Hbase个人笔记中篇
Hbase个人笔记中篇
- Kafka架构原理
- 写流程
- 重点:
- _root_表(了解)
- MemStore Flush(内存刷写)
- MemStore刷写时机
- 读流程
- HBase读磁盘慢的原因
- 官方解决HBase读磁盘慢的方法
- StoreFile Compaction
- 解读参数
- HBase删除清理过期数据的机制
- Region Split
- 解析不推荐使用的原因
- 解读公式
- 解决方案
- HBase API
- 环境准备
- 查看表是否存在
- 创建命名空间
- 创建表
- 删除表
- 插入单个数据
- 插入多个不同Row-key数据
- 查询数据
- 查询多条数据
- 查询(扫描)全表
- 删除表数据
Kafka架构原理

- StoreFile
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
- MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
- WAL(Hlog)
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
写流程

1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)将数据顺序写入(追加)到WAL;
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
重点:
写数据时,当数据写入HLog时,并不会马上写到HDFS
HLog会等到数据写入memstore后
并且进行逻辑判断
是否写入成功
如果成功,则写入磁盘和发送给HDFS
如果没成功,menstore则会回滚数据,将内存中该数据删除,并让客户端重新发送数据
_root_表(了解)
老版本中有_root_表的概念
这个表是为了保证meta表不做切分
meta表中存的是所有region的位置信息
如果meta做了切分 在zookeeper中
1.无法保存新的meta表信息
2.meta被切分,zookeeper不知道去哪个meta表去查询region,会出现崩溃现象
在实际生产中,meta表很难达到切分地步
所以在新版本中已经被移除了
但如果真的达到了
新版本写了一个逻辑判断
如果一个表达到了切分要求 判断是不是meta
如果是 就直接跳过不切分
MemStore Flush(内存刷写)
MemStore刷写时机
1.当某个memstroe的大小达到了
hbase.hregion.memstore.flush.size(默认值128M),
其所在region的所有memstore都会刷写。
当memstore的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)
hbase.hregion.memstore.block.multiplier(默认值4)
时,会阻止继续往该memstore写数据。
2.当region server中memstore的总大小达到
java_heapsize
hbase.regionserver.global.memstore.size(默认值0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。
直到region server中所有memstore的总大小减小到上述值以下。
当region server中memstore的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)
时,会阻止继续往所有的memstore写数据。
3. 到达自动刷写的时间,也会触发memstore flush。
自动刷新的时间间隔由该属性进行配置
hbase.regionserver.optionalcacheflushinterval(默认1小时)。
4.当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
原因:
wal数量一旦过大 会影响hbase启动的时间,所以官方对wal数量做了封装,最大32
读流程

