Tensorflow2.0 tf.data.Dataset.from_tensor_slices 自定义图像数据集 (一)
要利用Tensorflow或者Pytorch实现深度学习过程的第一步就是图像数据集的加载。
这里写目录标题
- Tensorflow
- 图像数据集加载
- 图片路径和标签读取
- 图像预处理
- 创建Tensorflow Dataset对象
- 方案一(不推荐)
- 方案二(推荐)
- Dataset对象的预处理
- 输入网络
- 读取.npy文件
- Pytorch
- 参考
Tensorflow
图像数据集加载
从tf.keras.util下载五类花数据集合
data_dir = tf.keras.utils.get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
fname='flower_photos', untar=True)
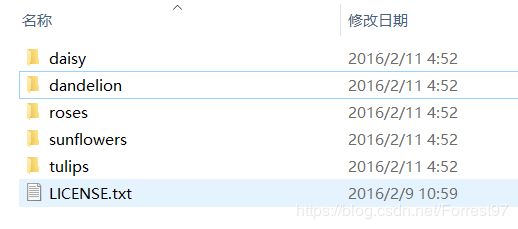
下载完成后,查看数据集的目录位置,可以看到flower_photos目录下有五类花对应的子目录,其中有对应的花.jpg图片。这就是一个标准的图像分类数据集合的存储格式。
import pathlib
data_root = pathlib.Path(data_dir)
print(data_root)
图片路径和标签读取
读取所有图像检索路径,注意不是读取图像数据
import random
all_image_paths = list(data_root.glob('*/*')) # 所有子目录下图片
all_image_paths = [str(path) for path in all_image_paths]
random.shuffle(all_image_paths) #打乱数据
print(len(all_image_paths))
根据子目录名称建立分类字典
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())#读取目录并排序为类别名
label_to_index = dict((name, index) for index, name in enumerate(label_names))#创建类别字典
all_image_labels = [label_to_index[pathlib.Path(path).parent.name]
for path in all_image_paths] #图像parent path 对应类
图像预处理
读取、解码、Resize、根据情况选择数据增强、标准化方法
def preprocess_image(path):
image_size=224
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [image_size, image_size])
# 数据增强
# x=tf.image.random_brightness(x, 1)#亮度调整
# x = tf.image.random_flip_up_down(x) #上下颠倒
# x= tf.image.random_flip_left_right(x) # 左右镜像
# x = tf.image.random_crop(x, [image_size, image_size, 3]) # 随机裁剪
image /= 255.0 # normalize to [0,1] range
# image= normalize(image) # 标准化
return image
创建Tensorflow Dataset对象
创建Tensorflow Dataset对象的目的是方便在训练过程中每组epoch的输入数据的高效输入和统一管理。
方案一(不推荐)
使用 from_tensor_slices 方法构建图像tf.data.Dataset。并使用map方法加载图像预处理preprocess_image
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
AUTOTUNE = tf.data.experimental.AUTOTUNE
image_ds = path_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
使用 from_tensor_slices 方法构建标签tf.data.Dataset。并于图像dataset打包zip构成数据对。
label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(all_image_labels, tf.int64))
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
方案二(推荐)
直接使用all_image_labels 和 all_image_paths 构成一个元组作为tf.data.Dataset.from_tensor_slices的输入
ds = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels))
def load_and_preprocess_from_path_label(path, label):
return preprocess_image(path), label
image_label_ds = ds.map(load_and_preprocess_from_path_label)
image_label_ds
Dataset对象的预处理
在正式开始训练前需要把数据集充分打乱、分割成batcch组、
BATCH_SIZE = 16
image_count = len(all_image_paths)
# 设置一个和数据集大小一致的 shuffle buffer size(随机缓冲区大小)以保证数据
# 被充分打乱。
ds = image_label_ds.shuffle(buffer_size=image_count) # buffer_size等于数据集大小确保充分打乱
ds = ds.repeat() #repeat 适用于next(iter(ds))
ds = ds.batch(BATCH_SIZE)
# 当模型在训练的时候,`prefetch` 使数据集在后台取得 batch。
ds = ds.prefetch(buffer_size=AUTOTUNE)#随机缓冲区相关
输入网络
最后就是输入网络中如果没问题就大功告成
mobile_net = tf.keras.applications.MobileNetV2(input_shape=(192, 192, 3), include_top=False)
mobile_net.trainable=False
def change_range(image,label):
return 2*image-1, label
keras_ds = ds.map(change_range)
# 数据集可能需要几秒来启动,因为要填满其随机缓冲区。
image_batch, label_batch = next(iter(keras_ds))
feature_map_batch = mobile_net(image_batch)
print(feature_map_batch.shape)
读取.npy文件
def load_features(root, mode='train'):
features, labels = load_features_csv(root, 'Feature_list.csv')
if mode == 'train':
features = features[:int(0.6*len(features))]
labels = labels[:int(0.6*len(labels))]
elif mode=='val':
features = features[int(0.6*len(features)):int(0.8*len(features))]
labels = labels[int(0.6*len(labels)):int(0.8*len(labels))]
elif mode == 'test':
features = features[int(0.8*len(features)):]
labels = labels[int(0.8*len(labels)):]
features = load_npy(features) # don't work in prepocess of the tf.data.map()
assert len(features) == len(labels)
return features, labels
def load_npy(feature_paths):
features=[]
for path in feature_paths:
feature=np.load(path)
features.append(feature)
return features
def preprocess(x,y):
y = tf.convert_to_tensor(y)
y = tf.one_hot(y, depth=2)
return x,y
def train(root, batch, epoch):
batchsz=batch
features, labels=load_features(root, mode='train') # =>(batch, 30, 2048)
db_train = tf.data.Dataset.from_tensor_slices((features, labels))
# db_train = db_train.shuffle(100).batch(batchsz)
db_train = db_train.shuffle(100).map(preprocess).batch(batchsz)
features, labels=load_features(root, mode='val')
db_val = tf.data.Dataset.from_tensor_slices((features, labels))
db_val = db_val.map(preprocess).batch(batchsz)
features, labels=load_features(root, mode='test')
db_test = tf.data.Dataset.from_tensor_slices((features, labels))
db_test = db_test.map(preprocess).batch(batchsz)
NOTE:db_train.map(preprocess)中不能使用feature=np.load(path),需要在tf.data.Dataset.from_tensor_slices之前将npy数据进行读取。
否则会报npy不是tensor,tensorflow无法识别的错误
Pytorch
标准二级目录名为类别的图像存储格式数据,采用Pytorch自带API
db = torchvision.datasets.ImageFolder(root='dir', transform=preprocess)