【项目小结】英语语法错误检测(GEC)开题论文阅读记录
毕业论文准备尝试一下GEC,虽然没有过这方面的经验,但做老生常谈的课题实在是亏待宝贵的最后一年。其实最主要的原因是莫名奇妙被一个从来没上过课的教授加微信翻了牌子,我看了一下他给出的题目:英语句法分析、英语用词错误检测,文本摘要、文本阅读理解,还有一个乱入的野生动物识别,我自己觉得很有兴趣也非常具有挑战性,他让我自己选一个,我觉得后面三个思路相对单纯一些,可能就是seq2seq的模型和图片识别的问题;前两个似乎比较有趣一些(也许之后我就不这么觉得了...),便脑子一热选了句法分析检测。
但毕竟这块白板一块,所以做个综述草稿,主要是记录文献阅读的总结。
20191029 英语学习者书面语法错误自动检测研究综述_刘磊(2018.1)
1. 第一代GEC系统:采用简单的字符串匹配和替换识别、修改错误(Writer's Workbench)
第二代GEC系统:人工编纂的语法规则对文本进行句法分析(Epistle, Critique, MS Office)
第三代GEC系统:从大规模本族语或学习者语料库中提取词汇-句法特征,通过机器学习算法自动构建统计模型检测语法错误,如微软公司开发的ESL Assistant系统;
2. 学习者语料库:UICLE FCE Lang-8 NUCLE
3. 本族语者语料库:BNC Gigaword Wikipedia
4. 常用方法:
> N元语法模型(N-gram)
>> Markov Chain
判断是否 替换/添加/删除 介词会使得句子概率更大
> 自动分类模型
>> 用于冠词介词虚词错误,以及动词时态和形态错误
>> 语言特征:词形、词性、句法和语义信息
>> 算法:LR SVM NB 检测介词周围的语言特征概率分布
>> 一般根据具体错误类型,从训练语料提取特征,构建针对特定错误的语言模型
>> 能够检测未出现在训练语料中的新样本所包含的语法错误
> 机器翻译模型
>> 无需人工标注
>> 为了检测包含多处语法错误的句子:Many cat runs after a mouse, 如果主谓一致模块置于名词单复数之前则无法得出正确结果
>> 模型从双语平行语料库中自动抽取基于短语的双语词典,
e* = argmax(e){P(e|f)} = argmax(e){P(f|e)P(e)} f中文,e英文
>> 可以自动选取特征训练模型,更加擅长处理复杂错误
>> 通常与自动分类模型混合使用
5. 不同标注人员对语法错误的意见一致性存在差异(往往这种差异很大),因此在数据集的选取上需要多人员标注
6. 模型评估:主要根据PR曲线, 准确度即改的错误是否正确, 召回率即是否改全了所有错误?
CoNLL-2014 GEC系统评测结果:
语法错误类型 召回率 方法
(1)动词时态 19.61% 规则+N-gram
(2)情态动词 20.51% 规则+N-gram
(3)动词缺失 15.19% 规则+机器翻译模型
(4)动词形式 18.99% 规则+N-gram
(5)主谓一致 57.67% 自动分类模型
(6)冠词 47.87% 自动分类模型
(7)名词单复数 46.18% 自动分类模型
(8)名词所有格 11.11% 机器翻译模型
(9)代词格 15.52% 规则+机器翻译模型
(10)代词指代 9.35% 规则+机器翻译模型
(11)介词 24.94% 规则+机器翻译模型
(12)搭配 6.79% 机器翻译模型
7. 总结与展望:
(1)PR曲线质量很差,在CoNLL-2014中最好的模型PR值分别为39.71%与30.10%
(2)改进的方向:
· 语法规则的引入
· 语言特征的抽取
· 母语对语言产出的影响
20191029 基于LSTM和N_gram的ESL文章的语法错误自动纠正方法_谭咏梅(2018.6)
1. 本文主要就 冠词错误、介词错误、名词单复数错误、动词形式错误和主谓不一致五类语法错误 进行研究
2. GEC方法主要分为基于规则和基于统计
(1) 基于规则:
> 基于上下文无关规则驱动的方法
>> 少量规则不实用,大量规则会出现矛盾。局限性大
> 基于简单统计的规则驱动的方法
3. 基于LSTM与N-gram的GEC
(1)对于冠词、介词错误,将其看作一项特殊的序列标注任务(LSTM方法)
(2)名词单复数错误、动词形式错误、主谓不一致错误,混淆集为开放集合(N-Gram投票)
(3)一些预设的表:
> 冠词混淆集:
>> 三种冠词:the a/an 零冠词
> 介词混淆集:
>> 17个常见介词:on about into with as at by or from in of over to among between under within
> 名词单复数变化表:
>> 字段:类型(规则 不规则 单复数一致),单数(word person fish),复数(word people fish)
> 动词形式变化表:
>> 字段:类型(规则 不规则),动词原形(work write),过去式(worked wrote),过去分词(worked written),现在分词(working writing)
> 动词单复数变化表
>> 字段:类型(规则 不规则),单数(plays has),复数(play have)
(4)移动窗口及N-gram投票策略:(主要用于名词单复数错误、动词形式错误和主谓不一致)
> 移动窗口:
>> i:句中第i个单词; k:窗口大小; j:窗口内第一个单词与w(i)的距离
