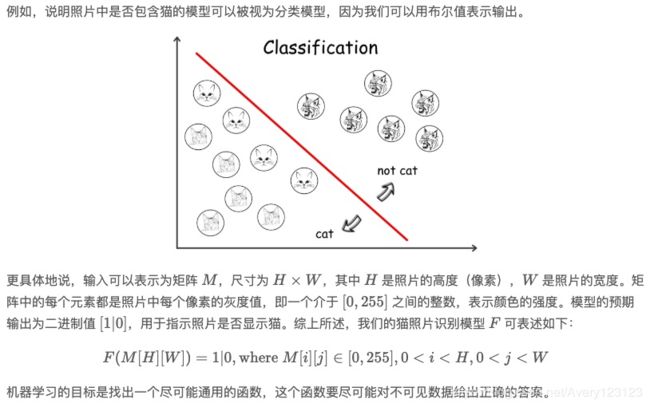
在前一节中,我们将机器学习模型定义为一个函数 F,它接受一定的输入并生成一个输出。通常我们会根据输出值的类型将机器学习模型进一步划分为分类(classification)和回归(regression)。
如果机器学习模型的输出是离散值(discrete values),例如布尔值,那么我们将其称为分类模型。如果输出是连续值(continuous values),那么我们将其称为回归模型。
分类模型
回归模型
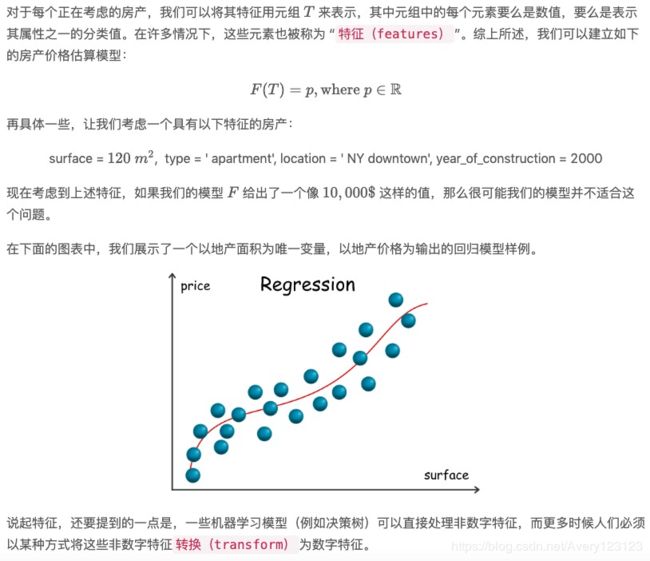
对于回归模型,我们给出这样一个例子,考虑一个用于估算房产价格的模型,其特征包括诸如面积、房产类型(例如住宅、公寓),当然还有地理位置。在这种情况下,我们可以将预期输出看作是一个实数 p∈R,因此它是一个回归模型。注意,在本例中,我们所拥有的原始数据并非全部是数字,其中某些数据是用于分类的,例如房地产类型。在现实世界中,情况往往就是这样的。
问题转换
对于一个现实世界的问题,有时人们可以很容易地将其表述出来,并快速地将其归结为一个分类问题或回归问题。然而,有时这两个模型之间的边界并不清晰,人们可以将分类问题转化为回归问题,反之亦然。
在上述房产价格估算的例子中,似乎很难预测房产的确切价格。然而,如果我们将问题重新表述为预测房产的价格范围,而不是单一的价格标签,那么我们可以期望获得一个更健壮的模型。因此,我们一个将问题转化为分类问题,而不是回归问题。

机器学习怎么做?