1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)分别在Block Cache(读缓存),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
HBase读磁盘慢的原因
hbase在读文件时但比写慢的原因
在读到regoin时,会同时读内存和磁盘
因为hbase在查询时是根据时间戳大小进行查询
并且hbase可以存放多个版本
举例:
第一次put一条时间戳为005的信息,进内存,并且被内存刷写进磁盘
第二次put一条时间戳为004的信息.进内存,但还没被刷写进磁盘
用户这时进行查询
如果hbase先读取内存后读取磁盘
会在内存中查询到时间戳004的信息,和用户的要求不对等
所以hbase会同时读取内存和磁盘
会比较时间戳最大的信息反馈给用户
官方解决HBase读磁盘慢的方法
所以为了解决这问题
hbase引用了LRUCache(最近最少使用)的概念
LRUCache是为了加速查询
底层逻辑结构是LinkedHashMap(默认阈值为75%)
添加了blockcache功能
如果需要的信息已经在磁盘中
将该信息先放进blockcache,有blockcache返回给用户
并且信息会在blockcache暂存一段时间
在blockcache不会一直保存数据,当内部数据达到75%时,就会将最近最少使用的数据从中删除
blockcache和memstore都是内存
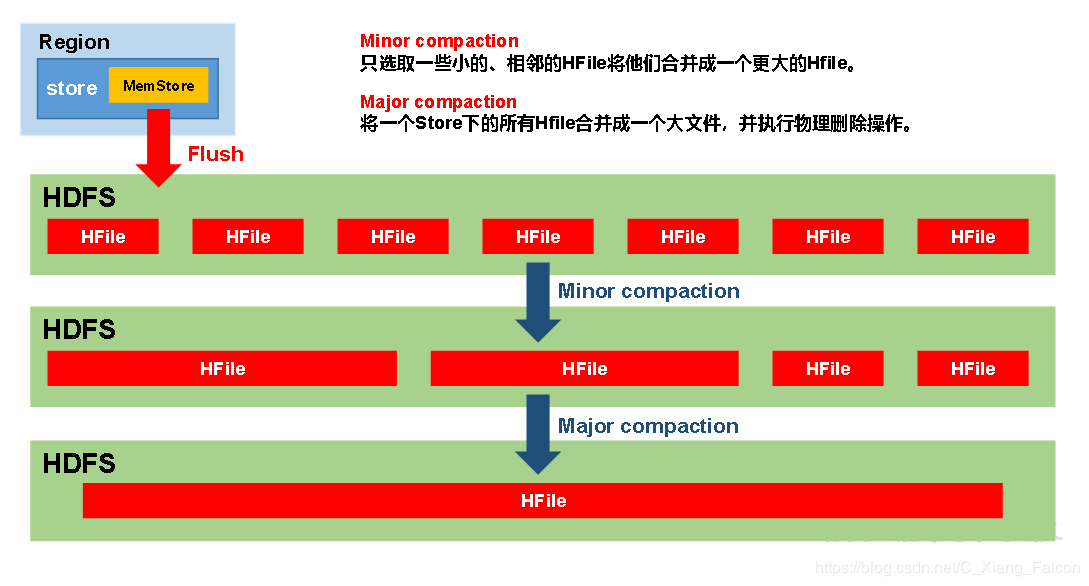
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。
解读参数
在hbase-default.xml中调整参数
- Major Compaction 默认合并间隔为7天,太消耗资源,不确定性,
建议关闭该设置,找合理时间手动进行合并

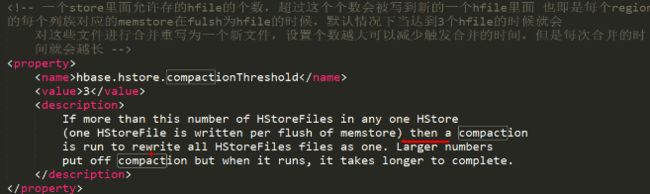
- 每个store file的合并时机
每一个store中的storefile数量达到3个时,就在空闲时间(注意不是立马合并)会自动重写一个storefile
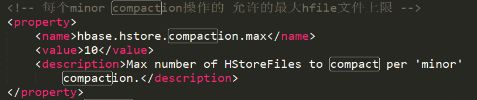
- 每次storefile合并的最大文件数为10个
每次到了合并的时机,不管store里有多少个storefile,一次最大合并为10个
HBase删除清理过期数据的机制
HBase删除数据会发生在两个阶段
- 一个是flush阶段
flush阶段,当数据从内存刷写到磁盘的时候,如果内存有两个版本的数据,并且当前列族的版本只设置1时,在刷写时候,HBase就会将时间戳小的版本数据进行删除,只刷写时间戳大的版本数据
flush阶段只对内存负责,如果两个时间戳版本,一个在磁盘,一个在内存,刷写时,不会进行删除操作
- 一个是compaction阶段
只有Major Compaction具有删除数据的操作,因为他是对全局进行合并,在合并时就会对不符合时间戳或者type为delete的数据进行删除
Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split时机:
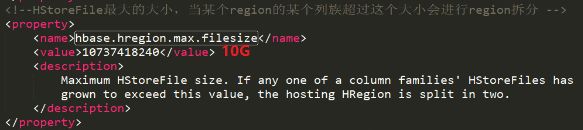
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该Region就会进行拆分(0.94版本之前)。
2.当1个region中的某个Store下所有StoreFile的总大小超过
Min(R^2 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize"),
该Region就会进行拆分,其中R为当前Region Server中属于该Table的个数(0.94版本之后)。

解析不推荐使用的原因
解读公式
Min(R^2 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize")
R为当表的region数量
hbase.hregion.memstore.flush.size默认值为128M
hbase.hregion.max.filesize默认参数为10G
第一次创建表时,只有一个region
所以当前表的第一次切分大小为128M
就会产生2个64M