>> MW(i,k,w) = {w(i-j),...,w(i-j+k-1)} where j=0,1,...,k-1 共计k个子句构成一个移动窗口
>> k的大小及j的取值范围影响很大,通常k取3~5
> N-Gram投票策略(基于语料库的策略):
>> 如修改冠词错误时:"have the apple"频次2,"have an apple"频次1,"have apple"频次1,则选择频次最高的
>> 由于语料有限不可能遍历,考虑最小频次(频次高于某一水平方可参与投票)
>> 同时可以不同窗口大小的一起投票集成
(5)基于LSTM的标注纠正策略:(主要用于冠介词)
> 即先把冠词、介词的地方挖去,然后预测该位置最有可能的冠词或介词(softmax)
> 模型输入应该是双向LSTM更为合理,即为上下文都要有,我理解上上下文各取一个合适的padding
> 在预测冠词时序列信息可以包含词向量与词性,个人觉得相对来说词性占比重较大
4. 实验结果:
(1)基于CoNLL2013的GEC,就P-R曲线数据上看来仍然很差劲
(2)F1:冠词(0.2395),介词(0.2783),名词(0.3402),主谓一致(0.3445),动词形式(0.3387)
Baseline: 0.18 0.19 0.29 0.30 0.31
20191101更新
论文编号:W14-1713
论文题目:A Unified Framework for Grammar Error Correction
# 1. 引入
> HOO-2012仅考虑限定词(the a/an some等)与介词错误
> CoNLL-2013进一步考虑了名词单复数,动词形式和主宾一致
>> 高分系统对不同错误进行了不同的训练,使用不同的分类器
> CoNLL-2014共计考虑28种语法错误,包括拼写错误
>> 28种语法错误用不同的分类器是代价极大且不现实的
>> 因此希望用一种统一架构来解决GEC,不可避免的忽视一些语法错误
> 利用翻译模型要求大量的学习者母语语料库的数量,而往往这是很难找到的
# 2. 任务描述
> 针对CoNLL-2014的解决方案
# 3. 系统概观
## 3.1 改观
> 为每种语法错误训练一个模型不现实,系统使用统一框架进行语法错误修正
>> 句中每个单词可能对应多种错误,由此为每个单词生成候选集
>> 使用语言模型(LM)周到最大概率的序列(N-gram)
>>> LM用于替代型错误,而非插入与删除型错误
>>> 因此为限定词与介词各训练一个分类器
## 3.2 修正候选集生成
> 基于如下规则:
>> 同源词
>> 相似拼写的单词(计算alignment distance) --> 提前计算好单词序列距离矩阵
> 系统中为每个单词设置了10个候选
> 只为如下的单词设置了第二种规则的候选:
>> 没有出现过在语料中的单词
>> 出现在语料中但频次少于某阈值
>> 不为NNP NNPS的单词设置(它们是名词复数形式),因为它们的正确性还取决于许多其他因素,如上下文
## 3.3 LM for 候选挑选
> 使用3-gram:P(wi|wi-2,wi-1)
> 可以根据实际情况调整P(wi|wi-2,wi-1),如一些明显正确的搭配可以加大概率
> 不为介词/限定词设置候选,因为它们很频繁,且学习者很容易犯错,因此另寻模型
## 3.4 限定词修正
> 同样的这里的冠词修正也是看作定冠词,不定冠词,零冠词的多分类问题
>> 考虑冠词时因为存在零冠词错误的可能性,所以需要考虑空格,这里没有考虑所有空格,只考虑名词性短语前的空格
>> 实验表明1-gram和2-gram已经足够,3-gram与4-gram没有能够提升性能
> 训练集很少,选择使用 English Gigaword corpus 生成训练数据(而非CoNLL-2014)
>> English Gigaword corpus 中都是新闻文本,英语本土人说的话,因此可以认为是黄金法则
> 生成训练集的方法:
>> 每个空格都挂上NULL的标签,选取每个NULL前三个单词与后三个单词生成特征
>> 每个冠词我们同样是前三个后三个单词生成特征
## 3.5 介词修正
> 原理基本与3.4相同,但是我感觉要难很多,因为零介词的情况很难区分
## 3.6 预处理
> 区分a/an
> 分割单词(如dailylife分为daily和life)
> 句首字母大写
# 4 实验分析
> 结果:
MODEL P R F0.5
LM 0.2989 0.1004 0.2142
LM+det 0.3223 0.1364 0.2533
LM+prep 0.2973 0.1004 0.2135
LM+det+prep 0.3221 0.1365 0.2532
> 调参后最优结果:
LM+det+prep 0.3664 0.1596 0.2910
> recall很小,因为设置的det与prep的阈值很高,即置信度高于0.99(论文中使用的阈值)时才会改正
20191121 更新 1812.08434 一篇来自清华大学的GNN的综述,个人觉得写得非常好,因为很多都看不懂。。。
今天问了一下,可能GNN跟GEC的关系并不大,似乎GEC是用不到GNN的。。。
图神经网络综述
【摘要】
很多学习任务中处理包含众多关系的图数据。物理系统建模、分子指纹图谱、预测蛋白质界面、疾病分控需要一个图输出的结果。在其他领域如学习非结构化数据(文本、图片),推理(如从图片中提取文字信息)也很需要GNN。GNN是一种通过节点来捕获图的相关性的关联型模型。起初GNN在早期存在训练上的难度,目前图卷积网络GCN与门控图神经网络GGNN的兴起改善了这种情况。本文我们详细综述各个GNN模型,系统性的分类并且展望发展前景
