LSGAN
《Least Squares Generative Adversarial Networks》
github

Goodfellow在2014年发表了《Generative Adversarial Nets》后,生成对抗网络就引起深度学习领域的关注。它通过一种双人博弈的过程,迭代的优化生成器和判别器,最终到达纳什均衡点。
在标准的GAN中,判别器 D D D的损失函数使用的是交叉熵,虽然最后可以生成效果不错的图像,但是GAN会存在以下两个问题:
- 梯度消失
- 模式坍缩
为了解决这两个问题,作者提出了LSGAN, D D D的损失函数改为使用最小二乘损失,通过实验证明了这种改变不仅可以生成更高质量的图像,而且训练过程更加的稳定,可以有效地解决模式坍缩问题。下面我们就看一下LSGAN是如何解决这两个问题的。
梯度消失问题的出现以及LSGAN的解决方案
在传统的GAN中使用的是交叉熵损失,由它定义的目标函数为:
min G max D V ( G , D ) = E x ∼ p d a t a ( x ) l o g D ( x i ) + E x ∼ p z ( z ) l o g ( 1 − D ( G ( z i ) ) ) \min \limits_{G} \max \limits _{D} V(G,D)=E_{x \sim p_{data}(x) } logD(x_{i})+E_{x \sim p_{z}(z)}log(1-D(G(z_{i}))) GminDmaxV(G,D)=Ex∼pdata(x)logD(xi)+Ex∼pz(z)log(1−D(G(zi)))
虽然GoodFellow在文中提出,可以使用最大化 log D ( G ( z ) ) \log D(G(z)) logD(G(z))来代替最小化 log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))来避免梯度消失问题的过早出现,但是仍然无法从根本上解决这个问题。
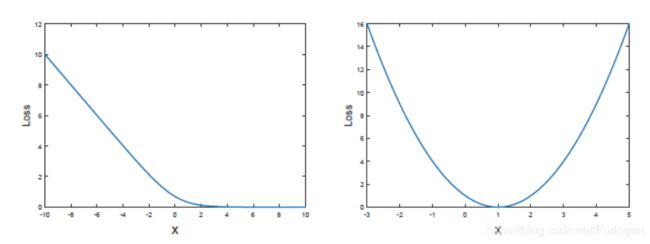
根源在于损失函数的选择,其他的方法只能使得梯度消失晚一点出现,而不是解决这个问题。从交叉熵损失函数的图来看,如下所示,随着 x x x的增大,Loss会很快降为零,此时梯度达到饱和状态, D D D无法再给 G G G提供梯度信息来使 G G G进一步的更新,这样的话整个迭代过程就会停滞,整个模型的效果就不会很好。
而在LSGAN中使用的最小二乘损失的函数图如下右图所示,它也存在Loss为零的点,但是随着 x x x的增大,它会很快地逃离梯度饱和的位置,从而从根源上解决了梯度消失这个问题。
从另一个角度来看,我们同样可以看出最小二乘损失是如何解决这个问题的。在交叉熵中使用的是Sigmoid函数,它可以使得 D D D判别出输入样本是来自真实数据分布还是生成器,但是Sigmoid函数会很快的饱和。类似于它的LR中的使用,LR只关注数据是否正确的落在了决策边界的一边,而不关注数据距离决策边界的远近,这意味着Sigmoid函数不会惩罚距离边界较远的数据点。换言之,只要它成功的欺骗了 D D D,就不会再为 G G G提供更新的梯度信息,所以会很快的出现梯度消失。
而在最小二乘损失中,它使得 D D D不仅需要正确的判别样本的来源,还会惩罚那些即使分类正确但距离决策边界较远的数据点,将其拉到距离边界较近的地方。在这个过程中,这些数据点会持续的为 G G G提供梯度信息,从而一定程度上很好的解决了梯度消失的问题,而且训练的过程也更加稳定。
生成图像质量不高问题的出现以及LSGAN的解决方案
在传统的使用交叉熵损失的GAN中,它的决策边界如下图中蓝色所示,只要数据点被正确分类即可。但是有很多的数据点虽然被正确分类,但是它们距离决策边界很远,也就是说它所满足的分布和真实数据分布之间差异很大,导致了生成的图像很难逼近真实的图像。
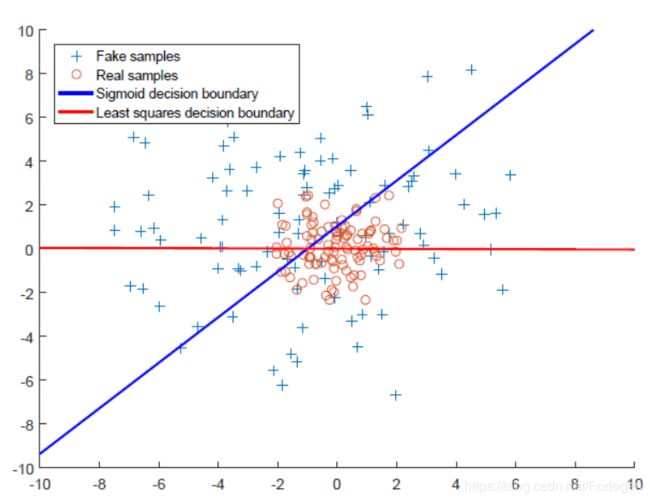
而在LSGAN中使用的最小二乘损失会将正确分类但距离决策边界较远的点拉近,使得整体的数据点距离边界先相比于前面近得多,即处理后它们所满足的分布更加接近真实数据分布,从而很好的提高了生成图像的质量。