当没有其他region时,数据会不断往第2个region中写数据
根据公式,第二次切分大小为512M
就会产生2个256M的region
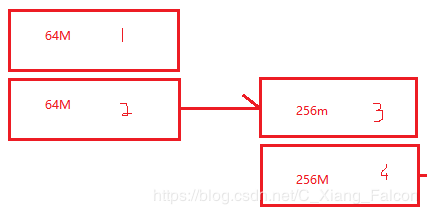
以此类推,当切分大小到达公式最大值hbase.hregion.max.filesize值时,
因为每一次计算切分大小都会根据当前region数量的平方乘以128M
所以迟早会超过10G
当超过10G后
就会生成2个5G的region

这个时候编号为6的region和1号的region比,明显出现了数据倾斜的问题
所以实际开发中不推荐使用region split
解决方案
实际开发中,更多的使用预分区的方案
提前将一段时间内所需要的region数规划好,以提高HBase性能
HBase API
环境准备
新建项目后在pom.xml中添加依赖:
org.apache.hbase
hbase-server
1.3.1
org.apache.hbase
hbase-client
1.3.1
查看表是否存在
package com.DIao.hbaseAPI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.jasper.tagplugins.jstl.If;
import java.io.IOException;
/**
* @version: V1.0
* @author: Diao
* @description: 这是测试HBaseAPI类
* @data: 2019-09-20 18:42
**/
public class MyAPItest {
private static Admin admin = null;
private static Connection connection = null;
static {
//创建配置对象
Configuration configuration = new Configuration();
//连接ZK
configuration.set("hbase.zookeeper.quorum", "hadoop120");
try {
//获取配置信息
connection = ConnectionFactory.createConnection(configuration);
//创建客户端对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
//判断表是否存在
private static boolean isTableExists(String tableName) throws IOException {
//判断是否存在表
boolean exists = admin.tableExists(TableName.valueOf(tableName));
//返回结果
return exists;
}
private static void close(Admin admin, Connection connection) {
//关闭对象和配置信息
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException {
System.out.println(isTableExists("student"));
close(admin, connection);
}
}
创建命名空间
public class MyAPItest {
private static Admin admin = null;
private static Connection connection = null;
static {
//创建配置对象
Configuration configuration = new Configuration();
//连接ZK
configuration.set("hbase.zookeeper.quorum", "hadoop120");
try {
//获取配置信息
connection = ConnectionFactory.createConnection(configuration);
//创建客户端对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
//创建命名空间
private static void createNameSpace(String ns) throws IOException {
//创建命名空间描述器
NamespaceDescriptor build = NamespaceDescriptor.create(ns).build();
//创建命名空间
try {
admin.createNamespace(build);
} catch (NamespaceExistException e) {
System.out.println(ns+":命名空间已存在");
}
}
private static void close(Admin admin, Connection connection) {
//关闭对象和配置信息
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException {
createNameSpace("person");
close(admin, connection);
}
}
创建表
public class MyAPItest {
private static Admin admin = null;
private static Connection connection = null;
static {
//创建配置对象
Configuration configuration = new Configuration();
//连接ZK
configuration.set("hbase.zookeeper.quorum", "hadoop120");
try {
//获取配置信息
connection = ConnectionFactory.createConnection(configuration);
//创建客户端对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void close(Admin admin, Connection connection) {
//关闭对象和配置信息
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//创建表
private static void createTable(String tableName,String... cls) throws IOException {
//判断是否有列族,没有直接返回
if(cls.length<=0){
System.out.println("没有设置列族");
return;
}
//判断表是否存在,没有直接返回
if(isTableExists(tableName)){
System.out.println("表已存在");
return ;
}
//创建表描述器
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
//遍历cls
for (String cl : cls) {
//创建列族描述器
HColumnDescriptor descriptor = new HColumnDescriptor(cl);
//将列族添加到表中
tableDescriptor.addFamily(descriptor);
}
//创建表
admin.createTable(tableDescriptor);
}
public static void main(String[] args) throws IOException {
createTable("student1","info1","info2");
close(admin, connection);
}
}
删除表
private static void deleteTable(String tableName) throws IOException {
//判断表是否存在
if(!isTableExists(tableName)){
System.out.println("表不存在!!!");
return;
}
//下线表
admin.disableTable(TableName.valueOf(tableName));
//删除表
admin.deleteTable(TableName.valueOf(tableName));
}
public static void main(String[] args) throws IOException {
deleteTable("student1");
close(admin, connection);
}
插入单个数据
private static void getTable(String tableName,String rowKey,String cls,String cs,String value) throws IOException {
//获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//添加rowkey
Put put = new Put(Bytes.toBytes(rowKey));