# 1 Introduction
> GNN刻画实体与关系,具有更强的表现力
> GNN源于CNN,CNN刻画局部特征,但只能处理常规的欧式数据(如2D的图像与1D的序列)。深入研究CNN我们发现CNN的关键是局部联系、共享权重、多层架构。这在解决图领域也是很重要的:
>> 图是典型的局部联系结构
>> 共享权重在图中同样可以节约计算量
>> 多层架构是处理层次模式的关键
因此从CNN到GNN是很直观的
> 另一种动机来自图嵌入,用于学习表示图节点、边和子图
>> DeepWalk用于解决随机游走问题,是基于表示学习,应用SkipGram模型的第一次图嵌入的成功应用
>> Node2Vector,LINE,TADW之后陆续取得突破
>> 上述方法的缺陷及改进:
>>> encoder中缺少参数共享,计算量庞大
>>> 直接嵌入方法缺少泛化能力,无法处理其他动态图以及应用到新图中
>>> 基于CNN与图嵌入,GNN可以从图结构中汇集信息
>>> 基于RNN可以对传播过程(diffusion process)建模
> GNN的优势:
>> 第一,CNN与RNN无法处理图输入,因为它们通常视图节点为有序的,然而图节点不存在自然排序,因此为了体现无序性,需要遍历所有的排序,这种计算量是骇人听闻的。而GNN处理图结构时分别分别传播节点,无视节点的输入顺序,也就是说,GNN的输出与GNN的输入顺序是无关的
>> 第二,图中的边表示两个节点的依赖关系,在CNN与RNN中这种依赖关系被认为是节点的特征,而GNN则通过这种特征来传播。GNN通过对邻接点状态加权求和更新隐层节点
>> 推理是高级AI,在人脑中推理过程就是基于日常经历得到的图结构,CNN与RNN无法从经验数据推出图结构,而GNN则致力于从非结构化数据绘制图。
>> 近期,实验表明即使是一个未训练的简单结构GNN也能表现的很好
# 2 Models
## Graph Neural Networks
> GNN起初被提出用于处理图表示的数据结构,图中每个节点被用其本身特征以及其相关节点来定义
> GNN的目标是学习一个状态嵌入hidden_vector h_v ∈ R^s来刻画一个节点本身及其邻里关系,它可以有输出out_vector o_v(如节点的标签)
>> h_v = f(x_v,x_co[v],h_ne[v],x_ne[v]) f称为“局部转移函数”,它的四个参数分别为节点v的特征、连接节点v的边的特征、节点状态、节点邻里特征
>> o_v = g(h_v,x_v) g称为“局部输出函数”
> 令H,O,X,X_N包含这一切状态、一切输出、一切特征、一切节点特征,则我们得到一个完全形体:
>> H = F(H,X) F成为“全局转移函数”,注意到H在本方程中是不动点,当F为压缩映射时H唯一确定,并且可以通过H_t+1 = F(H_t,X)的迭代方式逼近H的值
>> O = G(H,X_N) G称为“全局输出函数”
> f,g中的计算可以被看作是前馈神经网络,如何计算f,g的参数值是问题?
> 我们定义损失函数loss = SUM_1~p(t_i-o_i) 其中p是有监督的节点数量,学习算法基于梯度下降策略,具体算法步骤如下:
>> h_v_t 通过 h_v = f(x_v,x_co[v],h_ne[v],x_ne[v]) 迭代T步得到,最终的H(T)≈H
>> 权重W的梯度从损失函数中计算得到,并通过梯度下降法更新
> 局限性:
>> 为了一个不动点H来迭代地更新隐层节点h_v是低效的,如果我们松弛这个不动点H的假设,则可以设计一个多层GNN来得到一个节点及其邻里关系的稳定表示
>> GNN在不同次的迭代中使用相同的参数,大部分的主流网络每层都是不一样的,注意到更新隐层状态h_v是一个序列过程,可以用RNN来优化(如GRU与LSTM)
>> GNN也并非能够表示所有特征,如知识图谱中的边包含了关系类型以及传播中的一些信息(上下位),并且如何学习h_v也是一个问题
>> 使用不动点H的是不合适的,如果我们知识着重于节点表示而不是图的表示,因为不动点的表示分布在值上过于光滑且信息太少,很难区别于其他点(这个我没看懂,也无所谓懂不懂)?
## Variants of Graph Neural Networks
### Graph Types
> 常规GNN中的图是无向图,存在许多变体:
>> 有向图
>>> 如知识图谱中的的箭头从上位指向下位,不同的方向在传播上是不一样的
>>> ADGPM使用两种不同的权重矩阵,H_t = σ(D_p^-1 * A_p * σ(D_c^-1 * A_c * H_t-1 * W_c) * W_p) 其中 D_p^-1 * A_p 与 D_c^-1 * A_c 分别是父子标准化的邻接矩阵
>> 异构图
>>> 异构图中存在多种不同的节点,最简单的处理方法是用 one-hot 特征向量表示
>>> GraphInception 引入了“元路径”的概念,它根据不同的节点类型及距离用来汇总邻接节点
>>> 对于每个邻居组,GraphInception将其视为子图来传播与联系
>> 有边信息的图
>>> 先把图变成二部图(这个转化方法有点迷),然后在节点上添加信息即可
### Propagation Types
> 传播步骤与输出步骤是GNN中最重要的部分,它们是用来获得节点(或者)隐层状态的
> 不同的传播类型:
>> 以图的类型分类:
>>> 有向图:ADGPM
>>> 异构图:GraphInception
