String类常见问题
转自: 小黄鸭编程社区
1.判定定义为String类型的st1和st2是否相等,为什么?
public static void stringTest1(){
String st1 = "abc";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
输出结果:
第一行:true
第二行:true
分析:
先看第一个打印语句,在Java中==这个符号是比较运算符,它可以基本数据类型和引用数据类型是否相等,如果是基本数据类型,==比较的是值是否相等,如果是引用数据类型,==比较的是两个对象的内存地址是否相等。
字符串不属于8中基本数据类型,字符串对象属于引用数据类型,在上面把“abc”同时赋值给了st1和st2两个字符串对象,指向的都是同一个地址,所以第一个打印语句中的==比较输出结果是 true
然后我们看第二个打印语句中的equals的比较,我们知道,equals是Object这个父类的方法,在String类中重写了这个equals方法。
在JDK API 1.6文档中找到String类下的equals方法,点击进去可以看大这么一句话“将此字符串与指定的对象比较。当且仅当该参数不为null,并且是与此对象表示相同字符序列的String 对象时,结果才为 true。” 注意这个相同字符序列,在后面介绍的比较两个数组,列表,字典是否相等,都是这个逻辑去写代码实现。
由于st1和st2的值都是“abc”,两者指向同一个对象,当前字符序列相同,所以第二行打印结果也为true。
下面我们来画一个内存图来表示上面的代码,看起来更加有说服力。
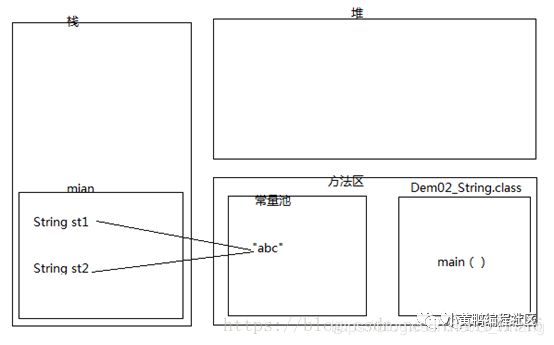
内存过程大致如下:
1)运行先编译,然后当前类Demo2_String.class文件加载进入内存的方法区
2)第二步,main方法压入栈内存
3)常量池创建一个“abc”对象,产生一个内存地址
4)然后把“abc”内存地址赋值给main方法里的成员变量st1,这个时候st1根据内存地址,指向了常量池中的“abc”。
5)前面一篇提到,常量池有这个特点,如果发现已经存在,就不在创建重复的对象
6)运行到代码 Stringst2 =”abc”, 由于常量池存在“abc”,所以不会再创建,直接把“abc”内存地址赋值给了st2
7)最后st1和st2都指向了内存中同一个地址,所以两者是完全相同的。
2.下面这句话在内存中创建了几个对象
String st1 = new String(“abc”);
答案是:在内存中创建两个对象,一个在堆内存,一个在常量池,堆内存对象是常量池对象的一个拷贝副本。
分析:
我们下面直接来一个内存图。
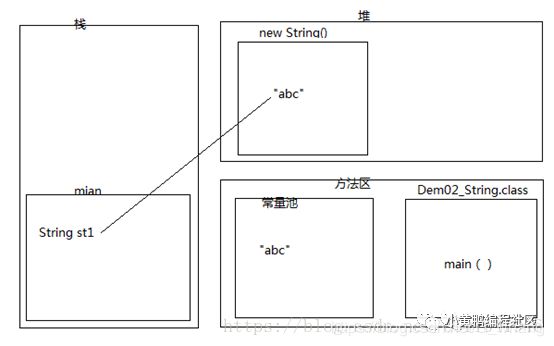
当我们看到了new这个关键字,就要想到,new出来的对象都是存储在堆内存。然后我们来解释堆中对象为什么是常量池的对象的拷贝副本。
“abc”属于字符串,字符串属于常量,所以应该在常量池中创建,所以第一个创建的对象就是在常量池里的“abc”。
第二个对象在堆内存为啥是一个拷贝的副本呢,这个就需要在JDK API 1.6找到String(String original)这个构造方法的注释:初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。
所以,答案就出来了,两个对象。
3、判定以下定义为String类型的st1和st2是否相等
public static void stringTest2(){
String st1 = new String("abc");
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
答案:false 和 true
由于有前面两道提内存分析的经验和理论,所以,我能快速得出上面的答案。
==比较的st1和st2对象的内存地址,由于st1指向的是堆内存的地址,st2看到“abc”已经在常量池存在,就不会再新建,所以st2指向了常量池的内存地址,所以 ,==判断结果输出false,两者不相等。
第二个equals比较,比较是两个字符串序列是否相等,由于就一个“abc”,所以完全相等。
内存图如下
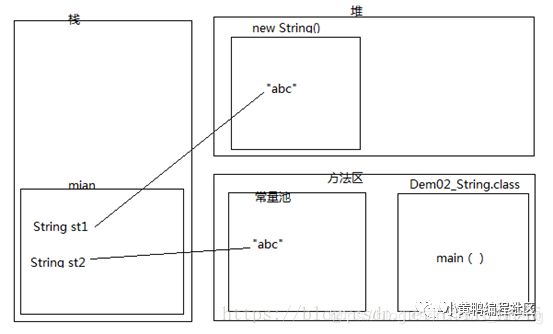
4. 判定以下定义为String类型的st1和st2是否相等
public static void stringTest3(){
String st1 = "a" + "b" + "c";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
答案是:true 和 true
分析:
“a”,”b”,”c”三个本来就是字符串常量,进行+符号拼接之后变成了“abc”,“abc”本身就是字符串常量(Java中有常量优化机制),所以常量池立马会创建一个“abc”的字符串常量对象,在进行st2=”abc”,这个时候,常量池存在“abc”,所以不再创建。所以,不管比较内存地址还是比较字符串序列,都相等。
5、判断以下st2和st3是否相等
public static void stringTest5(){
String st1 = "ab";
String st2 = "abc";
String st3 = st1 + "c";
System.out.println(st2 == st3);
System.out.println(st2.equals(st3));
}
答案:false 和 true
分析:
上面的答案第一个是false,第二个是true,第二个是true我们很好理解,因为比较一个是“abc”,另外一个是拼接得到的“abc”,所以equals比较,这个是输出true,我们很好理解。
那么第一个判断为什么是false,我们很疑惑。同样,下面我们用API的注释说明和内存图来解释这个为什么不相等。
首先,打开JDK API 1.6中String的介绍,找到下面图片这句话。
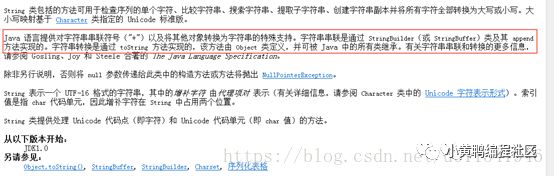
关键点就在红圈这句话,我们知道任何数据和字符串进行加号(+)运算,最终得到是一个拼接的新的字符串。
上面注释说明了这个拼接的原理是由StringBuilder或者StringBuffer类和里面的append方法实现拼接,然后调用 toString() 把拼接的对象转换成字符串对象,最后把得到字符串对象的地址赋值给变量。
结合这个理解,我们下面画一个内存图来分析

大致内存过程
1)常量池创建“ab”对象,并赋值给st1,所以st1指向了“ab”
2)常量池创建“abc”对象,并赋值给st2,所以st2指向了“abc”
3)由于这里走的+的拼接方法,所以第三步是使用StringBuffer类的append方法,得到了“abc”,这个时候内存0x0011表示的是一个StringBuffer对象,注意不是String对象。4)调用了Object的toString方法把StringBuffer对象装换成了String对象。
5)把String对象(0x0022)赋值给st3
所以,st3和st2进行==判断结果是不相等,因为两个对象内存地址不同。
总结:
主要比较是 == 和equals 的比较,通俗的理解 ==是比较两个字符串的引用地址是否一致,equals 是判断两个字符串是否长的一样
常用方法总结
获取功能的方法
public int length () :返回此字符串的长度。
public String concat (String str) :将指定的字符串连接到该字符串的末尾。
public char charAt (int index) :返回指定索引处的 char值。
public int indexOf (String str) :返回指定子字符串第一次出现在该字符串内的索引。
public String substring (int beginIndex) :返回一个子字符串,从beginIndex开始截取字符串到字符串结尾。
public String substring (int beginIndex, int endIndex) :返回一个子字符串,从beginIndex到endIndex截取字符串。含beginIndex,不含endIndex。
public int compareTo(String anotherString)//该方法是对字符串内容按字典顺序进行大小比较,通过返回的整数值指明当前字符串与参数字符串的大小关系。若当前对象比参数大则返回正整数,反之返回负整数,相等返回0。
public int compareToIgnore(String anotherString)//与compareTo方法相似,但忽略大小写。
public boolean equals(Object anotherObject)//比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。
public boolean equalsIgnoreCase(String anotherString)//与equals方法相似,但忽略大小写。
public String concat(String str)//将参数中的字符串str连接到当前字符串的后面,效果等价于"+"。
public int indexOf(int ch/String str)//用于查找当前字符串中字符或子串,返回字符或子串在当前字符串中从左边起首次出现的位置,若没有出现则返回-1。