机器学习工作流
首先,我们不能一昧只谈论机器学习,而将数据搁置在一旁。数据之于机器学习模型就如燃料之于火箭发动机一样重要。
以数据为中心的工作流
毫不夸张地说,数据决定了机器学习模型的构建方式。在下图中,我们展示了机器学习项目中涉及的典型工作流。
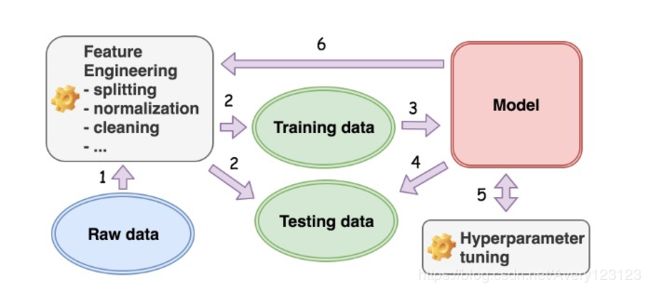
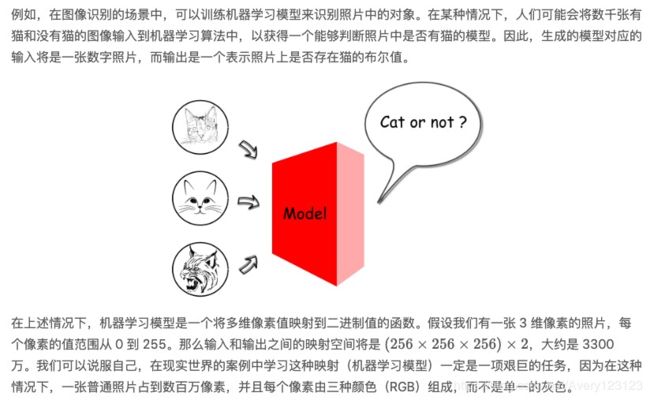
从数据出发,我们首先需要确定我们要解决的机器学习问题的类型,即有监督的学习问题还是无监督的机器学习问题。我们规定,如果数据中的一个属性是所需的属性,即目标属性,那么该数据被标记。例如,在判断照片上是否有猫的任务中,数据的目标属性可以是布尔值 [Yes|No]。如果这个目标属性存在,那么我们就说数据被标记了,这是一个简单的学习问题。
对于有监督的机器学习算法,我们根据模型的预期输出进一步确定生成模型的类型:分类或回归,即分类模型的离散值和回归模型的连续值。
一旦我们确定了想要从数据中构建的模型类型,我们就开始执行特征工程(feature engineering),这是一组将数据转换为所需格式的活动。下面给出了几个例子:

一旦数据准备好,我们就选择一个机器学习算法,并开始向算法输入准备好的训练数据(training data)。这就是我们所说的训练过程(training process)。
一旦我们在训练过程结束后获得了机器学习模型,就需要用保留的测试数据(testing data)对模型进行测试。这就是我们所说的测试过程(testing process)。
初次训练的模型往往无法令人感到满意。此后,我们将再一次回到训练过程,并调整由我们选择的模型公开的一些参数。这就是我们所说的超参数调优(hyper-parameter tuning)。之所以突出 “超(hyper)”,是因为我们调优的参数是我们与模型交互的最外层接口,而这最终会对模型的底层参数造成影响。例如,对于决策树模型,其超参数之一是树的最大高度。一旦在训练之前进行手动设置,它将限制决策树在结束时可以生长的分支和叶的数量,而这些正是决策树模型所包含的基本参数。
可以看到,机器学习工作流所涉及的几个阶段形成了一个以数据为中心的循环过程。
数据,数据,数据!
机器学习工作流的最终目标是建立机器学习模型。我们从数据中得到模型。因此,模型所能达到的性能上限是由数据决定的。有许多模型可以拟合特定的数据。我们所能做到最好的,就是找到一个可以最接近于数据所设置的上限的模型。我们不能期望一个模型能够从数据的范围之内学到其他东西。
经验法则: 若输入错误数据,则输出亦为错误数据。
用盲人摸象的寓言来说明这一观点也许是较为恰当的。故事是这样的,一群从来没有遇到过大象的盲人,他们试图通过触摸大象来了解和概念化大象是什么样子。每个人都可以触摸大象身体的一部分,如腿、象牙或尾巴等。虽然他们每个人都有接触到一部分真实情形,但没有一个人能获知大象的全貌。因此,他们中没有一个人可以真正了解大象的真实形象。

现在,回到我们的机器学习任务,我们得到的训练数据可能是来自象腿或象牙的图像,而在测试过程中,我们得到的测试数据是大象的完整肖像。不出所料,我们的训练模型在这种情况下表现不佳,因为我们没有更切合实际的高质量训练数据。
有人可能会想,如果这些数据真的很重要,那么为什么不将大象的完整肖像等 “高质量” 数据输入到算法中,而偏偏要输入大象身体某些部分的概况呢?这是因为,在面对一个问题时,无论是我们还是机器,就像 “盲人” 一样,或者是由于技术问题(例如数据隐私),或者仅仅是因为我们没有以正确的方式认识到问题,常常很难收集到能够描绘问题本质特征的数据,
现实世界中,在有利的情况下,我们得到的数据可能反映了现实的一部分,而在不利的情况下就可能是一些干扰判断的噪音,在最糟糕的情况下,甚至会与现实相矛盾。不管机器学习算法如何,人们都无法从包含太多噪音或与现实不符的数据中学到任何东西。
欠拟合 VS. 过拟合
对于有监督学习算法,例如分类和回归,通常有两种情况下生成的模型不能很好地拟合数据:欠拟合(underfitting)和过拟合(overfitting)。
有监督学习算法的一个重要度量是泛化,它衡量从训练数据导出的模型对不可见数据的期望属性的预测能力。当我们说一个模型是欠拟合或过拟合时,它意味着该模型没有很好地推广到不可见数据。