>>> 带有边信息的图:G2S R-GCN
>> 以训练方法分类:
>>> 邻里采样:GraphSAGE FastGCN Adaptive
>>> 感知域控制:ControlVariate
>>> Boosting:Co-trainingGCN Self-trainingGCN
>> 以传播步骤分类:
>>> 卷积汇集:GCN
>>> 注意力汇集:GraphAttentionNetwork
>>> 门更新单元:GRU LSTM
>>> 跳过联系:HighWayGNN
#### Convolution
> 将卷积带入图领域是很有趣的事情,主要分为spectral-approaches与nonspectral-approaches
>> spectral-approaches:(看不懂,无能为力)
>> nonspectral-approaches:(看不懂,无能为力)
#### Gate
> GRU与LSTM使用了门单元,在GNN中使用门单元可以提高图架构中信息长期传播的质量
> GGNN:在传播步骤中使用GRU门单元,展开RNN到一个固定的次数T,并且使用反向传播计算梯度
>> 公式21:Page_9
> LSTM与GRU一样也会使用到:
>> 公式22:Page_9
>> Child-Sum Tree-LSTM
>> N-ary Tree-LSTM
>> Sentence-LSTM:用于提升文本编码,将文本转化为一张图且优化Graph LSTM来学习表示
#### Attention
> 注意力机制已经被成功应用于基于序列的任务,如机器翻译、机器阅读
> Graph Attention Network(GAT)
> Graph Attention Layer
> multi-head attention:
>> 常规更新:h_i' = σ(∑(a_ij*W*h_j))
>> 多头更新:h_i' = σ((1/K)*∑_1~K(∑(a_ij_k*W*h_j)))
> 注意力机制的性质
>> 相邻节点对的计算可以并行,因此传播是高效的
>> 可以用于有不同出入度节点的图
>> 可以被轻松用于归纳学习问题(我觉得这里的意思可能是迁移学习)
#### Skip connection
> 许多应用选择展开或者堆叠神经网络来取得更好的结果
> 但是实验发现更深的模型未必有更好的结果,甚至表现得更差,原因可能是更多的网络层会使得噪声在传播过程中不断扩大
> 解决这种问题的一个直接的方法是使用残差网络,即便如此,2层的GCN在大部分的数据集上也要比多层GCN要表现得更好
> 另外还有一种叫作 Highway-GCN 的方法,是添加了Highway gate的东西,此时4层最优
### Training Methods
> GCN的弱点:
>> GCN要求全图拉普拉斯矩阵(拉普拉斯矩阵L = 度矩阵D - 邻接矩阵A),对于大图来说计算很耗时
>> 因为每层GCN都要recurrent递归,所以节点数是几何阶数递增的
>> GCN只能为特定图训练,缺乏延展性(迁移能力)
> GraphSAGE是对GCN的一个综合提升
> FastGCN进一步提升了采样算法
> 另外还有两种改进,分别基于随机近似算法与协同训练
## General Frameworks
### Message Passing Neural Networks(MPNNs)
> 用于监督学习
> 模型包括两阶段:信息传递阶段与读出阶段
>> 信息传递阶段:看不懂
>> 读出阶段:看不懂
### Non-local Neural Networks(NLNN)
> 为了深度神经网络中捕获长范围的关联而提出
> non-local算子:它用一个加权汇总所有位置的特征来计算表示一个位置的响应
>> NLNN可以视为不同的“自注意力”的方法的融合
>> 由该算子推得出的generic non-local 算子定义如下:h_i' = (1/C(h)) * ∑_j(f(h_i,h_j)*g(h_j)),其中f与g有很多的不同的选择:
>>> Gaussian:f(h_i,h_j) = exp(h_i.T * h_j)
>>> Embedded Gaussian:f(h_i,h_j) = exp(θ(h_i).T * δ(h_j))
>>> Dot Product:θ(h_i).T * δ(h_j)
>>> Concateation:ReLU(...)
### Graph Networks
> 图定义:G = (u,H,E),分别表示全局性质,顶点集,边集
> 图网络块:每个GN block里面包含3个“更新函数”(Φ_e(ek,h_rk,h_sk,u) Φ_h(e'_i,h_i,u) Φ_u(e'_,h'_,u))与3个“汇总函数”(ρ_eh(Ei') ρ_eu(E') ρ_hu(H'))
> 图计算步骤(GN block):(看不懂,要结合)
>> Φ_e函数更新每个边
>> ρ_eh汇总边Ei' --> e'_i
>> Φ_h函数更新节点
>> ρ_eu汇总边E' --> e'_
>> ρ_hu更新H' --> h'_
>> Φ_u更新u
> 设计规则
>> 灵活表示
>> 配置within-block架构
>> 可合成的多块架构
# 3 Applications 应用
## Structural Scenarios
> 物理
>> Interaction Networks
>> Visual Interaction Networks
> 化学与生物
>> 分子指纹
>> 蛋白质界面预测
> 知识图谱!!!