//添加列族,列名,value
put.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs), Bytes.toBytes(value));
//添加数据
table.put(put);
}
public static void main(String[] args) throws IOException {
getTable("student","1005","into","name","zhangsan");
close(admin, connection);
}
插入多个不同Row-key数据
private static void getTables (String tableName,String rowKey1,String rowKey2,String rowKey3,String cls,String cs,String value) throws IOException {
//获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建put的集合
List puts = new ArrayList();
//添加多个rowkey
Put put1 = new Put(Bytes.toBytes(rowKey1));
Put put2 = new Put(Bytes.toBytes(rowKey2));
Put put3 = new Put(Bytes.toBytes(rowKey3));
//添加列族,列名,value
put1.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs), Bytes.toBytes(value));
put2.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs), Bytes.toBytes(value));
put3.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs), Bytes.toBytes(value));
//往集合中添加多个put
puts.add(put1);
puts.add(put2);
puts.add(put3);
//上传多个数据
table.put(puts);
}
public static void main(String[] args) throws IOException {
getTables("student","1006","1007","1008","into","name","zhangsan");
close(admin, connection);
}
查询数据
private static void getData(String tableName,String rowKey,String cls,String cs) throws IOException {
//获取表信息
Table table = connection.getTable(TableName.valueOf(tableName));
//获取get对象
Get get = new Get(Bytes.toBytes(rowKey));
//添加列族和列名
get.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs));
//获取行数据
Result result = table.get(get);
//遍历行,获取想要的数据信息
for (Cell cell : result.rawCells()) {
System.out.println("RK:"+ Bytes.toString(CellUtil.cloneRow(cell))+
",CF:"+ Bytes.toString(CellUtil.cloneFamily(cell))+
",CN:"+ Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
}
public static void main(String[] args) throws IOException {
getData("student","1006","into","name");
close(admin, connection);
}
查询多条数据
private static void getDatas(String tableName,String rowKey1,String rowKey2,String rowKey3,String cls,String cs) throws IOException {
//获取表信息
Table table = connection.getTable(TableName.valueOf(tableName));
//创建get集合
List gets = new ArrayList();
//获取多个get对象
Get get1 = new Get(Bytes.toBytes(rowKey1));
Get get2 = new Get(Bytes.toBytes(rowKey2));
Get get3 = new Get(Bytes.toBytes(rowKey3));
//添加列族和列名
get1.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs));
get2.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs));
get3.addColumn(Bytes.toBytes(cls), Bytes.toBytes(cs));
//获取集合
gets.add(get1);
gets.add(get2);
gets.add(get3);
Result[] results = table.get(gets);
//内嵌遍历,获取想要的数据信息
for (Result result : results) {
for (Cell cell : result.rawCells()) {
System.out.println("RK:"+ Bytes.toString(CellUtil.cloneRow(cell))+
",CF:"+ Bytes.toString(CellUtil.cloneFamily(cell))+
",CN:"+ Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
public static void main(String[] args) throws IOException {
getDatas("student","1006","1007","1008","into","name");
close(admin, connection);
}
查询(扫描)全表
private static void scanData(String tableName) throws IOException {
//创建table对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建scan对象
Scan scan = new Scan();
//获取数据
ResultScanner scanner = table.getScanner(scan);
//解析scanner
for (Result result : scanner) {
//解析result
for (Cell cell : result.rawCells()) {
System.out.println("RK:"+ Bytes.toString(CellUtil.cloneRow(cell))+
",CF:"+ Bytes.toString(CellUtil.cloneFamily(cell))+
",CN:"+ Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
public static void main(String[] args) throws IOException {
scanData("student");
close(admin, connection);
}
删除表数据
private static void deleteDate(String tableName,String rowKey,String cls,String ns) throws IOException {
//创建table对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
//对指定列族:列的最新版本进行删除
//delete.addColumn(Bytes.toBytes(cls), Bytes.toBytes(ns));
//对指定列族:列的全部版本进行删除
delete.addColumns(Bytes.toBytes(cls), Bytes.toBytes(ns));
//删除操作
table.delete(delete);
//关闭资源
table.close();
}
public static void main(String[] args) throws IOException {
deleteDate("student","1008","into","name");
close(admin, connection);
}