)public int indexOf(int ch/String str, int fromIndex)//改方法与第一种类似,区别在于该方法从fromIndex位置向后查找。
public int lastIndexOf(int ch/String str)//该方法与第一种类似,区别在于该方法从字符串的末尾位置向前查找。
public int lastIndexOf(int ch/String str, int fromIndex)//该方法与第二种方法类似,区别于该方法从fromIndex位置向前查找。
public String toLowerCase()//返回将当前字符串中所有字符转换成小写后的新串
public String toUpperCase()//返回将当前字符串中所有字符转换成大写后的新串
public String replace(char oldChar, char newChar)//用字符newChar替换当前字符串中所有的oldChar字符,并返回一个新的字符串。
public String replaceFirst(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的第一个和字符串regex相匹配的子串,应将新的字符串返回。
public String replaceAll(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的所有和字符串regex相匹配的子串,应将新的字符串返回。
String trim()//截去字符串两端的空格,但对于中间的空格不处理。
boolean statWith(String prefix)或boolean endWith(String suffix)//用来比较当前字符串的起始字符或子字符串prefix和终止字符或子字符串suffix是否和当前字符串相同,重载方法中同时还可以指定比较的开始位置offset。
regionMatches(boolean b, int firstStart, String other, int otherStart, int length)//从当前字符串的firstStart位置开始比较,取长度为length的一个子字符串,other字符串从otherStart位置开始,指定另外一个长度为length的字符串,两字符串比较,当b为true时字符串不区分大小写。
contains(String str)//判断参数s是否被包含在字符串中,并返回一个布尔类型的值。
转换功能的方法
public char[] toCharArray () :将此字符串转换为新的字符数组。
public byte[] getBytes () :使用平台的默认字符集将该 String编码转换为新的字节数组。
public String replace (CharSequence target, CharSequence replacement) :将与target匹配的字符串使用replacement字符串替换。
分割功能的方法
public String[] split(String regex) :将此字符串按照给定的regex(规则)拆分为字符串数组。
1、字符串转换为基本类型
java.lang包中有Byte、Short、Integer、Float、Double类的调用方法:
1)public static byte parseByte(String s)
2)public static short parseShort(String s)
3)public static short parseInt(String s)
4)public static long parseLong(String s)
5)public static float parseFloat(String s)
6)public static double parseDouble(String s)
2、基本类型转换为字符串类型
String类中提供了String valueOf()放法,用作基本类型转换为字符串类型。
1)static String valueOf(char data[])
2)static String valueOf(char data[], int offset, int count)
3)static String valueOf(boolean b)
4)static String valueOf(char c)
5)static String valueOf(int i)
6)static String valueOf(long l)
7)static String valueOf(float f)
8)static String valueOf(double d)