理论分析
结合标准的GAN的目标函数和上面的分析,LSGAN的整体的训练过程可以表示为如下的形式:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − b ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − a ) 2 ] min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − c ) 2 ] \begin{aligned} \min _{D} V_{\mathrm{LSGAN}}(D) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}\left[(D(\boldsymbol{x})-b)^{2}\right]+\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z}))-a)^{2}\right] \\ \min _{G} V_{\mathrm{LSGAN}}(G) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z}))-c)^{2}\right] \end{aligned} DminVLSGAN(D)GminVLSGAN(G)=21Ex∼pdata(x)[(D(x)−b)2]+21Ez∼pz(z)[(D(G(z))−a)2]=21Ez∼pz(z)[(D(G(z))−c)2]
其中 G G G代表生成器, D D D代表判别器, z z z代表输入的噪声向量,满足 z ∼ p z z \sim p_{z} z∼pz, p d a t a p_{data} pdata代表真实数据的分布。
确定其中 a 、 b 、 c a、b、c a、b、c值的一种方法是:使其满足 b − c = 1 b-c=1 b−c=1和 b − a = 2 b-a=2 b−a=2 ,目标函数最小化的过程,就是最小化 p d + p g p_{d}+p_{g} pd+pg和 2 p g 2p_{g} 2pg之间 P e a r s o n χ 2 Pearson\ \chi^2 Pearson χ2 散度的过程。
-
当 a = − 1 , b = 1 , c = 0 a=-1, b= 1, c= 0 a=−1,b=1,c=0,得到如下目标函数:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p z [ ( D ( G ( z ) ) + 1 ) 2 ] min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) ) 2 ] \begin{aligned} \min _{D} V_{\mathrm{LSGAN}}(D) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}\left[(D(\boldsymbol{x})-1)^{2}\right]+\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}\left[(D(G(\boldsymbol{z}))+1)^{2}\right] \\ \min _{G} V_{\mathrm{LSGAN}}(G) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z})))^{2}\right] \end{aligned} DminVLSGAN(D)GminVLSGAN(G)=21Ex∼pdata(x)[(D(x)−1)2]+21Ez∼pz[(D(G(z))+1)2]=21Ez∼pz(z)[(D(G(z)))2] -
当 b = c b=c b=c 时,例如使用0-1标签,可以得到如下的目标函数:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p z [ ( D ( G ( z ) ) + 1 ) 2 ] min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) ) 2 ] \begin{aligned} \min _{D} V_{\mathrm{LSGAN}}(D) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}\left[(D(\boldsymbol{x})-1)^{2}\right]+\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}\left[(D(G(\boldsymbol{z}))+1)^{2}\right] \\ \min _{G} V_{\mathrm{LSGAN}}(G) &=\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z})))^{2}\right] \end{aligned} DminVLSGAN(D)GminVLSGAN(G)=21Ex∼pdata(x)[(D(x)−1)2]+21Ez∼pz[(D(G(z))+1)2]=21Ez∼pz(z)[(D(G(z)))2]
对上式求导得到 D D D的最优解 D ∗ D^* D∗:
D ∗ ( x ) = b p d a t a ( x ) + a p g ( x ) p d a t a ( x ) + p g ( x ) D^{*}(\boldsymbol{x})=\frac{b p_{\mathrm{data}}(\boldsymbol{x})+a p_{g}(\boldsymbol{x})}{p_{\mathrm{data}}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} D∗(x)=pdata(x)+pg(x)bpdata(x)+apg(x)
将其代入 min G V L S G A N ( G ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − c ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − c ) 2 ] \min _{G} V_{\mathrm{LSGAN}}(G)=\frac{1}{2} \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}\left[(D(\boldsymbol{x})-c)^{2}\right]+\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z}))-c)^{2}\right] minGVLSGAN(G)=21Ex∼pdata(x)[(D(x)−c)2]+21Ez∼pz(z)[(D(G(z))−c)2] 后,设 b − c = 1 , b − a = 2 b-c=1,b-a=2 b−c=1,b−a=2 有:
2 C ( G ) = ∫ X ( 2 p g ( x ) − ( p d ( x ) + p g ( x ) ) ) 2 p d ( x ) + p g ( x ) d x = χ Pearson 2 ( p d + p g ∥ 2 p g ) 所 以 说 \begin{aligned} 2 C(G) &=\int_{\mathcal{X}} \frac{\left(2 p_{g}(\boldsymbol{x})-\left(p_{\mathrm{d}}(\boldsymbol{x})+p_{g}(\boldsymbol{x})\right)\right)^{2}}{p_{\mathrm{d}}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} \mathrm{d} x \\ &=\chi_{\text { Pearson }}^{2}\left(p_{\mathrm{d}}+p_{g} \| 2 p_{g}\right) \end{aligned}所以说 2C(G)=∫Xpd(x)+pg(x)(2pg(x)−(pd(x)+pg(x)))2dx=χ Pearson 2(pd+pg∥2pg)所以说
所以说目标函数最小化的过程,就是最小化 p d + p g p_{d}+p_{g} pd+pg和 2 p g 2p_{g} 2pg之间 P e a r s o n χ 2 Pearson\ \chi^2 Pearson χ2 散度的过程。
模型架构
-
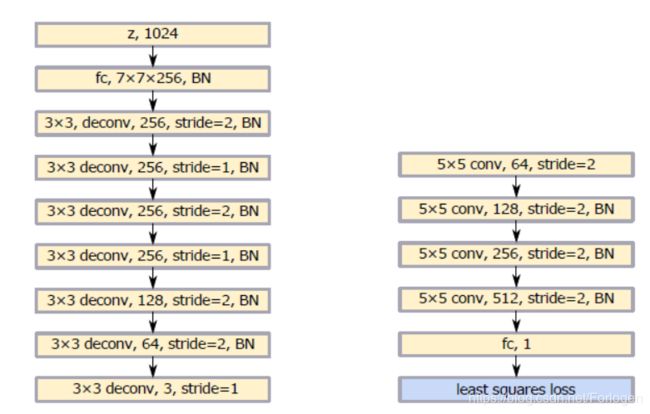
当待处理的数据中类别较少时, G G G和 D D D的网络架构如下所示:
-
当待处理的数据中类别较多时, G G G和 D D D的网络架构如下所示:

实验
作者在多个数据集上进行实验,比较LSGAN和传统的GAN的稳定性。其中在 LSUN ( 使用了里面的 bedroom, kitchen, church, dining room 和 conference room 五个场景)和 HWDB1.0 的这两个数据集上使用 LSGANs 的效果如下所示:

其中在Bedroom中还对比了DCGAN和EBGAN和LSGAN的效果,从中我们可以看出,LSGAN的效果由于其他两个。
此外通过和传统的GAN比较,也可以看出LSGAN的效果要好很多

在显示LSGAN解决模式坍缩问题上,作者使用 LSGANs 和 GANs 学习混合高斯分布的数据集,如下所示:
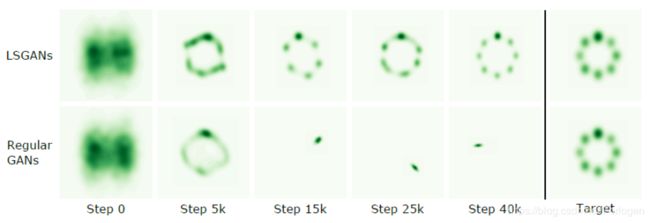
从中可以看出,传统 GAN 在 Step 15k 时就会发生模式坍缩现象,但 LSGANs 非常成功地学习到了混合高斯分布。
在实验的过程中,作者提出了如下的几个训练技巧:
-
G 带有 batch normalization 批处理标准化(以下简称 BN)并且使用 Adam 优化器的话,LSGANs 生成的图片质量好,但是传统 GANs 从来没有成功学习到,会出现 mode collapse 现象;
-
G 和D 都带有 BN 层,并且使用 RMSProp 优化器处理,LSGANs 会生成质量比 GANs 高的图片,并且 GANs 会出现轻微的 mode collapse 现象;
-
G 带有 BN 层并且使用 RMSProp 优化器, G 、 D 都带有 BN 层并且使用 Adam 优化器时,LSGANs 与传统 GANs 有着相似的表现;
-
RMSProp 的表现比 Adam 要稳定,因为传统 GANs 在 G 带有 BN 层时,使用 RMSProp 优化可以成功学习,但是使用 Adam 优化却不行
参考
https://blog.csdn.net/pandamax/article/details/61918899
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/83005495
https://blog.csdn.net/Hansry/article/details/83862548
https://www.jiqizhixin.com/articles/2018-10-10-11
https://zhuanlan.zhihu.com/p/25768099
https://www.cnblogs.com/shouhuxianjian/p/8467845.html
https://cloud.tencent.com/developer/news/325306
https://blog.csdn.net/victoriaw/article/details/60755698