一个与训练数据相拟合的模型并不一定意味着它能很好地概括不可见数据。有以下几点原因:1). 训练数据只是我们从现实世界中收集的样本,只代表了现实的一部分。这可能是因为训练数据根本不具有代表性,因此即使模型完全符合训练数据,也不能很好的拟合不可见数据。2). 我们收集的数据不可避免地含有噪音和误差。即便该模型与数据完全吻合,也会错误地捕捉到不期望的噪音和误差,最终导致对不可见数据的预测存在偏差和误差。
在深入欠拟合和过拟合的定义之前,我们将会展示一些能够反映欠拟合和过拟合模型在分类任务中真实情形的示例。
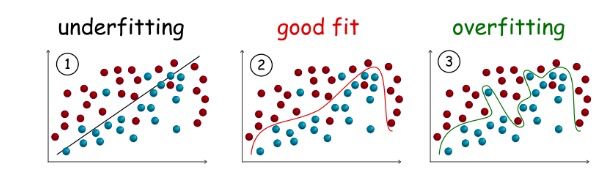
欠拟合
欠拟合模型是指不能很好地拟合训练数据的模型,即显著偏离真实值的模型。
欠拟合的原因之一可能是模型对数据而言过于简化,因此无法捕获数据中隐藏的关系。从上图(1)可以看出,在分离样本(即分类)的过程中,一个简单的线性模型(一条直线)不能清晰地画出不同类别样本之间的边界,从而导致严重的分类错误。
为了避免上述欠拟合的原因,我们需要选择一种能够从训练数据集生成更复杂模型的替代算法
过拟合
过拟合模型是与训练数据拟合较好的模型,即误差很小或没有误差,但不能很好地推广到不可见数据。
与欠拟合相反,过拟合往往是一个能够适应每一位数据的超复杂模型,但却可能会陷入噪音和误差的陷阱。从上面的图(3)可以看出,虽然模型在训练数据中的分类错误少了,但在不可见数据上更可能出错。
类似地于欠拟合的情况,为了避免过拟合,可以尝试另一种从训练数据集生成更简单的模型的算法。或者更常见的情况是,使用生成过拟合模型的原始算法,但在算法中增加添加了正则化(regularization)项,即对过于复杂的模型进行附加处理,从而引导算法在拟合数据的同时生成一个不太复杂的模型。
为什么存在?
为什么要机器学习
在阅读前面的章节之后,我们应该能够大致地说出机器学习(ML)算法是什么,并且应该对如何在项目中应用 ML 有一个简要的想法。
现在,在这一章中,我们正应该思考这个问题:为什么我们需要 ML 算法?
首先,我们需要承认,目前(2018 年),在我们生活中的许多方面,确实需要 ML 算法。值得注意的是,它在互联网服务中(如社交网络、搜索引擎等)无处不在,而我们每天都在使用这些工具。事实上,正如 Facebook 最近发表的一篇论文所揭示的那样,ML 算法变得如此重要,以至于 Facebook 开始从硬件到软件重新设计数据中心,以更好地满足应用 ML 算法的要求。
“在 Facebook 上,机器学习提供了驱动用户体验几乎所有方面的关键功能……机器学习广泛应用于几乎所有的服务。”
以下是关于 ML 如何在 Facebook 中应用的几个示例:
新闻提要中的事件排序是通过 ML 进行的。
显示广告的时间、地点和对象由 ML 确定。
各种搜索引擎(如照片、视频、人物)都是由ML支持的。
在我们现在使用的服务(例如谷歌搜索引擎、亚马逊电子商务平台)中,可以很容易地识别出许多其他应用 ML 的场景。ML 算法的普遍存在已经成为现代生活中的一种规范,这就证明了至少在现在和不久的将来都有其存在的合理性。
ML 算法之所以存在,是因为它们能够解决非 ML 算法无法解决的问题,而且还提供了非 ML 算法所不具备的优势。
区分 ML 算法与非 ML 算法的最重要特征之一是,它将模型与数据分离,以便 ML 算法能够适应不同的业务场景或相同的业务案例,但具有不同的上下文。例如,可以应用分类算法来判断照片上是否显示了人脸。它还可以用来预测用户是否会点击广告。在人脸检测的情况下,同样的分类算法可以训练一个模型来判断照片上是否出现了人脸,也可以训练另一个模型来确认照片上出现的是谁。
通过分离模型与数据,ML 算法可以一种更灵活、更通用、更自治的方式来解决许多问题,也就是说,它更像是一个人。ML 算法似乎能够从环境(即数据)中学习知识,并相应地调整其行为(即模型),以解决特定的问题。在不对 ML 算法中的规则(即模型)进行显式编码的情况下,我们构造了一种元算法,它能够以有监督或无监督的方式从数据中学习规则/模式。
机器学习是万能的吗?
和人类一样,ML 模型也会犯错。