## Non-structural Scenarios
> 图片
>> 图片分类
>> 虚拟推理
>> 语义分割 Semantic segmentation
> 文本
>> 文本分类
>> 序列标注
>> 神经机器翻译
>> 关联挖掘
>> 实践挖掘
>> 其他应用
## Other Scenarios
> 生成模型
>> NetGAN
> 联合优化
# 4 Open Problems
> Shallow Structure
> 动态图
> 非结构化场景
> Scalability:可延展性及规模化
# 5 Conclusion
20191129更新 1909.00502 当前时间节点上的NO.1论文
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
# 【摘要】
- 将伪造数据引入到GEC中是一种提升模型性能的方法, 然而这种共识缺乏实验配置, 即选择如何生成伪造数据以及使用伪造数据, 本研究中, 通过广泛的实验找到了在CONLL-2014上的较好测试结果, F0.5指数为65.0, 且官方测试集(BEA-2019)的测试结果F0.5指标70.2, 其中后者没有对前者在模型上进行修正;
# 1. Introduction
- 如今许多研究将GEC问题当作机器翻译(MT)任务来解决, 不符合语法的句子被认为是源语言, 符合语法的句子被认为是目标语言, 于是encoder-decoder(EncDec)得以使用, 并且取得较好的结果;
+ EncDec使用的问题在于需要大量训练数据, 而最大的公开数据集是Lang-8仅有200M个句子对;
+ 所以我们需要伪造训练数据的方法是很紧急的;
- 伪造数据的要点:
+ 生成伪造数据的方法;
+ 伪造数据的种子语料;
+ 优化设置;
- 伪造数据的要点并未达成共识:
+ 回译(backtranslation)方法: 回译方法要比DirectNoise方法表现得好
+ 但最近的优秀模型使用的是DirectNoise方法
- 本研究主要提供提升模型效果的生成伪造数据的方法
# 2. Problem Formulation and Notation
- 常用标记:
+ D: GEC的训练数据集, 包含了不合语法的句子X与合语法的句子Y, 我们一般通过Y来生成伪造数据(此时我们称Y为种子语料SeedCorpus), D={(Xi,Yi) i=1~n}
+ Θ: 表示模型中所有可训练的参数, 我们的目标是找到最优的参数集Θ^来最小化目标函数L(D,Θ)
+ L: 损失函数 L(D,Θ)=-(1/|D|) * ∑log(p(Yi|Xi,Θ))----(1)
- 我们的兴趣在于(1)式的三个非平凡方面:
+ 生成伪造数据集Dp的有哪些方法?
+ 如何选择种子语料(即合语法的句子集)?
* 我们比较了三种种子语料: Wikipedia, SimpleWiki, English Gigaword;
* 前面两个领域相似但有不同的语法复杂度, 因此可以用于对比不同语法复杂度对模型的影响;
* Gigaword被认为是噪声最小的, 可以用来验证是否干净的文本能够提升模型性能;
+ 对于(1)式的优化至少有两个办法:
* 第一种令 D = Dg ∪ Dp (JOINT), Dg称为真实的平行数据集, Dp是伪造集, 直接训练
* 第二种对Dp进行与训练, 即先最小化L(Dp,Θ)以获得Θ', 然后再最小化L(Dg,Θ') // 个人觉得这个方法好像有点意思
# 3. Methods for Generating Pseudo Data
- 介绍三种方法, 前两种是回译方法的变体, 用于EncDec模型, 从一个合法句子生成一个非法句子(这是一个逆模型), 逆模型的输出配上输入可以作为伪造数据:
+ Backtrans(noisy): 添加一个r*β_random到迭代优化每步中的得分中
* 噪声 r 服从 Uniform[0,1]
* β_random为超参数用于控制噪声规模, 若为0则退化为标准的回译方法;
+ Backtrans(sample): 即句子被decode通过对逆模型的分布中采样得到;
+ Directnoise:
* 前两种方法都是利用逆模型生成不合乎语法的句子, 该方法是直接将噪声插入到合乎语法的句子中去;
* 特别的, 对于给定的一个句子, 该方法随机做下面四种事情之一(概率应当预设μ_mask,μ_deletion,μ_insertion,μ_keep):
· 用一个占位符
· 删除;
· 插入一个随机标记;
· 保持原样;
# 4. Experiments
- 实验目的基于第二部分中的三个非平凡方面;
- 为确保实验结果在GEC中具有普遍性, 使用了以下两个策略:
+ 我们使用一个没有明确目标的架构或技术的 off-the-shelf EncDec 模型;
+ 我们调整超参数, 评估以及比较每种方法在验证集上进行, 然后在测试集上做一次模型检测;
## 4.1 Experimental Configurations
- 数据集:
+ BEA-2019 被分为训练集(561410), 验证集(2377), 测试集(4477); 种子语料选取了SimpleWiki/Wikipedia/Gigaword, 对每个语料采用了噪声化处理, 得到了伪造数据集Dp; 另外还使用了CoNLL-2014与JFLEG作为测试集;
- 评估方式: ERRANT, M2-scorer, GLEU, JFLEG;
- 模型: Transformer EncDec 模型
- 优化:
- 对于第二部分中提到的JOINT配置, 我们利用Adam优化;
- 对于第二部分中提到的PRETRAIN配置, 我们利用Adam优化然后用Adafactor迁移学习;
## 4.2 Aspect(i): Pseudo Data Generation
- 比较Backtrans(Noise), Backtrans(sample), DirectNoise三种方法生成伪造数据的有效性;
+ DirectNoise 实验: (μ_mask,μ_deletion,μ_insertion,μ_keep) = (0.5,0.15,0.15,0.2);
+ Backtrans(Noise)中: β_random = 6;
+ 使用JOINT配置以及种子语料为SimpleWiki;
- 三种伪造数据的实验结果:
---------------------------
|方法|查准率P|查全率R|F0.5|
|Baseline|46.6|23.1|38.8|
|Backtrans(sample)|44.6|27.4|39.6|
|Backtrans(noisy)|42.5|31.3|39.7|
|DirectNoise|48.9|25.7|41.4|
----------------------------
+ Backtrans(noisy)在解码不合语法的句子时比Backtrans(sample)快1.2倍;
+ DirectNoise在F0.5的表现非常好;
## 4.3 Aspect(i): Seed Corpus T
- 三种种子语料的实验结果:
----
|方法|种子语料|查准率P|查全率R|F0.5|
|Baseline|N/A|46.6|23.1|38.8|
|Backtrans(noisy)|Wikipedia|43.8|30.8|40.4|
|Backtrans(noisy)|SimpleWiki|42.5|31.3|39.7|
|Backtrans(noisy)|Gigaword|43.1|33.1|40.6|
|DirectNoise|Wikipedia|48.3|25.5|41.0|
|DirectNoise|SimpleWiki|48.9|25.7|41.4|
|DirectNoise|Gigaword|48.3|26.9|41.7|
----
+ 设置|Dp|为1.4M;
+ F0.5的差别很小, 表明种子语料对模型表现影响很小, 但是Gigaword的表现要优于其他两个语料;
## 4.4 Aspect (iii): Optimization Setting
- 这部分比较JOINT与PRETRAIN两种设置情况的效果;
- 该部分使用Wikipedia, 一方面因为SimpleWiki太小了, 另一方面Gigaword似乎并不容易获得, 不方便其他研究者来复制结果;
- JointTraining v.s. Pretraining
-----------------------------------------------
|优化策略|方法|Dp集合规模|准确率P|召回率R|F0.5|
|N/A|Baseline|0|46.6|23.1|38.8|
|Pretrain|Backtrans(noisy)|1.4M|49.6|24.3|41.1|
|Pretrain|DirectNoise|1.4M|48.4|21.2|38.5|
|Joint|Backtrans(noisy)|1.4M|43.8|30.8|40.4|
|Joint|DirectNoise|1.4M|48.3|25.5|41.0|
|Pretrain|Backtrans(noisy)|14M|50.6|30.1|44.5|
|Pretrain|DirectNoise|14M|49.8|25.8|42.0|
|Joint|Backtrans(noisy)|14M|43.0|32.3|40.3|
|Joint|DirectNoise|14M|48.7|23.5|40.1|
--------------------------------------
+ 显然, Pretrain中Dp集合规模越大, 效果越好, Joint则不然;
+ 关于上面这件事情的解释我觉得略显牵强, 遂不加以赘述;
- 伪造数据的数量:
+ 我们测试了伪造数据集的数量{1.4M, 7M, 14M, 30M, 70M}, 从图1可以看出Backtrans(noisy)的F0.5指标纯优于DirectNoise, 并且两者随着伪造集的规模上升F0.5指标不断上升(70M时回译达到45.9);
## 4.5 Comparison with Current Top Models
- 如今的实验表明以下设置是有效的:
+ 结合 Joint 与 Gigaword (## 4.3);
+ Joint配置中的伪造数据集数量不应过多(## 4.4a);
+ Pretrain配置中使用Backtrans(noisy)的可以尽量用大的伪造集(## 4.4b);
+ 目前的Top模型可以做到F0.5 = 61.3(P5有一张表);
- 可以改进的方向:
+ 人造拼写错误(SSE): 加入字母级的噪声进入Dp;
+ 从右到左的重排序(R2L): 我们训练4个从右到左的模型, 在集成4个从左到右的模型, 生成n个最好的候选集以及他们对应的得分, 把这n个候选集输入到从右到左的模型中得到得分并重排序(我人都傻了);
+ 句子级别的错误探测(SED): 动机在于SED可以潜在地减少GEC模型中的false-positive错误, 我们使用re-implementation of the BERT-based SED model(不懂这是啥玩意儿);
# 5 Conclusion
- 利用Gigaword作为种子语料是有效的;
- Pretrain模型使用Backtrans(noisy)数据有用;
- 测试集为CoNLL-2014与BEA-2019两个测试集;
Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
1909.00138 当前时间节点上的NO.2 在Github上有源码可参考
【摘要】
- 神经机器翻译系统已经成为解决GEC问题最先进的方法;
- 本文我们提出一种“复制增强架构”(下称CAA)——它通过从原句中复制未改变的单词到目标句中;
- 由于GEC受限于没有足够多已标注的训练数据来达到高精确度, 我们使用一个“降噪自动编码器”(下称DAE)来预训练CAA, 使用了10亿未标注的Benchmark然后在全预训练模型与部分预训练模型间作比较;
- 这是GEC问题中第一次从原句中复制单词并且构建一个完全预训练的Seq2Seq模型;
- 此外我们增加了token-level与sentence-level多任务学习;
- 实验结果表明我们的模型比别人好不少;
- 实验代码在: https://github.com/zhawe01/fairseq-gec
# 1 Introduction
- “原句-->目标句”过程中一般80%以上的单词不会发生变化, 正因如此, 我们改进目前的神经架构通过使它能够直接从原句中复制未改变的和不在词汇表中的单词, 就和人类纠错时一样, 这是第一次“复制机制”被用于GEC;
- 我们用了很多训练语料: NUS Corpus of Learner English(NUCLE), Lang-8, 即便如此但是因为缺少标注还是很难;
- 为了缓解没有足够已标注的句子的问题, 我们提出使用DAE预训练我们的CAA模型使用10亿未标注的Benchmark;
- 我们也增加两个“多任务”, 包括token-level标注任务与sentence-level复制任务, 用于提升模型性能;
+ 复制机制是首次用于GEC, 曾用于文本总结任务, 在GEC中它可以用于训练集较小的情况, 将未改变的与不在词汇表中的单词直接复制;
- CAA比其他架构在GEC中运行的好, CoNLL2014中测试集取得F0.5指标56.42, 通过用DAE与“多任务”的加成, 最终F0.5为61.15;
- 贡献总结:
+ 提出一个更合适的神经架构CAA;
+ 预训练没有标注的数据, 缓解了训练集标注不足的问题;
+ 在CoNLL2014上进行了测试;
# 2 Our Approach
## 2.1 Base Architecture
- 原句: 第二语言学习者写的句子; 目标句: 纠正语法后的句子; 翻译模型学习从原句到目标句的映射;
- 我们使用基于注意力机制的Transformer架构来作为baseline, Transformer将原句编码成L个完全相同的区块, 每块都在原句tokens上应用一个多头自注意机制, (Position-wise Feed-Forward Networks 位置全链接前馈网络——MLP变形), 解码器与编码器架构相同, 但是在隐层上多加了注意力层;(这边具体架构我也不是很看得懂)
- 目的是预测在单词标记序列({y1,y2,...,yT})中的下一个单词(???暂时没弄明白)
+ h_src_1...N = encoder(L_src_x1...N)
+ h_t = decoder(L_trg * y_t-1...1, h_src_1...N)
+ P_t(w) = softmax(L_trg * h_t)
+ 其中矩阵 L ∈ R^(d_x*|V|) 是词嵌入矩阵, |V|是词汇表规模, h_src_1...N是编码器隐层状态, h_t是下一个单词的目标隐层状态,
+ 损失函数: l_ce = - ∑_t=1~t(log(p_t(y_t))) 交叉熵损失;
+ (我总结一下, 先对原单词标记编码, 再解码, 再软大即可, 交叉熵损失函数)
## 2.2 复制机制
- 复制机制在文本摘要任务与语义分析任务中是有效的, 本文首次将它应用于GEC;
- 图1: 复制增强架构CAA(我下面做个简要描述)
+ 编码器输出一个复制的分布, 解码器输出一个词汇分布, 然后两者通过一个权重加和得到最后的结果;
+ 总之随后是通过加权Copy Scores与Vocabulary Distribution
+ 我觉得并没有看得很懂, 因为我没太看得出来复制体现在哪里了(详细只能看图了);
# 3 Pre-training
- 预训练被证明在很多问题中都是有效的;
- 这里提出使用DAE(这与NO.1的DAE应该是相同的, 这里就再看一遍)
## 3.1 Denoising Auto-encoder
- BERT随机对15%的标记进行降噪处理, 对其中80%的直接用[MASK]替代, 10%用随机单词, 10%是保持原样;
- 本实验中是依据以下顺序操作:
+ 首先 10% 删除一个token;
+ 然后 10% 增加一个token;
+ 接着 10% 用一个随机挑选的单词替代一个单词;
+ 随后正态随机打乱单词(以单词位置为偏差), 然后通过矫正后的位置对单词重新排序, 标准差0.5(???)
## 3.2 Pre-training Decoder
- 预训练嵌入词向量;
- 本实验中的对 CAA-seq2seq 架构中的解码器进行参数预训练;
# 4 Multi-Task Learning(MTL)
- MTL通过联合训练多个相关任务来解决问题, 在很多任务中有效(计算机视觉);
- 本文中给出两个任务: 即标记级别的标注任务与句子级别的复制任务;
## 4.1 Token-level Labeling Task
- 给单词加token, 加注标签是否这个token是对/错;
- 假设每个原标记xi可以与一个目标标记yj一致, 我们定义目标标记是正确的如果xi==yi, 否则错误, 每个标记的标签通过经过编码器的最后状态h_src_i的softmax被预测;
+ 即: p(label_i|x_1...N) = softmax(W' * h_src_i), 其中W'为W的转置;
+ 这个标记级的标注任务直接加强了输入标记的正确性对于编码器而言, 之后还可以被decoder使用;
## 4.2 Sentence-level Copying Task
- 该任务的最初动机是使得模型看起来更加正确;
- 在训练中我们将同等数量的校正样句对与edited句子对发送给模型, 当输入正确的句子时, 我们移除解码器的注意力层, 失去了EncDec的注意力层, 生成工作变得困难, 于是模型中复制的部分将对正确的句子得到提升(我写的我自己都懵了);
# 5 Evaluations
## 5.1 Datasets
- 与之前的研究相同, 我们的使用了已标注数据集如公开的NUCLE, Lang-8, FCE 语料库作为我们的平行训练数据;
- 未标注的数据集如著名的"One Billion Word Benchmark", 我们选择CoNLL2013,2014作为测试集;
- 为了使得我们研究有可比性, 我们只使用了如下的训练集:
+ 训练语料: Lang-8 NUCLE FCE One-Billion;
+ 验证语料: CoNLL2013 CoNLL2014 JFLEG;
+ 我们建立了一个基于统计的拼写错误纠正系统来纠正训练集中的拼写错误;
+ 从Lang-8数据语料中提取出50000词的字典;
+ 训练前先把没有改变的句子扔了;
## 5.2 Model and Training Settings
- 公开的 FAIR seq2seq 工具包 codebase中的Transformer implementation;
- 对于transformer模型,
+ 我们使用标记嵌入层与隐层规模为512;
+ 编码器与解码器都是6层8个注意力头;
+ 对于内部的层前馈网络, 我们使用4096;
+ dropout为0.2;
+ 从训练数据集中找到了一个50000词的词汇表;
+ 优化方法为Nesterovs加速梯度;
+ 学习率为0.002;
+ 权重衰减为0.5;
+ patience为0(patience是个什么玩意儿?);
+ 动量为0.99;
+ 最小学习率10-4(什么意思?);
+ 训练中我们检测每个epoch的表现;
+ 好像还用了些统计上的东西, 看不懂, 不看了;
## 5.3 Experimental Results
- 详见Table4 P6
+ 历年的模型好像大部分都用了LM作为辅助;
## 5.4 Ablation Study
### 5.4.1 Copying Ablation Results
- 比较有无复制机制的情况, 显然对结果提升很大(上一篇中也着重强调了);
- 复制确实对UNK单词处理有很大优势;
- 详见Table5 P7;
### 5.4.2 Pre-training Ablation Results
- 预训练当然有用了, 确实有很大提升;
### 5.4.3 Sentence-level Copying Task Ablation Results
- 前面提到的那个权重α_copy为0.44/0.45是比较好的;
## 5.5 Attention Visualization
- 我觉得已经开始玄学了, 详见Figure2 P8, 意思说大致如下:
+ copy alignment: 复制一句话, 每个单词与它下一个单词对应;
+ Enc-Dec Attention Alignment: 学习出更灵活的对应, 即每个单词检查它是否正确应该有个单词会做出较强的指示, 我们要去学习这个注意力;
# 6 Discussion
## 6.1 Recall on Different Error Types
- 语法错误自动纠正是一个很复杂的任务, 在该部分, 我们分析不同语法错误类型上的表现;
- CoNLL2014测试集有28种不同的错误, 我们排序出最高的9种错误;
- 我们的方法Recall了72.65%的错误在“名词单复数”以及61.79%的错误在“主谓一致”上, 但是在“错误的搭配/习语”上仅有10.38%的Recall;
- 计算机擅长确定性的机械式错误, 但在人类语言文化习惯方面还是不行;
# 7 Related Work
- SMT系统;
- 当前最优的系统;
# 8 Conclusions
- 我们提出CAA(然而我没看懂):
+ 首先我们提出一个加强的CAA, 它改进了seq2seq模型的能力通过直接复制未改变的单词和不在词汇表中的单词从原输入标记;
+ 其次, 我们完全预训练和CAA了使用大规模的未标注的数据, 平衡了降噪自动编码器;
+ 其三, 我们引入两个辅助任务为了多任务学习;
+ 最后我们表现得很好;
!!!在这里我说一下我对注意力机制及多头注意力层的理解!!!
主要参考了https://zhuanlan.zhihu.com/p/54356280
主要是三个矩阵Query(Q),Key(K),Value(V),它们分别与词向量相乘得到查询向量q,键向量k,值向量v,qk点乘得到标量,一句话里每个单词得到一个标量,做softmax,把softmax的输出值乘以v即作为注意力层的输出了。
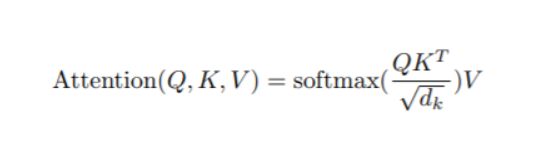
多头则是有多个QKV的三联对(Transformer中有8个),它们分别得到一个注意力层输出,但是模型不需要8个,所以把他们concat起来,用一个需要训练的超参数矩阵W0相乘得到与一个输出相同的维度即可(本质差不多是对这8个加权求和)。原理差不多就是这样了。
20191204更新 著名的Attention is all you need摘要 1706.03762
1. Encoder:
- Encoder由六个同样的编码器层组成;
- 每个编码器层有两个子层: 先进入多头自注意机制(multi-head self-attention mechanism), 再进入前馈全连接层(fully-connected feed-forword network);
- 这两个子层我们都使用了残差连接(residual connection), 且每个子层的输出都会经过一个标准化层处理(Add&Norm: LayerNorm(x+Sublayer(x)));
- 输出维度是d_model=512;
2. Decoder:
- Decoder由六个同样的解码器层组成;
- 每个解码器层有三个子层: 第一层与第三层与编码器中的两个子层相同, 第二层除了接收第一层多头自注意机制的输出外, 还接收Encoder的最终输出;
- 仍然采用残差连接与标准化层;
- 第一个子层多头自注意力机制有所改变, 为了防止位置去影响子序列位置, 于是加了一个masking, 将embedding的输出平移一个位置, 确保对位置i的预测只依赖于已知输出的位置小于i的部分(masked multi-head attention);(说实话我并没有看懂什么意思)
3. Attention: Q K V
- 单位化后的点积注意力:
+ 点积: dot_qk = Q * K
+ 单位化: dot_qk = Q * K / sqrt(d_k)
+ Mask: ???
+ Softmax: 对dot_qk进行softmax处理
+ 点积: 将softmax的输出结果点乘 V 即可
- Attention(Q,K,V) = softmax(QK'/sqrt(d_k))*V;
+ 其中 Q与K 的维度是d_k, V的维度是d_v
- MultiHead(Q,K,V) = Concat(head_1,...,head_h) * W_O
+ 其中head_i = Attention(Q*Wi_Q,K*Wi_K,V*Wi_V)
+ 单个注意力函数有d_model维度的K,V,Q; 然后我们创造h组不同的(Ki,Vi,Qi), 分别学习线性映射到d_k, d_k, d_v维度,
4. Transformer中Attention的应用
- Transformer使用多头注意力在三个不同的方面:
+ 在"Encoder-Decoder Attention"层中, Q来自之前的decoder层, K,V来自encoder的输出, 这使得deocoder中每个位置都可以处理输入序列的每个位置;
+ Encoder中包含自注意力层, K,V,Q来自同样的位置, 即前一层encoder的输出, 同样encoder中的每个位置都可以处理前一层Encoder中的每个位置;
+ Decoder中的自注意力层同样可以处理前一层直到并包括那个位置的; 我们需要防止左边的信息流入decoder破坏了自回归(auto-regressive)性质;
+ 于是我们对
5. 全连接层:
- 使用ReLU作为激活函数;
- FFN(x) = max(0,xW1+b1)W2 + b2
- 输入与输出都是512维; 隐层是2048维的;
6. Embeddings and Softmax:
- 我们使用已经训练好的维度为d_model的embeddings来转换输入token与输出token;
- 在嵌入层中我们把权重乘以sqrt(d_model);
- 因为Encoder-decoder模型中没有RNN与CNN, 为了使得模型可以利用序列的顺序, 我们需要插入一些关羽相对/绝对位置信息;
- 为了达到这个目的, 我们在encoder与decoder的底部向input embeddings中加入positional encodings;